







- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
(1) Equal channel width minimizes memory access cost (MAC)
(2) Excessive group convolution increases MAC
(3)Network fragmentation reduces degree of parallelism
(4)Element-wise operations are non-negligible
前言
ShuffleNet是Face++(旷视)在2017年发布的一个高效率可以运行在手机等移动设备的网络结构,论文发表在CVRP2018上。它是一种轻量级卷积神经网络架构,旨在在计算资源有限的情况下实现高效的模型推理。它是专门为计算能力有限的移动平台设计的。

通过逐点分组卷积(Pointwise Group Convolution) 和通道洗牌(Channel Shuffle) 两种新运算,在保持精度的同时大大降低了计算成本 。
ShuffleNet 比最近的 MobileNet 在 ImageNet 分类任务上的 top-1误差更低 (绝对7.8%) 。在基于ARM的移动设备上,ShuffleNet 比 AlexNet 实现了约13倍的实际加速,同时保持了相当的精度 。
一、ShuffleNet V1
2017年之前,最优的算法结构例如Xception、ResNext等因为大量使用1×1卷积,虽然会使模型变小,但导致计算效率降低。ShuffleNet中的pointwise group convolution可以降低1×1卷积的计算复杂度。但是group卷积也有一定缺点,为了解决组卷积带来的副作用,提出了channel shuffle来帮助信息在各通道之间流动。
与热门的VGG和ResNet相比,在限定的计算复杂度之内,ShuffleNet允许有更多的特征映射通道,这有助于编码更多的信息,并且这对非常小的网络的性能特别关键。
1.分组卷积(Group Convolution)
分组卷积(Group Convolution) 的概念首先是在 AlexNet 中引入,用于将模型分布到两块 GPU 上 。
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
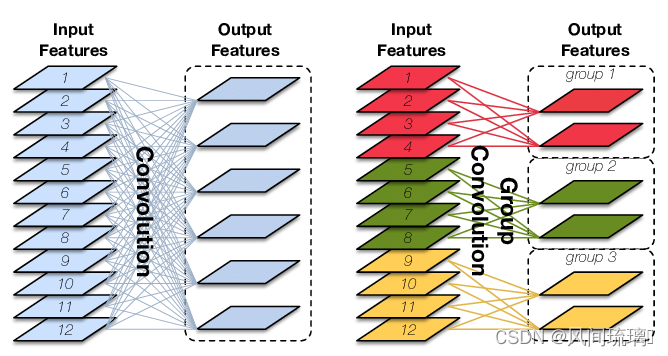
常规卷积 VS 分组卷积
如果输入feature map尺寸为C∗H∗W,卷积核有N个,输出feature map与卷积核的数量相同也是N,每个卷积核的尺寸为C∗K∗K,N个卷积核的总参数量为N∗C∗K∗K,输入map与输出map的连接方式如上图左所示。
Group Convolution,则是对输入feature map进行分组,然后每组分别卷积。
假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每个卷积核的尺寸为C/G∗K∗K,卷积核的总数仍为N个,每组的卷积核数量为N/G,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为N∗C/G∗K∗K。
可见,总参数量减少为原来的 1/G,其连接方式如上图右所示,group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。
在小型网络中,逐点卷积会导致满足复杂度约束的通道数量有限,从而严重的影响精度 ;最直接的解决方案是:采用通道稀疏连接( channel sparse connections ),例如分组卷积可以大大降低计算成本 。但是,这样就会出现一个 问题 :某个通道的输出只能来自一小部分输入通道,这样阻止了通道之间的信息流,也就削弱了神经网络表达能力 ;
为此作者进一步将分组卷积和深度可分离卷积推广为一种新的形式:通道洗牌操作( Channel Shuffle Operation )。
