







- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
一、HLS设计简介
1.接口综合
在做 HLS 的时候, 设计者需要分析设计的两个主要方面:
• 设计的接口,即它的顶层连接;
• 设计的功能,即它所实现的算法;
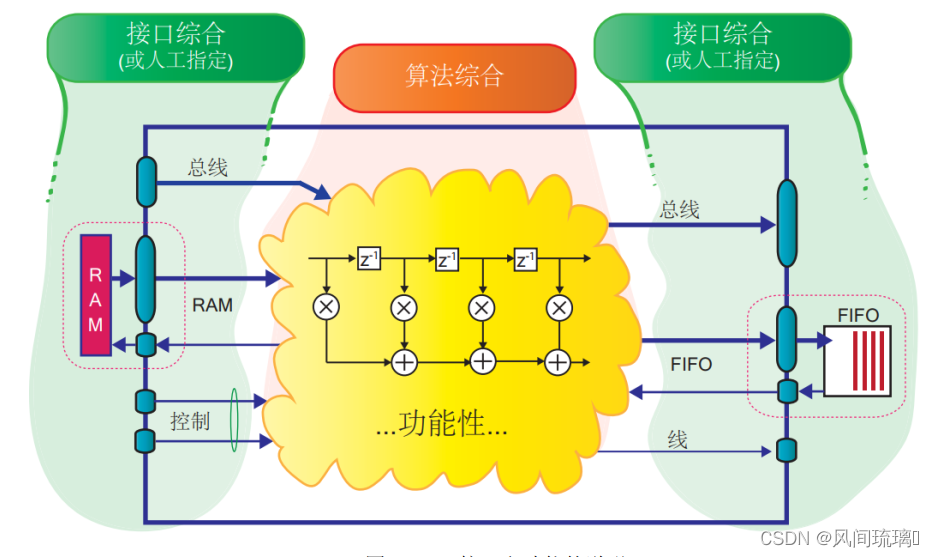
在上图中,两端的绿色区域表示设计的输入和输出接口,其中展示了部分接口类型,如 RAM 接口、 FIFO接口,以及总线类型的接口等。这些接口可以是工具从代码中通过接口综合(Interface Synthesis) 得到的,也可以由设计者手动指定具体的接口类。
图中间黄色的区域表示 HLS 设计具体能够实现的功能,对于不同的应用,其功能也各不相同。 在 VivadoHLS 设计中,功能是从输入的代码中,经过算法综合(Algorithm Synthesis)的过程得到的。
接口综合(Interface Synthesis) 指的是 HLS 设计中对接口的综合,综合出来的接口能够与系统中的其他模块通信,还有可能需要与系统中的处理器进行通信。
这里接口的概念既包括端口(port),也包含所使用的协议。所有端口的细节(如类型、位宽和方向)是从 C/C++ 文件中顶层函数的参数和返回值里推断出来的;而协议是从端口的表现(行为)推断出来的。比如,最简单的接口可以是一条 1 比特的线(wire),而更复杂的接口,可能要用总线或 RAM 接口。接口综合能够推断出来的接口类型包括:线、寄存器、单向和双向握手信号、 FIFO、存储器和总线等。
Vitis HLS设计的顶层函数的实参均综合到接口和端口内, 这些接口和端口通过将多个信号加以组合来定义 HLS 设计与设计外部的组件之间的通信协议。 Vitis HLS 会自动定义接口, 并使用业界标准来指定要使用的协议。 Vitis HLS创建的接口类型取决于顶层函数的参数的数据类型和方向、处于活动状态的解决方案的目标流程、 config_interface 指定的默认接口配置设置以及任何指定的 INTERFACE 编译指示或指令。
一个简单的 C 设计的顶层函数,函数名为 find_average_of_best_X(),其参数如下图所示: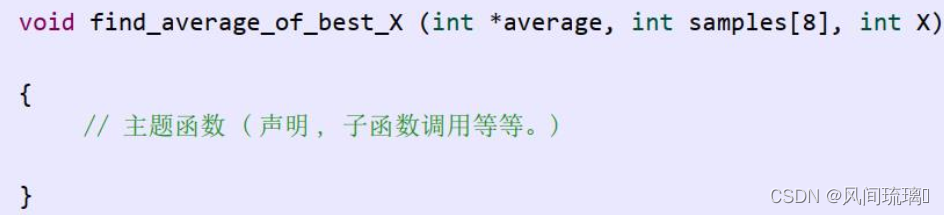
函数内部工作的详细情况无关紧要,不过每个参数的读/写操作将决定综合出来的端口的方向。函数定义包含三个参数,数组sample和整数X是函数的输入,average 作为函数的输出。因此,这三个函数参数要被 HLS 转换成两个输入接口和一个输出接口,如下图所示:

这只是一个简化了的接口示意图。根据所用的协议,这些接口可能包括数据端口自身以外的控制输入或输出,如下图所示:
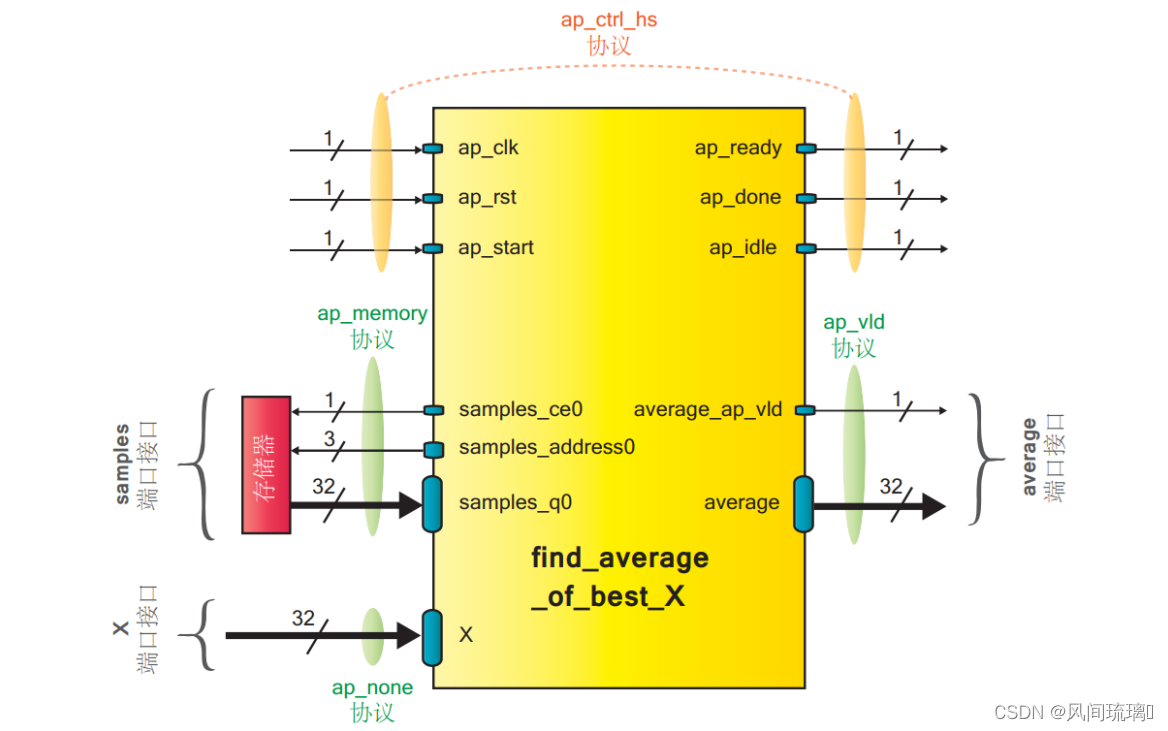
函数 find_average_of_best_X()经 HLS 综合出来的完整的 RTL 模块的接口图。从图中可以看到由函数的三个参数所综合出来的接口分别拥有了各自的协议,如 ap_memory 协议、 ap_none 协议和 ap_vld协议。同时模块还多出来了一些端口,如 ap_clk 和 ap_rst 等,它们使用的是 ap_ctrl_hs 协议。
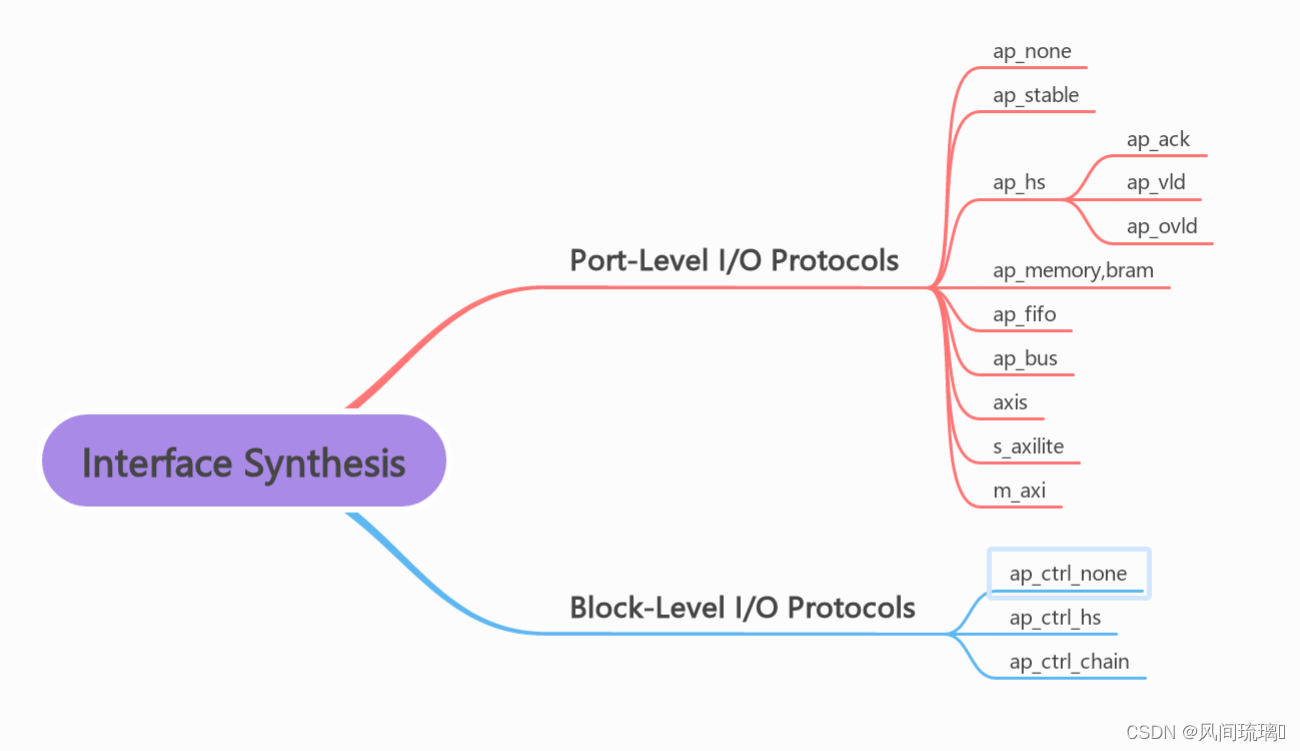
常见的接口信号基本就是定义成块(Block-Level)和端口(I/O Protocols),这两分别是对于顶层函数和顶层函数的形参来说的。
2.算法综合
算法综合关注的是设计的功能,即设计所期望的行为,它是由输入的 C 设计所描述的。算法综合从代码中推出各种运算操作,然后转换成一组 RTL 语句。
算法综合包括三个主要阶段,依次是:
①解析出数据通路和控制电路
②调度和绑定
③优化
a.解析出数据通路和控制电路
HLS 的第一个阶段是分析 C/C++/SystemC 代码,并且解释所需的功能。 Vivado HLS 从以下几个方面分析程序: 逻辑和算法的运算、条件语句和分支、 数组运算和循环等。
所产生的实现会具有一个数据通路元件和一个控制元件。“数据通路”处理指的是在数据样本上作的运算,“控制”是需要协同数据流处理所需的电路。算法的本质定义出数据通路和控制元件,设计者可以在 HLS 中采取专门的步骤来最小化控制元件的复杂度。
b.调度和绑定
HLS 是由两个主要过程组成的:调度(Scheduling)和绑定(Binding)。它们是交替进行的,彼此互相影响,如下图所示: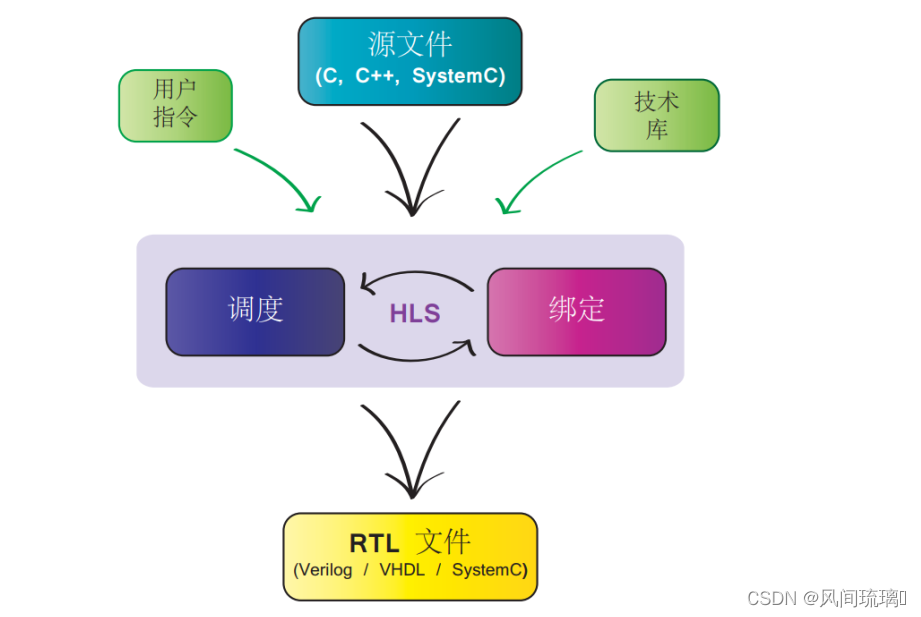
调度是把由 C 代码解释得到的 RTL 语句翻译成一组运算,每个运算都关联着一定的执行时间,以
