







文章目录
- 前言
- 一、TensorRT
- 二、LeNet-5 部署
- 三、TensorRT 常用API
- 1.addinput
- 2.addConvolutionNd
- 3.setStrideNd和setPaddingNd
- 4.addActivation
- 5.addPoolingNd
- 6.addFullyConnected
- 7.getOutput和markOutput
- 8.setMaxBatchSize
- 9.setMaxWorkspaceSize
- 10.buildEngineWithConfig
- 11.createInferBuilder
- 12.createBuilderConfig
- 13.serialize
- 14.createInferRuntime
- 15.deserializeCudaEngine
- 16.createExecutionContext
- 17.getNbBindings
- 18.getBindingIndex
- 19.cudaMemcpyAsync
- 20.cudaStreamSynchronize
- 21enqueue
- 22.enqueueV2
- 23.seekg
- 24.tellg
- 25.good
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
本文记录一下TensorRT部署流程,参考了网上很多例程,可能有的代码是旧版本的,但是这并不影响的,这里主要是使用API的方式构建网络,下一篇会使用ONNX构造网络。参考文档:TensorRT官方文档
一、TensorRT
1.TensorRT简介
NVIDIA® TensorRT™的核心是一个C++库,旨在实现在NVIDIA图形处理单元(GPU)上的高性能推理。TensorRT接收一个已训练的网络,包括网络定义和一组训练参数,并生成一个高度优化的运行时引擎,用于执行该网络的推理。TensorRT提供通过C++和Python的API,通过网络定义API表达深度学习模型或通过parsers(解析器)加载预定义模型,使TensorRT能够优化并在NVIDIA GPU上运行它们。
TensorRT使开发人员能够导入、校准、生成以及部署优化的网络。网络可以直接从Caffe导入,也可以通过UFF或ONNX格式从其他框架导入,也可以通过实例化各个图层并直接设置参数和weight以编程的方式创建。
用户可以通过TensorRT使用Plugin interface运行自定义图层。TensorRT中的GraphSurgeon功能提供了Tensorflow中自定义layer的节点映射,因此可以支持许多TensorFlow模型的inference。TensorRT在所有支持平台上提供了C++实现,并在x86,aarch64和ppc64le上提供Python实现。
TensorRT核心库中的关键接口:
-
Network Definition
网络定义接口为应用程序提供了指定网络定义方法。可以指定网络的输入输出tensor,也可以添加layer,并且有一个用于配置每一个支持layer type的interface。例如,convolution layer和recurrent layers等layer type,以及Plugin layer type都允许应用程序实现TensorRT本身不支持的功能。有关网络定义的更多信息,请参见nvinfer1::INetworkDefinition Class Reference -
Optimization Profile
优化配置文件指定对动态维度的约束。有关更多信息,请参考以下两部分
nvinfer1::IOptimizationProfile Class Reference
Working with Dynamic Shapes -
Builder Configuration
构建器配置接口指定用于创建engine的详细信息,它允许应用程序指定优化Profile,最大工作空间大小,最小可接受的精度水平,用于自动调整的定时迭代技术以及用于量化网络以8位精度运行的接口。有关更多信息,请参考nvinfer1::IBuilderConfig Class Reference -
Builder
构建器接口允许根据网络定义和builder configuration创建一个优化的engine。有关Builder的更多信息,请参阅nvinfer1::IBuilder Class Reference -
Engine
engine接口允许应用程序执行inference。它支持同步和异步执行、概要分析以及枚举和查询engine的输入和输出的绑定。单engine可以具有多个执行上下文,从而允许将一组trained parameters用于同时执行multiple batches。有关Engine的更多信息,请参见nvinfer1::ICudaEngine Class Reference -
Caffe Parser
该解析器可用于解析在BVLCCaffe或NVCaffe0.16中创建的Caffe网络。它还提供了为自定义层注册插件工厂的功能。有关C ++Caffe解析器的更多详细信息,请参见nvcaffeparser1::ICaffeParser Class Reference
Python版本请参阅Caffe Parser -
UFF Parser
该解析器可用于解析UFF格式的网络。它还提供了注册插件工厂并为自定义层传递字段属性的功能。有关C ++ UFF解析器的更多详细信息,请参见nvuffparser::IUffParser Class Reference
Python版请参阅UFF Parser -
ONNX Parser
该解析器可用于解析ONNX模型。有关C ++ ONNX解析器的更多详细信息,请参见nvonnxparser Namespace Reference
Python版请参阅Onnx Parser
Github上TensorRT官方源码参考(包含TensorRT Caffe和ONNX解析器的插件):TensorRT
TensorRT优化策略介绍,这也是为什么TensorRT能加速的原因。
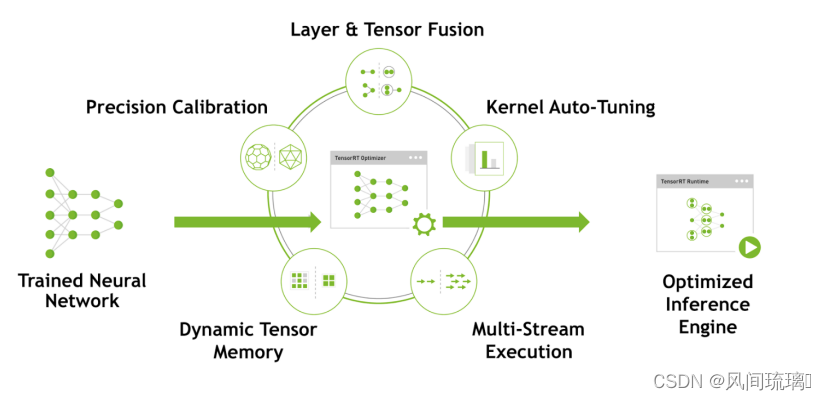
⋆
\star
⋆低精度优化
TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用INT8和FP16,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度,达到加速推断的目的。
⋆
\star
⋆Kernel 自动调优
根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
⋆
\star
⋆算子融合
通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速。比如卷积层、BN层和一个relu层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。
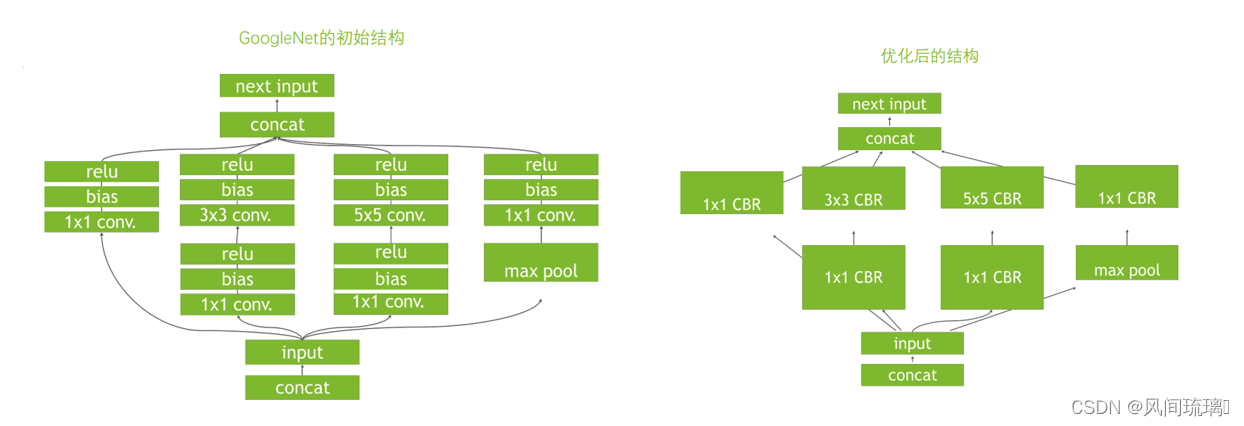
左边是原始网络(googlenet),右边相对原始层进行了垂直优化,将conv+bias(BN)+relu进行了融合优化。具体原理可以参考如下文章:
Conv + BN层融合原理
⋆
\star
⋆多流运行
使用CUDA中的stream技术,最大化实现并行操作
⋆
\star
⋆显存优化
显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间。
2. TensorRT工作流程
TensorRT 工作流程主要有以下步骤:
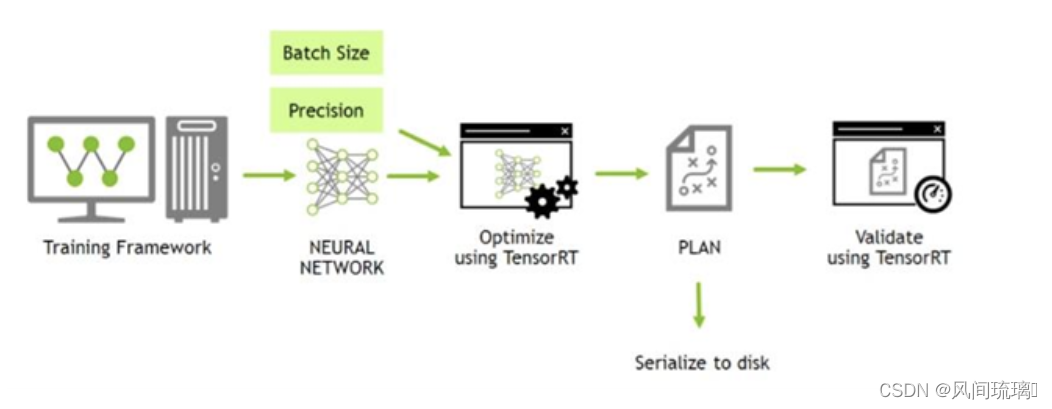
1.训练模型
2.导出模型生成wts文件 / onnx文件
3.wts / onnx 转化成 TensorRT 模型(构建阶段)
4.运行时阶段
前面两个步骤一般是在Python中处理,后面是TensorRT的处理,TensorRT分两个阶段运行
构建(Build)阶段:你向TensorRT提供一个模型定义,TensorRT为目标GPU优化这个模型。这个过程可以离线运行。运行时(Runtime)阶段:使用优化后的模型来运行推理。
一般构建阶段后,我们可以将优化后的模型保存到磁盘上,模型文件可以用于后续加载,以省略模型构建和优化的过程。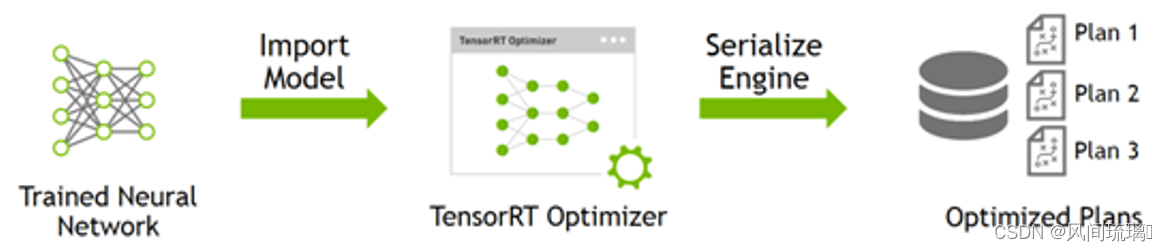
如上图所示,TensorRT需要将不同训练框架训练出来的模型,转换为TensorRT支持的中间表达(IR),并做计算图的优化等,并序列化生成plan文件。
Buidi阶段主要完成模型转换(从Caffe/TensorFlow/Onnx–>TensorRT),在转换阶段会完成优化过程中的计算图融合,精度校准。这一步的输出是一个针对特定GPU平台和网络模型的优化过的TensorRT模型。TensorRT模型可以序列化的存储到磁盘或者内存中,存储到磁盘中的文件叫plan file 。

如上图所示,运行时(Runtime)阶段就是完成前向推理过程,这里将Buidi过程中获得的plan文件首先反序列化,并创建一个runtime engine,然后执行推理引擎并验证输出。
为了优化模型的inference,TensorRT会根据网络的定义执行优化【包括特定平台的优化】并生成engine文件。此过程被称为构建阶段,尤其是在嵌入式平台上会消耗大量的时间,因此,一个典型的应用程序只会被构建一次engine,然后将其序列化为plan文件以供后续使用。保存好的TRT模型文件可以从磁盘重新加载到TRT执行引擎中,不需要再次执行优化步骤。
【注意:生成的plan文件不能跨平台或TensorRT 版本移植。另外,因为plan文件是明确指定GPU 的model,所以我们要想使用不同的GPU来运行plane file必须得重新指定GPU】
二、LeNet-5 部署
深度学习的工作流程,如下图所示,可分为训练和推理两个部分。

训练过程通过设定数据处理方式,并设计合适的网络模型结构以及损失函数和优化算法,在此基础上将数据集以小批量的方式(mini-batch)反复进行前向计算并计算损失,然后反向计算梯度利用特定的优化函数来更新模型,来使得损失函数达到最优的结果。
推理部署是在训练好的模型结构和参数基础上,做一次前向传播得到模型输出的过程。相对于训练而言,推理不涉及梯度和损失优化。推理的最终目标是将训练好的模型部署生产环境中。
下面我们从零开始完成Pytorch模型训练到TensorRT模型部署,这里使用较为简单的LeNet模型。
1.Pytorch实现网络模型
LeNet-5是一种经典的卷积神经网络(CNN),最初用于手写数字的字符识别。这里基于Pytorch框架实现了LeNet-5模型,并使用MNIST数据集进行字符识别。
LeNet(LeNet-5)由两个部分组成:卷积编码器:由两个卷积层组成;全连接层密集块:由三个全连接层组成。如下图所示,
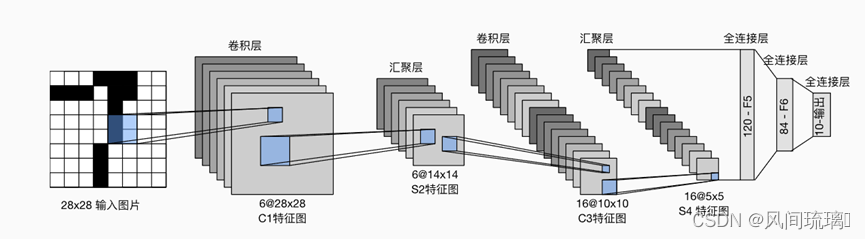