2.通道洗牌(Channel Shuffle)
为达到特征通信目的,采用Channel Shuffle操作,其含义是对Group Convolution后的特征图进行重组,这样可以保证接下了采用的Group Convolution其输入来自不同的组,因此信息可以在不同组之间流转。进一步的展示了这一过程并随机,其实是均匀地打乱。
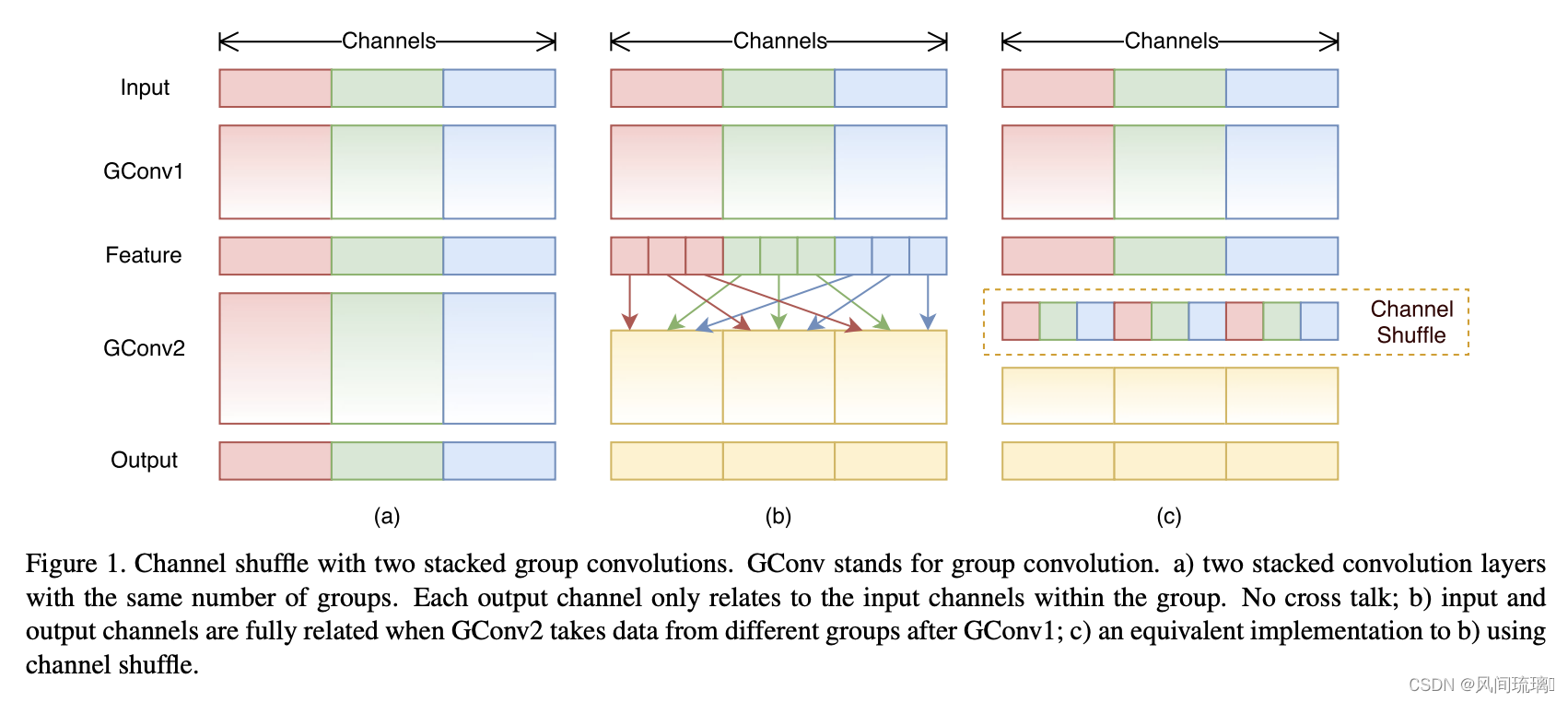
对于普通分组卷积,如上图 a 所示,都是针对该组内的 channel 信息进行卷积操作,如果简单串联的话,则一直对同一个组内的信息进行处理,组与组之间是没有信息交流的,阻止了通道之间的信息流,也就削弱了神经网络表达能力。
当加入channel shuffle 操作,首先还是进行分组卷积得到特征矩阵,假设使用三个 group,如上图 b 所示。然后对特征矩阵原来的 group 再进行更细粒度的划分成三个 sub-group,将每个组中的第一个 sub-group 放到一起,将每个组中的第二个 sub-group 放到一起…,就能形成新的特征矩阵,如(c)中的Channel Shuffle。然后再进行分组卷积,就使得组与组之间的信息可以得到交流。
通过 通道洗牌(Channel Shuffle) 允许分组卷积从不同的组中获取输入数据,从而实现输入通道和输出通道相关联 。
3. ShuffleNet Unit
ShuffleNet Unit是基于残差块(residual block)、Group convolution和Channel Shuffle设计。
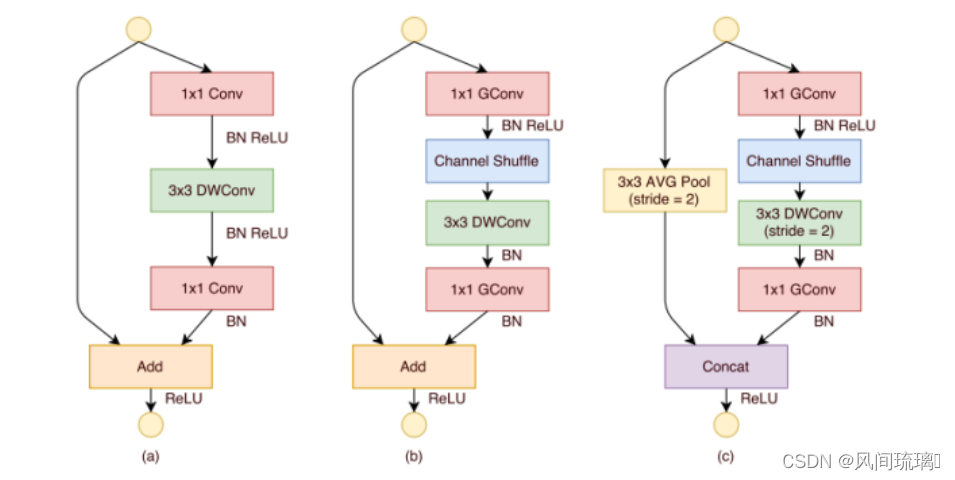
图(a)是Resdual block
①1×1卷积(降维)+3×3深度卷积+1×1卷积(升维)
②之间有BN和ReLU
③最后通过add相加
图(b)为输入输出特征图大小不变的ShuffleNet Unit
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 + Channel Shuffle
②去掉原3×3深度卷积后的ReLU
③ 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
(b)展示了改进思路:将密集的1x1卷积替换成1x1的Group Convolution(因为主要计算量较大的地方是密集的1x1的卷积操作),然后在之后增加了一个Channel Shuffle操作。第二个逐点群卷积的目的是恢复通道维数以匹配shortcut路径。为了简单起见,不在第二个逐点层之后应用额外的channel shuffle操作,因为它产生的结果变化不大。这里是stride为1的情况。
图(c)为输出特征图大小为输入特征图大小一半的ShuffleNet Unit
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 +Channel Shuffle
②令原3×3深度卷积的步长stride=2, 并且去掉深度卷积后的ReLU
③将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
④shortcut上添加一个3×3平均池化层(stride=2)用于匹配特征图大小
⑤对于块的输出,将原来的add方式改为concat方式
(c)降采样操作,对于使用stride>1(stride=2)的情况,只需做两个修改:
(1)在shortcut路径上添加3×3平均池化
(2)将逐元素相加ADD替换为通道级联Concat,这使得可以在不增加额外计算成本的情况下轻松地扩大通道维数。
ResNet、ResNeXt和ShuffleNet网络的参数使用对比
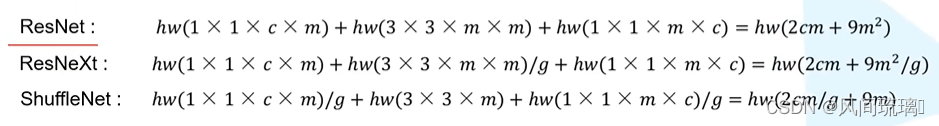
