







一、目标检测思路演进
目标:图像识别+定位
思路一:看作回归问题,搭建神经网络预测(x,y,w,h)四个参数值,从而得到检测框的位置。
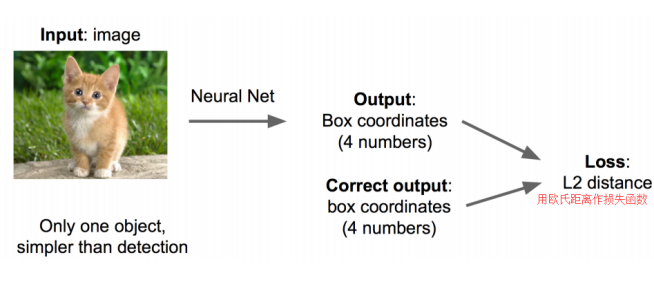
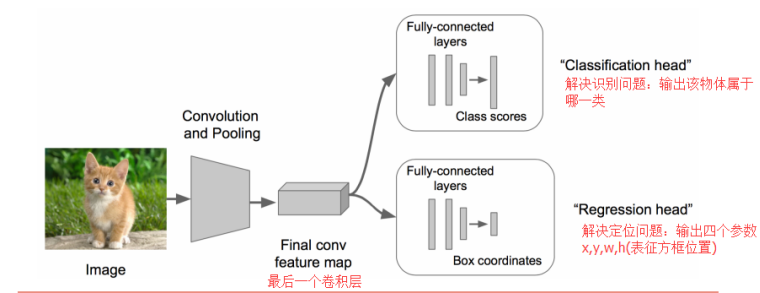
问题:最后用于定位的“回归头”(regression head)很难收敛
思路二:提取图像窗口,对窗口打分,选取得分最高的窗口作为检测框
问题一:传统窗口生成规则:滑动窗口,暴力枚举,遍历图像——耗时、内存占用大
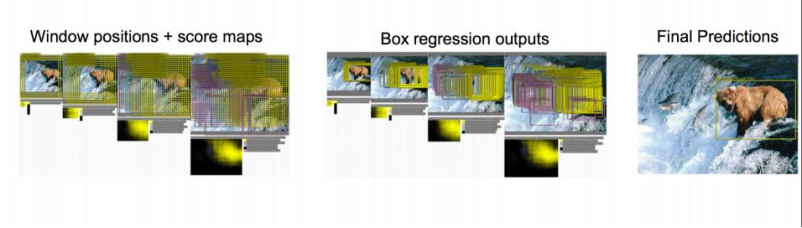
问题二:难以解决图像中出现多个物体的情况
思路三:选取候选框——选择性搜索算法(Selective Search,SS算法)