model.py文件:主要完成LeNet网络模型,如上图所示。
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.relu1(self.conv1(x)) # input(1, 28, 28) output(6, 24, 24)
x = self.pool1(x) # output(6, 12, 12)
x = self.relu2(self.conv2(x)) # output(16, 8, 8)
x = self.pool2(x) # output(16, 4, 4)
x = x.view(-1, 16*4*4) # output(16*4*4)
x = F.relu(self.fc1(x)) # output(256)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
train.py文件:完成对上述模型的训练以及模型保存
import os
import sys
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from model import LeNet
from tqdm import tqdm
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 预处理
transform = transforms.Compose(
[transforms.ToTensor(), # 将图像转化为 tensor,并做归一化:[0, 1]
transforms.Normalize((0.5,), (0.5,)) # 输入数据的数值范围标准化为特定的均值和标准差
]
)
batch_size = 32
# min: CPU 核心数量、批次大小(如果大于1),以及一个最大值8
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print("using {} dataloader workers every process".format(nw))
# 加载训练集 MNIST
train_set = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=nw)
train_num = len(train_set)
# 加载测试集 MNIST
val_set = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=1000, num_workers=nw)
val_num = len(val_set)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
# 使用 next 函数从 val_data_iter 迭代器中获取下一个批次的数据
# val_data_iter = iter(val_loader)
# val_image, val_label = next(val_data_iter)
net = LeNet()
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
epochs = 10
best_acc = 0.0
save_path = './LeNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# 设置为训练模式
net.train()
# 每次训练的损失值
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
# 获取批次的索引 step 和数据 data
for step, data in enumerate(train_bar):
# 获取 images, labels; data 是一个列表 [images, labels]
images, labels = data
# 将优化器的梯度缓冲区清零
optimizer.zero_grad()
# forward + backward + optimize
# 前向传播,得到模型的输出
outputs = net(images.to(device))
# 计算模型的输出和真实标签 labels 之间的损失(误差)
loss = loss_function(outputs, labels.to(device))
# 通过反向传播算法计算损失对模型参数的梯度
loss.backward()
# 根据梯度更新模型参数,这是优化器的一次参数更新步骤
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# 设置为测试模式
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
# 测试层仅有最后输出层
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
predict.py文件:使用训练后保存的模型文件进行预测
import os
import torch
import cv2
from torchvision import transforms
from model import LeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 分类标签
classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9')
# 加载图片
img_path = '5.jpg'
assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)
# 使用 OpenCV 加载图像
image = cv2.imread(img_path, 0)
# 转换 BGR 格式为 RGB 格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# [N, C, H, W]
img = transform(image)
# 扩展维度
img = torch.unsqueeze(img, dim=0)
# 加载网络
model = LeNet().to(device)
# 加载模型文件
weights_path = "./LeNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# 对输入图像进行预测
output = torch.squeeze(model(img.to(device))).cpu()
# 对模型的输出进行 softmax 操作,将输出转换为类别概率
predict = torch.softmax(output, dim=0)
# 得到高概率的类别的索引
predict_cla = torch.argmax(predict).numpy()
res = "class: {} prob: {:.3}".format(classes[int(predict_cla)], predict[predict_cla].numpy())
# 在图像上添加文本信息
font = cv2.FONT_HERSHEY_SIMPLEX
position = (10, 30)
font_scale = 1
font_color = (0, 255, 0) # 红色
font_thickness = 2
image = cv2.resize(image, (400, 400))
image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
cv2.putText(image, res, position, font, font_scale, font_color, font_thickness)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(classes[int(i)], predict[i].numpy()))
# 使用 OpenCV 显示图像
cv2.imshow('LeNet', image)
cv2.waitKey(0)
if __name__ == '__main__':
main()
预测结果如下:
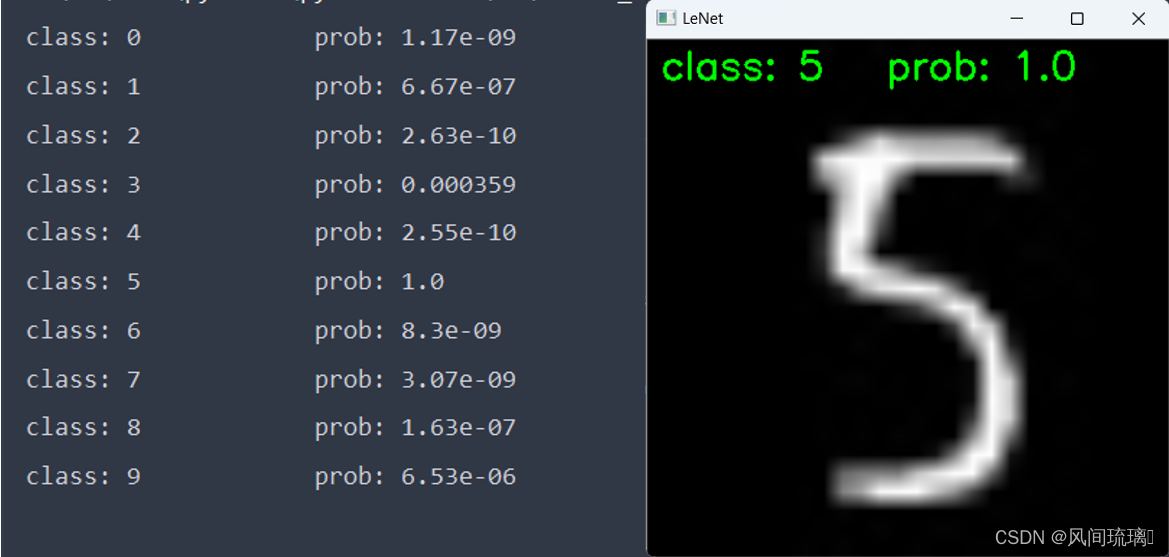
2.WTS文件保存权重数据
在上面我们保存的网络模型文件是pth文件,这是pytorch保存模型的一种方式,该文件只保存模型的参数,模型参数实际上一个字典类型,通过key-value的形式存储。
我们需要将它的参数读取并保存为wts文件。wts文件是权重文件,其中包含神经网络的所有参数,但不包括网络结构。可以在TensorRT中使用wts文件来加载预先训练好的权重。
wts文件格式:
- 第一行代表整个文件有多少行,不包括它本身
- 其余每行格式为: [weight name] [value count = N] [value1] [value2], …, [valueN],该值是16进制的形式
pth转为wts如下所示:
import torch
import struct
from model import LeNet
import os
def convert_pth_to_wts():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)
model = LeNet().to(device)
# 加载模型文件
weights_path = "./LeNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
# 转换权重为 TensorRT 格式
weights_dict = {}
for name, param in model.state_dict().items():
# 将 PyTorch 张量转换为 NumPy 数组
param_np = param.cpu().numpy()
# 展平数组并转换为 float32
param_flat = param_np.flatten().astype('float32')
# 转换为十六进制
param_hex = [struct.pack('>f', float(val)).hex() for val in param_flat]
# 保存到权重字典
weights_dict[name] = param_hex
# 保存为 .wts 文件
with open('LeNet5.wts', 'w') as f:
f.write(f"{len(weights_dict)}\n")
for name, values in weights_dict.items():
print(name)
f.write(f"{name} {len(values)} {' '.join(values)}\n")
if __name__ == '__main__':
convert_pth_to_wts()
