







- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
在计算机视觉领域,目标检测一直是一个备受关注的研究方向。而YOLO(You Only Look Once)系列是目标检测领域的里程碑式工作之一,本文将深入分析YOLOv1-v3论文,探讨其实现思路和技术细节,帮助读者更好地理解这一算法的核心原理。
一、YOLOv1
YOLOv1是一种端到端的目标检测方法,其核心思想是将目标检测任务视为回归问题,同时预测目标的类别和位置信息。与传统的两阶段目标检测方法(如R-CNN系列)不同,YOLOv1采用单一的卷积神经网络(CNN)来实现端到端的目标检测。以下是YOLOv1的一些关键特点和组成部分:
1.1 论文思想

(1)如上图将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
(2)每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。 每个网格还要预测C个类别的分数。
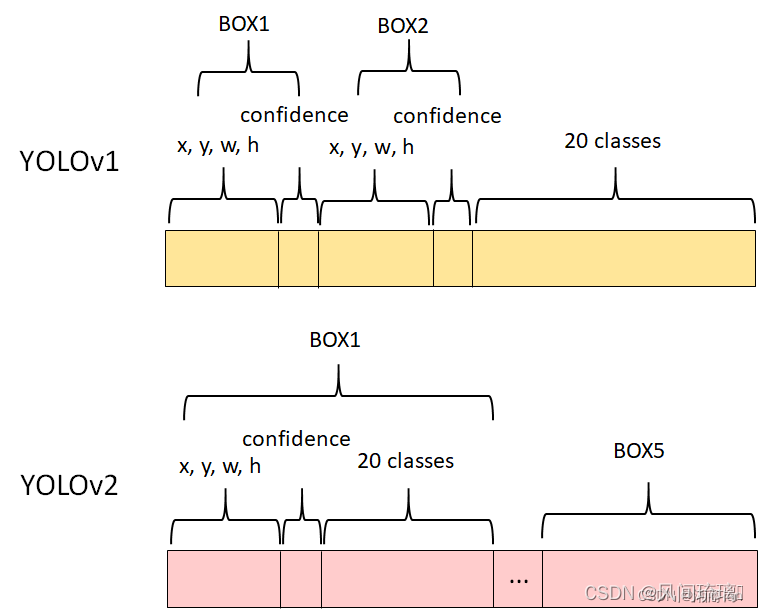
所以,使用PASCAL VOC数据集,其有20个分类,在YOLOv1中,S=7,B=2,网络的最终输出为7x7x30。
1.2 论文关键点
1.2.1 网络结构
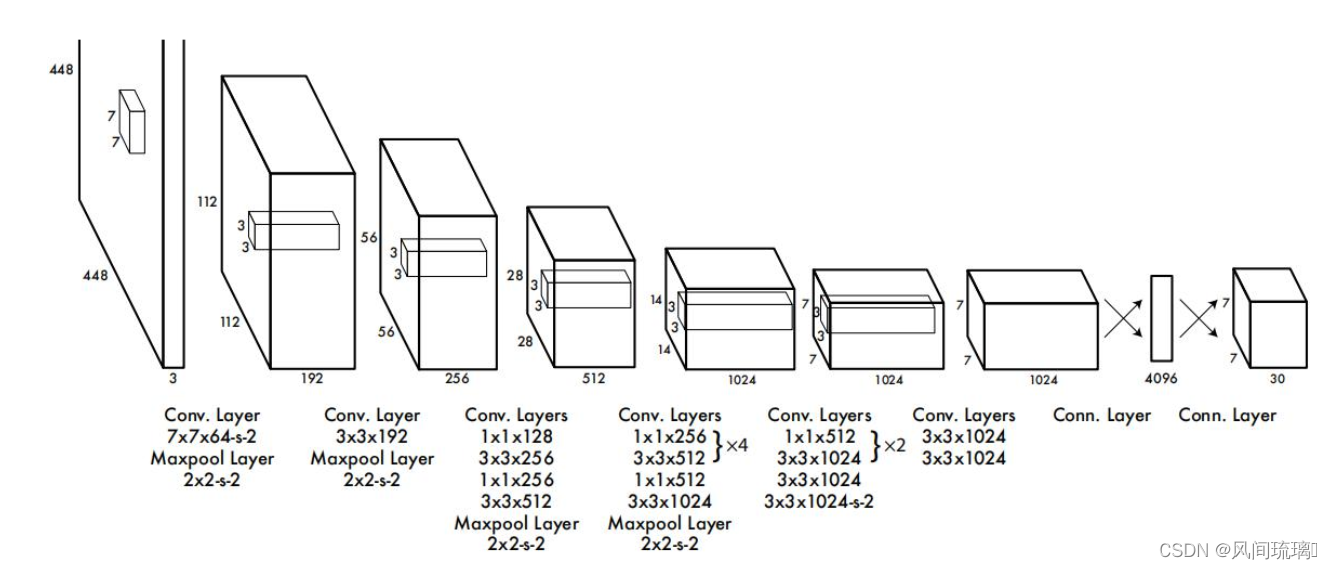
YOLOv1的网络结构由卷积神经网络(CNN)组成,包括24个卷积层和2个全连接层。这个网络被设计成端到端的目标检测模型,通过单次前向传播即可同时预测目标的类别和位置。
YOLOv1的输入层接受固定尺寸的图像作为输入。在原始论文中,作者使用了448x448像素的输入图像,这些图像经过标准化处理后输入网络。在预训练分类阶段输入大小: 224x224,但是在检测训练阶段输入大小: 448x448。
接下来的卷积层用于提取输入图像的特征。这些卷积层构成了一个深度的卷积神经网络,负责捕捉图像的语义信息。网络结构中的卷积核大小、深度和步幅都是经过精心设计的,以便在不同层次捕获不同尺度的特征。
在YOLOv1的网络结构中,最后一个卷积层之前加入了一个1x1卷积层。这个1x1卷积层的主要作用是调整特征图的通道数,以适应不同尺度的目标检测。通过这个层,YOLOv1能够同时检测小物体和大物体,提高了模型的鲁棒性。
最后两层是全连接层,负责生成目标检测的输出。这两个全连接层将卷积层的输出映射到一个固定维度的向量,包括目标的位置信息和类别概率。每个网格单元都会输出一个这样的向量,从而实现目标的密集预测。
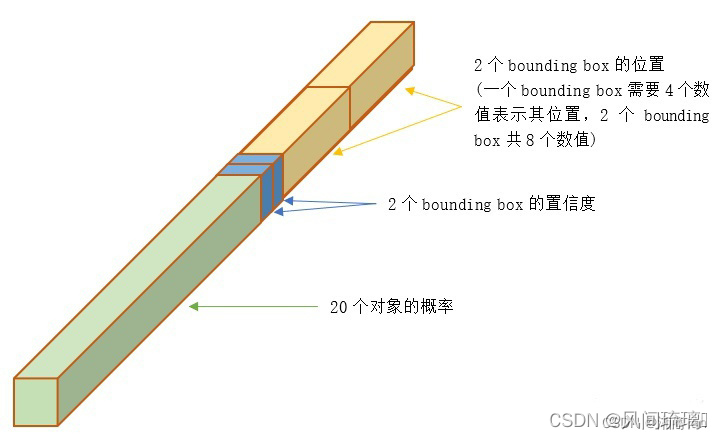
我们来看看最终生成目标数据: 7x7x30:

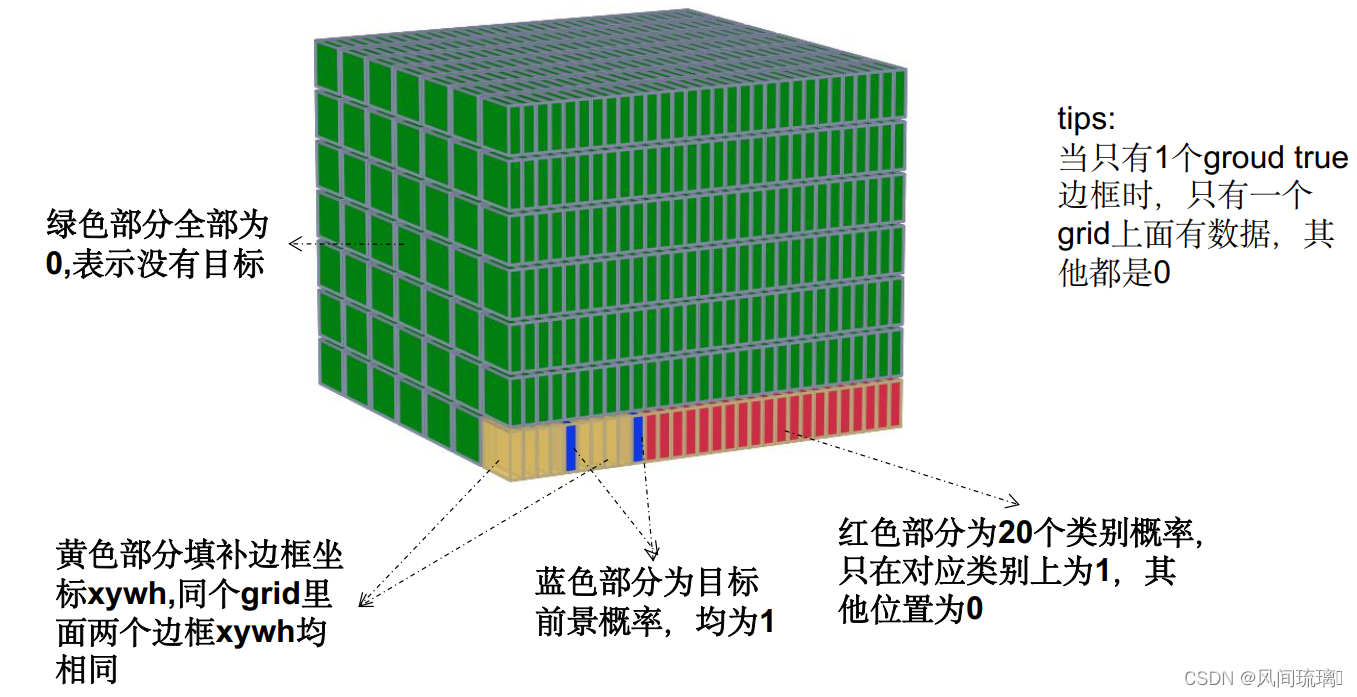
1.xy表示预测边框的中心点,它是相对于当前grid坐标的偏移量。
2.width,heigh表示预测边框的宽高。
3.confidence表示预测的边框是否包含目标