时钟周期为单位。这个阶段所作的决策,受时钟频率和不确定度、目标芯片的技术和用户所施加的指令所影响。
绑定是调度好了的运算和目标芯片上的实际资源联系起来的过程。这些资源的功能和时序特征可能
会影响调度,因此绑定信息会反馈给调度过程。
如果综合出来的算法需要做一组算术运算, HLS 过程就必须根据目标的时钟频率和不确定度来决定如何调度这些运算(要分配多少个时钟周期来完成),以及如何绑定这些运算(如何把运算映射到 PL 上的可计算资源里)。 C 源码并不能表达或指定硬件架构,但是通过施加指令,源码确实可以产生不同的架构。
c.优化
有两种方法可以用来调整 HLS 过程的行为,让高层综合朝着设计者的实现目标而努力,从而影响结果:
①约束
设计者可以对设计的某些指标加以限制。可以指定最低的时钟周期, 这样就能确保实现结果能够满足要集成进去的系统的要求。设计者可以选择约束资源的利用情况或其他的指标,从而优化应用的设计。
②指令
设计者可以通过指令对 RTL 的实现参数施加更具体的影响。有各种类型的指令,分别映射在代码的某些特征上。设计者可以指定 HLS 引擎如何处理 C 代码中识别出来的循环或数组,或是某
个特定运算的延迟,这能导致 RTL 输出的巨大改变。
二、默认流程接口
1.Vivado IP流程接口
由于需要为各种应用提供 FPGA 设计支持, 因此 Vivado IP 流程支持各种 I/O 协议和握手。此流程支持将多个 IP 集成到单个系统内的传统系统设计流程。
Vivado IP 流程支持存储器、串流和寄存器接口范例, 其中每个范例都支持不同接口协议与外部世界进行通信
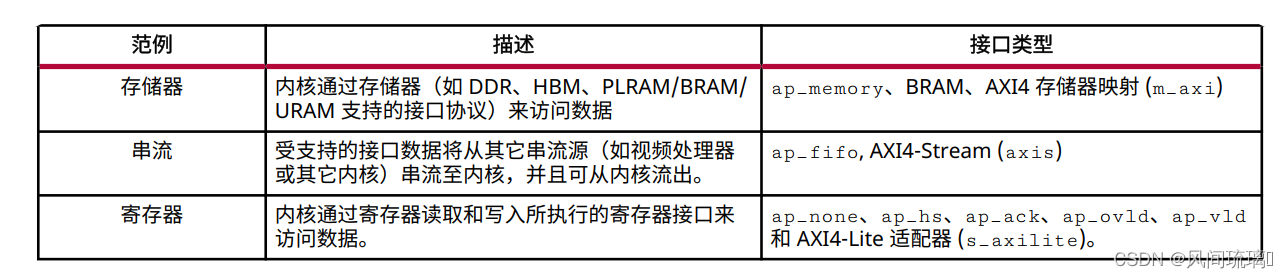
默认接口由顶层函数中的 C 语言实参类型和默认范例来定义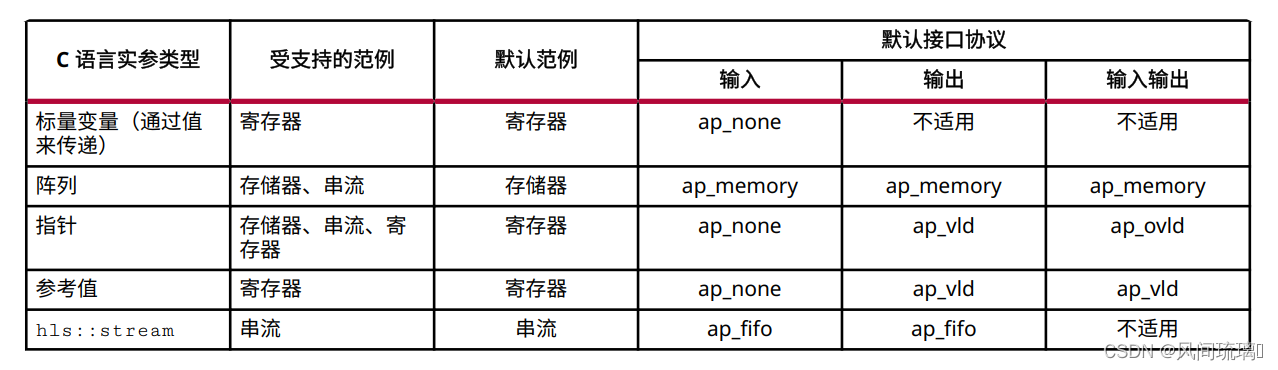
Vivado IP 流程的默认执行模式为顺序执行, 要求 HLS IP 完成前一次迭代后才能开始下一次迭代。这是通过ap_ctrl_hs 块控制协议指定的。控制协议可按 块级控制协议 中指定的方式来更改
#define VDATA_SIZE 16
typedef struct v_datatype { unsigned int data[VDATA_SIZE]; } v_dt;
extern "C" {
void vadd(const v_dt* in1, // Read-Only Vector 1
const v_dt* in2, // Read-Only Vector 2
v_dt* out_r, // Output Result for Addition
const unsigned int size // Size in integer
) {
unsigned int vSize = ((size - 1) / VDATA_SIZE) + 1;
// Auto-pipeline is going to apply pipeline to this loop
vadd1:
for (int i = 0; i < vSize; i++) {
vadd2:
for (int k = 0; k < VDATA_SIZE; k++) {
out_r[i].data[k] = in1[i].data[k] + in2[i].data[k];
}
}
}
}通过 Vivado IP 流程所使用的默认接口综合设置, 设计将综合到含端口的 RTL 块中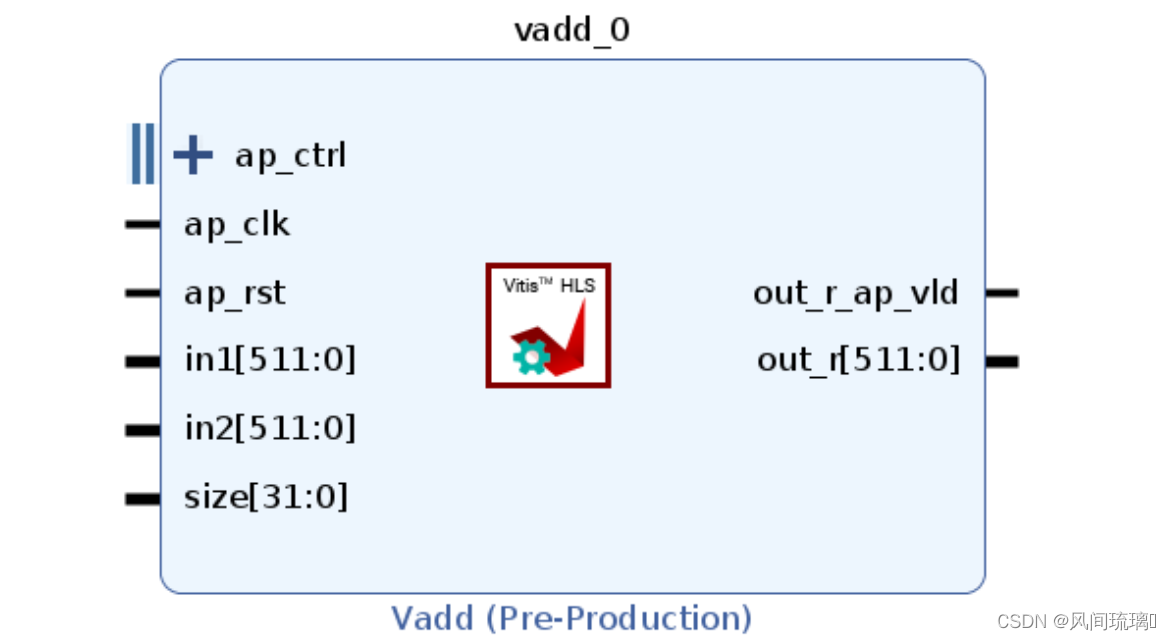
在默认 Vivado IP 流程中, 该工具会在 RTL 上创建三种类型的接口端口, 以处理数据流和控制流。
①时钟和复位端口: ap_clk 和 ap_rst 均添加到内核中
②块级控制协议: ap_ctrl 接口是作为 s_axilite 接口来实现的
③端口级协议: 这些协议是针对顶层函数和函数返回(如果函数返回值) 中的每个实参创建的。大部分实参都使用端口协议 ap_none, 并且不含控制信号。但是, out_r_o 输出端口使用 ap_vld 协议, 因此与 out_r_o_ap_vld 信号相关联。
2.Vitis 内核流程接口
Vitis 内核流程为已编译的内核对象 (.xo) 提供支持, 以便从主机应用和赛灵思的 Xilinx Run Time (XRT) 来执行软件控制。
Vitis HLS 支持多种存储器、串流和寄存器接口范例, 其中每个范例都遵循某个接口协议并使用适配器来与外部世界进行通信。
• 存储器范例 (m_axi): 内核通过存储器(如 DDR、 HBM、 PLRAM/BRAM/URAM) 来访问数据