导出wts文件如下所示,


将网络的每一层的权重和偏置大小都保存下来,上面对应每一个层权重和偏置的名字也很重要,后面以API构建网络时会使用到的。
3.TensorRT构建阶段( TensorRT 模型文件)
🍎创建Builder
在构建阶段的最高级别接口是 Builder,Builder负责优化一个模型,并产生Engine。
通过如下接口创建一个Builder:
函数原型: inline IBuilder* createInferBuilder(ILogger& logger) noexcept
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
要生成一个可以进行推理的Engine,一般需要以下三个步骤:
- 创建一个Network网络定义 (NetworkDefinition)
- 设置Builder构建配置参数,优化网络模型 (IBuilderConfig)
- 调用Builder生成Engine
🍉创建Network
在TensorRT中使用builder的成员函数createNetworkV2来构建network,其类型为NetworkDefinition。
使用示例如下所示:
函数原型:nvinfer1::INetworkDefinition* createNetworkV2(NetworkDefinitionCreationFlags flags) noexcept
// bit shift,移位:y左移N位,相当于 y * 2^N
// kEXPLICIT_BATCH(显性Batch)为0,1U << 0 = 1
// static_cast:强制类型转换
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
createNetworkV2该函数接受配置参数,参数用按位标记的方式传入,用于设置一些创建网络的标志,一般将explicitBatch对应的配置位设置为1。
🍒使用API构建网络
创建一个神经网络的实例后,可以在创建网络的过程中使用其他 API 函数向网络中添加层、设置输入和输出,通过使用TensorRT的Layer和Tensor等接口一步一步地进行定义。通过接口来定义网络的代码示例如下:
- 输入层
// 向网络添加输入张量(tensor):data[1,28,28]
nvinfer1::ITensor* data = network->addInput(INPUT_BLOB_NAME, nvinfer1::DataType::kFLOAT, nvinfer1::Dims4{1, 1, INPUT_H, INPUT_W});
- 卷积层
nvinfer1::IConvolutionLayer* conv1 = network->addConvolutionNd(*data, 6, nvinfer1::DimsHW{5, 5}, weightMap["conv1.weight"], weightMap["conv1.bias"]);
- 激活层
nvinfer1::IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), nvinfer1::ActivationType::kRELU);
- 池化层
nvinfer1::IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), nvinfer1::ActivationType::kRELU);
- 全连接层
nvinfer1::IFullyConnectedLayer* fc1 = network->addFullyConnected(*pool2->getOutput(0), 120, weightMap["fc1.weight"], weightMap["fc1.bias"]);
以上的参数要传入的Weights kernelWeights 权值参数和Weights biasWeights偏置参数都是来自wts中的,从wts文件中获取权重和偏置参数示例如下。
// 从给定的文件中读取权重数据,并将其存储为一个 std::map 对象,权重名称为key和相应的权重数据为value
std::map<std::string, nvinfer1::Weights> loadWeights(const std::string file)
{
std::cout << "Loading weights: " << file << std::endl;
// 创建一个用于存储权重的映射
std::map<std::string, nvinfer1::Weights> weightMap;
// 打开权重文件
std::ifstream input(file);
// 判断文件是否打开成功,若打开失败,则执行后面打印语句
assert(input.is_open() && "Unable to load weight file.");
// 首先读取权重的数量
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
// 依次处理每一行
while (count--)
{
// 创建一个权重对象并初始化为默认值
nvinfer1::Weights wt{nvinfer1::DataType::kFLOAT, nullptr, 0};
uint32_t size;
// 读取权重的名称和val的数量(十进制)
std::string name;
input >> name >> std::dec >> size;
wt.type = nvinfer1::DataType::kFLOAT;
// 循环读取每一层权重的值
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
{
// 从文件中读取十六进制表示的权重
input >> std::hex >> val[x];
}
wt.values = val;
wt.count = size;
// 将权重添加到 weightMap 中,使用权重的名称作为键 weightMap[features.0.weight] = wt
weightMap[name] = wt;
}
return weightMap;
}
权重和偏置在TensorRT中的类型都是Weights类型,类的定义如下
class Weights
{
public:
DataType type; //!< The type of the weights.
void const* values; //!< The weight values, in a contiguous array.
int64_t count; //!< The number of weights in the array.
};
但我们还必须定义哪些张量是网络的输入(输入值在上面定义了的)和输出。没有被标记为输出的张量被认为是瞬时值,可以被构建者优化掉。输入和输出张量必须被命名,以便在运行时,TensorRT知道如何将输入和输出缓冲区绑定到模型上。示例代码如下:
// 设置输出名字
fc3->getOutput(0)->setName(OUTPUT_BLOB_NAME);
// 标记输出
network->markOutput(*fc3->getOutput(0));
注意:TensorRT的网络定义不会复制参数数组(如卷积的权重)。因此,在构建阶段完成之前,不能释放这些数组的内存。
🍅优化网络
下面就可以来添加相关Builder 的配置。createBuilderConfig接口被用来指定TensorRT应该如何优化模型。如下:
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
在可用的配置选项中,可以控制TensorRT降低计算精度的能力,控制内存和运行时执行速度之间的权衡,并限制CUDA内核的选择。由于构建器的运行可能需要几分钟或更长时间,也可以控制构建器如何搜索内核,以及缓存搜索结果以用于后续运行。
在示例代码中,仅配置workspace(workspace 就是 tensorrt 里面算子可用的内存空间 )大小、运行时batch size和精度 ,如下:
// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间,即配置运行时workspace大小(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 20);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
🫒序列化模型
当网络定义和Builder配置后,可以调用Builder来创建Engine。Builder以一种称为plan的序列化形式创建Engine,它可以立即反序列化,也可以保存到磁盘上供以后使用。需要注意的是,由TensorRT创建的Engine是特定于创建它们的TensorRT版本和创建它们的GPU的,当迁移到别的GPU和TensorRT版本时,不能保证模型能够被正确执行。
示例代码如下:
// 创建engine
nvinfer1::ICudaEngine* engine = createEngine(builder, config);
assert(engine != nullptr);
// 序列化
nvinfer1::IHostMemory* engine_data = engine->serialize();
// 序列化保存engine
std::ofstream engine_file("lenet5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)engine_data->data(), engine_data->size());
engine_file.close();
一般都是将engine文件保存到磁盘上,以供后续使用。
🍊释放资源
在前面申请的资源都应该在程序最后释放,如下所示。
// 关闭所有资源,释放内存
config->destroy();
builder->destroy();
engine->destroy();
engine_data->destroy();
构建阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>
#include <map>
#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"
static Logger gLogger;
static const int INPUT_H = 28;
static const int INPUT_W = 28;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";
// 从给定的文件中读取权重数据,并将其存储为一个 std::map 对象,权重名称为key和相应的权重数据为value