4.P(Cat|Object)...表示当对应边框包含目标,该目标对应类别的概率
最终预测:
1. 7x7x2x4个边框坐标(7x7个格子,每个格子预测2个边框,每个边框包含xywh)
2. 7x7x2个前景目标概率(每个边框都要计算confidence)3. 7x7x20个类别概率(voc2012数据为20个类别)
1.2.2 损失函数

损失函数的每一项都是平方和误差,将目标检测问题当作回归问题。YOLOv1的损失函数由三个主要部分组成,它们分别是位置误差、目标置信度误差和类别误差。这些误差项用于衡量模型预测与真实目标之间的差距,通过最小化这些误差项来训练模型。
符号说明:
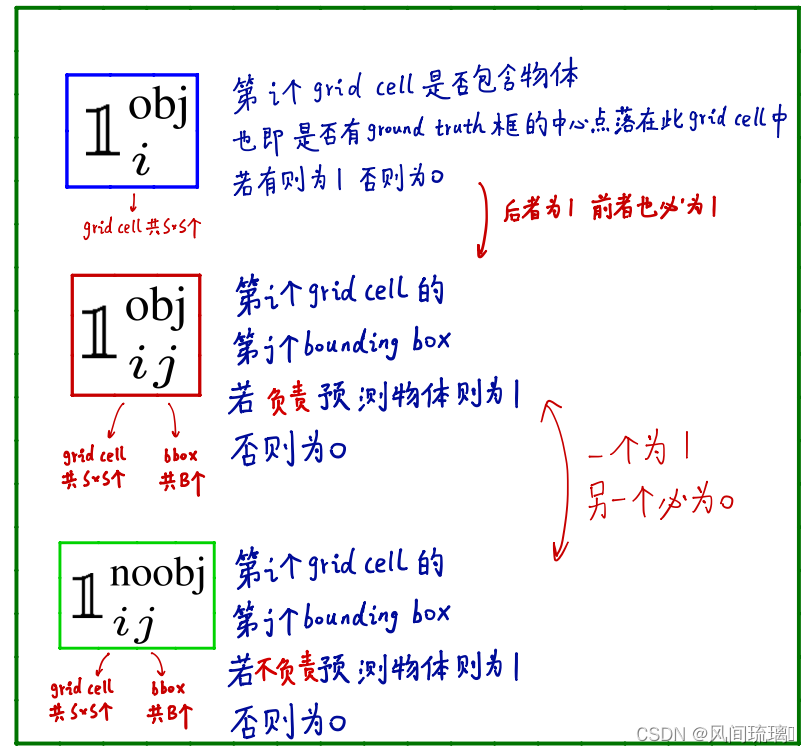
(1)位置误差

1.λ=5是为了平衡负样本跟正样本比例不均衡问题
2.xywh预测损失计算均采用mae平方差3.由于一个grid会预测两个边框, 实际上计算损失的时候只会选择其中一个跟真实边框iou较高的那个做计算。
这两步都是在遍历所有grid cell的所有bounding box,第一项是负责检测物体的 bounding box中心点定位误差;第二项是负责物体的bounding box宽高定位误差,求根号是为了使小框对误差更敏感。
(2) 目标置信度误差

第一项负责检测 bounding box的confidence误差,其标签值为1
第二项是不负责检测物体的bounding box的confidence误差,其标签值为0
(3)类别误差

负责检测物体的grid cell分类误差,Pi(C)里只有对应类别的概率为1, 其他为0
YOLOv1的目标检测流程可以分为以下几个步骤:
输入处理:将输入图像调整为固定大小,并将其划分为网格。
特征提取:通过卷积神经网络提取图像的特征。
目标预测:对每个网格单元进行目标检测,包括目标的边界框和类别。
非极大值抑制:对于每个类别,使用非极大值抑制来去除重叠的边界框,保留置信度最高的边界框。
输出结果:输出检测到的目标边界框和类别。
二、YOLOv2
YOLOv2(You Only Look Once Version 2)是YOLO系列目标检测算法的第二代版本,由Joseph Redmon和Ali Farhadi于2016年提出。YOLOv2在YOLOv1的基础上进行了改进,提高了检测速度和准确性,成为目标检测领域的一项重要工作。
yolov2改进点:
1.Batch Normalization(批归一化)
2.High Resolution Classifier(高分辨率的分类器,提高输入数据分辨率)
3.Fine-Grained Features(细粒度特征,高低维特征融合)
4.Multi-Scale-Training(多尺度训练策略)
5.Anchor Box(预测边框引入anchor机制)
6.Dimension Cluster(维度聚类,采用kmeans聚类得到先验框)
7.Direct location prediction(直接位置预测)
2.1 网络架构(Darknet19)
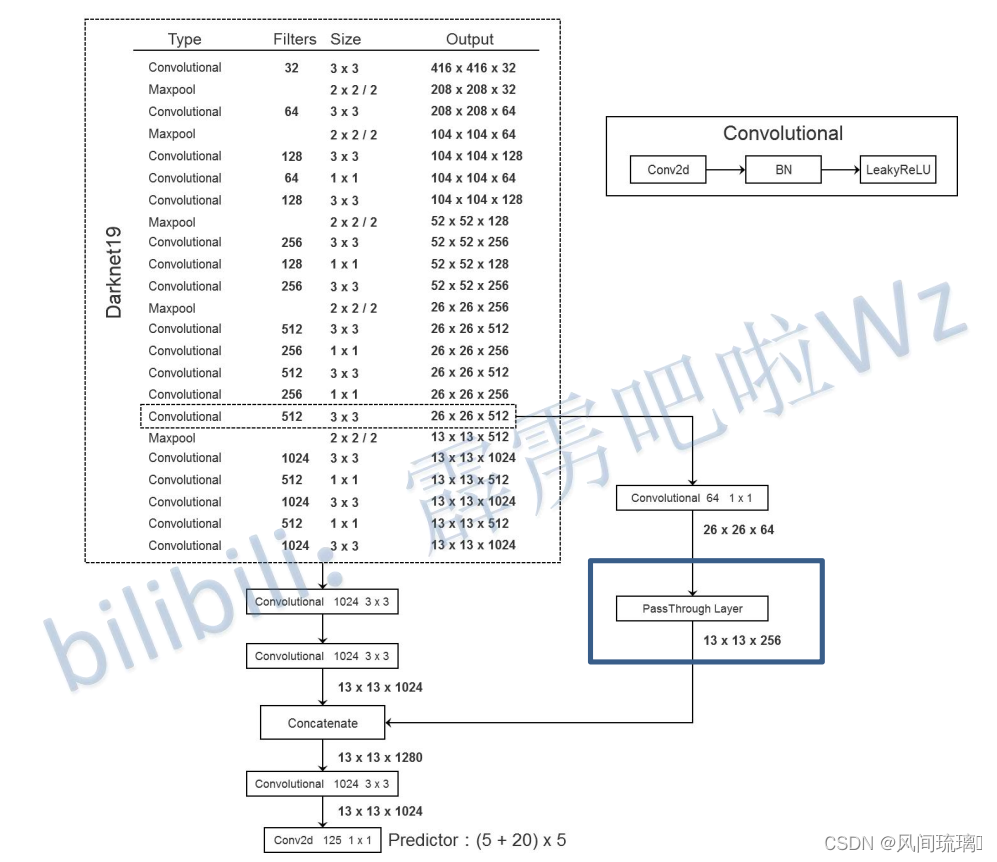