• 串流范例 (axis): 数据从其它串流源(例如, 视频处理器或其它内核) 串流至内核中, 也可从该内核流出。
• 寄存器范例 (s_axilite): 内核通过寄存器接口来访问数据, 软件则通过寄存器读/写来访问数据。
Vitis 内核流程默认会实现下列接口: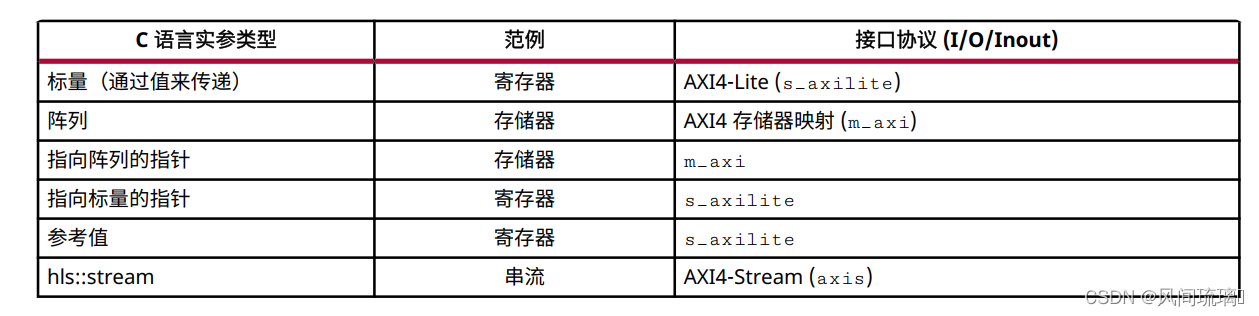
指向阵列的指针是作为 m_axi 接口(用于数据传输) 来实现的, 指向标量的指针则是使用 s_axilite接口来实现的。作为常量来传递的标量值不需要读取权限, 而指向标量值的指针则需要读取和写入权限。 s_axilite接口会根据 C 语言实参类型来实现一项额外的内部协议。此内部实现可使用 端口级 I/O 协议 来控制。
Vitis 内核流程的默认执行模式为流水打拍执行, 即启用内核的重叠执行以改善吞吐量。这是通过 s_axilite 接口上的 ap_ctrl_chain 块控制协议来指定的。
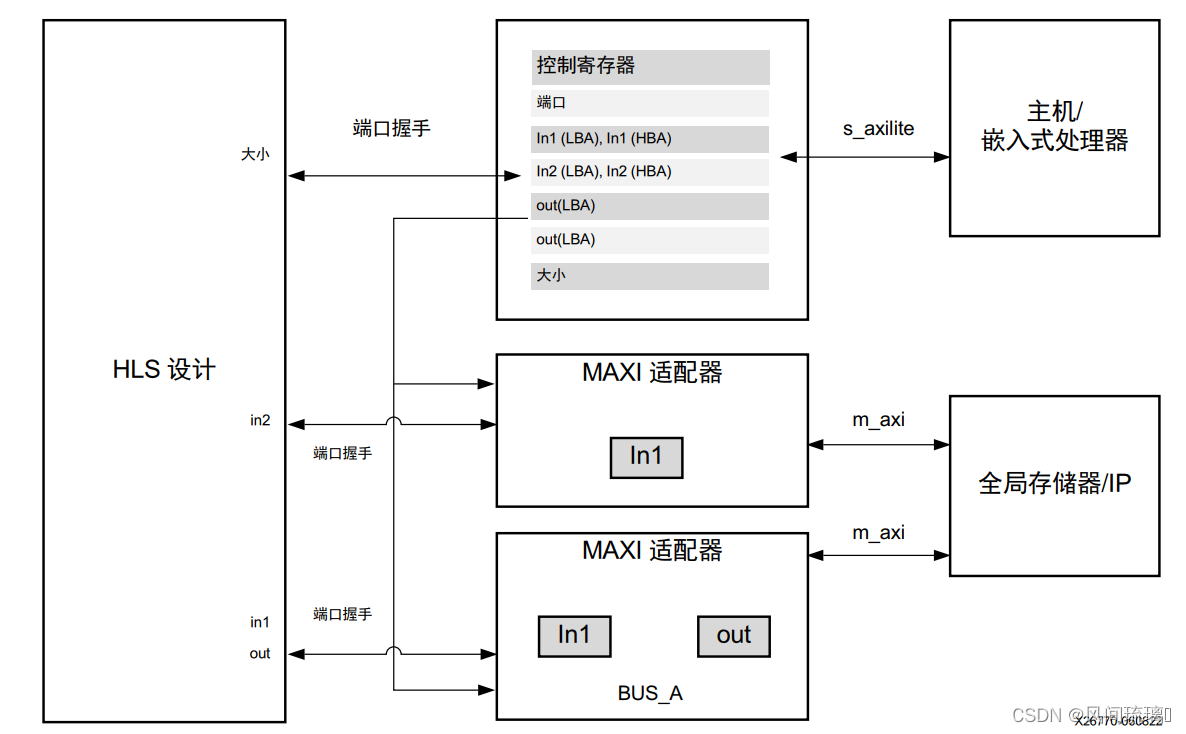
vivado ip上面同样的代码,如果 Vitis HLS 为 Vitis 内核流程使用默认接口综合设置, 那么设计将综合到含下图所示端口和接口的 RTL 块中。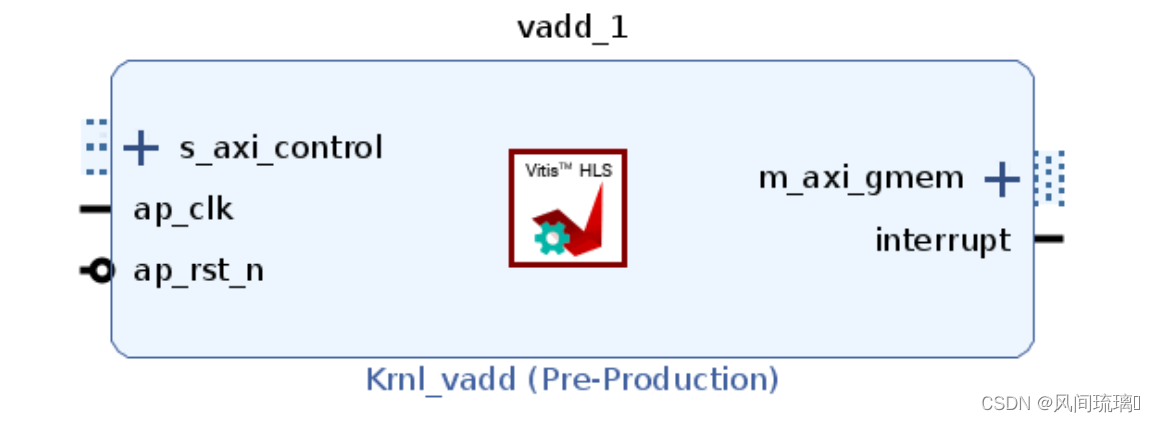
该工具会在 RTL 上创建三种类型的接口端口, 以处理数据流和控制流。
①时钟、复位和中断端口: 在内核中添加 ap_clk、 ap_rst_n 和 interrupt。
②AXI4-Lite 接口: s_axi_control 接口中包含标量实参(如 size) 、管理 m_axi 接口的地址偏移并定义块控制协
议。
③AXI4 存储器映射接口: m_axi_gmem 接口, 其中包含指针实参: in1、 in2 和 out_r。
三、AXI 接口协议
Vitis HLS 支持的 AXI4 接口包括 AXI4-Stream 接口 (axis)、 AXI4-Lite (s_axilite) 和 AXI4 主接口 (m_axi)。
m_axi: 仅在阵列和指针(以及 C++ 中的引用) 上指定。 m_axi 模式用于指定 AXI4 存储器映射接口。
s_axilite: 仅限在除串流外的任意类型的实参上指定此协议。 s_axilite 模式用于指定 AXI4-Lite 从接口。axis: 仅限在输入实参或输出实参上指定此协议, 而不得在输入/输出实参上指定。 axis 模式用于指定 AXI4-Stream 接口。
1.M_AXI
AXI4 存储器映射 (m_axi) 接口允许内核在全局存储器(DDR、 HBM 和 PLRAM) 中读取和写入数据, 存储器映射接口便于跨加速应用的不同元素进行数据共享。例如, 在主机与内核之间或者在加速器卡上的内核之间。
①M_AXI模式
M_AXI具有读/写地址通道, 可用于读/写特定地址。默认情况下, m_axi 接口会从地址0x00000000 启动所有读写操作。
m_axi 接口可作为发起传输事务的主接口, 也可以作为接收数据并发送确认的从接口。根据随 INTERFACE 编译指示的 offset 选项指定的模式, HLS IP 可使用多种方法来设置基址。
主模式:使用不同 offset 选项充当主接口时, m_axi 接口起始位置可采用硬编码
offset=off: 在 Vivado IP integrator 工具中使用 IP 时, Vitis HLS 会为 m_axi 接口设置基址。这种方法的缺点之一是在运行时间内无法更改基址。
offset=direct: Vitis HLS 会在 IP 上生成端口用于设置地址。它支持在运行时间更新地址, 即可通过同一个 m_axi 接口来读取和写入不同位置。
一个 HLS 模块用于将数据从 ADC 读取到 RAM 内, 另一个 HLS 模块则用于处理此数据。由于可更改模块上的地址, 因此当其中一个HLS 模块在处理初始数据集时, 另一个模块则可将更多数据读取到其它地址内。
从模式: 接口的从模式是使用 offset=slave 来设置的。在此模式下, IP 将由主机应用控制或者由微控制器通过s_axilite 接口来控制。这是 Vitis 内核流程的默认行为, 也可在 Vivado IP 流程中使用。以下是操作流程:
1. 初始情况下, 主机/CPU 将使用块级控制协议启动 IP 或内核, 此协议需映射到 s_axilite 适配器。
2. 主机将通过 s_axilite 适配器为 m_axi 接口发送标量和地址偏移。
3. m_axi 适配器将从 s_axilite 适配器读取起始地址, 并将其存储在队列中。
4. HLS 设计会开始从全局存储器读取数据。