std::map<std::string, nvinfer1::Weights> loadWeights(const std::string file)
{
std::cout << "Loading weights: " << file << std::endl;
// 创建一个用于存储权重的映射
std::map<std::string, nvinfer1::Weights> weightMap;
// 打开权重文件
std::ifstream input(file);
// 判断文件是否打开成功,若打开失败,则执行后面打印语句
assert(input.is_open() && "Unable to load weight file.");
// 首先读取权重的数量
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
// 依次处理每一行
while (count--)
{
// 创建一个权重对象并初始化为默认值
nvinfer1::Weights wt{nvinfer1::DataType::kFLOAT, nullptr, 0};
uint32_t size;
// 读取权重的名称和val的数量(十进制)
std::string name;
input >> name >> std::dec >> size;
wt.type = nvinfer1::DataType::kFLOAT;
// 循环读取每一层权重的值
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
{
// 从文件中读取十六进制表示的权重
input >> std::hex >> val[x];
}
wt.values = val;
wt.count = size;
// 将权重添加到 weightMap 中,使用权重的名称作为键 weightMap[features.0.weight] = wt
weightMap[name] = wt;
}
return weightMap;
}
// 生成engine文件
nvinfer1::ICudaEngine* createEngine(nvinfer1::IBuilder* builder, nvinfer1::IBuilderConfig* config)
{
// 定义网络模型
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
if (!network)
{
std::cout << "Failed to create network" << std::endl;
}
// 加载权重
std::map<std::string, nvinfer1::Weights> weightMap = loadWeights("/home/mingfei/codeRT/test/lenet_wts/LeNet5.wts");
for (const auto& entry : weightMap) {
const std::string& name = entry.first;
const nvinfer1::Weights& weights = entry.second;
std::cout << "Name: " << name << " Count: " << weights.count << std::endl;
}
// 向网络添加输入张量(tensor):data[1,28,28]
nvinfer1::ITensor* data = network->addInput(INPUT_BLOB_NAME, nvinfer1::DataType::kFLOAT, nvinfer1::Dims4{1, 1, INPUT_H, INPUT_W});
assert(data);
// 卷积层1:[1,28,28] --> [6,24,24]
nvinfer1::IConvolutionLayer* conv1 = network->addConvolutionNd(*data, 6, nvinfer1::DimsHW{5, 5}, weightMap["conv1.weight"], weightMap["conv1.bias"]);
assert(conv1);
// relu激活函数
nvinfer1::IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), nvinfer1::ActivationType::kRELU);
assert(relu1);
// [6,24,24] --> [6,12,12]
nvinfer1::IPoolingLayer* pool1 = network->addPoolingNd(*relu1->getOutput(0), nvinfer1::PoolingType::kMAX, nvinfer1::DimsHW{2, 2});
assert(pool1);
// 设置步长
pool1->setStrideNd(nvinfer1::DimsHW{2, 2});
// 卷积层2:[6,12,12] --> [16,8,8]
nvinfer1::IConvolutionLayer* conv2 = network->addConvolutionNd(*pool1->getOutput(0), 16, nvinfer1::DimsHW{5, 5}, weightMap["conv2.weight"], weightMap["conv2.bias"]);
assert(conv2);
nvinfer1::IActivationLayer* relu2 = network->addActivation(*conv2->getOutput(0), nvinfer1::ActivationType::kRELU);
assert(relu2);
// [16,8,8] --> [16,4,4]
nvinfer1::IPoolingLayer* pool2 = network->addPoolingNd(*relu2->getOutput(0), nvinfer1::PoolingType::kMAX, nvinfer1::DimsHW{2, 2});
assert(pool2);
pool2->setStrideNd(nvinfer1::DimsHW{2, 2});
//三层全连接层
nvinfer1::IFullyConnectedLayer* fc1 = network->addFullyConnected(*pool2->getOutput(0), 120, weightMap["fc1.weight"], weightMap["fc1.bias"]);
assert(fc1);
nvinfer1::IActivationLayer* relu3 = network->addActivation(*fc1->getOutput(0), nvinfer1::ActivationType::kRELU);
assert(relu3);
nvinfer1::IFullyConnectedLayer* fc2 = network->addFullyConnected(*relu3->getOutput(0), 84, weightMap["fc2.weight"], weightMap["fc2.bias"]);
assert(fc2);
nvinfer1::IActivationLayer* relu4 = network->addActivation(*fc2->getOutput(0), nvinfer1::ActivationType::kRELU);
assert(relu4);
nvinfer1::IFullyConnectedLayer* fc3 = network->addFullyConnected(*relu4->getOutput(0), 10, weightMap["fc3.weight"], weightMap["fc3.bias"]);
assert(fc3);
// 设置输出名字
fc3->getOutput(0)->setName(OUTPUT_BLOB_NAME);
// 标记输出
network->markOutput(*fc3->getOutput(0));
// 创建engine
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "build out" << std::endl;
// 一旦引擎构建完成,网络对象的存在就不再需要,因为所有的信息已经被引擎所优化
network->destroy();
for (auto& mem : weightMap)
{
// 释放权重数据的内存位置
free((void*) (mem.second.values));
}
return engine;
}
int main()
{
// 创建TensorRT的Builder对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
// 构建TensorRT构建器配置(builder config)
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间,即配置运行时workspace大小(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 20);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
// 创建engine
nvinfer1::ICudaEngine* engine = createEngine(builder, config);
assert(engine != nullptr);
// 序列化
nvinfer1::IHostMemory* engine_data = engine->serialize();
// 序列化保存engine
std::ofstream engine_file("lenet5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)engine_data->data(), engine_data->size());
engine_file.close();
// 释放资源
std::cout << "Engine build success!" << std::endl;
// 关闭所有资源,释放内存
config->destroy();
builder->destroy();
engine->destroy();
engine_data->destroy();
return 0;
}
4.TensorRT运行时阶段(推理)
🍃创建Runtime
TensorRT运行时的最高层级接口是Runtime 如下:
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(gLogger);
当使用Runtime时,通常会执行以下步骤:
- 反序列化模型:反序列化一个plan文件以创建一个Engine