YOLOv2 采用Darknet-19 作为特征提取网络,包括19个卷积层, 5个 maxpooling 层。
1.yolov2采用Darknet-19,使用global avgpooling做预测。输入数据采用416x416,因为它是32的倍数,并且还是奇数倍,会有一个中心,为了特征图都有奇数大小的宽和高,奇数大小的宽和高会使得每个特征图在划分cell的时候就只有一个中心cell。因为大的目标一般会占据图像的中心,所以希望用一个中心cell去预测,而不是4个中心cell。
2.没有FC层,全连接层参数多,容易过拟合,网络中5次下采样完成尺度变换
3.在3x3卷积层之间使用1x1卷积层来压缩 feature map channles 以降低模型计算量和参数 (parameters)。4.每个卷积层后面同样使用了 batch normalization 层(取代Dropout层)以加快收敛速度,降低模型over-fitting。
2.2 High Resolution Classifier
因为大部分的检测模型是使用 ImageNet 分类数据集上pre-train的模型,YOLOv1 采用 224x224 的图片分类器,但因为分辨率比较低,不利于检测模型。因此YOLO2 提高分辨率至 448x448 并在test数据集上进行 fine-tuning(微调)。
先采用 224x224 的 ImageNet 图像数据集进行约160个 epoch的训练,然后再将输入图像的尺寸更改为 448x448 再训练10个 epoch。训练完的这个 pre-train model也就可以适用高分辨率的图像输入了。最后再拿这个model 在test数据集上 fine-tuning。
2.3 Fine-Grained Features
随着网络的层数的增加,卷积层会逐渐减小空间维度,感受野会增大,但是随着相应分辨率的降低,也就更难检测到小物体。
YOLOv2 图片输入大小为 416 x 416,经过5次 maxpooling 后得到13x13 的feature map,并以此 feature map 采用卷积做预测,如此已经可以达到检测大物体的作用。但如果需要检测小物体,则还需要更精细的 feature map。
感受野越大对于小目标的特征就越不明显,为了检测好小目标,在yolov2中将前面卷积得到的小的感受野的特征和最后大感受野特征进行整合,即需要融合之前的特征。
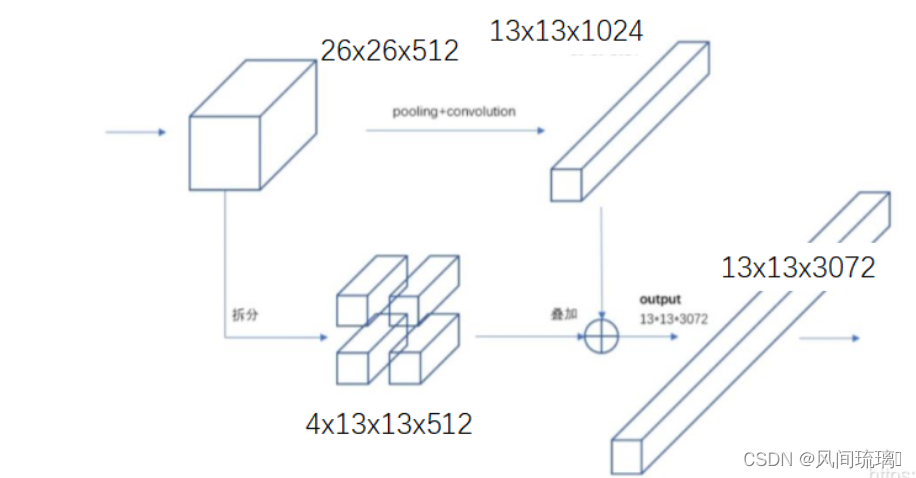

它将 26×26×512 层使用按行列隔行采样的方法,抽取2x2的局部区域,然后将其转化为 channel 维度,便可以巧妙地reshape为13×13×2048。然后与原始的13×13×1024 输出层连接。现在我们在新的13×13×3072层上应用卷积滤波器来进行预测,相当于做了一次特征融合,有利于检测小的目标。
感受野:在特征图上的点能看到原始图像多大区域。
随着卷积层的增加,其感受野也增加。
如果堆叠3个3x3的卷积层,并且保持滑动窗口步长为1,其感受野为7x7,这与直接使用7x7卷积核结果一样,那为什么要堆叠3个3x3的卷积核呢?