计算可以知道,ShuffleNet V1的参数使用量比ResNet和ResNeXt网络的参数都要少。在给定的有限的计算资源下,ShuffleNet 能够使用更宽的特征图。 作者发现这对于小型网络来说至关重要,因为通常小型网络通常有很少的通道数来处理信息。
4.网络结构
基于ShuffleNet Unit,如下表中展示了整个ShuffleNet V1结构,首先使用的普通的3x3的卷积和max pool层,接着网络主要由为三个阶段的ShuffleNetUnit单元的堆栈组成(stage2/3/4),每个stage第一层stride=2,从而实现降采样的功能,每个stage中的其他超参数保持不变,从上一个stage到下一stage中的输出通道数加倍。与ResNet类似,每个ShuffleNet Unit中bottleneck中的通道数设置为输出通道数的1/4。
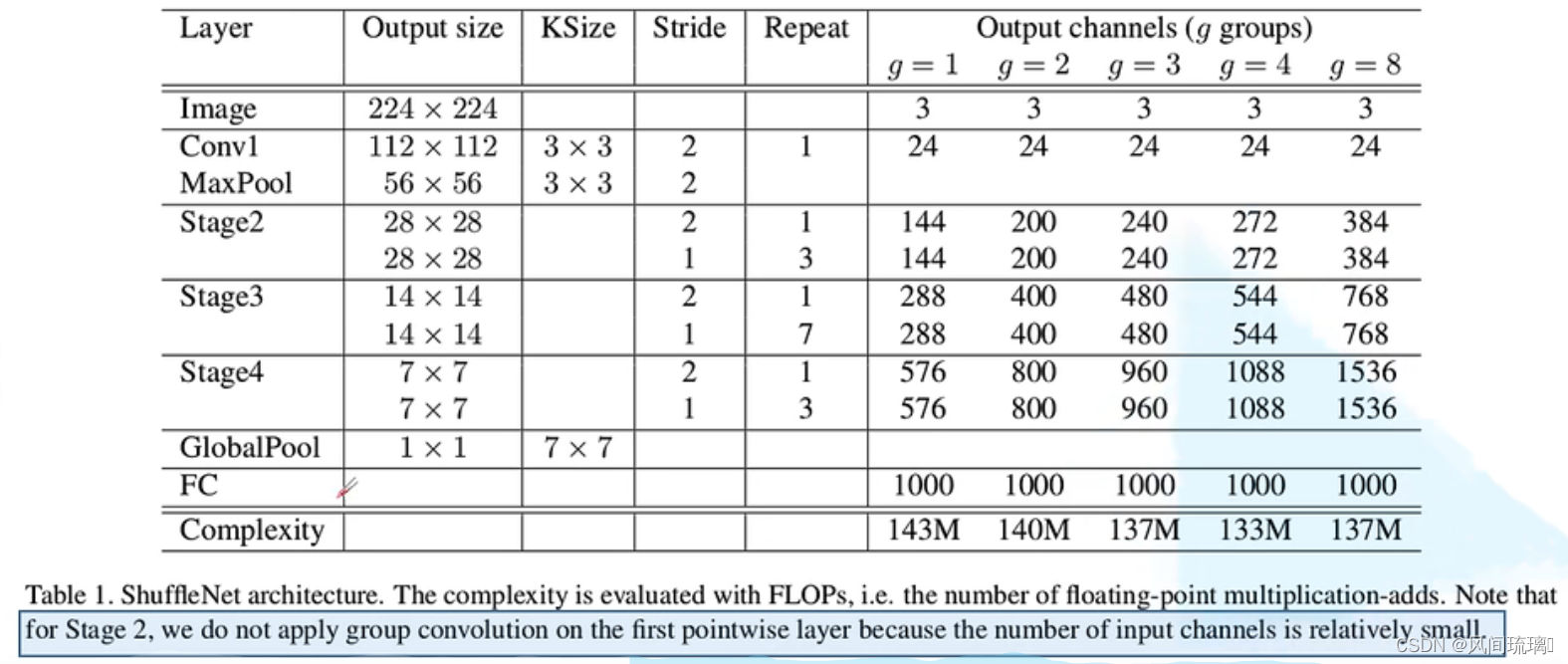
在ShuffleNet unit 中,组个数g代表着逐点卷积的连接稀疏程度。在上图中展示了不同的组数量的方案,同时通过调整输出通道数(网络的宽窄),来使得整体的计算量大致相同。那么对于一个给定的计算量约束,g越大,则可以设置越多的卷积核,产生越多的输出通道,从而帮助编码更多的信息,其中较多论文使用的是g=3的版本。
创新点
①使用分组逐点卷积(Group Convolution)来降低1×1卷积的计算复杂度
②使用通道重排(Channel Shuffle)操作来帮助信息在特征通道间流动
二、ShuffleNet V2
ShuffleNet v2是一种深度神经网络架构,与ShuffleNet v1和MobileNet v2相比,在计算复杂度为40M FLOPs的情况下,精度分别比ShuffleNet v1和MobileNet v2高3.5%和3.7%。ShuffleNet v2的框架与ShuffleNet v1基本相同,都包括Conv1、Maxpool、Stage 2~5、Global pool和FC等部分。唯一的不同是ShuffleNet v2比ShuffleNet v1多了一个1x1 Conv5。ShuffleNet v2还提供了四个不同版本,即ShuffleNet v2 0.5x、ShuffleNet v2 1x、ShuffleNet v2 1.5x和ShuffleNet v2 2x。
ShuffleNetV2中提出了一个关键点,之前的轻量级网络都是通过计算网络复杂度的一个间接度量,即FLOPs,通过计算浮点运算量来描述轻量级网络的快慢。
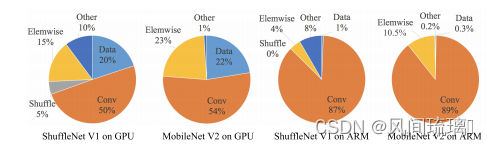
但是从来不直接考虑运行的速度。在移动设备中的运行速度不仅仅需要考虑FLOPs,还需要考虑其他的因素,比如内存访问成本(memory access cost)和平台特点(platform characterics)。
所以,ShuffleNet v2通过控制不同的环境来测试网络在设备上运行速度的快慢,而不是通过FLOPs来判断性能指标。
因此,ShuffleNetv2提出了设计应该考虑两个原则:
①应该使用直接度量(如速度)而不是间接度量(如FLOPs)。
②这些指标应该在目标平台上进行评估。
然后,ShuffleNetv2根据这两个原则,提出了四种有效的网络设计原则:
G1: Equal channel width minimizes memory access cost (MAC)
G2: Excessive group convolution increases MAC
G3: Network fragmentation reduces degree of parallelism
G4: Element-wise operations are non-negligible
1.高效网络设计的实用准则
(1) Equal channel width minimizes memory access cost (MAC)
当保持FLOPs不变时,卷积层的输入特征矩阵与输出特征矩阵相等时,MAC最小,这里针对1x1的卷积层。