- 从Engine中创建执行上下文context
然后,重复执行:
- 为Inference填充输入缓冲区
- 在ExecutionContext调用enqueueV2()来运行Inference
🍂反序列化模型
通过读取模型文件并反序列化,我们可以利用runtime生成Engine。如下:
// 加载模型文件
auto plan = load_engine_file("lenet5.engine");
// 反序列化生成engine
nvinfer1::ICudaEngine *mEngine = runtime->deserializeCudaEngine(plan.data(), plan.size(), nullptr);
mEngine 接口代表一个优化的模型。可以查询mEngine 关于网络的输入和输出张量的信息,如:预期尺寸、数据类型、数据格式等。load_engine_file这个函数是将上面保存的lenet5.engine文件加载进来,
☘️创建ExecutionContext
有了Engine后需要创建ExecutionContext 以用于后面的推理执行。
// 创建执行上下文context
nvinfer1::IExecutionContext *context = mEngine->createExecutionContext();
从Engine创建的ExecutionContext接口是调用推理的主要接口。ExecutionContext包含与特定调用相关的所有状态,因此可以有多个与单个引擎相关的上下文,且并行运行它们。
🍀传输计算数据(host->device)
在传输数据时还需要对输入的图片做预处理,这里的预处理可以在CPU上处理也可以在GPU上处理,在GPU上处理可以加快处理速度,但是需要编写核函数,这里是在CPU上对图片进行预处理,预处理主要是调整输入图片大小、归一化以及减均值等操作,如下所示
cv::Mat preprocess(cv::Mat &image)
{
// 获取图像的形状(高度、宽度和通道数)
int height = image.rows;
int width = image.cols;
int channels = image.channels();
// 打印图像的形状
std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
// 使用blobFromImage函数创建blob
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));
// 获取图像的形状(高度、宽度和通道数)
height = blob.rows;
width = blob.cols;
channels = blob.channels();
// 打印图像的形状
std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
return blob;
}
然后需要创建CUDA Stream用于推理的执行。stream 可以理解为一个任务队列,调用以 async 结尾的 api 时,是把任务加到队列,但执行是异步的,当有多个任务且互相没有依赖时可以创建多个 stream 分别用于不同的任务,任务直接的执行可以被 cuda driver 调度,这样某个任务做 memcpy时, 另外一个任务可以执行计算任务,这样可以提高 gpu利用率。
// 创建流
cudaStream_t stream;
// 创建CUDA Stream用于context推理
CHECK(cudaStreamCreate(&stream));
然后同时在CPU和GPU上分配输入输出内存,并将输入数据从CPU拷贝到GPU上。
// 为输入和输出设备缓冲区创建指针以传递给引擎
assert(engine.getNbBindings() == 2);
void* buffers[2];
// 为了绑定缓冲区,需要知道输入和输出张量的名称
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
// 在设备上创建输入和输出缓冲区
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
注意,在使用enqueueV2进行推理的时候是把输入输出的内存地址放到buffers这个数组中,需要确定这些输入输出的顺序。
🌿执行推理
将数据从CPU中拷贝到GPU上后,便可以调用enqueueV2 进行推理。
context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2
🍁传输计算结果(device->host)
执行完推理后需要把推理的结果从GPU拷贝到CPU。
// 将推理结果从设备拷贝到主机上:output
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
// stream同步,等待stream中的操作完成
cudaStreamSynchronize(stream);
🌼释放资源
同样地在运行时阶段也需要释放申请的资源。
// 释放资源
context->destroy();
mEngine->destroy();
runtime->destroy();
运行时阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>
#include <algorithm>
#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
static Logger gLogger;
static const int INPUT_H = 28;
static const int INPUT_W = 28;
static const int OUTPUT_SIZE = 10;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";
#define CHECK(status) \
do\
{\
auto ret = (status);\
if (ret != 0)\
{\
std::cerr << "Cuda failure: " << ret << std::endl;\
abort();\
}\
} while (0)
// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{
std::vector<unsigned char> engine_data;
// 打开二进制文件流
std::ifstream engine_file(file_name, std::ios::binary);
// 检查文件是否成功打开
assert(engine_file.is_open() && "Unable to load engine file.");
// 定位到文件末尾以获取文件长度
engine_file.seekg(0, engine_file.end);
int length = engine_file.tellg();
// 调整容器大小以存储整个文件的数据
engine_data.resize(length);
// 重新定位到文件开头
engine_file.seekg(0, engine_file.beg);
// 读取文件数据到容器中
engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);
return engine_data;
}
std::vector<float> softmax(const float input[10])
{
std::vector<float> result(10);
float sum = 0.0;
// Calculate e^x for each element in the input array
for (int i = 0; i < 10; ++i) {
result[i] = std::exp(input[i]);
sum += result[i];
}
// Normalize the values by dividing each element by the sum
for (float& value : result) {
value /= sum;
}
return result;
}
// 执行推理
void inference(nvinfer1::IExecutionContext& context, float* input, float* output, int batchSize)
{
// 获取与上下文相关的引擎
const nvinfer1::ICudaEngine& engine = context.getEngine();
// 为输入和输出设备缓冲区创建指针以传递给引擎
assert(engine.getNbBindings() == 2);
void* buffers[2];
// 为了绑定缓冲区,需要知道输入和输出张量的名称
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
// 在设备上创建输入和输出缓冲区
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
// 创建流
cudaStream_t stream;
// 创建CUDA Stream用于context推理
CHECK(cudaStreamCreate(&stream));
// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2
// 将推理结果从设备拷贝到主机上:output
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
// stream同步,等待stream中的操作完成
cudaStreamSynchronize(stream);
// 释放流和缓冲区
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
}
cv::Mat preprocess(cv::Mat &image)
{
// 获取图像的形状(高度、宽度和通道数)
int height = image.rows;
int width = image.cols;
int channels = image.channels();
// 打印图像的形状
std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
// 使用blobFromImage函数创建blob
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));
// 获取图像的形状(高度、宽度和通道数)
height = blob.rows;
width = blob.cols;
channels = blob.channels();
// 打印图像的形状