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,这就是VGG网络的基本出发点,用小的卷枳核来完成特征提取操作。
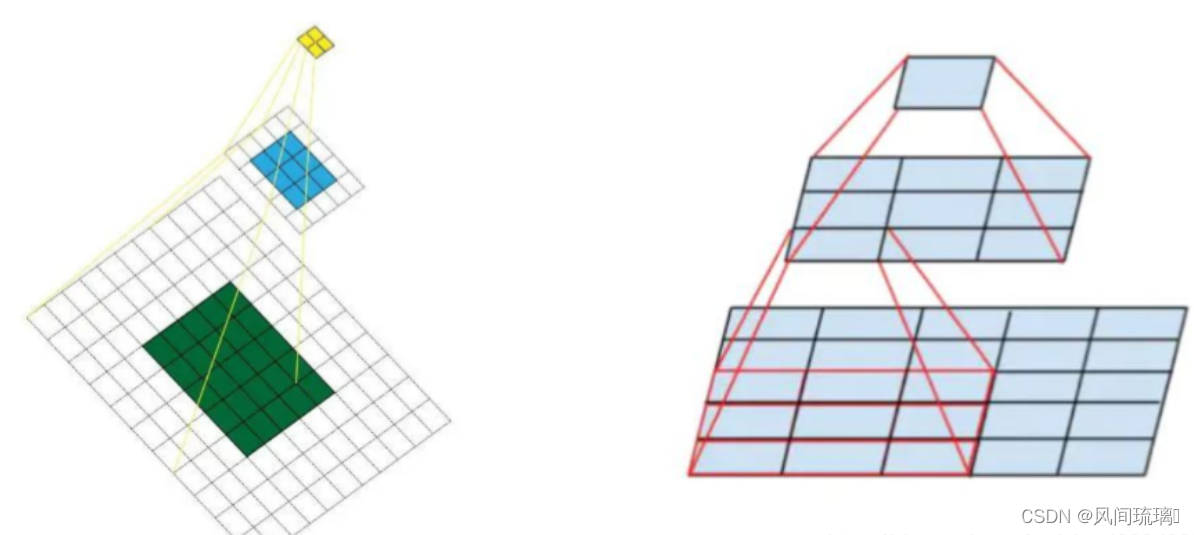


2.4 Multi-Scale-Training
由于模型仅使用卷积层和池化层,因此可以随时调整输入的大小。为了使 YOLOv2 在不同大小的图像上运行时具有鲁棒性,作者针对不同的输入大小训练了模型,就是在训练的过程中每间隔一定的 iterations 后改变输入的图片大小。
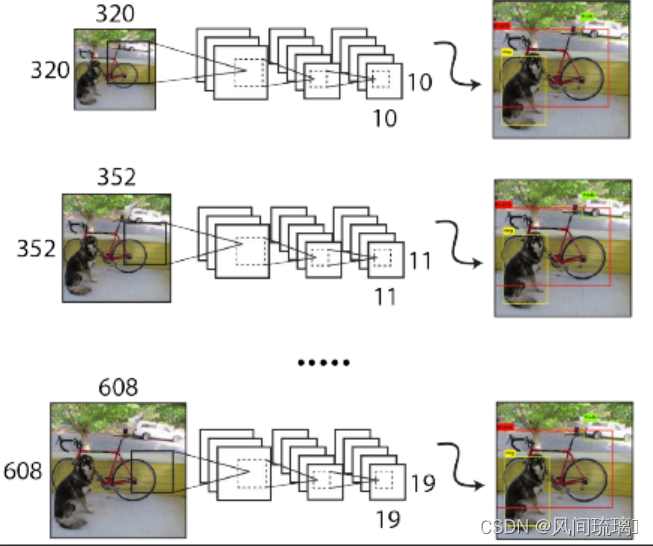
YOLOv2 下采样步长为32,因此输入图片大小要选择32的倍数 (最小尺寸为320x320, 最大尺寸为608x608)。在训练过程,每隔10个 iterations 随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。这起到了数据增强的作用,并迫使网络对不同的输入图像尺寸和比例进行良好的预测。
2.5 Convolutional With Anchor Boxes
在YOLOv1中,输入图片最终被划分为7x7网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。
YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。
YOLOv1中将输入图像分成7x7的网格,每个网格预测2个bounding box,一共只有7x7x2=98个box。 YOLOv2中引入anchor boxes,输出feature map大小为13x13,每个cell有5个anchor box预测得到5个bounding box,一共有13x13x5=845个box,增加box数量是为了提高目标的定位准确率。
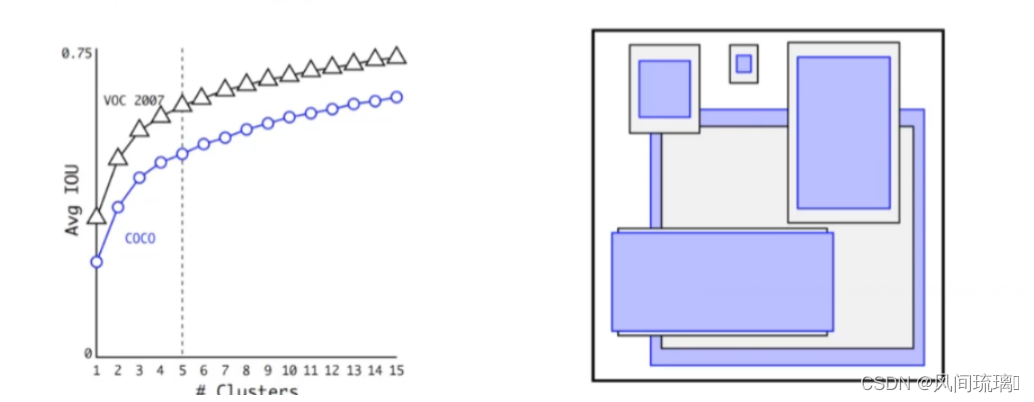
2.6 Dimension Clusters
