







概述

从课程地图上可以看出来,这是本门课程中第一次正式的介绍强化学习的算法,并且是一个 model-based 的算法,而在下一节课将会介绍第一个 model-free 的算法(在 chapter 5)。而这两节和之前所学的 BOE 是密切相关的:value iteration 在 BOE 中已经介绍过,但是不够正式,而 policy iteration 则是下一节 Monte Carlo Learning 的一个基础。
本节课大纲如下:

这三者联系同样非常紧密,实际上值迭代和策略迭代是 truncated policy iteration 的两种极端情况。
Value iteration algorithm

从上图可以看到,实际上之前通过迭代的方式求解贝尔曼最优公式的过程就是这里要学习的 value iteration 算法。
其算法过程包括两部分,第一部分就是首先会给定 Vk,要求解这个嵌套在这个 BOE 式子当中的一个优化问题也就是求解 Π,当这个 Π 被求解出来以后,然后再求解出来这个 Vk+1 即可。
也就是下图所对应的两个步骤:

注意上图中最后留下的问题:Vk 是一个 state value 吗?
乍一看好像 Vk 就是一个 state value,然而并不是。右边是 Vk,左边是V(k+1),如果左边是 Vk 那么该式子确实是一个贝尔曼公式,求得的解就是 state value,但是左边并不是 Vk,因此并非 state value。
那它是什么呢?其实就是一个向量,一个值,Vk 只是某次迭代过程中还没有收敛的一个值。为什么叫值迭代算法?就是因为它可以是任意的值,然后慢慢迭代到 state value 罢了。
接下来我们使用 elementwise form 来实现 值迭代 算法(矩阵向量形式适合理论研究):

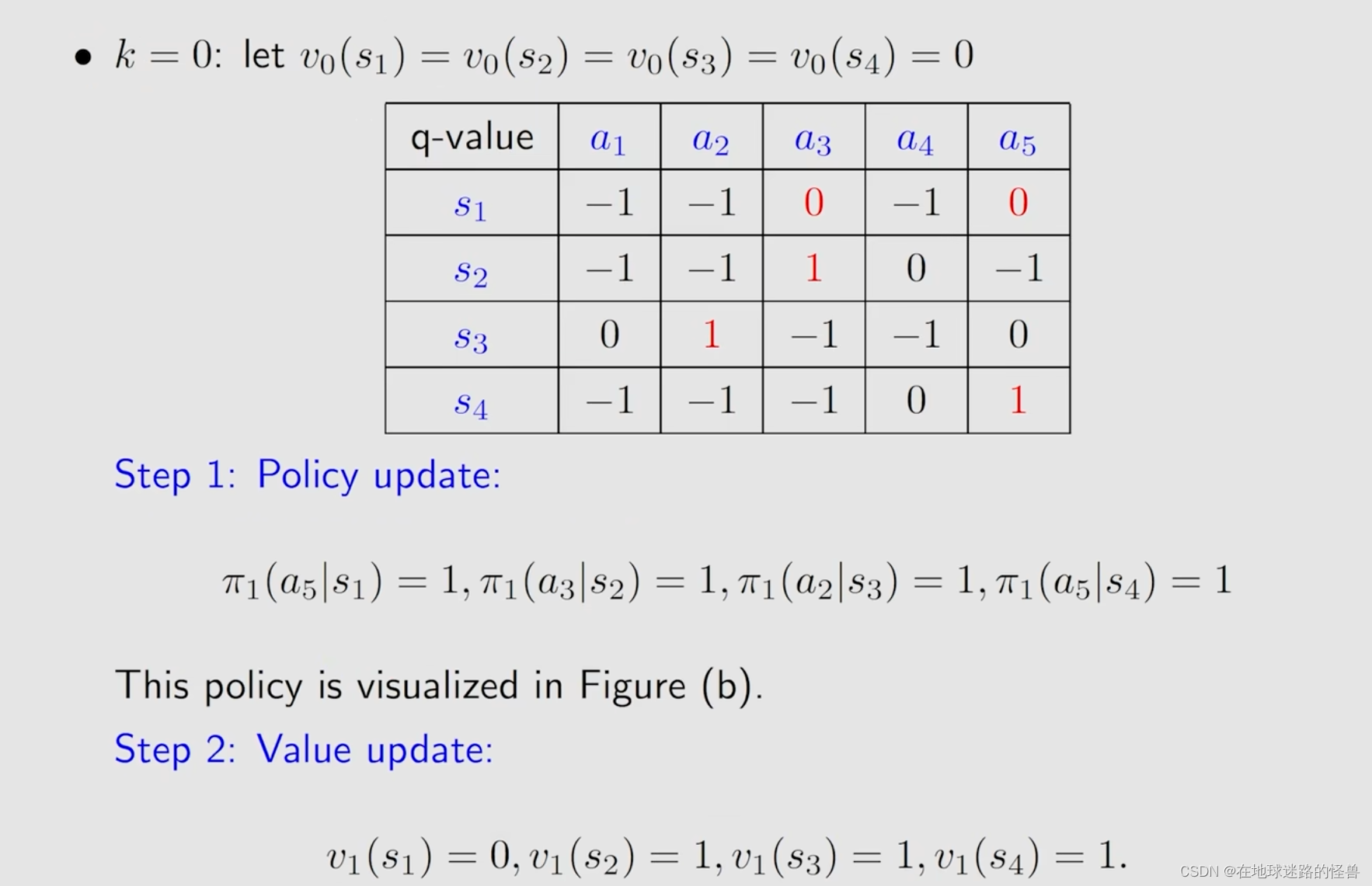
首先是第一步,策略更新:

然后是第二步,值更新:

合起来的过程如下:

算法实例:


Value iteration algorithm Code Implementation
注意在 PyCharm 上测试时,需要打开如下图中的配置:

代码如下:
import numpy as np
import time
import os
def get_reward(location, action, graph):
# r, c 表示地图的行数和列数
r, c = len(graph), len(graph[0])
reward = -1 # 默认奖励为 -1,因为要求走最短路径
# row, col 表示当前所在行列位置
row, col = location
# 采取行动为0,表示往上,那么当前位置的行数+1
if action == 0:
row = row - 1
# 采取行动为1,表示往下,那么当前位置的行数-1
elif action == 1:
row = row + 1
# 采取行动为2,表示往左,那么当前位置的列数-1
elif action == 2:
col = col - 1
# 采取行动为3,表示往右,那么当前位置的列数+1
elif action == 3:
col = col + 1
# 如果采取了action后的所在行列位置越界了,reward-1
if row < 0 or row > r - 1 or col < 0 or col > c - 1:
reward = -1
# 如果采取了action后的所在行列位置在forbidden area,reward-100
# 这表示我们并不想让 agent 走进 forbidden area
elif graph[row][col] == '×':
reward = -100
# 如果采取了action后的所在行列位置在目标位置了,reward+20
elif graph[row][col] == '●':
reward = 20
# 控制边界约束, 防止越界异常
row = max(0, row)
row = min(r - 1, row)
col = max(0, col)
col = min(c - 1, col)
# 返回下一个状态以及奖励
return row, col, reward
# 在Python 3中,几乎所有的类都默认继承自object类,即使你不显式地写出来
class Solver(object):
def __init__(self, r: int, c: int):
"""
:param r: 代表当前地图行数
:param c: 代表当前地图列数
"""
# 初始化动作空间
# 在Python中,大括号 {} 通常用来表示一个字典(dictionary)。
# 字典是Python中一种内置的数据结构,用于存储键值对(key-value pairs)。
# 每个键(key)都是唯一的,并且与一个值(value)相关联。
self.idx_to_action = {0: '↑', 1: '↓', 2: '←', 3: '→', 4: 'O'}
# 初始化地图行数、列数、动作个数
self.r, self.c, self.action_nums = r, c, len(self.idx_to_action)
# 随机初始化状态价值矩阵
self.state_value_matrix = np.random.randn(r, c)
# 随机初始化动作价值矩阵,这是一个三维矩阵
# 这个矩阵用于表示在某个状态(由r和c指定)下,执行不同动作(由len(self.idx_to_action)确定)的“价值”或“评分”。
self.action_value_matrix = np.random.randn(r, c, len(self.idx_to_action))
# 随机初始化当前最优策略
# self.cur_best_policy 被赋予了这个二维数组,它用于表示在当前学习或评估过程中,
# 对于每个状态(由 r 行和 c 列定义的状态空间中的每个点),算法认为的最佳动作(或动作索引)。
# 然而,由于这些值是随机抽取的,所以它们并不代表真正的最优策略,而只是作为初始值或某种随机策略的一部分。
# np.random.choice 是 NumPy 库中的一个函数,用于从给定的一维数组中随机抽取元素,或者从指定的范围中随机生成整数
# size=(r, c) 指定了输出数组的形状。
# 因此,np.random.choice 会生成一个形状为 (r, c) 的二维数组,其中每个元素都是从上述范围内随机抽取的一个整数
self.cur_best_policy = np.random.choice(len(self.idx_to_action), size=(r, c))
# 打印当前的最优策略
def show_policy(self):
# [self.idx_to_action[idx] for idx in i] 是一个列表推导式,
# 它遍历 i 中的每个元素(假设 i 是一个可迭代对象,比如列表或元组,且其元素是索引),
# 并使用这些索引从 self.idx_to_action(假设这是一个字典或列表,将索引映射到动作名称或动作本身)中检索对应的动作。
# 然后,print 函数的星号操作符 * 用于解包这个列表,使得列表中的每个元素都作为 print 函数的一个单独的位置参数,
# 从而它们会被打印出来,并且默认会在它们之间添加空格作为分隔符。
# 更具体的解释可以看本文代码后面的相关语法解析
for i in self.cur_best_policy.tolist():
print(*[self.idx_to_action[idx] for idx in i], sep=' ')
# 显示地图
def show_graph(self, graph):
for i in graph:
print(*i, sep=' ')
# 清空控制台
def clear_console(self):
"""
通过os.name属性,可以获取一个字符串,该字符串表示Python正在运行的操作系统。
对于Windows系统,os.name的值是'nt'(代表“New Technology”,是Windows NT及其后续版本的缩写)。
对于大多数Unix-like系统(包括Linux和macOS),os.name的值是'posix'。
对于代码 _ = os.system(...):
其使用了_(通常用作Python中的“don't care”变量,即一个用于接收不需要使用的值的变量名)来接收os.system(...)的返回值。