std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
return blob;
}
int main()
{
// 读取图像
cv::Mat image = cv::imread("/home/mingfei/codeRT/test/lenet_wts/8.jpg");
// 检查图像是否成功加载
if (image.empty()) {
std::cerr << "Error: Unable to read the image." << std::endl;
return -1;
}
// 创建推理运行时runtime
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(gLogger);
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
// 加载模型文件
auto plan = load_engine_file("lenet5.engine");
// 反序列化生成engine
nvinfer1::ICudaEngine *mEngine = runtime->deserializeCudaEngine(plan.data(), plan.size(), nullptr);
if (!mEngine)
{
return -1;
}
// 创建执行上下文context
nvinfer1::IExecutionContext *context = mEngine->createExecutionContext();
if (!context)
{
std::cout << "context create failed" << std::endl;
return -1;
}
// 运行推理
cv::Mat blob = preprocess(image);
// 获取blob的数据指针
uchar* ucharData = blob.ptr<uchar>(); // 使用uchar*类型的指针
// 获取图像数据指针
float* data = reinterpret_cast<float*>(ucharData);
float prob[OUTPUT_SIZE];
inference(*context, data, prob, 1);
// softmax
std::vector<float> result = softmax(prob);
// 找到最大值和索引
auto maxElement = std::max_element(result.begin(), result.end());
float maxValue = *maxElement;
int maxIndex = std::distance(result.begin(), maxElement);
// 打印结果
std::cout << "probability: " << maxValue << std::endl;
std::cout << "Number is : " << maxIndex << std::endl;
// 显示
std::ostringstream text;
text << "Predict: " << maxIndex;
cv::resize(image,image,cv::Size(400,400));
cv::putText(image, text.str(), cv::Point(10, 50), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1, cv::LINE_AA);
// 保存图像到当前路径
cv::imwrite("output_image.jpg", image);
// 释放资源
context->destroy();
mEngine->destroy();
runtime->destroy();
return 0;
}
5.编译和运行
我的整个工程如下
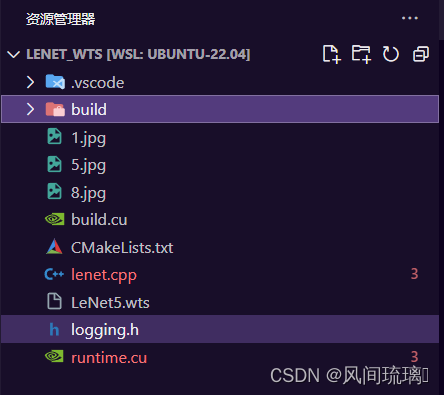
使用CMakeLists.txt来构建整个工程,lenet.cpp相当于集成了build.cu和runtime.cu,然后将生成的文件保存在build目录下。
- 方式一:cmake
生成可执行程序:
cmake -S . -B build (–> Makefile)
cmake --build build (–>可执行程序)
运行可执行程序:
./build/build
./build/runtime
- 方式二:cmake + make
生成可执行程序:
cd build
cmake … (–>Makefile)
make (–>可执行程序)
运行可执行程序:
./build
./runtime
以上两种都可以用于编译和运行程序,各有各的好处,方式一的指令都是在CmakeLists.txt的同级目录下执行的,而方式而需要切换到build的目录下执行的。
CmakeLists.txt如下
cmake_minimum_required(VERSION 3.10)
# 支持c++和cuda编译(nvcc)
project(lenet LANGUAGES CXX CUDA)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
include_directories(${PROJECT_SOURCE_DIR}/include)
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/usr/include/x86_64-linux-gnu/)
link_directories(/usr/lib/x86_64-linux-gnu/)
# opencv
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# lenet
add_executable(lenet ${PROJECT_SOURCE_DIR}/lenet.cpp)
target_link_libraries(lenet nvinfer)
target_link_libraries(lenet cudart)
target_link_libraries(lenet ${OpenCV_LIBS})
set_target_properties(lenet PROPERTIES CUDA_ARCHITECTURES "61;70;75")
# build
add_executable(build ${PROJECT_SOURCE_DIR}/build.cu)
target_link_libraries(build nvinfer)
target_link_libraries(build cudart)
target_link_libraries(build ${OpenCV_LIBS})
# set: CMAKE_CUDA_ARCHITECTURES
set_target_properties(build PROPERTIES CUDA_ARCHITECTURES "61;70;75")
# runtime
add_executable(runtime ${PROJECT_SOURCE_DIR}/runtime.cu)
target_link_libraries(runtime nvinfer)
target_link_libraries(runtime cudart)
target_link_libraries(runtime ${OpenCV_LIBS})
set_target_properties(runtime PROPERTIES CUDA_ARCHITECTURES "61;70;75;86")
add_definitions(-O2 -pthread)
最后程序运行结果如下,测试了几张图片,基本上预测准确率很高的。

三、TensorRT 常用API
以下是我在学习TensorRT中常使用的函数,由于新版的更新,所以下面有的是老版本的函数。
1.addinput
void addInput(const char* layerName, DataType dtype, Dims dims)
name: 输入张量的名称,是一个字符串。
type: 输入张量的数据类型,是一个 DataType 枚举值,如 DataType::kFLOAT 表示浮点数类型。
dimensions: 输入张量的维度信息,是一个 Dims 对象,描述了输入张量的形状。可以根据实际情况设置输入张量的维度,如 Dims3{3, INPUT_H, INPUT_W} 表示一个三通道的图像输入。
作用:用于向网络添加输入张量(tensor),并返回对应的 ITensor 指针,以便在构建网络时使用。这个输入张量通常用于将模型输入的数据喂入到TensorRT中进行推理。
2.addConvolutionNd
IConvolutionLayer* addConvolutionNd(ITensor& input, int nbOutputMaps, Dims kernelSize, Weights kernel, Weights bias)
input: 输入张量,是卷积层的输入。
nbOutputMaps: 卷积核的数量,即输出通道数。
kernelSize: 卷积核的大小,是一个 Dims 对象,描述了卷积核的尺寸。
kernel: 卷积核的权重,是一个 Weights 对象,包含了卷积核的权重值。
bias: 卷积核的偏置,是一个 Weights 对象,包含了卷积核的偏置值。
作用:在网络中添加卷积层,并返回对应的 IConvolutionLayer 指针。卷积层是神经网络中常用的一种层,通过卷积操作可以提取输入数据的特征。
3.setStrideNd和setPaddingNd
void setStrideNd(Dims stride) noexcept
void setPaddingNd(Dims padding) noexcept
setStrideNd 和 setPaddingNd 是设置卷积层的步幅(stride)和填充(padding)的方法。
setStrideNd 用于设置卷积层在每个维度上的步幅大小。步幅是卷积核在输入上滑动的间隔,它决定了输出张量的空间维度。例如,如果步幅为 (s_h, s_w),那么在水平方向上每次移动 s_w 个像素,在垂直方向上每次移动 s_h 个像素。
setPaddingNd 用于设置卷积层在每个维度上的填充大小。填充是在输入张量的边界上添加额外的像素,以便在卷积过程中可以考虑输入张量的边界信息。填充可以帮助防止在卷积过程中丢失输入张量的边缘信息。
4.addActivation
IActivationLayer* addActivation(ITensor& input, ActivationType type)
input: 输入张量,即前一层的输出。
type: 激活函数的类型,可以是 ActivationType 枚举中的一种
kRELU = 0, //!< Rectified linear activation.