相同的channel可最大限度地降低内存访问成本(MAC):轻量化网络通常采用深度可分离卷积,其中逐点卷积(即1×1卷积)占了绝大部分的计算量。我们研究了1×1卷积的核心形状,其由两个参数指定:输入通道的数量c1和输出通道的数量c2。设h和w为feature map的空间大小,1×1卷积的FLOPs为B = h * w * c1 * c2。内存访问成本(MAC),即内存访问操作数,为
这个公式分别对应于输入/输出特性映射的内存访问和卷积核权重。其实这条公式可以看成由三个部分组成:第一部分是,对应的是输入特征矩阵的内存消耗;第二部分是
,对应的是输出特征矩阵的内存消耗。第三部分是
。
然后根据均值不等式得出:
因此理论上MAC的下界由FLOPs决定,当且仅当c1 = c2 时取得最小值。
在实验中,由于内存的限制,加上卷积库对于卷积使用的模块优化,真实情况会略有差异,因此作者在现实情况中做了实验结果如图:
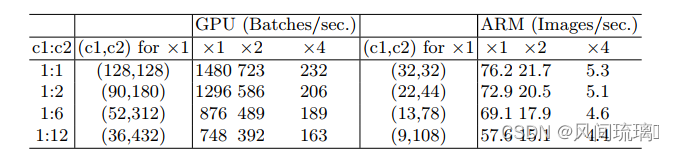
通过改变比率c1: c2显示了在固定总FLOPs时的运行速度。可见,当c1: c2接近1:1时,MAC变小,网络评估速度加快。
(2) Excessive group convolution increases MAC
当GConv的groups增大时(保持FLOPs不变时),MAC也会增大。
组卷积的组数越大,MAC越大,组卷积是轻量化网络的核心,它通过将所有channel之间的密集卷积改变为稀疏(仅在同一组内)来降低计算复杂度(FLOP)。
一方面,因为组卷积相比普通卷积降低了计算量,因此在给定FLOP的情况下使用组卷积可以使用更多的channel,增加了网络的容量(从而提高了精度)。然而,另一方面,增加的channel数导致更多的MAC。
假设 g 是1x1组卷积的组数,则有:
给定固定的输入形状c1× h × w,计算代价B, MAC随着g的增长而增加(线性函数)。
实验结果如下,

通过保持FLOPs一定的情况下,改变g的数值,以GPU x1 与CPU x1为例进行说明,当g=1的时候,每秒能推理2451个batches;当g=2,每秒能推理1725个batches;当g=8,每秒能推理634个batches;当g有1到8,它的推理速度下降到原来的1/4还是非常明显的。但在cpu上我们发现它下降的连一半都不到。
(3)Network fragmentation reduces degree of parallelism
网络设计的碎片化程度越高,速度越慢。这里所说的碎片化可以理解为网络的分支的程度,大多数网络在设计的时分支比较多。
分支可以是串联,可以是并联,在GoogLeNet系列中,它就并行了有3x3的卷积层,5x5的卷积层,还有池化层等等,他们就很喜欢采用多分支的结构来进行网络的搭建。
在GoogLeNet系列和自动生成的体系结构中,每个网络块都广泛采用了一种多路径结构。许多小型操作,这里称为碎片操作,被用来代替几个大的操作。
虽然这种碎片化结构已经被证明有利于提高准确性,但它可能会降低效率,因为它对GPU等具有强大并行计算能力的设备不友好。它还引入了额外的开销,比如内核启动和同步。
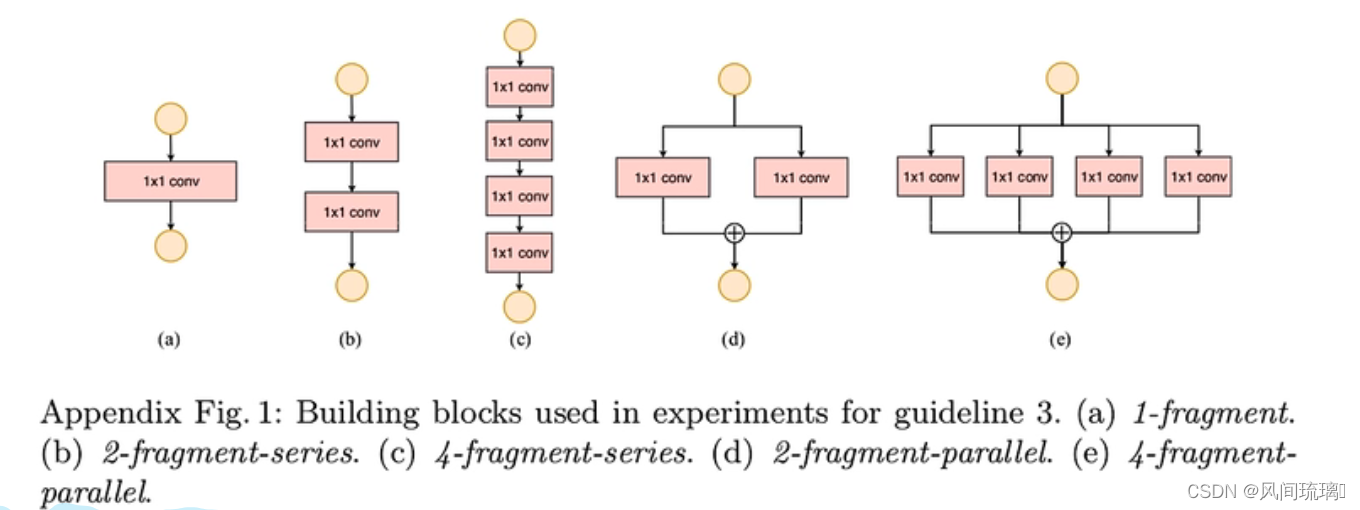
对于(e)块结构,有4个并行的分支,对于每个卷积层都需要有kernel的启动,如果四个并行结构计算时间差不多,影响较小。如果相差很大,运算快的分支运算完成之后就会一直等着运算比较慢的分支,只有等到所有分支全部计算完成后,才能进行下一步计算,因此效率是比较低的。
为了量化网络分片如何影响效率,作者评估了一系列不同分片程度的网络块。每个构造块由1到4个1 × 1的卷积组成,这些卷积是按顺序或平行排列的,每个块重复堆叠10次,块结构上图所示。
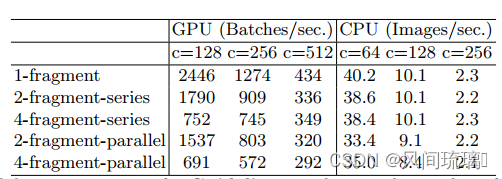
其中上图(a),(b),(c)对应的与1-fragement,2-fragement-series,4-fragement_series,他们是简单的串行,同样是保持FLOPs不变的情况下,串行的层数越多,碎片化程度越高我们的推理速度也是越来越慢的。
