






问题描述
在QQ,微信上存在着大量的好友关系,
如果A和B是好友,我们说A和B是一度人脉;
如果A和B是好友,B和C也是好友,我们说A和C是二度人脉。
以下为一系列朋友关系,每行出现两个姓名,以空格隔开,表示两人为朋友关系。
A B;
B C;
C D;
B F;
A F;
F G;
F H;
H A;
H D;
B G;
D F;
D G;
H G;
H C
根据以上的朋友关系,使用MapReduce编程计算出所有的二度人脉关系。
分析
A B为好友,B C为好友,说明A C可能存在二度人脉,但是若存在A C,则AC就不是二度人脉了,这也是难点所在。
需要利用两个Job完成分析。
Job1找到某人所有的一度人脉和二度人脉
Map1:输入A B 输出: < A, A_B> <B,A_B>
Reduce1:输入<A,<A_B , …>>
将key的一度关系挑选出来(即Value中存在key),以<A_B,1>的形式输出,并将一度好友存入vector容器,vector容器中的人互为二度好友,将他们以<A_C,2>的形式输出。这样就Job1就找出了每个人的一度人脉和二度人脉。
Job2将每个人的一度人脉好友和二度人脉好友放在一个列表,若二度人脉也是一度人脉好友,则说明两人是一度人脉关系而不是二度人脉关系。
Map2:输入A_B 1 输出:A_B 1
Reduce2:输入<A_B,<1,2 , …>> 输出:二度关系数目 A B
代码
import java.io.IOException;
import java.net.URI;
import java.util.Scanner;
import java.util.Vector;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class App_2_Friend {
// map1
public static class Map1 extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
Text map1_key = new Text();
Text map1_value = new Text();
if (words[0].compareTo(words[1]) < 0) {
map1_value.set(words[0] + "\t" + words[1]);
} else {
map1_value.set(words[1] + "\t" + words[0]);
}
map1_key.set(words[0]);
context.write(map1_key, map1_value);
map1_key.set(words[1]);
context.write(map1_key, map1_value);
}
}
// reduce1
public static class Reduce1 extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Vector<String> friends = new Vector<String>();
for (Text val : values) {
String[] words = val.toString().split("\t");
if (words[0].equals(key.toString())) {
friends.add(words[1]);
context.write(val, new Text("DirectFriend"));
}
if (words[1].equals(key.toString())) {
friends.add(words[0]);
context.write(val, new Text("DirectFriend"));
}
}
for (int i = 0; i < friends.size()-1; i++) {
for (int j = i+1; j < friends.size(); j++) {
if (friends.elementAt(i).compareTo(friends.elementAt(j)) < 0) {
context.write(new Text(friends.elementAt(i) + "\t" +
friends.elementAt(j)), new Text("IndirectFriend"));
} else {
context.write(new Text(friends.elementAt(j) + "\t" +
friends.elementAt(i)), new Text("IndirectFriend"));
}
}
}
}
}
// map2
public static class Map2 extends Mapper<LongWritable , Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split("\t");
context.write(new Text(line[0] + "\t" + line[1]), new Text(line[2]));
}
}
// reduce2
public static class Reduce2 extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
boolean isdirect = false;
boolean isindirect = false;
int count = 0;
for (Text val : values) {
if (val.toString().compareTo("DirectFriend") == 0) {
isdirect = true;
}
if (val.toString().compareTo("IndirectFriend") == 0) {
isindirect = true;
count++;
}
}
if ((!isdirect) && isindirect) {
context.write(new Text(String.valueOf(count)), key);
}
}
}
// main
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job1 = Job.getInstance(conf);
job1.setJarByClass(App_2_Friend.class);
job1.setMapperClass(Map1.class);
job1.setReducerClass(Reduce1.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(Text.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(Text.class);
Scanner sc = new Scanner(System.in);
System.out.print("inputPath:");
String inputPath = sc.next();
System.out.print("outputPath:");
String outputPath = sc.next();
FileInputFormat.setInputPaths(job1, new Path("hdfs://master:9000"+inputPath));
FileOutputFormat.setOutputPath(job1, new Path("hdfs://master:9000"+inputPath+"temp"));
if (job1.waitForCompletion(true)) {
Job job2 = Job.getInstance(conf);
job2.setJarByClass(App_2_Friend.class);
job2.setMapperClass(Map2.class);
job2.setReducerClass(Reduce2.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job2, new Path("hdfs://master:9000"+inputPath+"temp"+"/part-r-00000"));
FileOutputFormat.setOutputPath(job2, new Path("hdfs://master:9000"+outputPath));
job2.waitForCompletion(true);
try {
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path srcPath = new Path(outputPath+"/part-r-00000");
FSDataInputStream is = fs.open(srcPath);
System.out.println("Results:");
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
}
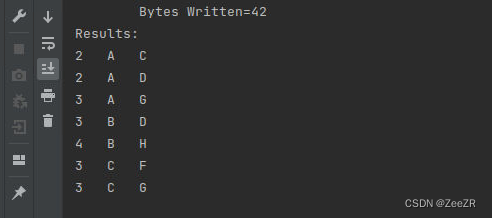
运行结果















 2921
2921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