至此,R-CNN横空出世。
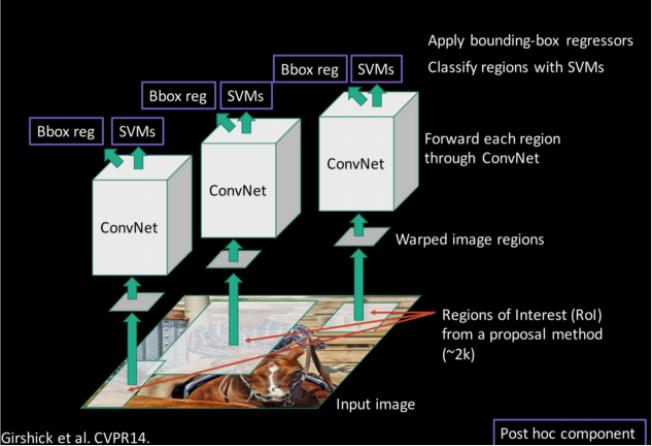
二、R-CNN
R-CNN是Region-based Convolutional Neural Networks的缩写,中文翻译是基于区域的卷积神经网络。Rich feature hierarchies for accurate object detection and semantic segmentation一文被称为将CNN方法引入目标检测领域的开山之作,大大提高了目标检测效果,可以说改变了目标检测领域的主要研究思路,紧随其后的系列文章:(RCNN),Fast RCNN, Faster RCNN 代表该领域当前最高水准。
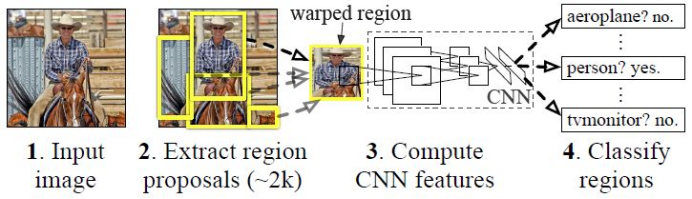
1、基本架构
· 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
· 特征提取: 对每个候选区域,使用卷积神经网络提取特征 (CNN)
· 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类并打分
· 位置精修: 使用回归器精细修正候选框位置
2、SS算法
SS算法由IJCV 2012的论文《Selective Search for Object Recognition》Uijlings,et.提出。这种提取候选框的方法基于Graph-Based Image Segmentation中提出的基于图的图像分割。
a.基于图的图像分割
图是由顶点集V(vertices)和边集E(edges)组成,表示为G=(V,E),顶点v∈V,在本文中 即为单个的像素点,连接一对顶点的边(vi,vj)∈E具有权重w(vi,vj),本文中的意义为顶点之间的不相似度。
树:特殊的图,图中任意两个顶点,都有路径相连接,但是没有回路
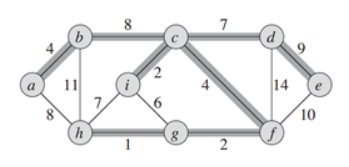
最小生成树(MST,minimum spanning tree):特殊的树,给定需要连接的顶点,选择边权之和最小的树。
区域生成的法则:初始化时每一个像素点都是一个顶点,然后逐渐合并得到一个区域,确切地说是连接这个区域中的像素点的一个MST。
边权的定义:相似性
对于孤立的两个像素点,所不同的是颜色,采用颜色的距离来衡量两点的相似性,本文中使用RGB距离![]() ,物理意义是两个像素点的不相似度(距离)。
,物理意义是两个像素点的不相似度(距离)。
区域生长(合并)的法则:自适应阈值
一个区域的类内差异![]() :
:
![]()
可以近似理解为一个区域内部最大的亮度差异值,定义是MST中不相似度最大的一条边。
两个区域的类间差异![]() :
:
![]()
即连接两个区域所有边中,不相似度最小的边的不相似度,也就是两个区域最相似的地方的不相似度。
判断是否合并的标准:
![]()
直观解释: ![]() ,
,![]() 分别是区域和所能忍受的最大差异,当二者都能忍受当前差异
分别是区域和所能忍受的最大差异,当二者都能忍受当前差异![]() 时,你情我愿,一拍即合,只要有一方不愿意,就不能强求。
时,你情我愿,一拍即合,只要有一方不愿意,就不能强求。
特殊情况,当二者都是孤立的像素值时,![]() ,所有像素都是"零容忍"只有像素值完全一样才能合并,自然会导致过分割(分割区域细碎)。所以刚开始的时候,应该给每个像素点设定一个可以容忍的范围,当生长到一定程度时,削弱乃至去掉该初始容忍值的作用。原文条件如下
,所有像素都是"零容忍"只有像素值完全一样才能合并,自然会导致过分割(分割区域细碎)。所以刚开始的时候,应该给每个像素点设定一个可以容忍的范围,当生长到一定程度时,削弱乃至去掉该初始容忍值的作用。原文条件如下
![]()
增加项![]() :
:
![]()
其中![]() 为区域所包含的像素点的个数。
为区域所包含的像素点的个数。
根据以上法则进行顶点初始化以及区域生长,最终效果如下:


b、具体流程
step1.使用基于图的图像分割方法初始化区域集R
step2.计算R中相邻区域的相似度,并以此构建相似度集S
step3.如果S不为空则执行以下子步骤,否则跳至step4:
ss1.获取S中的最大值s(ri, rj);
ss2.将ri与 rj合并成一个新的区域rt;
ss3.将S中与ri有关的值s(ri, r*)剔除掉;
ss4.将S中与rj有关的值s(r*, rj)剔除掉;
ss5使用step2中的方法,构建S的元素与rt之间相似度的集合St;
ss6.将St中的元素全部添加到S中;
ss7.将rt放入R中,循环step3;
step4.将R中的区域作为目标的位置框,即为算法的执行结果。
c、相似度定义及计算公式
·颜色相似度