yolov2里的anchor大小都是通过聚类生成的, faster-rcnn里是硬编码固定大小生成的。
K-means是聚类的方法,最后得到K个聚类中心以及每个样本属于哪个中心,其中K是聚类的个数,需要人为指定,其中使用“距离”来衡量每个样本与聚类中心的关系,通常使用欧式距离,但是对YOLOv2来说,需要选取框的尺寸,衡量的标准应该是“覆盖率”,所以YOLOv2利用IOU来计算,所以距离公式如下:d(box, centroid) = 1 – IOU(box, centroid)(K=5)
2.7 Direct location prediction
在yolov1中作者直接使用偏移量,而在v2中,采用相对于网格得相对坐标。
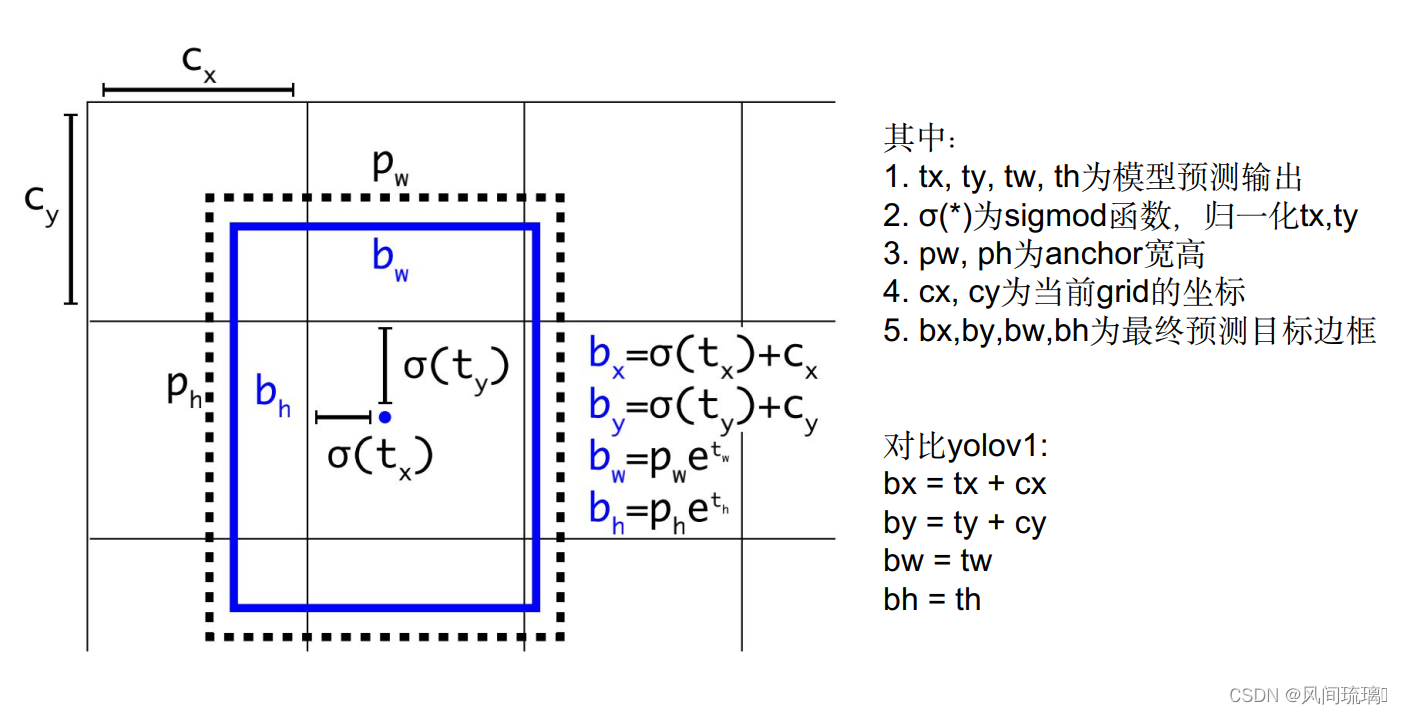
上图为可视化效果,蓝色框为预测的bounding box,虚线矩形是Anchor Box。
三、YOLOv3
YOLOv3 在 YOLOv2 的基础上,改良了网络的 backbone、利用多尺度特征图 (feature map) 进行检测,并且改用多个独立的 Logistic regression 分类器取代softmax 来预测类别分类。
3.1 网络架构(Darknet53)
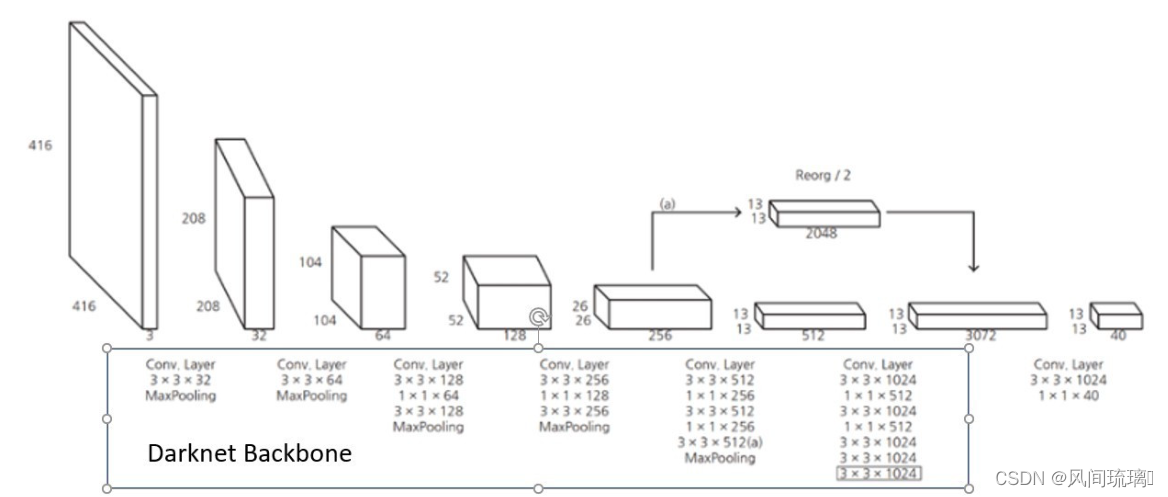
YOLOv3 提出新的 backbone: Darknet-53,从第0层到74层,一共有53层convolutional layer,其余为 ResNet 层。
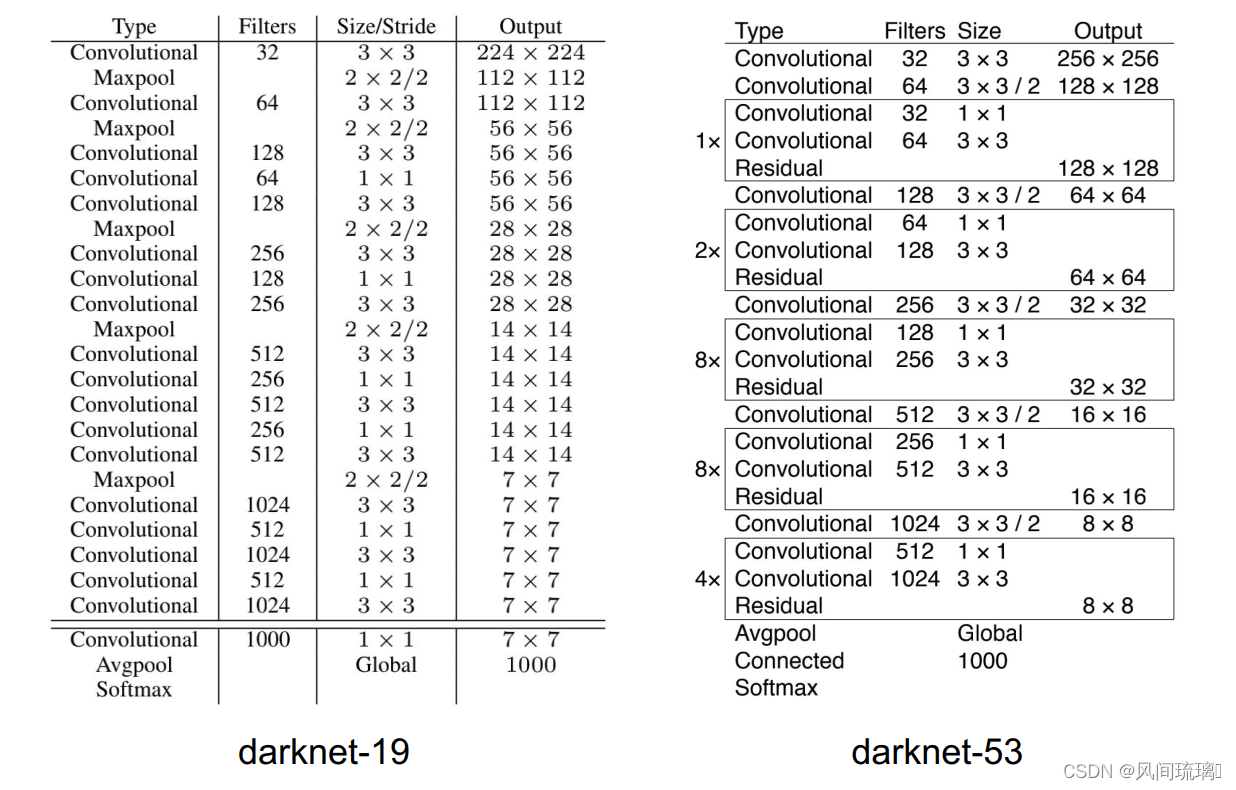
跟 Darknet-19 相比,Darknet-53 去除了所有的 maxpooling 层、增加了更多的1x1和3x3的卷积层,但因为加深网路层数容易导致梯度消失或爆炸,所以Darknet-53 加入了 Resnet 网路 (Residual Network) 来解决梯度的问题。由上图的 Darknet-53 架构可以看到共加入了23个 residual block。
3.2 检测流程