HLS 设计将包含 s_axilite 适配器用于基址, 也包含 m_axi 用于对全局存储器执行读写传输。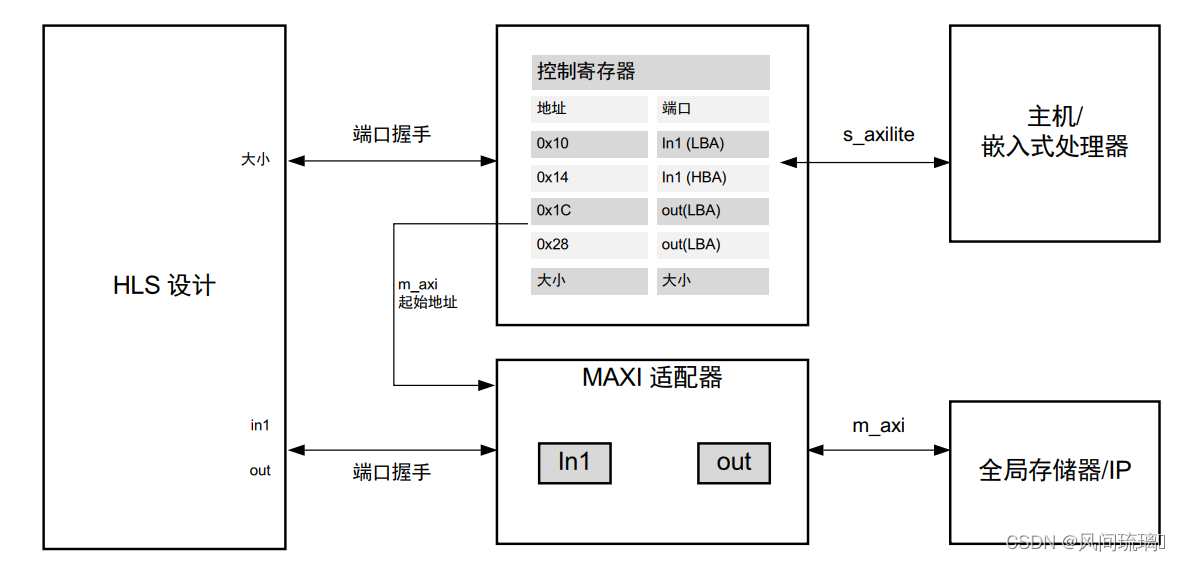
②偏移规则
a.完全指定偏移: 当用户显式设置偏移值时, 该工具会使用指定的设置。用户还可在设计中为不同 m_axi 接口设置不同偏移值(offset), 工具将使用指定的偏移。
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE mode=m_axi bundle=BUS_A port=out offset=direct
#pragma HLS INTERFACE mode=m_axi bundle=BUS_B port=in1 offset=slave
#pragma HLS INTERFACE mode=m_axi bundle=BUS_C port=in2 offset=offb.不指定偏移: 如果在 INTERFACE 编译指示中未指定任何偏移, 那么该工具将遵从config_interface -m_axi_offset 指定的设置。
要应用地址偏移, 使用offset 选项与 INTERFACE 指令搭配使用, 并指定以下选项之一:
• off: 不应用偏移地址。这是默认方式。
• direct: 向设计添加 32 位端口以应用地址偏移。
• slave: 在 AXI4-Lite 接口内添加 32 位寄存器以应用地址偏移。
在最终 RTL 中, Vitis HLS 会将地址偏移直接应用于 AXI4 主接口生成的任意读取地址或写入地址。这样即可允许设计访问系统中的任意地址位置。
如果在 AXI 接口中使用 slave 选项, 则必须在设计接口上使用 AXI4-Lite 端口。并且如果使用 slave 选项并使用多个 AXI4-Lite 接口, 则必须确保 AXI 主端口偏移寄存器已与正确的 AXI4-Lite 接口捆绑。
端口 a 作为含偏移和 AXI4-Lite 接口(名为 AXI_Lite_1 和 AXI_Lite_2) 的 AXI 主接口来实现:
#pragma HLS INTERFACE mode=m_axi port=a depth=50 offset=slave
#pragma HLS INTERFACE mode=s_axilite port=return bundle=AXI_Lite_1
#pragma HLS INTERFACE mode=s_axilite port=b bundle=AXI_Lite_2以下 指令是确保端口 a 的偏移寄存器与名为 AXI_Lite_1 的 AXI4-Lite 接口捆绑所必需的:
#pragma HLS INTERFACE mode=s_axilite port=a bundle=AXI_Lite_1③M_AXI捆绑
Vitis HLS 会将具有兼容选项的函数实参组合到单个 m_axi 接口适配器中。将端口捆绑到单个接口中有助于通过消除AXI 逻辑来节省 FPGA 资源, 但它可能限制内核性能, 因为所有存储器传输都必须经过同一个端口。
m_axi 接口具有独立的读取 (READ) 和写入 (WRITE) 通道, 因此单个接口即可同时执行读取和写入, 但仅限单一位置。使用多个捆绑会创建多个接口来连接到多个存储体, 故而会导致内核带宽和吞吐量增加。
示例:所有指针实参都使用接口选项 bundle=BUS_A 组合到单个 m_axi 适配器中, 并为 m_axi 偏移、标量实参 size 和函数返回添加单个 s_axilite 适配器。
extern "C" {
void vadd(const unsigned int *in1, // Read-Only Vector 1
const unsigned int *in2, // Read-Only Vector 2
unsigned int *out, // Output Result
int size // Size in integer
) {
#pragma HLS INTERFACE mode=m_axi bundle=BUS_A port=out
#pragma HLS INTERFACE mode=m_axi bundle=BUS_A port=in1
#pragma HLS INTERFACE mode=m_axi bundle=BUS_A port=in2
#pragma HLS INTERFACE mode=s_axilite port=in1
#pragma HLS INTERFACE mode=s_axilite port=in2
#pragma HLS INTERFACE mode=s_axilite port=out
#pragma HLS INTERFACE mode=s_axilite port=size