kSIGMOID = 1, //!< Sigmoid activation.
kTANH = 2, //!< TanH activation.
kLEAKY_RELU = 3, //!< LeakyRelu activation: x>=0 ? x : alpha * x.
kELU = 4, //!< Elu activation: x>=0 ? x : alpha * (exp(x) - 1).
kSELU = 5, //!< Selu activation: x>0 ? beta * x : beta * (alpha*exp(x) - alpha)
kSOFTSIGN = 6, //!< Softsign activation: x / (1+|x|)
kSOFTPLUS = 7, //!< Parametric softplus activation: alpha*log(exp(beta*x)+1)
kCLIP = 8, //!< Clip activation: max(alpha, min(beta, x))
kHARD_SIGMOID = 9, //!< Hard sigmoid activation: max(0, min(1, alpha*x+beta))
kSCALED_TANH = 10, //!< Scaled tanh activation: alpha*tanh(beta*x)
kTHRESHOLDED_RELU = 11 //!< Thresholded ReLU activation: x>alpha ? x : 0
用于向神经网络中添加激活层,激活层对输入张量的每个元素应用激活函数,以引入非线性性
5.addPoolingNd
IPoolingLayer* addPoolingNd(ITensor& input, PoolingType type, Dims windowSize);
input: ITensor& input 表示要应用池化的输入张量。通常,这是前一层的输出。
type: PoolingType type 表示池化类型。可以是 PoolingType::kMAX(最大池化)、PoolingType::kAVERAGE(平均池化)等。
windowSize: Dims windowSize 表示池化窗口的大小。这是一个描述池化窗口大小的 Dims 对象,它可以是一维、二维或三维,具体取决于数据的维度。在 2D 池化中,windowSize 通常是 DimsHW 类型。
用于向网络中添加池化层。
6.addFullyConnected
IFullyConnectedLayer* addFullyConnected(ITensor& input, int32_t numOutputChannels, Weights kernelWeights, Weights biasWeights);
input: ITensor& input 表示要应用全连接的输入张量。通常,这是前一层的输出。
numOutputChannels: int32_t numOutputChannels 表示全连接层的输出通道数,即输出张量的深度。
kernelWeights: Weights kernelWeights 表示全连接层的权重。这是一个包含权重数据的结构体。
biasWeights: Weights biasWeights 表示全连接层的偏置。这是一个包含偏置数据的结构体。
用于向网络中添加全连接层,全连接层的作用是将输入张量的每个元素与权重相乘,然后将结果相加,最终得到输出张量。
7.getOutput和markOutput
ITensor* getOutput(int32_t index) const noexcept
index:一个整数,指定要检索的输出张量的索引。索引从 0 开始。
void markOutput(ITensor& tensor) noexcept
tensor:要标记为网络输出的 ITensor 对象的引用。
getOutput用于在网络中检索特定索引处的输出张量;markOutput用于标记给定的张量作为网络的输出。
如果不标记输出,TensorRT 将在推断期间计算网络的所有张量,这可能包括一些您不关心的中间计算结果。这可能会导致不必要的计算和内存占用,从而降低推断的效率。此外,如果没有标记输出,将无法直接获取和处理网络的最终预测结果。
8.setMaxBatchSize
TRT_DEPRECATED void setMaxBatchSize(int32_t batchSize) noexcept
用于设置 TensorRT 引擎的最大批处理大小。最大批处理大小是在构建 TensorRT 引擎时确定的一个参数,表示引擎可以同时处理的最大输入样本数。
9.setMaxWorkspaceSize
TRT_DEPRECATED void setMaxWorkspaceSize(std::size_t workspaceSize) noexcept
workspaceSize:工作空间的最大尺寸,以字节为单位。
1 << 20 : 1MB
1 << 30 : 1GB
用来设置引擎运行时所需的工作空间(workspace)的最大尺寸的方法。工作空间是在 TensorRT 运行时用于存储中间计算结果、临时缓冲区等的内存空间。
设置工作空间的大小是为了确保在运行时引擎有足够的内存来执行前向传播和后向传播的计算。TensorRT 会在编译过程中分配一些内存用于存储中间结果,工作空间的大小就是限制这个分配的上限。
10.buildEngineWithConfig
nvinfer1::ICudaEngine* buildEngineWithConfig(INetworkDefinition& network, IBuilderConfig& config) noexcept
network: 构建引擎所使用的网络结构。这通常是使用 IBuilder 创建的网络结构。
config: 引擎的配置,包括一些关于引擎优化和行为的设置。可以通过 IBuilderConfig 接口进行配置。
该函数的作用是基于给定的网络结构和配置,生成一个可在 CUDA 上运行的TensorRT 引擎。引擎是 TensorRT 运行推断的核心组件,可以在 GPU 上高效地执行神经网络模型。
11.createInferBuilder
inline IBuilder* createInferBuilder(ILogger& logger) noexcept
gLogger: 是一个用于日志输出的 ILogger 接口。ILogger 是 TensorRT 提供的一个日志接口。通常,createInferBuilder 会使用一个默认的 ILogger 实现,将日志输出到标准输出。
该函数的作用是创建一个 IBuilder 实例,使用户能够使用 TensorRT 的 API 构建、配置和优化神经网络模型。
12.createBuilderConfig
nvinfer1::IBuilderConfig* createBuilderConfig() noexcept
用户可以使用 IBuilderConfig 的方法设置不同的选项,具体取决于 TensorRT 版本和使用情况。一些常见的选项包括设置精度、设置 GPU 设备、设置工作空间大小、设置打开或关闭某些 TensorRT 功能等。
13.serialize
IHostMemory* serialize() const noexcept
返回一个指向 IHostMemory 接口的指针,通过该指针可以获取包含序列化引擎数据的主机内存。
在构建好 TensorRT 引擎后,通常需要将其序列化为二进制数据以进行存储,以便在推理时能够加载并使用。serialize 方法就是用于执行这个序列化过程。
当调用 serialize 方法后,它会返回一个 IHostMemory 对象,该对象包含了 TensorRT 引擎的二进制表示。用户可以将这个二进制数据保存到文件、内存或其他存储介质中。在后续的推理过程中,可以使用这个二进制数据来快速加载 TensorRT 引擎,而不需要重新构建。
14.createInferRuntime
inline IRuntime* createInferRuntime(ILogger& logger) noexcept
ILogger& logger: 一个用于记录日志的接口。TensorRT 将日志信息通过此接口输出。