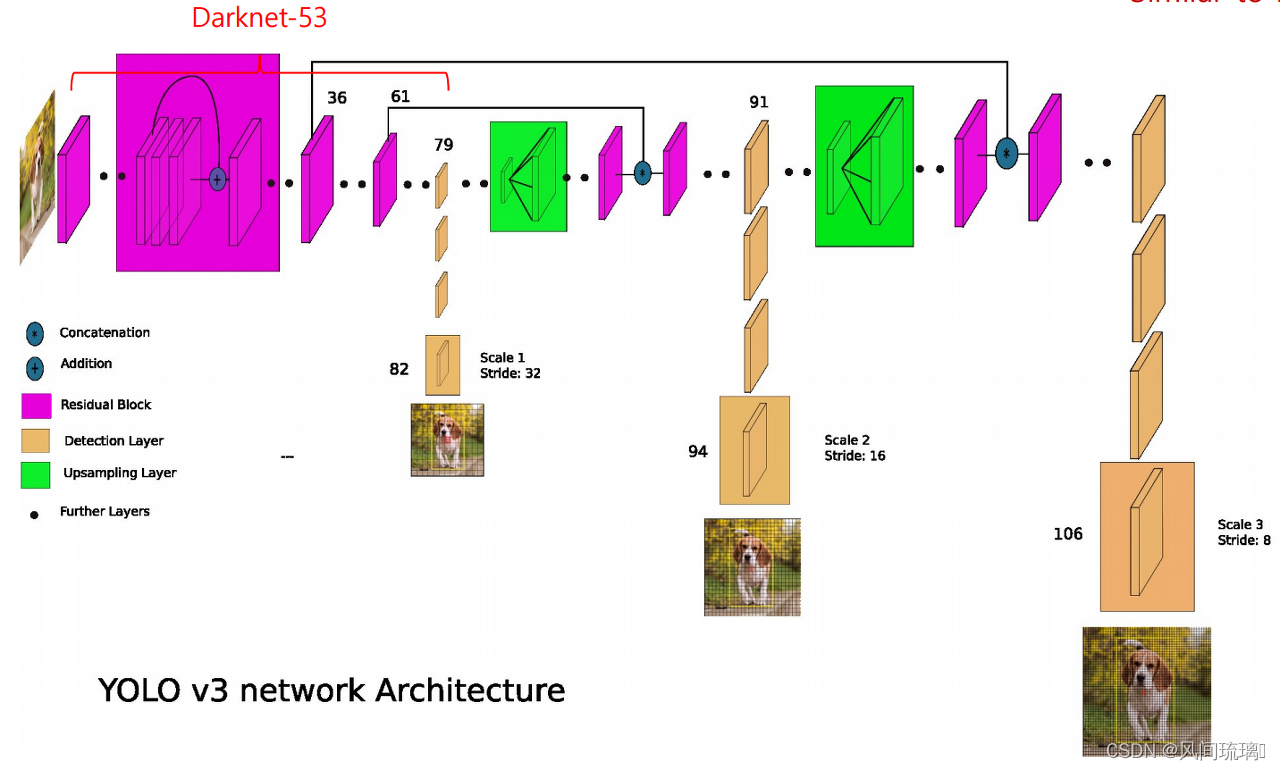
(1)若输入416x416的图片,在79层卷积层后,会先经过32倍的下采样,再通过3x3, 1x1的卷积层后,得到13x13的feature map (第82层)
(2)为了实现能够检测小物体,将第79层13x13的 feature map 进行上采样,与第61层26x26的 feature map 合并 (Concat) 后,再经过16倍的下采样及3x3, 1x1的卷积层后,得到26x26的feature map (第94层)
(3)第91层26x26的 feature map 再次上采样,并与第36层26x26的 feature map 合併 (Concat) 后,再经过8倍下採样及3x3, 1x1的卷积层后,得到52x52的 feature map (第106层)

3.3 Bounding Box Prediction
边框预测保持与yolov2一致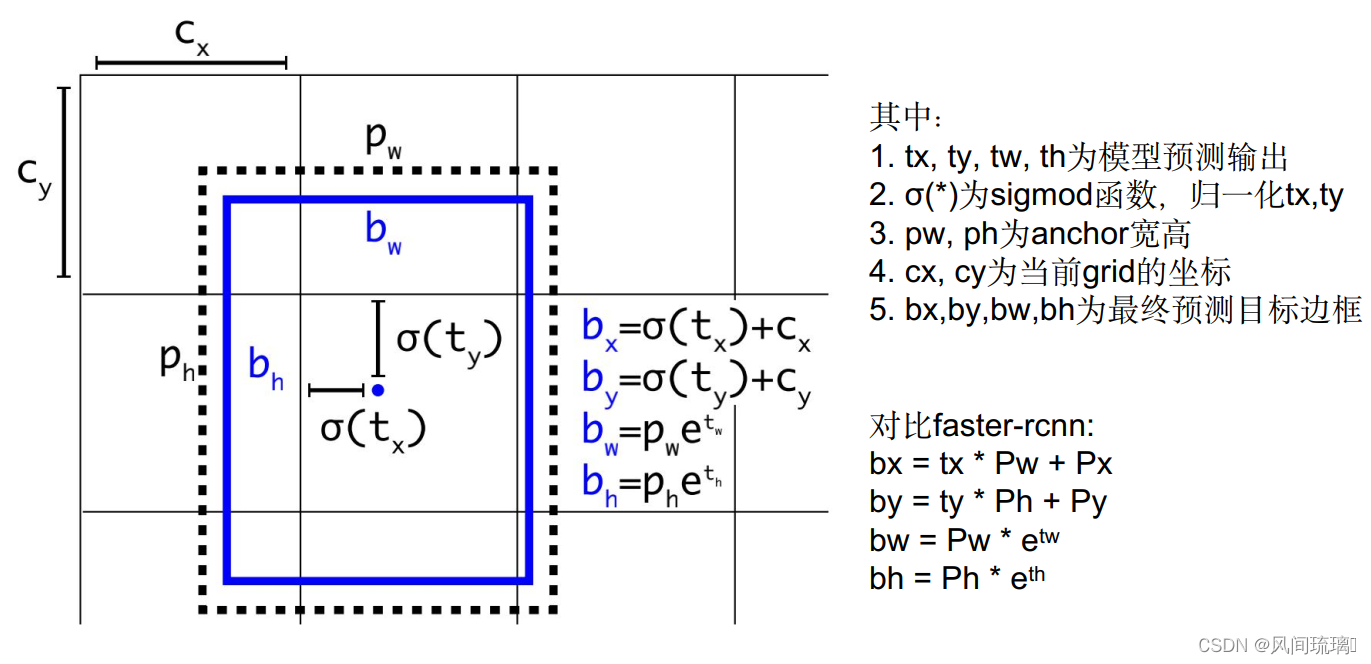
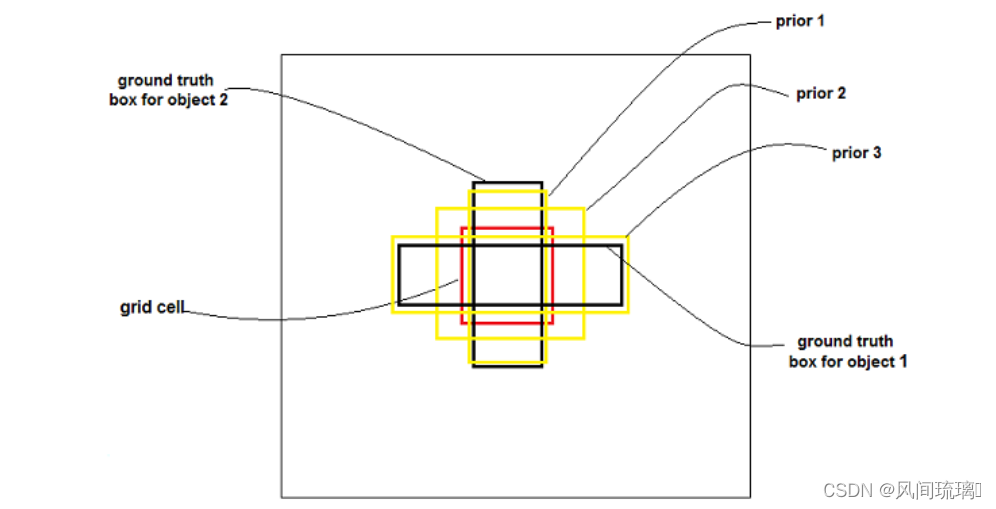
YOLOv3 还使用 Logistic regression (逻辑回归)预测每个边界框的confidence score(置信度)。
1.正例:如果边界框先验与地面实况对象的重叠比任何其他边界框先验多,则该值应为 1。例如,(prior 1)与第一个 ground truth 对象的重叠比任何其他 bounding box (具有最高 IOU)更多,prior 2 与第二个 ground truth 对象的重叠比任何其他 bounding box 都多。
2.忽略样例: 其他不是最高 IOU 的 bounding box 并且 IOU 大于阈值 (threshold,预测为0.5) ,则忽略这些 bounding box,不计算 loss。
3.负例:若bounding box没有与任何一个gound truth对应,那么就应该减少对应的confidence score。
3.4 Multi labels prediction