#pragma HLS INTERFACE mode=s_axilite port=return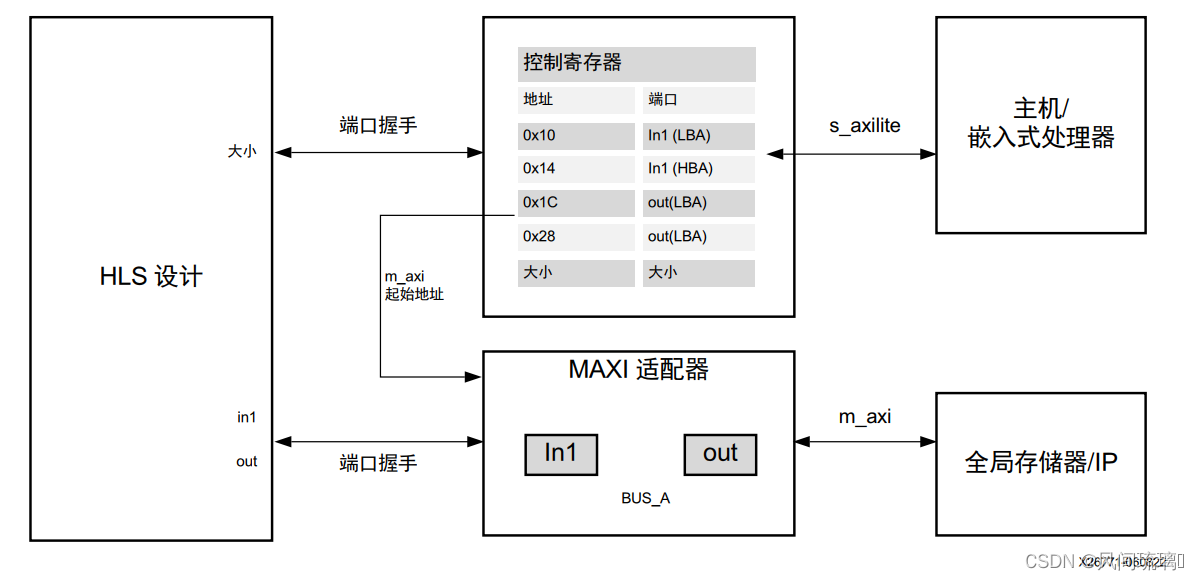
若实参 in2 通过 bundle=BUS_B 组合到独立的接口适配器内。这样会为端口 in2 创建新的 m_axi 接口适配器。
捆绑规则
a.默认捆绑名称:该工具将不含捆绑名称的所有接口端口都组合到单个 m_axi 接口端口内, 并使用工具默认名称bundle=<default>, 将 RTL 端口命名为 m_axi_<default>。
b.用户指定的捆绑名称: 该工具会将具有相同用户指定的 bundle=<string> 的所有接口端口都组合到同一个m_axi 接口端口中, 并以 m_axi_<string> 指定的值来命名 RTL 端口。未分配 bundle 的端口则组合到默认捆绑中, 如上所述。
④M_AXI资源
AXI 主适配器用于将自定义的 AXI 命令从 HLS 调度器转换为标准 AXI AMBA 协议, 并将其发送至外部存储器。 MAXI适配器使用 FIFO 等资源来存储请求/数据和确认 (ack)。以下提供了它所耗用的模块和资源综述:
①写入模块: 总线写入模块负责执行写入操作。
②读取模块: 这些模块负责执行读取操作。
M_AXI 适配器的器件资源耗用量是所有写入模块(FIFO_wreq module 模块、 buff_wdata、和 FIFO_ resp 的大小) 总和与所有读取模块总和相加所得。FIFO 大小的计算方式为“宽度 * 深度”。
⑤AXI4突发行为
突发是一种最优化方式, 它会尝试以智能方式聚集对 DDR 的存储器访问操作, 以便尽可能提升吞吐量带宽和/或减小时延。突发是可对内核执行的诸多最优化操作之一。突发通常可以实现 4 到 5 倍的提升, 而其它最优化(访问拓宽或者确保不存在通过 DDR 的依赖关系) 甚至可提供更大的性能提升。通常 DDR 端口上存在争用(源于多个相互竞争的内核) 时, 适合使用突发。
AXI4 协议的突发功能特性能够通过在单个请求内在全局存储器上读取/写入多个数据块来提升加载存储功能的吞吐量。数据越大, 吞吐量越高。这种指标的计算方式如下: ((传输的字节数) * (内核频率)/(时间))。最大内核接口位宽为 512位, 如果内核编译为按 300 MHz 频率运行, 那么理论上每个 DDR 可达成 (512* 300 MHz)/1 秒 = ~17 GB/s。
当设计在等待访问总线时, 从不会在最优化 AXI4 接口上停滞, 授予总线访问后, 总线等待设计执行读/写时从不停滞。为创建最优化 AXI4 接口, 在 INTERFACE 编译指示或指令中提供了以下选项以指定突发的行为并最优化 AXI4 接口的效率。
其中部分选项使用内部存储空间来缓冲数据, 并且可能影响面积和资源:
①latency: 指定 AXI4 接口的期望时延, 允许设计发起总线请求的时间比执行期望的读取或写入操作早数个周期(时延) 。如果该值太低, 设计将过早达成就绪状态, 可能停滞并等待总线; 如果该值太高, 则可能授予总线访问权时, 总线仍处于停滞状态并等待设计发起访问。
②max_read_burst_length: 指定突发传输期间读取的数据值的最大数量。
③num_read_outstanding: 指定在设计停滞前可对 AXI4 总线发出的读取请求的数量。设计中的内部存储空间, 即 FIFO 大小为: num_read_outstanding*max_read_burst_length*word_size。
④max_write_burst_length: 指定突发传输期间写入的数据值的最大数量。
⑤num_write_outstanding: 指定在设计停滞前可对 AXI4 总线发出的写入请求的数量。设
计中的内部存储空间, 即 FIFO 大小为: num_read_outstanding*max_read_burst_length*word_size
2.S_AXILITE
主机应用或嵌入式处理器可使用 AXI4-Lite 从接口 (s_axilite) 对 HLS IP 或内核进行控制, 该接口充当系统总线, 用于处理器与内核之间通信。主机或嵌入式处理器可使用 s_axilite 接口启动和停滞内核, 以及对内核进行数据读取或写入。当 Vitis HLS 对设计进行综合时, s_axilite 接口是作为适配器来实现的, 用于捕获来自适配器上的寄存器中的主机的通信信息。
AXI4-Lite 接口在 Vivado IP 或 Vitis 内核中执行多项功能:
①它可映射用于启动和停滞内核的块级控制机制。
②它可提供通道, 用于将 m_axi 接口的标量实参、指向标量值的指针、函数返回值和地址偏移从主机传递到 IP 或内核。