·纹理相似度
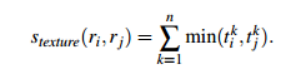
·尺寸相似度
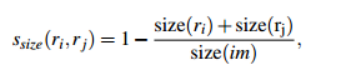
·填充相似度
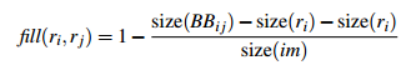
最终给出的相似度计算公式合并了以上四种相似度
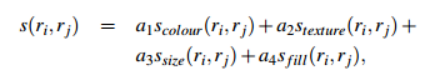
其中![]() 。
。
3、阶段详解
·候选框搜索阶段:采用SS算法生成约2000个候选框,在算法的迭代过程中,由于区域是从小到大融合生长的,所以可以随着迭代创建大小不同的候选框。
·CNN特征提取阶段
两个特性使检测效率提高。首先,所有CNN参数在所有类别中都是共享的。其次,与其他常见的方法相比,CNN计算的特征向量是低维的
训练CNN先使用ILSVRC2012(或ImageNet)上的预训练参数模型,然后在VOC数据集上进行微调。将原网络(如AlexNet)最后一层替换成N+1输出的softmax,使用SGD进行微调训练,batch size选择128,其中32个正样本(包含N个类别)、96个负样本(背景)。
·SVM训练与测试
训练N个二分类线性SVM,输入为CNN卷积层为每个候选框提取出的固定大小的特征向量(文中为4096维),即2000*4096,那么SVM的权重矩阵为4096*N,最终得到的输出结果是2000个候选框对应N个类别的分数(2000*N)。
对于同一个物体得到多个建议候选框的情况,采用非极大值抑制减少重复框:
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
·位置精修
训练边界框回归器对建议候选框进行校正以提高定位精度。
定位精度:采用候选框框与实际标注的物体边界框的IoU值来近似表示。
4、正负样本的采样及训练问题:
(1)对于CNN:
文中首先采用ILSVRC2012(大数据集)进行有监督的预训练,预训练的目标是得到网络参数,用于初始化后面特定样本的微调训练。
特定样本的微调:样本来源PASCAL VOC 2007(小数据集)
正样本:Ground Truth+与Ground Truth相交IoU>0.5的候选框
负样本:与Ground Truth相交IoU≤0.5的候选框
此处正样本的采样条件较为宽松因为每幅图片真正的正样本只有一个,样本太少难以有效微调网络,容易过拟合。
为什么要进行微调:文中设计了没有进行微调的对比实验,分别就AlexNet CNN网络的pool5、fc6、fc7层进行特征提取,输入SVM进行训练,实验结果发现f6层提取的特征比f7层的mAP还高,pool5层提取的特征与f6、f7层相比mAP差不多(网络权重冗余);
在PASCAL VOC 2007数据集上采取了微调后fc6、fc7层特征较pool5层特征用于SVM训练提升mAP十分明显;
由此作者得出结论:不针对特定任务进行微调,而将CNN当成特征提取器,pool5层得到的特征是基础特征,类似于只学习到了人脸共性特征;从fc6和fc7等全连接层中所学习到的特征是针对特征任务特定样本的特征,类似于学习到了分类性别分类年龄的个性特征(特征细化)。
(2)对于SVM:
正样本:Ground Truth
负样本:与Ground Truth相交IoU<0.3的候选框
由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格,也正因此采用SVM作为分类器。
为什么单独训练SVM,不直接应用微调后的softmax层:原文中作者比较了二者的表现,采用SoftMax会使PSACAL VOC 2007测试集上mAP从54.2%降低到50.9%。作者推测这是由于微调时和训练SVM时所采用的正负样本阈值不同,微调阶段正样本定义并不强调精准的位置,而SVM正样本只有Ground Truth;并且微调阶段的负样本是随机抽样的,而SVM的负样本是经过hard negative mining方法筛选的。而根本原因仍然在于数据集的稀缺,作者推断如果有大量标注好Ground Truth的数据集,采用softmax也有同样好的表现。
参考博客:
RCNN-将CNN引入目标检测的开山之作 R-CNN论文详解
论文地址:
Rich feature hierarchies for accurate object detection and semantic segmentation















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