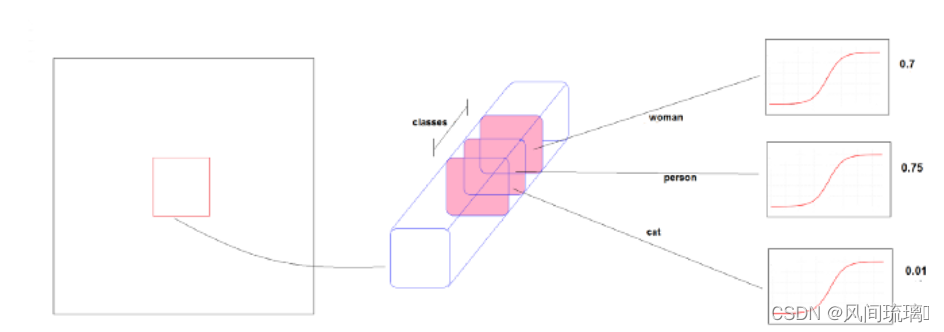
在一些数据集中,一个对象可能有多个标签。例如,一个对象可以被标记为一个男人和人。在这个数据集中,有很多重叠的标签。使用 softmax 进行类预测会假设每个框都只有一个类。因此,YOLOv3 没有使用 softmax,而是对任何类使用独立的 Logistic classifiers 逻辑分类器。使用独立的逻辑分类器,可以同时将对象检测为男人和人。
3.5 Predictions Across Scales
多尺度: 为了能检测到不同大小的物体,设计了3个scale。

与预测最后一层输出的 YOLO 和 YOLO2 不同,YOLOv3 Feature Pyramid Network (FPN) 的方法,预测 3 个不同尺度的框,从而提高对不同大小物体进行检测,提升小物体的检测能力。
每个尺度的 feature map 会预测出3个 Anchor prior,而 Anchor prior 的大小则采用K-means进行聚类分析 。
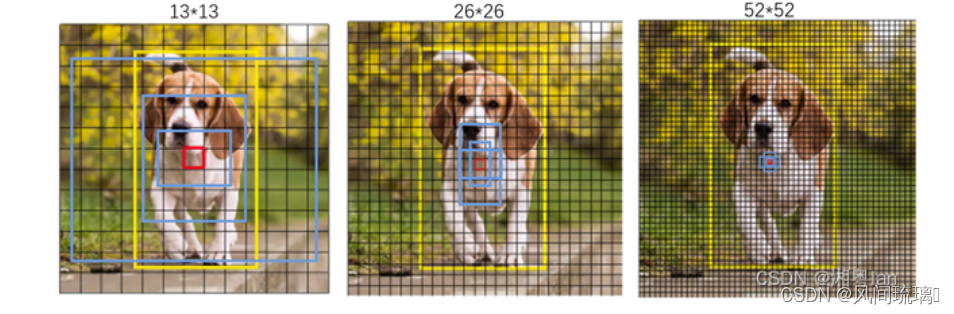
YOLOv3 通过下采样32倍、16倍、8倍得到3个不同尺度的 feature map,例如输入416x416的图片,则会得到13x13 (416/32)、26x26 (416/16)、52x52 (416/8),这3个尺度的 feature map。
feature map对应Anchor prior
①13x13 feature map (有最大的感受野) 用于检测大物体,所以用较大的Anchor prior (116x90), (156x198), (373x326)
②26x26 feature map (中等的感受野) 用于检测中等大小的物体,所以用中等的Anchor prior (30x61), (62x45), (59x119)
③52x52eature map (较小的感受野) 用于检测小物体,所以用较小的Anchor prior (10x13), (16x30), (33x23)