在 Vitis 内核流程:将自动推断 s_axilite 接口编译指示, 以向分配给 m_axi 接口的指针实参、标量值和函数返回类型提供偏移。
如果指向标量值的指针分配给 s_axilite 接口, 那么 Vitis HLS 允许您在该指针上执行读取或写入。指针默认分配给 m_axi 接口, 可以使用 INTERFACE 编译指示或指令将该指针手动分配给 s_axilite。
将多个实参(包括函数返回) 作为 s_axilite 接口来实现的方式。由于针对 bundle 选项每条编译指示都使用相同名称, 因此每个端口都分组到单个接口中。
void example(char *a, char *b, char *c)
{
#pragma HLS INTERFACE mode=s_axilite port=return bundle=BUS_A
#pragma HLS INTERFACE mode=s_axilite port=a bundle=BUS_A
#pragma HLS INTERFACE mode=s_axilite port=b bundle=BUS_A
#pragma HLS INTERFACE mode=s_axilite port=c bundle=BUS_A
#pragma HLS INTERFACE mode=ap_vld port=b
*c += *a + *b;
}综合后的示例将作为系统的一部分, 该系统具有 3 个重要元素, 如下图所示:
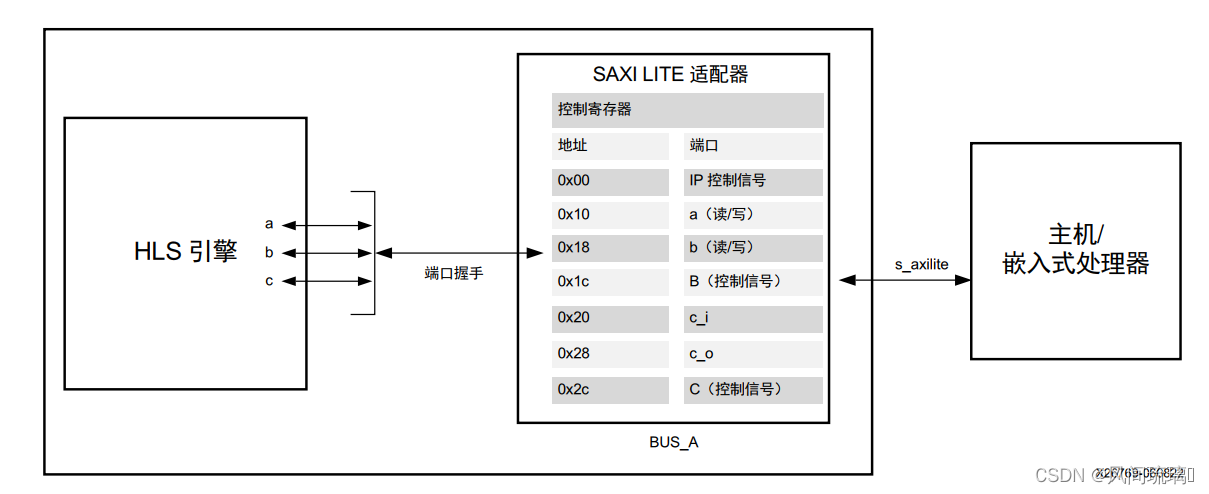
1. 与 IP 或内核交互的 x86 或嵌入式处理器上运行的主机应用
2. SAXI Lite Adapter: INTERFACE 编译指示用于实现 s_axilite 适配器。该适配器具有 2 个主要函数: 用于实现接口协议以便与主机进行通信, 并向 IP 或内核提供控制寄存器映射。3. 实现设计逻辑的 HLS 引擎或函数
在操作中, 主机应用将通过写入控制地址空间 (0x00) 来初始启动内核。主机/CPU 通过写入其它地址空间来完成初始设置, 这些地址空间与示例中定义的各函数实参相关联。
①S_AXILITE控制寄存器映射
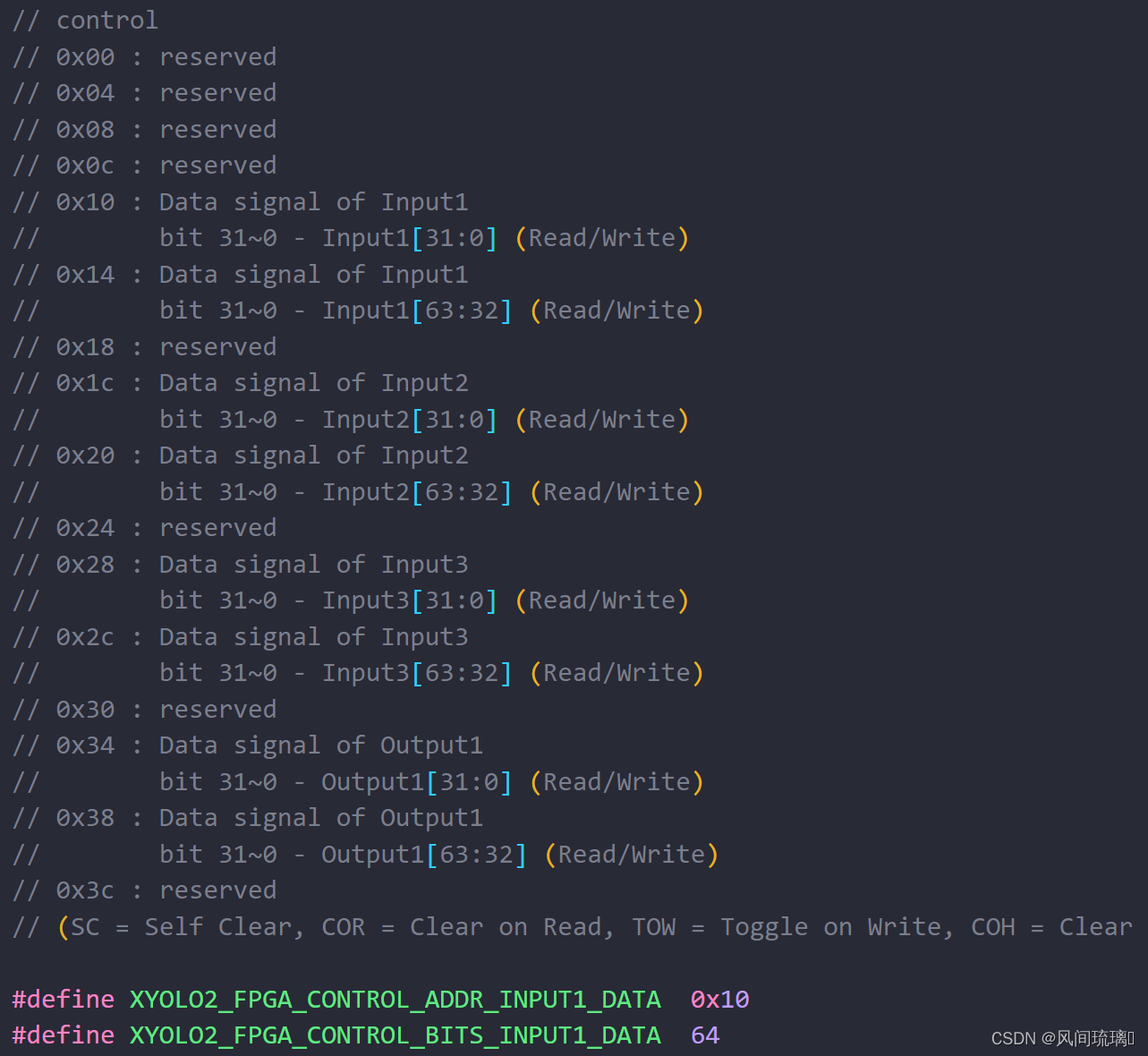
Vitis HLS 会在 S_AXILITE 控制寄存器映射 中报告分配的地址, 并在 C 语言驱动程序文件 中提供这些地址以辅助进行软件开发。
可使用 s_axilite 接口以利用 C 语言驱动程序文件, 通过使用提供的应用编程接口 (API) 函数, 可将这些文件搭配嵌入式或 x86 处理器上运行的代码来一起使用, 以便通过自己的软件来控制硬件。
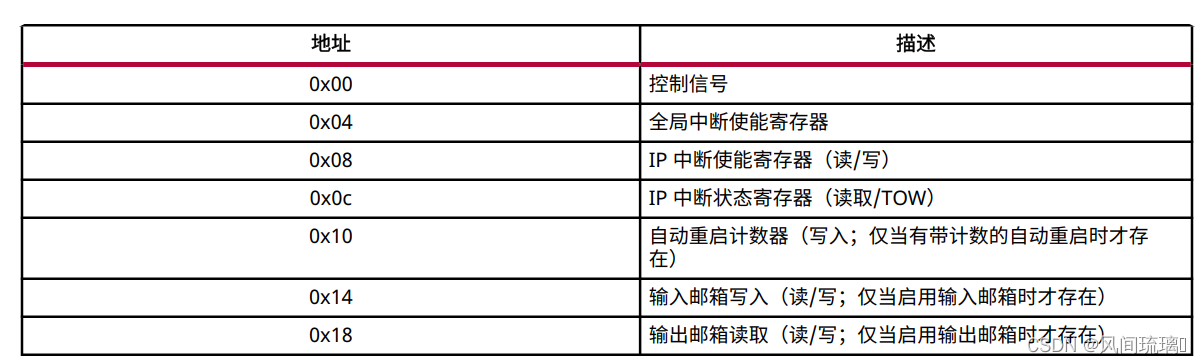
Vitis HLS 会自动生成控制寄存器映射 (Control Register Map) 用于控制 Vivado IP 或 Vitis 内核以及组合到 s_axilite接口中的各端口。此寄存器映射会被添加到生成的 RTL 文件中, 并且可拆分为两部分:
①块级控制信号
②映射到 s_axilite 接口内的函数实参
在控制寄存器映射中, Vitis HLS 会保留地址 0x00 到 0x18 用于顶层协议控制、中断控制、邮箱控制和自动重启控制。
②S_AXILITE端口级协议
端口级 I/O 协议将来自 s_axilite 适配器的数据按顺序输入输出 HLS 引擎,在 Vitis 内核流程中,一般不更改默认端口级 I/O 协议。该工具会根据与端口关联的实参的类型和方向来向端口分配默认端口协议。端口可包含以下一个或多个对象:
①实参的数据信号
②有效信号 (ap_vld/ap_ovld), 用于指示何时数据可供读取
③确认信号 (ap_ack), 用于指示何时已读取数据
各实参类型的默认端口协议分配如下: 注意:数组向量默认采用 ap_memory。
注意:数组向量默认采用 ap_memory。
上面的示例中,若将端口 b 组合到 s_axilite 接口内并将端口 b 指定为搭配 INTERFACE 编译指示使用 ap_vld 协议。所以, s_axilite 适配器包含用于端口 b 的数据的寄存器和用于端口 b 的输入有效信号的寄存器。
如果输入有效寄存器未设置为逻辑 1, b 数据寄存器中的数据将不会被视为有效, 设计将停滞并等待有效寄存器完成置位。每次读取端口 b 时, Vitis HLS 都会自动清除输入有效寄存器, 并将该寄存器复位为逻辑 0。为简化设计操作, 一般使用与 s_axilite 接口关联的默认端口协议。
③S_AXILITE 捆绑规则