对于图(d),(e),对应的是2-fragement-parallel,4-fragement-parallel,也同样是碎片化程度越高,推理速度越慢。但是在cpu上其实变化是不大的,GPU变化非常明显。
(4)Element-wise operations are non-negligible
逐元素操作的执行时间是不可忽略的。

在像ShuffleNet V1和MobileNet V2这样的轻量级模型中,逐元素操作占用了相当多的时间,尤其是在GPU上。逐元素运算包括激活函数比如ReLU,AddTensor比如shortcut分支与主分支的输出进行Add操作,AddBias比如卷积运算过程中偏置相加等。
对于每一个元素型操作的都叫Element-wise operation,这些操作的特点都是它的FLOPs很小,但是他们的MAC很大。作者也说了像depthwise convolution也可以看做为element-wise operator。因为它也具有较高的MAC / FLOP比。
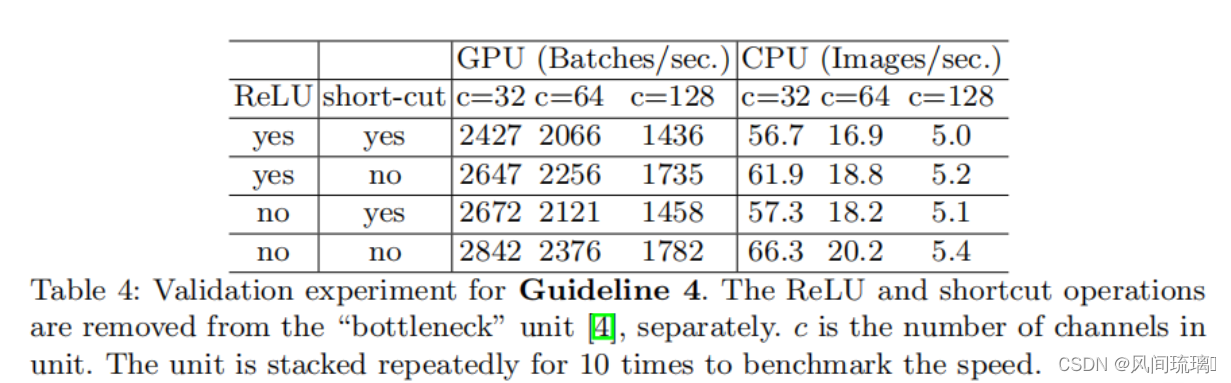
可以看见上表中报告了不同变体的运行时间。观察到,在移除ReLU和shortcut后,GPU和ARM都获得了大约20%的加速。这里主要突出的是,这些操作会比我们想象当中的要耗时。
总结:基于上述准则和实证研究,作者总结出一个高效的网络架构应该:
①要使用“平衡”卷积,使输入特征矩阵和输出矩阵的channel相等或者接近
②注意分组卷积的计算成本,增大组数能降低参数,但是它会增加计算成本
③降低网络的碎片程度,不要涉及多分支结构
④尽可能减少使逐元素操作(element-wise operator)
2. 网络结构
如下图所示,图(a)和图(b)是shuffleNet V1,其中(a)是DW卷积步距为1时的block,(b)是DW卷积步距为2时的 block。右边的图(c)和图(d),是shuffleNet V2中对应步距为1和2的block。

ShuffleNetV2在V1上做出了一些改进,如图( c )所示,在每个单元的开始,通过一个Channel Split操作将输入特征矩阵划分为两部分,一部分是shortcut分支,另一部分对应于主分支(在ShuffleNetV2中这里是对channels均分成两半)。根据G3,不能使用太多的分支,所以其中一个分支不作改变,另外的一个分支由三个卷积组成,它们具有相同的输入和输出通道以满足G1。
在主分支上,两个1 × 1卷积不再是组卷积,而改变为普通的1x1卷积操作,这是为了遵循G2(需要考虑组的代价)。卷积后,两个分支被拼接,而不是相加(G4)。因此,通道的数量保持不变(G1)。
然后使用与ShuffleNet V1中相同的Channels Shuffle操作来启用两个分支之间的信息通信。需要注意,ShuffleNet v1中的“Add”操作不再存在。ReLU和depthwise convolutions 这样的元素操作只存在于一个分支中。
对于三个连续的element-wise操作,Concat,Channel Shuffle以及下一个block的Channel Split,这三个操作可以合并为一个element-wise operation,这样减少了element-wise操作的个数,这就满足G4准则。
对于stride为2降采样图(d),ShuffleNet v1使用了3x3的平均池化,而ShuffleNet v2使用了一个3x3 DW卷积和一个1x1的普通卷积。不存在channel split操作,移除通道分离操作符,输出通道的数量增加了一倍。
所提出的block( c )( d )以及由此产生的网络称为ShuffleNet V2。基于上述分析,该体系结构设计是高效的,因为它遵循了所有的指导原则。积木重复堆叠,构建整个网络。ShuffleNet V2网络结构如下表所示。