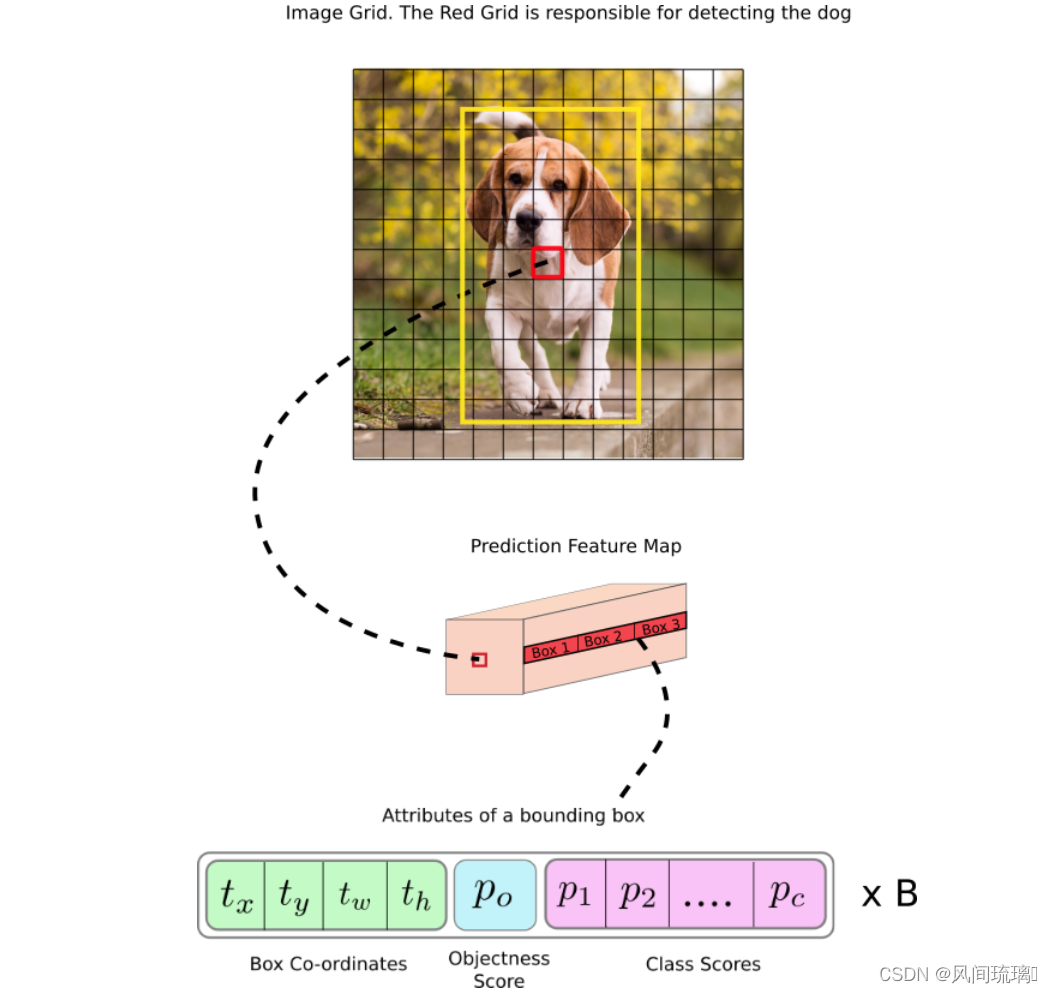
YOLOv3 最显着的特点是它可以在三个不同的尺度上进行检测。 YOLO 是一个全卷积网络,其最终输出是通过在feature map(特征图)上应用 1 x 1 kernel生成的。在 YOLOv3 中,检测是通过在网络中三个不同位置的三个不同大小的特征图上应用 1 x 1 来完成的。
小结
1.YOLOv1网络架构:
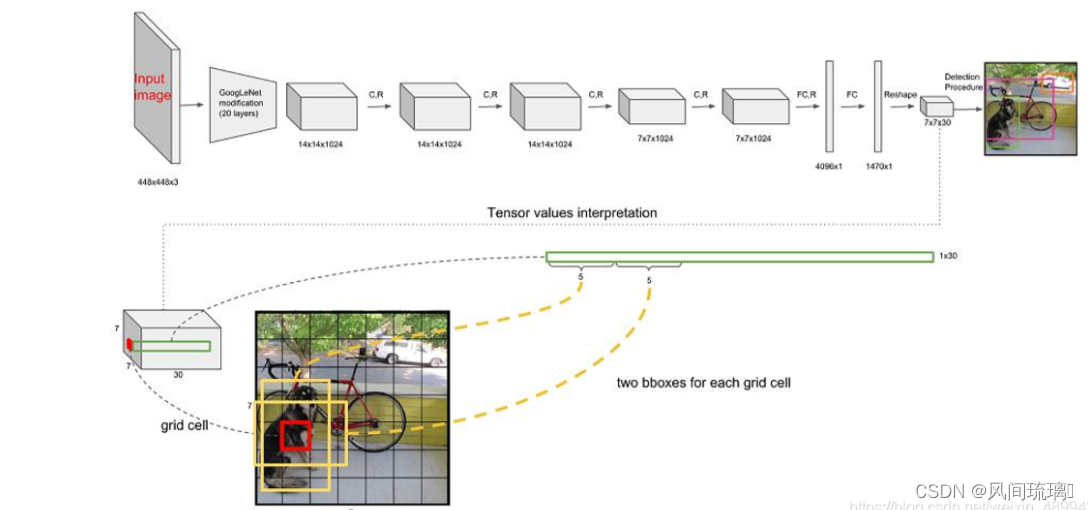
YOLOv1 在 feature map (7x7) 的每一个 grid 中预测出 2个 bounding box 及分类概率值,每个 bounding box 预测出5个值。
2.YOLOV2网络架构:
YOLOv2 在 feature map (13x13) 的每一个 grid 中预测出 5个 bounding box (对应5个 Anchor Box),每个bounding box 预测出5个值及分类概率值。
3.YOLOv3网络架构:
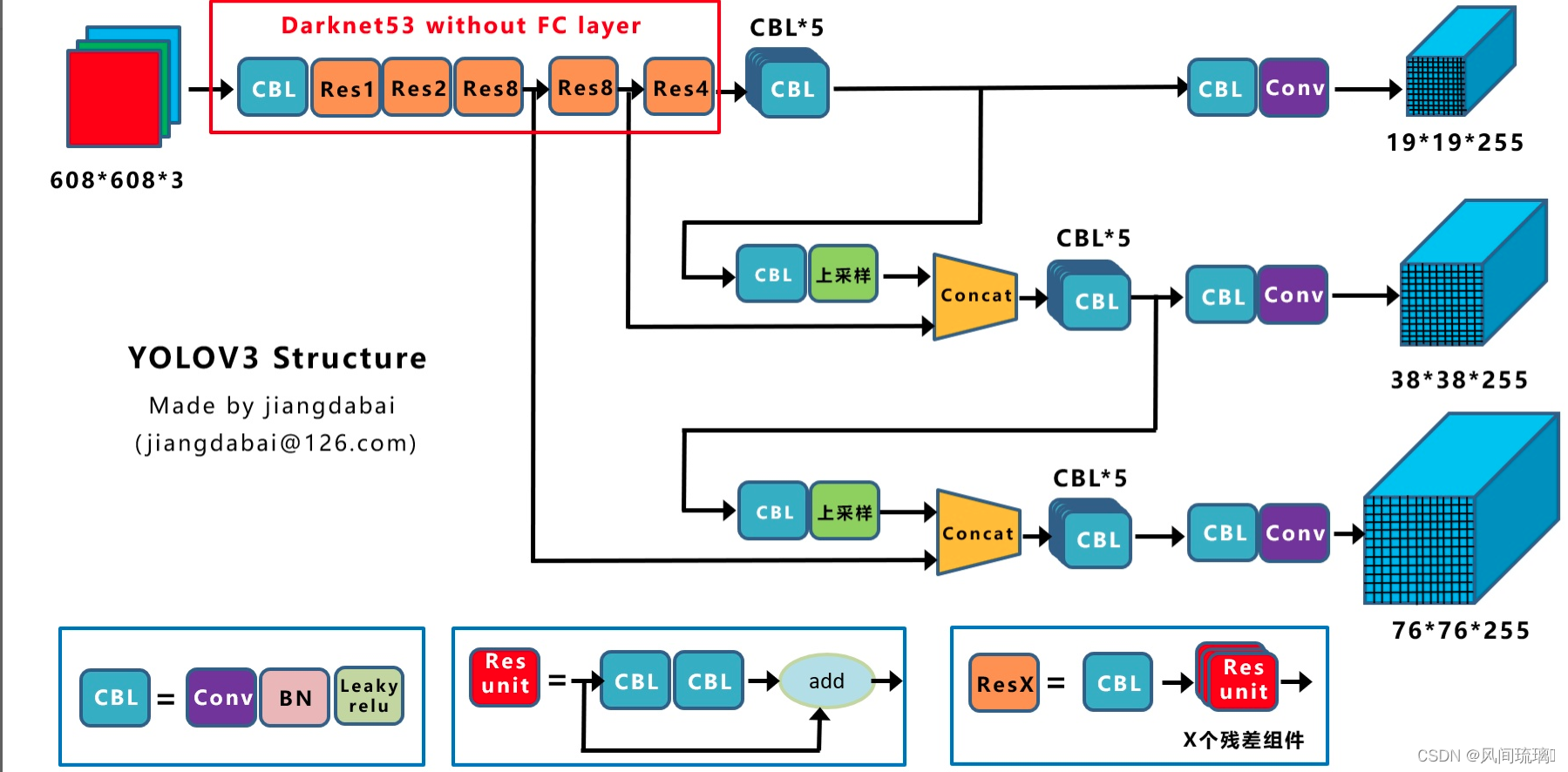
YOLOv3 在3个 feature map的每一个 grid 中预测出 3个 bounding box (对应3个 Anchor prior),每个 bounding box 预测出5个值及分类概率值 ( YOLOv3 是使用 COCO 资料集有80类)。
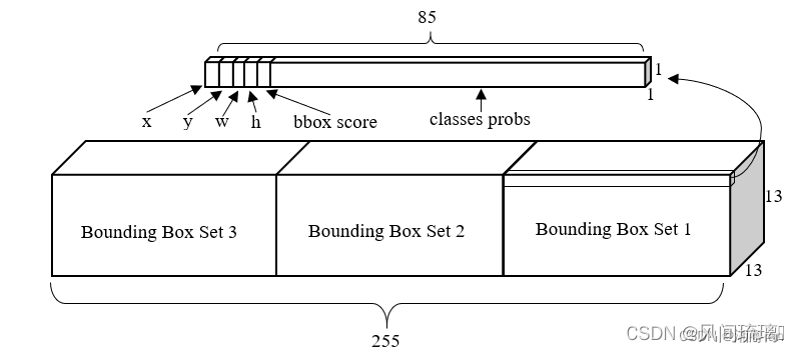
YOLOv2 采用 passthrough 结构来检测小物体特征,而 YOLOv3 采用3个不同尺度的feature map来进行检测。
结束语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个666也是对博主的鼓舞吖 💞 感谢 💐

















 3255
3255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