s_axilite 接口捆绑规则:
a.默认捆绑名称: 此规则将不含捆绑名称的所有接口端口都显式组合到同一个 AXI4-Lite 接口端口中, 并使用工具默认捆绑名称, 通常将 RTL 端口命名为 s_axi_<default>( s_axi_control) 。
#pragma HLS INTERFACE mode=s_axilite port=ab.用户指定的捆绑名称: 此规则将具有相同 bundle 名称的所有接口端口都显式组合到同一个 AXI4-Lite 接口端口中, 并以 s_axi_<string> 指定的值来命名 RTL 端口。
#pragma HLS INTERFACE mode=s_axilite port=a bundle=BUS_Aa端口生成的接口名为 s_axi_BUS_A。
c.部分指定的捆绑名称: 如果部分实参指定 bundle 名称, 但其它实参则保留不分配, 那么该工具会按如下方式来捆绑这些实参:
①按 INTERFACE 编译指示的要求将所有端口组合到指定捆绑内。
②将不含捆绑分配的所有端口都组合到一个采用默认命名的捆绑内。
④S_AXILITE C 语言驱动程序文件
当实现 AXI4-Lite 从接口时, 会自动创建一组 C 语言驱动程序文件。这些 C 语言驱动程序文件可提供一组 API 以集成到 CPU 上运行的任意软件中, 并且这些 API 可用于通过 AXI4-Lite 从接口与器件进行通信。这些 C 语言驱动程序文件是在 IP 目录中将设计封装为 IP 时创建的。
针对独立模式和 Linux 模式会创建驱动程序文件。在独立模式下, 驱动程序的使用方式与任何其它赛灵思独立驱动程序的使用方式并无不同。在 Linux 模式下, 会将所有 C 语言文件 (.c) 和头文件 (.h) 都复制到软件工程中。
驱动程序文件和 API 函数的名称衍生自综合的顶层函数。驱动程序文件是在封装的 IP 内创建的(位于solution 内的 impl 目录中) 。若顶层函数称为“example”。名为“Example”的设计的 C 语言驱动程序文件
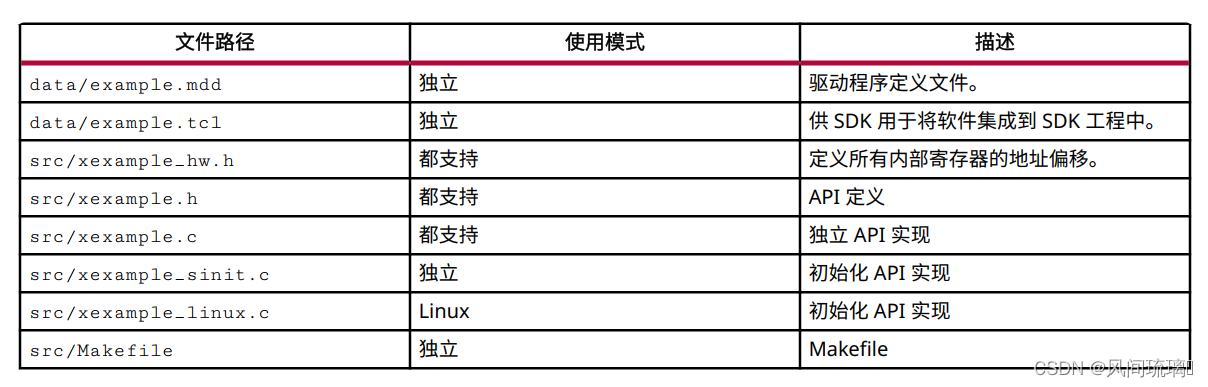
注意:若顶层函数名为“DUT” , 那么在以下描述中名称“example”将被替换为“DUT”。
在 xexample.h 文件中定义了 2 个结构体
XExample_Config: 用于保存 IP 实例的配置信息(每个 AXI4-Lite 从接口的基址)
XExample: 用于保存 IP 实例指针,大部分 API 使用此实例指针作为首个实参。
标准 API 实现在文件 xexample.c、 xexample_sinit.c 和 xexample_linux.c 中提供, 可提供用于以下操作的函数
①初始化器件
②控制器件并查询其状态
③读写寄存器
④设置、监测和控制中断
硬件头文件 xexample_hw.h 提供了存储器映射位置完整列表。
在 CPU 上运行的软件中可使用 API 函数来控制硬件块,此进程概述为:
①创建硬件实例
②查找器件配置③初始化器件
④设置 HLS 块的输入参数
⑤启动器件并读取结果
⑤S_AXILITE 时钟和复位
默认情况下, Vitis HLS 针对 AXI4-Lite 接口和已综合的设计使用相同时钟。 Vitis HLS 将 AXI4-Lite 接口中的所有寄存器都连接到用于综合逻辑的时钟 (ap_clk)。
使用 INTERFACE 指令 clock 选项来为每个 AXI4-Lite 端口指定独立的时钟。将时钟连接到 AXI4-Lite 接口时, 必须使用以下协议:
①AXI4-Lite 接口时钟必须同步到用于综合逻辑的时钟 (ap_clk)。这 2 个时钟必须衍生自同一个主生成器时钟
②AXI4-Lite 接口时钟频率必须等于或小于用于综合逻辑的时钟 (ap_clk) 的频率
如果将 clock 选项与 INTERFACE 指令搭配使用, 那么只需针对每个捆绑中的 1 个函数实参指定 clock 选项即可。Vitis HLS 通过相同的时钟和复位来实现捆绑中的所有其它函数实参。
示例:将函数实参 a 和 b 组合到同一个 AXI4-Lite 端口内, 且该端口含名为 AXI_clk1 的时钟
和关联的复位端口。
#pragma HLS interface mode=s_axilite port=a clock=AXI_clk1
#pragma HLS interface mode=s_axilite port=bVitis HLS 以 ap_rst_ 作为前缀并后接时钟名称的方式来对生成的复位信号命名。生成的复位信号处于低电平有效状态, 与 config_rtl 命令无关。
3.AXIS