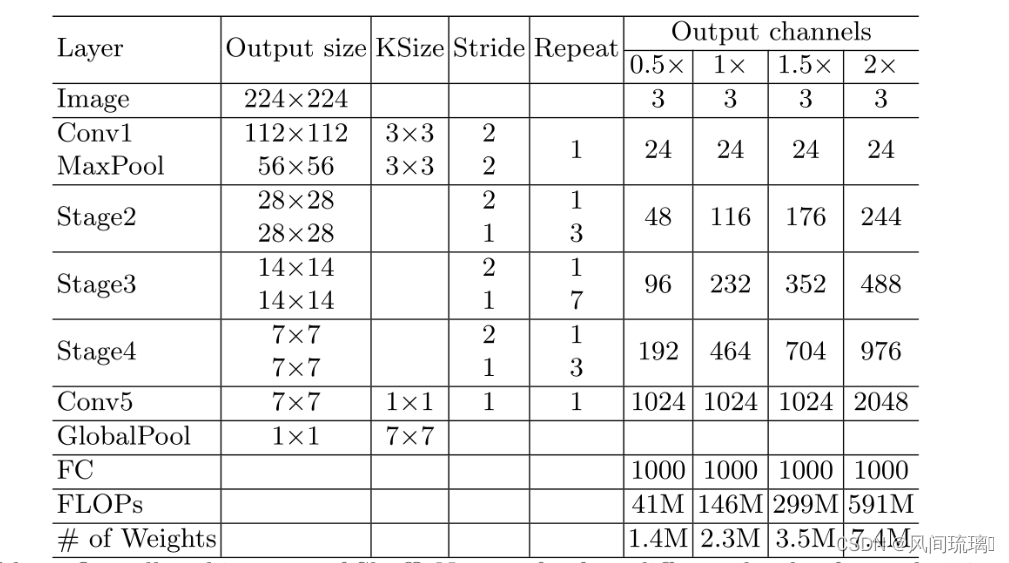
总体网络结构类似于ShuffleNet v1,唯一的区别是在全局平均池化前增加了一个1 × 1的卷积层来混合特性。每个block中的通道数量被缩放,生成不同复杂度的网络,标记为0.5x,1x,1.5x,2x。对于每个stage,它的第一个block是需要进行翻倍的,步距strip都是等于2的。
ShuffleNet v2不仅高效,而且准确,主要有两个原因:
①每个block的高效率使使用更多的特征通道和更大的网络容量成为可能
②在每个block中,有一半的特征通道直接穿过该块并加入下一个块, 可以看作是一种特性复用,与DenseNet和CondenseNet的思想一样
三、ShuffleNetV2网络实现
1.构建ShuffleNetV2网络
# 通道洗牌
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size() # [n,c,h,w]
channels_per_group = num_channels // groups # groups划分组数
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous() # 1,2维度交换
# flatten
x = x.view(batch_size, -1, height, width)
return x
# ShuffleNetV2 block
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
# 参数判断
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0 # 判断 output_c = in‘ + in’ = 2*in'
branch_features = output_c // 2 # 均分
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2: # 两个分支均有处理
# 分支1
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential() # stride=1 不做任何处理
# 分支2 只有DW conv 的stride不同
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
# DW Conv
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 均分 channel
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int], # stege重复次数
stages_out_channels: List[int], # 输出特征矩阵channel
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
# 参数检查
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
# 第一次卷积+下采样
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# stage模块
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)] # 第一层stride=2
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
# Conv5
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model2.训练和测试模型
from model import shufflenet_v2_x1_0
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