该函数用于创建 IRuntime 实例,即 TensorRT 运行时环境。IRuntime 是 TensorRT 运行时的主要接口,用于推理引擎的执行和管理。在创建 IRuntime 实例后,可以使用它加载和执行推理引擎,管理推理过程中所需的资源等。
15.deserializeCudaEngine
nvinfer1::ICudaEngine* deserializeCudaEngine(void const* blob, std::size_t size, IPluginFactory* pluginFactory) noexcept
void const* blob: 指向序列化引擎数据的指针。
std::size_t size: 序列化引擎数据的大小(以字节为单位)。
IPluginFactory* pluginFactory: 一个用于创建自定义插件的工厂对象。如果引擎包含自定义插件,需要提供一个插件工厂。
deserializeCudaEngine 函数是 TensorRT 中用于反序列化 CUDA 引擎的函数。
该函数用于从序列化的引擎数据中创建一个 CUDA 引擎。在序列化引擎之后,可以使用此函数将其还原为可执行的 CUDA 引擎。如果引擎包含自定义插件,需要通过 pluginFactory 参数提供插件工厂。
16.createExecutionContext
IExecutionContext* createExecutionContext() noexcept
此方法用于创建一个执行上下文 (IExecutionContext)。执行上下文是 TensorRT 中用于运行推断的对象。通过创建执行上下文,可以将输入数据传递给引擎,执行推断,并获得输出结果。在创建执行上下文之前,必须先构建引擎并将其序列化为可执行的 CUDA 引擎。
17.getNbBindings
int32_t getNbBindings() const noexcept
此方法用于获取 CUDA 引擎中绑定的输入和输出张量的数量。TensorRT 中的引擎可以具有多个输入和输出张量,getNbBindings 可以告诉你有多少个张量与引擎相关联。
18.getBindingIndex
int32_t getBindingIndex(char const* name) const noexcept
char const* name:要查询索引的绑定名称
此方法用于获取给定名称的张量在 CUDA 引擎中的绑定索引。TensorRT 引擎可以有多个输入和输出张量,每个张量都有一个唯一的名称。通过此方法,你可以通过张量的名称查找其在引擎中的索引。
19.cudaMemcpyAsync
__host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaMemcpyAsync(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream __dv(0));
void *dst:目标内存地址,即要将数据复制到的位置。
const void *src:源内存地址,即要复制的数据的位置。
size_t count:要复制的字节数。
enum cudaMemcpyKind kind:指定数据传输的方向,可能的取值包括:
cudaMemcpyHostToHost:从主机内存复制到主机内存。
cudaMemcpyHostToDevice:从主机内存复制到设备内存。
cudaMemcpyDeviceToHost:从设备内存复制到主机内存。
cudaMemcpyDeviceToDevice:在设备之间复制。
cudaStream_t stream:可选参数,指定用于执行操作的 CUDA 流。默认值为 0,表示使用默认流。
cudaMemcpyAsync 函数用于在 GPU 设备和主机之间异步传输数据。它允许异步执行内存传输,即在数据传输的同时,可以在 GPU 上执行其他任务,提高了并行性。
20.cudaStreamSynchronize
__host__ cudaError_t CUDARTAPI cudaStreamSynchronize(cudaStream_t stream);
cudaStream_t stream:指定要同步的 CUDA 流。
cudaStreamSynchronize 函数用于等待指定的 CUDA 流上的所有任务完成。它将使主机线程阻塞,直到与给定流相关联的所有操作都已完成。
在异步 CUDA 编程中,通过将任务放入 CUDA 流中,可以实现并发执行。使用 cudaStreamSynchronize 函数可以确保在主机继续执行之前等待流上的任务完成。在异步 CUDA 编程中,使用 CUDA 流可以在 GPU 上执行多个任务,而不必等待每个任务完成。通过同步 CUDA 流,程序可以在需要确保某个特定任务已完成时进行显式同步。
21enqueue
bool enqueue(int32_t batchSize, void* const* bindings, cudaStream_t stream, cudaEvent_t* inputConsumed) noexcept
batchSize:指定推理请求中的批处理大小。
bindings:包含输入和输出缓冲区的数组,是一个指向指针的数组。这些指针指向相应的输入和输出数据缓冲区。
stream:CUDA 流,用于在异步模式下执行推理。如果为 nullptr,则在默认流中执行推理。
inputConsumed:一个可选的 CUDA 事件,表示输入数据是否已在流中使用。如果不为 nullptr,并且在调用 enqueue 后,inputConsumed 事件会在输入数据被引擎使用后触发。
将推理请求推入引擎的执行队列中,异步执行推理操作。如果在异步模式下使用,enqueue 函数将立即返回,而不会等待推理完成。在执行推理之前,确保将输入数据传递给 bindings 指定的输入缓冲区。在执行之后,可以从 bindings 中的输出缓冲区中提取输出数据。
22.enqueueV2
bool enqueueV2(void* const* bindings, cudaStream_t stream, cudaEvent_t* inputConsumed) noexcept
bindings: 一个包含指向输入和输出数据的指针数组。这些指针是通过 cudaMalloc 分配的 GPU 内存,包含了模型输入和输出的数据。
stream: 用于执行异步推理的 CUDA 流(cudaStream_t)。
inputConsumed: 输入数据已被引擎消耗的 CUDA 事件。可以为 nullptr,表示不需要等待。
outputProduced: 输出数据已经被引擎生成的 CUDA 事件。可以为 nullptr,表示不需要等待。
函数的返回值是一个布尔值,表示推理是否成功。
这个函数的主要作用是触发 TensorRT 引擎执行推理操作,根据输入数据生成输出数据。在异步推理中,可以使用 stream 参数来指定 CUDA 流,以便在 GPU 上进行异步操作。
23.seekg
std::istream& seekg (std::streampos pos);
std::istream& seekg (std::streamoff off, std::ios_base::seekdir way);
seekg 用于设置文件输入流的读取位置。第一种形式将文件指针直接设置到绝对位置 pos 处,而第二种形式根据 way 参数和相对偏移量 off进行定位。
file.seekg(0, file.end);
这一行代码将文件指针移动到文件的末尾。第一个参数 0 表示偏移量,第二个参数 file.end 表示从文件末尾开始计算偏移。
24.tellg
std::istream::pos_type tellg();
tellg 返回当前的读取位置(以 pos_type 类型表示),通常用于确定文件指针的当前位置。
size = file.tellg();
这一行代码获取当前文件指针的位置,即文件的长度。这在确定文件大小时很有用。
25.good
bool good() const;
good 返回一个布尔值,指示流的状态是否良好。如果流状态良好,返回 true;否则,返回 false。流的状态良好意味着文件已成功打开且未发生错误。
if (file.good()) {
// ...
}
这一行代码检查文件流的状态,以确保文件成功打开且未发生错误。如果流状态良好,条件成立。
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