AXI4-Stream 接口可应用于任意输入实参和任意阵列或指针输出实参。由于 AXI4-Stream 接口按顺序串流方式来传输数据, 因此不可用于同时支持读写的实参。
就数据布局而言, AXI4-Stream 的数据类型会对齐到下一个字节。如果数据类型大小为 12 位, 则将扩展至 16 位。根据选择的是有符号接口还是无符号接口, 扩展的位将采用符号位扩展或零位扩展。
四、端口级 I/O 协议
默认情况下, 输入指针和按值传递 (pass-by-value) 实参作为简单的线型端口(只含数据端口)来实现, 无关联的握手信号。默认输出指针实现时含关联的输出有效信号, 用于指示何时输出数据有效。
同时支持读取和写入的函数实参将拆分为独立的输入端口和输出端口,在 vadd 函数示例中, out_r 实参是作为输入端口 out_r_i 和输出端口 out_r_o 来实现的, 并具有关联的 I/O 协议端口 out_r_o_ap_vld。
如果函数具有返回值, 则实现输出端口 ap_return 以提供返回值。当 RTL 设计完成 1 项传输事务时(等同于执行 1次 C/C++ 语言函数), 块级协议会以 ap_done 信号来表明函数已完成。这也表示 ap_return 端口上的数据有效且可读。
1.无协议
ap_none 指定不向端口添加任何 I/O 协议。指定该选项时, 实参作为不含任何其它关联信号的数据端口来实现。ap_none 模式是标量输入的默认模式。
ap_none 端口级 I/O 协议是最简单的接口类型, 没有与之关联的其它信号。输入和输出数据信号都没有关联的控制端口以指示何时读取或写入数据。 RTL 设计中仅有的端口是源代码中指定的端口。
ap_none 接口无需额外硬件开销。但是ap_none 接口需满足以下条件:
• 生产者块执行以下操作之一:
○ 在正确的时间向输入端口提供数据, 通常是在设计开始之前提供。
○ 在执行传输事务期间保留数据, 直到设计发出 ap_ready 信号为止。
• 设计完成时, 使用者块会在设计重新启动之前读取输出端口。
注: ap_none 接口不能与阵列实参一起使用。
2.有线握手
接口模式 ap_hs 包含与数据端口的双向握手信号。此握手属于业界标准的有效和确认握手。但ap_vld 模式仅含有效端口, ap_ack 仅含确认端口。
ap_ovld 模式用于输入输出实参。将输入输出拆分为独立输入端口和输出端口时, ap_none 模式适用于输入端口,ap_vld 适用于输出端口。
ap_hs 模式可应用于按顺序读写的阵列。如果 Vitis HLS 可判定读访问或写访问为无序访问, 它将停止综合并报错。如果无法判定访问顺序, Vitis HLS 将发出警告。
ap_hs(ap_ack、 ap_vld 和 ap_ovld)
ap_hs 端口级 I/O 协议在开发过程中提供了最大的灵活性, 允许采用自下而上和自上而下的设计流程。双向握手可安全执行所有块内通信, 无需人为干预或假设即可正确执行。 ap_hs 端口级 I/O 协议提供以下信号:
• 数据端口
• 用于指示数据信号有效并且可读的有效信号
• 用于指示何时已读取数据的确认信号
ap_ack:用于指示何时使用数据的确认信号
ap_vld:用于指示数据信号有效并且可读的有效信号
ap_ovld:用于指示数据信号有效并且可读的有效信号
3.存储器接口协议
默认情况下, 阵列实参作为 ap_memory 接口来实现。这是含数据、地址、芯片使能和写使能端口的标准块 RAM 接口。
ap_memory 和 bram 接口端口级 I/O 协议用于实现阵列实参。当实现要求随机访问存储器地址位置时, 这种类型的端口级 I/O 协议可以与存储器元件(RAM 和 ROM) 通信。如果只需顺序访问存储器元件, 请改用 ap_fifo 接口。 ap_fifo 接口可以减少硬件开销, 因为不执行地址生成。
ap_fifo:写入输出端口时, 当设计需要访问存储器元件并且访问始终以顺序方式执行时, 即不需要随机访问, 则与其关联的输出valid 信号接口是最节省硬件的方法。适用于阵列、指针和按引用传递实参类型。
五、块级控制协议
Vitis 内核或 Vivado IP 的执行模式是由块级控制协议来指定的。内核的执行模式包括:
• 流水打拍执行 (ap_ctrl_chain), 允许重叠的内核运行在内核准备就绪后立即开始处理其它数据。
• 顺序执行 (ap_ctrl_hs), 要求内核在完成一个周期后再开始另一个周期。
• 数据驱动的执行 (ap_ctrl_none), 支持内核在数据可用时运行, 并在数据不可用时停滞。
















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