# 检测是否支持CUDA,如果支持则使用第一个可用的GPU设备,否则使用CPU
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
# tensorboard --logdir=F:/NN/Learn_Pytorch/ShuffleNetV2/runs/Oct11_13-22-17_DESKTOP-64L888R
# 记录训练过程中的指标和可视化结果
tb_writer = SummaryWriter()
# 创建一个用于存储模型权重文件的目录
if os.path.exists("./weights") is False:
os.makedirs("./weights")
# 获取训练和验证数据集的文件路径和标签
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
# 数据预处理/增强的操作
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(), # 类型转变并归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
# 加载数据集,指定了批处理大小、是否打乱数据、数据加载的并行工作进程数(num_workers)
# 以及如何合并批次数据的函数(collate_fn)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
# 如果存在预训练权重则载入
model = shufflenet_v2_x1_0(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
# 加载权重文件
weights_dict = torch.load(args.weights, map_location=device)
# 仅包含与模型结构相匹配的权重,
# 遍历预训练权重字典(weights),
# 只保留那些与当前模型(net)中同名参数具有相同尺寸的键-值对,并将它们保存在load_weights_dict中
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
# # 将上一步筛选出的pre_dict中的权重加载到模型net中,
# strict=False表示允许加载不完全匹配的权重,可能会有一些不匹配的权重被忽略
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
# 对于不是全连接层("fc")的参数,即冻结这些参数,不进行梯度计算
para.requires_grad_(False)
# 创建一个包含所有需要进行梯度更新的参数的列表
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=4E-5)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# 学习率调度策略,将学习率在训练过程中按余弦函数的方式进行调整
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
# 根据余弦函数的形状调整学习率
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
best_acc = 0.0
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
# 保存准确率最高的权重
if round(acc, 3) > best_acc:
best_acc = round(acc, 3)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.1)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default=r"F:/NN/Learn_Pytorch/flower_photos")
