







前言:当今的计算机视觉领域,目标检测一直是研究的热点与难点。传统的目标检测方法往往依赖于大量的标注数据和复杂的监督学习流程,这不仅增加了数据收集和标注的成本,也限制了这些方法在真实世界应用中的泛化能力。然而,随着深度学习技术的飞速发展,尤其是无监督学习方法的兴起,我们迎来了目标检测领域的新变革,希望通过本文的解读,读者能够深入了解无监督目标检测技术的最新进展,激发对计算机视觉领域研究的兴趣和热情。让我们一起期待无监督目标检测技术在未来能够为我们带来更多的惊喜和突破!
本文所涉及所有资源均在传知代码平台可获取
目录
概述
今天我们介绍一篇CVPR2024的最新无监督三维目标检测的SOTA工作,这篇论文介绍了一种名为Commonsense Prototype-based Detector(CPD)的方法,用于解决无监督三维目标检测中的挑战,可以点击 论文地址 进行查看,如下图所示:
在当前的无监督三维目标检测方法中,通常采用基于聚类的伪标签生成和迭代式自训练过程。然而,由于激光雷达扫描的稀疏性,导致生成的伪标签存在尺寸和位置上的错误,从而影响了检测性能。为了应对这一问题,该论文提出了一种基于常识原型的检测器(CPD),以提高无监督三维目标检测的性能,如下所示:

无监督学习与传统的全监督学习有所区别,它要求在没有任何数据标记的前提下,从数据集中吸取特定的知识。目前有多种基于不完备信息的半监督分类算法用于解决这一问题。常用的策略有预先的训练和启示性的算法等。传统的DBSCAN方法是直接对点云数据进行分类,进而模拟出较为粗糙的边界结构。MODEST技术采用了多次在场景中的遍历来判断物体是否在移动,并依据一些基础知识来过滤掉不合逻辑的伪标签。该方法具有很强的鲁棒性和精确性,但也有不足,例如在大数据环境下需要人工参与。OYSTER利用近距离的点聚类方法来培训一个目标探测器,并借助CNN的平移等变特性来产生远距离的伪标签,接着利用目标路径的时间一致性来抽取自我监控的信号。这些方法都能有效地检测出运动对象在不同时刻发生的变化情况。显然,这些建议的方法都有其固有的限制,并且它们的准确性不高。
在三维目标检测领域,一个至关重要的议题是如何获得高品质的伪标签(pseudo label)。在三维场景下,为了提高伪标签的质量,必须对其进行聚类分析以获取最优解。由于基于聚类生成的伪标签往往表现得非常粗略和不精确,因此有必要构建一个能够生成高品质伪标签的系统架构。本文提出了一种新的、有效的、快速高效的方法来生成高质量的伪标签。CPD的技术主要分为三个核心部分:
1)伪标签初始化
作者观察到,连续帧中的一些静止物体看起来更完整。作者通过使用一种多帧聚类(Multi-Frame Clustering)的策略来初始化伪标签。具体做法是将将一个连续的点云序列:{x−n,...,xn}{x−n,...,xn}拼接,x−nx−n代表前n帧点云,xnxn代表后n帧。并通过计算点云的PP-Score来确定运动点,并移出当前帧之外的所有运动点,避免运动伪影对标签生成产生影响。并通过去除地面、DBSCAN、拟合检测框等操作来得到初步的伪标签b={bj}jb={bj}j,bj=[x,y,z,l,w,h,α,β,τ]bj=[x,y,z,l,w,h,α,β,τ]。分别代表检测框的位置、长宽高、方位角、类别和跟踪标识。
2)伪标签标签优化
基于原型学习的方法是近年来无监督学习中常见的一种策略,方法希望网络能够从代表性样本(即Prototype)中学习到特征,并且通过这些典型样例,进一步将其泛化为更为复杂的场景。初始化伪标签时可能会得到很多伪标签位置与尺寸都不精确,而且因为点云稀疏,所以点云上的例子也会不全面。因此,从点云数据中筛选出高品质的典型原型变得尤为关键。笔者的思路是根据从完整物体上获得的无监督评分来构造一个优质CProto集来对不完整物体进行伪标签细化。区别于OYSTER仅能细化被扫描物体中至少1个完整物体的伪标签,CBR方法能够细化全部物体伪标签并显着减小总体尺寸及位置误差。
笔者设计了测量这些伪标签质量优劣的CSS分数,以筛选出优质常识原型。该方法仅依赖于基础的常识知识来近似评估IoU在全监督评估中的表现。例如:离得较近的点中相对应的例子完整性可能相对较好,汽车、人员等对象通常都有长宽比范围。以及基于优质常识原型调整初始化标签。
3)自训练
在上面的过程中,通过基于常识原型对伪标签进行了调整。然而,即使在细化之后,一些伪标签仍然不准确,降低了正确监督的有效性,并可能误导训练过程。因此作者设计两部分损失函数解决这一问题,特别地,如pipeline所示,作者设计了两个网络:检测网络FdetFdet和原型网络FproFpro:
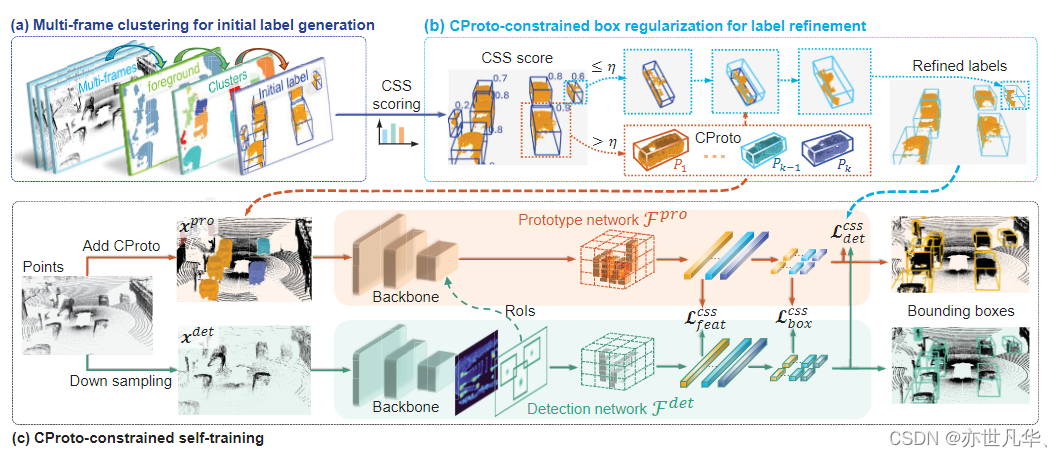
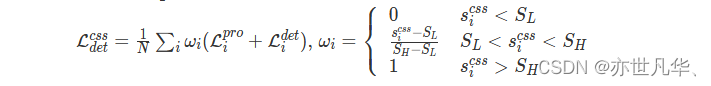
(1) CSS-Weighted Detection Loss,它根据标签质量分配不同的训练权重来抑制虚假监督信号。
(2)几何对比度损失,将稀疏扫描点的预测与密集的CProto对齐,从而提高特征的一致性。
作者将CPD和先前的无监督目标检测方法进行了对比,说明了CPD性能的有效性:

核心代码
下面这段代码的作用是定义了一个用于处理Waymo无监督数据集的类,并提供了初始化函数来配置数据集的相关参数,并准备好加载数据集的样本序列列表:
class WaymoUnsupervisedDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None, test_iter=0):
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger,
test_iter=test_iter
)
self.data_path = self.root_path / self.dataset_cfg.PROCESSED_DATA_TAG
self.split = self.dataset_cfg.DATA_SPLIT[self.mode]
split_dir = self.root_path / 'ImageSets' / (self.split + '.txt')
self.sample_sequence_list = [x.strip() for x in open(split_dir).readlines()]
self.only_top_lidar = dataset_cfg.TL
self.sampling = dataset_cfg.SAMPLING
self.infos = []
self.include_waymo_data(self.mode)OpenPCDet提供各种主流的backbone框架,可以根据自己的求修改配置文件和网络架构。它定义了一个父类Detector3DTemplate作为基本的检测器框架,不同检测器继承这个类,并根据自己的要求修改:
class Detector3DTemplate(nn.Module):
def __init__(self, model_cfg, num_class, dataset):
super().__init__()
self.model_cfg = model_cfg
self.num_class = num_class
self.dataset = dataset
self.class_names = dataset.class_names
self.register_buffer('global_step', torch.LongTensor(1).zero_())
self.module_topology = [
'vfe', 'backbone_3d', 'map_to_bev_module', 'temporal_model',
'backbone_2d', 'dense_head','pfe', 'wrap_head', 'point_head', 'roi_head'
]
self.num_frames=dataset.num_frames
self.test_filp=dataset.test_flip下面这段配置文件提供了一个完整的目标检测模型的定义,包括输入数据的处理、特征提取、以及最终的目标检测过程:
CLASS_NAMES: ['Vehicle', 'Pedestrian', 'Cyclist']
DATA_CONFIG:
_BASE_CONFIG_: cfgs/dataset_configs/waymo_unsupervised/waymo_unsupervised_cproto.yaml
NUM_FRAMES: 1
LABEL_OFFSET: 0.0
POINT_FEATURE_ENCODING: {
encoding_type: absolute_coordinates_encoding,
used_feature_list: ['x', 'y', 'z', 'intensity', 'time'],
src_feature_list: ['x', 'y', 'z', 'intensity', 'time']}
MODEL:
NAME: VoxelRCNN
VFE:
NAME: MeanVFE
BACKBONE_3D:
NAME: VoxelResBackBone8x
NUM_FILTERS: [16, 32, 64, 128]
RETURN_NUM_FEATURES_AS_DICT: True
OUT_FEATURES: 128
MM: True
FREEZE_TEACHER: False
MAP_TO_BEV:
NAME: HeightCompression
NUM_BEV_FEATURES: 256
BACKBONE_2D:
NAME: BaseBEVBackbone
LAYER_NUMS: [5, 5]
LAYER_STRIDES: [1, 2]
NUM_FILTERS: [128, 256]
UPSAMPLE_STRIDES: [1, 2]
NUM_UPSAMPLE_FILTERS: [256, 256]
......使用方式
本次代码运行环境如下:
Linux (tested on Ubuntu 14.04/16.04/18.04/20.04/21.04)
Python 3.6+
PyTorch 1.1 or higher (tested on PyTorch 1.1, 1,3, 1,5~1.10)
CUDA 9.0 or higher (PyTorch 1.3+ needs CUDA 9.2+)
spconv v2.x
安装 OpenPCDet 如下:
git clone https://github.com/open-mmlab/OpenPCDet.git
cd OpenPCDet
pip install -r requirements.txt
python setup.py developWaymo数据集准备,下载waymo官方数据集 Waymo Open Dataset ,解压所有 xxxx.tar 到 data/waymo/raw_data文件夹下。(798 train tfrecord and 202 val tfrecord ): 结构目录如下:
CPD
├── data
│ ├── waymo
│ │ │── ImageSets
│ │ │── raw_data
│ │ │ │── segment-xxxxxxxx.tfrecord
| | | |── ...
| | |── waymo_processed_data_train_val_test
│ │ │ │── segment-xxxxxxxx/
| | | |── ...
│ │ │── pcdet_waymo_track_dbinfos_train_cp.pkl
│ │ │── waymo_infos_test.pkl
│ │ │── waymo_infos_train.pkl
│ │ │── waymo_infos_val.pkl
├── pcdet
├── tools运行如下命令执行项目:
python3 -m pcdet.datasets.waymo.waymo_tracking_dataset --cfg_file tools/cfgs/dataset_configs/waymo_unsupervised/waymo_unsupervised_cproto.yaml训练和评估执行命令如下:
# 分布式训练
cd tools
sh dist_train.sh {cfg_file}
# 或者运行
cd tools
python train.py
# 评估
cd tools
sh dist_test.sh {cfg_file}写在最后
回顾这些最新的研究成果,无监督目标检测技术的魅力在于其摆脱了对大量标注数据的依赖,使得模型能够直接从无标签的图像中学习到目标对象的特征。这不仅降低了数据收集和标注的成本,也为目标检测技术的广泛应用提供了更加灵活和便捷的途径。我们也看到了无监督目标检测技术在多个方面的突破。从模型的架构设计到优化算法的创新,再到实验验证的严谨性,这些研究都展示了研究者们对无监督目标检测技术的深入理解和不断探索的精神。
然而,无监督目标检测技术仍然面临着诸多挑战。如何进一步提高模型的检测精度和泛化能力,如何更好地处理复杂场景下的目标检测问题,以及如何将无监督目标检测技术与其他计算机视觉任务相结合,都是未来研究需要重点关注的方向。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号



















 3547
3547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