# shufflenetv2_x1.0 官方权重下载地址
# https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
parser.add_argument('--weights', type=str, default='./shufflenetv2_x1.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
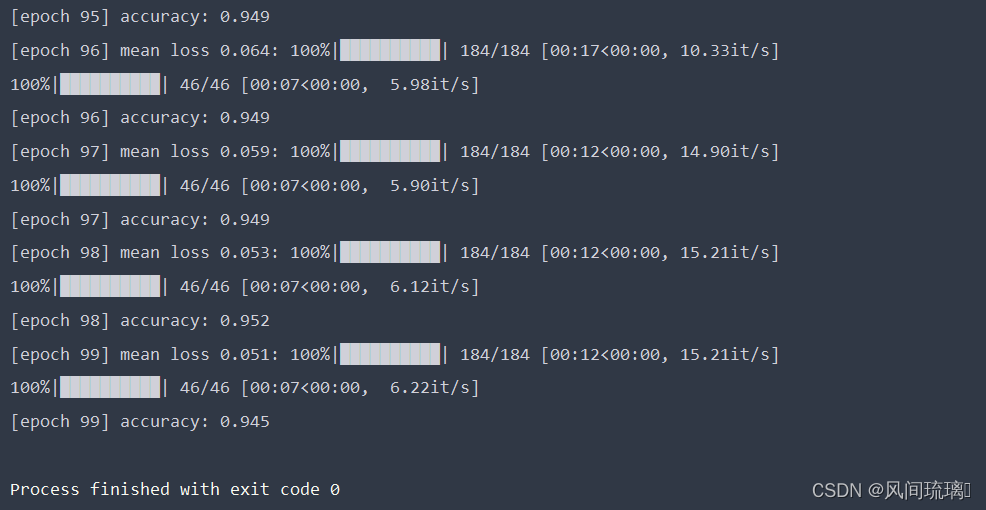
main(opt)这里使用了官方的预训练权重,在其基础上训练自己的数据集。训练100epoch的准确率能到达90%左右
四、实现图像分类
这里使用花朵数据集,下载连接:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 与训练的预处理一样
data_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载图片
img_path = 'tulips2.jpg'
assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)
image = Image.open(img_path)
# image.show()
# [N, C, H, W]
img = data_transform(image)
# 扩展维度
img = torch.unsqueeze(img, dim=0)
# 获取标签
json_path = 'class_indices.json'
assert os.path.exists(json_path), "file: '{}' does not exist.".format(json_path)
with open(json_path, 'r') as f:
# 使用json.load()函数加载JSON文件的内容并将其存储在一个Python字典中
class_indict = json.load(f)
# create model
model = shufflenet_v2_x1_0(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-17.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# 对输入图像进行预测
output = torch.squeeze(model(img.to(device))).cpu()
# 对模型的输出进行 softmax 操作,将输出转换为类别概率
predict = torch.softmax(output, dim=0)
# 得到高概率的类别的索引
predict_cla = torch.argmax(predict).numpy()
res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy())
draw = ImageDraw.Draw(image)
# 文本的左上角位置
position = (10, 10)
# fill 指定文本颜色
draw.text(position, res, fill='red')
image.show()
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy()))
if __name__ == '__main__':
main()
测试结果:

结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。


















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