如果不关心返回值的话,不写 _ 也是可以的,但这是一种良好的编程习惯
"""
if os.name == 'nt': # 对于 windows 系统
_ = os.system('cls')
else: # 对于 Linux 和 mac
_ = os.system('clear')
# 打印点到点的动态运行过程
def show_point_to_point(self, start_point, end_point, graph):
# 越界检测
assert (0 <= start_point[0] < self.r) and (
0 <= start_point[1] < self.c), f'The start_point is {start_point}, is out of range.'
assert (0 <= end_point[0] < self.r) and (
0 <= end_point[1] < self.c), f'The end_point is {end_point}, is out of range.'
# 记录起始点
row, col = start_point
i = 0
# 开始展示动态运行过程
while True:
# 在起始点根据当前的最优策略选择采取的行动
graph[row][col] = self.idx_to_action[self.cur_best_policy[row][col]]
# 选择行动之后,清空控制台
self.clear_console()
# 显示地图
self.show_graph(graph)
# 为了方便观察,沉睡 0.5 s
time.sleep(0.5)
# 根据最优策略选择action后所进入的下一个状态[row][col]以及对应得到的 reward 值
# 对于打印动态运行过程来说 reward 并没有用,因此这里没有接收 reward 值
row, col, _ = get_reward((row, col), self.cur_best_policy[row][col], graph)
# 循环退出条件为:要么已经到达最终状态,要么i已经大于了 r*c 大小
# 因为如果进行轮次数 i 已经比网格世界的格子数还大了,那么说明无解,当然可以结束
if (row, col) == end_point or i > self.r * self.c:
break
# 轮次数量+1
i += 1
class ValueIterationSolver(Solver):
"""值迭代算法"""
def __init__(self, r: int, c: int):
# super() 函数返回了一个代表父类(超类)的临时对象,允许你调用在父类中定义的方法。
# 这个临时对象会绑定到子类的实例上,因此你可以像调用子类方法一样调用父类的方法,但实际上是调用了父类中的实现。
super().__init__(r, c)
def update(self, graph, gama=0.8, eps=1e-4):
"""
:param graph: 状态地图
:param gama: 折扣率
:param eps: 误差,当小于给定误差时就认为达到了最优的情况
:return:
"""
# 先定义一下上一轮的状态价值矩阵,否则 while 循环的循环条件不满足进不去 while
# ones_like()这个函数接收一个数组作为参数,并返回一个新数组,
# 这个新数组的形状和类型与输入的数组相同,但所有元素都被初始化为1
last_state_value_matrix = np.ones_like(self.state_value_matrix)
# 开始迭代更新,目的是通过求解贝尔曼最优方程迭代搜索到最优状态价值矩阵和一个最优策略
# 只要还没有迭代结果误差还没有小到eps,那么就一直迭代
while np.sum(np.abs(last_state_value_matrix - self.state_value_matrix)) > eps:
# 上一轮的状态价值矩阵
last_state_value_matrix = self.state_value_matrix.copy()
# 对于每一个状态,行列位置共同确定一个状态
for row in range(self.r):
for col in range(self.c):
# 对于每一个动作
for action in range(self.action_nums):
# 计算其动作价值矩阵
next_row, next_col, reward = get_reward((row, col), action, graph)
# 贝尔曼最优公式中求 QΠ的部分
self.action_value_matrix[row][col][action] = (
reward + gama * self.state_value_matrix[next_row][next_col])
"""策略更新"""
self.cur_best_policy[row, col] = np.argmax(self.action_value_matrix[row, col])
"""值更新"""
self.state_value_matrix[row, col] = np.max(self.action_value_matrix[row, col])
if __name__ == "__main__":
# 定义地图,□ 表示可以正常走的,× 表示 forbidden area,● 表示终点
graph = [['□', '□', '□', '□', '□'],
['□', '×', '×', '□', '□'],
['□', '□', '×', '□', '□'],
['□', '×', '●', '×', '□'],
['□', '×', '□', '□', '□']]
r = len(graph)
c = len(graph[0])
# 值迭代算法
Value_Iteration = ValueIterationSolver(r, c)
# Value_Iteration.show_policy()
# print("--------------------")
Value_Iteration.update(graph)
# Value_Iteration.show_policy()
# 动态展示过程
Value_Iteration.show_point_to_point((0, 0), (3, 2), graph)
整个的代码逻辑和伪代码的逻辑是差不多的,再列一下贝尔曼最优公式:

第一部分就是首先会给定一个随机的 V(s`),就是状态价值,对应于上面代码中的一开始随机初始化的 state_value_matrix [row][col]:
self.state_value_matrix = np.random.randn(r, c)
初始化后这个矩阵中的每个数值都对应了一个位置,也就是一个状态的价值数。比如该矩阵坐标 [0][0] 也就是第一行第一列的位置就是网格世界中的 S0 状态,假设其随机初始化的值为 3,那么 S0 的 state value 就为 3。
从公式中不难发现,知道了 V(s`) 自然就能够得到 q(s, a) 的值了,也就是 action value 值。action value 显然也是要根据给定的 V(s`) 变化的,因此我们也要随机初始化一个 action value ,对应于上面代码中一开始随机初始化的 action_value_matrix[row][col][action]:
self.action_value_matrix = np.random.randn(r, c, len(self.idx_to_action))
其中行列位置共同确定一个状态 S,而在一个状态 S 上,其一共有 5 种 action,因此对于每个 action 我们都要分别记录其对应的 action value,所以 action_value_matrix 被设计为三维数组。
同时,对于一个贝尔曼公式来说,其一定是依赖于一个给定的 Π ,但是贝尔曼最优公式是没有给定的,我们必须要去求解这样一个 Π,最优公式与一般公式其实很相似,就是在策略 Π 前面限定了一个 max Π,此时就嵌套了一个优化问题,我们需要先解决这个优化问题,求解出来这个 Π,然后再把这个 Π 代入到这个式子里面去进行求解。
因此所谓的贝尔曼最优公式其实就是要求得一个最优的策略 Π,然后根据最优的策略 Π 自然就可以获得最优的 state value,state value 的值越高,说明采取的策略越好,而 action value 就是用来帮助我们改进策略的。
代码中,先循环遍历每一个状态 S 的全部五个 action:
for row in range(self.r):
for col in range(self.c):
for action in range(self.action_nums):
next_row, next_col, reward = get_reward((row, col), action, graph)
self.action_value_matrix[row][col][action] = (
reward + gama * self.state_value_matrix[next_row][next_col])
对每个 action 做两个行为,第一个行为是求它的 immediate reward 值,第二个行为是求它的 discounted return,对于 gama * self.state_value_matrix[next_row][next_col]) 其实就是求 future reward 了,因为在之前介绍原理的时候说过,从不同状态出发,它是依赖于从其它状态出发所得到的 return 的,还记得吗:

以上图中的 v1 = r1 + γ( r2 + γr3 + … ) = r1 + γv2 为例,这个 v2 是下一个状态的 state value,很明显我们是不知道 v2 的,那怎么计算 v1 呢?之前说过,用线性方程组的方式可以做,但是这效率低下,因此采用 值迭代 的算法。
我们直接随机给出一个 v2`,然后通过一点一点的迭代使得这个 v2` 无限接近真实的 v2 即可,这样就能求得一系列真实的 state value 值也就是 v 值了。
因此对于这第二个行为的代码:
self.action_value_matrix[row][col][action] = (
reward + gama * self.state_value_matrix[next_row][next_col])
其直接使用 immediate reward 加上 下一状态的 reward 也就是 gama*self.state_value_matrix[next_row][next_col] 就可以算出从当前状态出发所获得的总的 discounted return。
当我们遍历完某一个状态 S 中的五个 action 之后,我们就已经知道了该状态下哪一个 action 的 value 最高,因此就可以针对当前状态 S 所使用的最优策略进行更新了,代码如下:
self.cur_best_policy[row, col] = np.argmax(self.action_value_matrix[row, col])
这里简单粗暴的直接返回 action_value_matrix[row , col] 位置对应的 action 数组中值最大的元素下标(别忘了 action_value_matrix 是一个三维数组嗷),为什么可以直接这样计算就能拿到最优策略呢?这问的不是废话吗,动作价值最高肯定选它作为策略会更好啊。
然后进行 state value 价值矩阵的更新,代码如下:
self.state_value_matrix[row, col] = np.max(self.action_value_matrix[row, col])
这里直接返回了 action_value_matrix 中当前状态位置上 action 数组中的最大 action value 值。为什么这样可以直接取得最优的 state value 呢?
这又不得不提到之前说过的例子了,首先贝尔曼最优公式如下:

可以看到 v(s) = max Π Σ Π(a|s)q(s,a) 。对于这样一个式子,更简化的看法其实就是
v(s) = 概率值1* q1 + 概率值2 * q2 + 概率值3*q3 ....
对于这样一个式子求 v 的最大值,之前老师例证过:

因此如果要让 v(s) 求得最大值,直接默认概率为1,然后取最大的 action value,也就是 q 值即可。
最后就是一直循环遍历每一个 state 的每一个 action 即可。
在之前课程中证明过,最后一定会收敛到最优值,因此放心大胆的用即可。
运行结果如下:

关于 print(*[self.idx_to_action[idx] for idx in i], sep=’ ') 的 Python 语法解释:

Policy iteration algorithm
直接给出该算法是怎么做的:

这样一个过程可以被下图表示出来:

在实现该算法之前,先来回答上面 PPT 中的问题:

对于求解 state value 有两种方法,我们这里会介绍常用的迭代的方式。



接下来是实现 policy iteration 的做法:


伪代码如下:

一个简单的例子用来加深印象:



这是一个比较简单的例子,因此迭代次数较少。
Policy iteration algorithm implementation
基本环境和上面的值迭代处写的差不多,只要将这个算法类放入值迭代的文件中即可:
class PolicyIterationSolver(Solver):
def __init__(self, r: int, c: int):
super().__init__(r, c)
def update(self, graph, gama=0.8, eps=1e-4):
last_best_policy = np.ones(shape=(r, c))
i = 0
while not np.array_equal(last_best_policy, self.cur_best_policy) or i < 20:
# 上一轮的状态价值矩阵
last_state_value_matrix = np.ones_like(self.state_value_matrix)
"""策略评估,获取状态价值矩阵"""
# 策略评估就是在求解在当前最优策略下的状态价值矩阵
while np.sum(np.abs(last_state_value_matrix - self.state_value_matrix)) > eps:
last_state_value_matrix = self.state_value_matrix.copy()
for row in range(self.r):
for col in range(self.c):
action = self.cur_best_policy[row][col]
next_row, next_col, reward = get_reward((row, col), action, graph)
self.state_value_matrix[row][col] = reward + gama * self.state_value_matrix[next_row][next_col]
"""策略改进,获取改进策略"""
# 策略改进就是用上面求出来的当前最优状态价值矩阵去求得下一次要迭代的最优策略
last_best_policy = self.cur_best_policy.copy()
for row in range(self.r):
for col in range(self.c):
for action in range(self.action_nums):
next_row, next_col, reward = get_reward((row, col), action, graph)
self.action_value_matrix[row][col][action] = reward + gama * self.state_value_matrix[next_row][
next_col]
self.cur_best_policy[row][col] = np.argmax(self.action_value_matrix[row, col])
# 确保是最优策略
if np.array_equal(last_best_policy, self.cur_best_policy):
i += 1
else:
i = 0
测试代码如下:
if __name__ == "__main__":
# 定义地图,□ 表示可以正常走的,× 表示 forbidden area,● 表示终点
graph = [['□', '□', '□', '□', '□'],
['□', '×', '×', '□', '□'],
['□', '□', '×', '□', '□'],
['□', '×', '●', '×', '□'],
['□', '×', '□', '□', '□']]
r = len(graph)
c = len(graph[0])
"""策略迭代算法, 其收敛速度比值迭代算法快"""
policy_iterator = PolicyIterationSolver(r, c)
policy_iterator.update(graph)
# policy_iterator.show_policy()
policy_iterator.show_point_to_point((2, 1), (3, 2), graph)
运行结果是动态展示的,这里就不再赘述,自己跑一下就知道了。
Truncated policy iteration algorithm
首先比较一下上文说的 value iteration 和 policy iteration:

从上图可以看出,二者其实是非常类似的:

但还是会有区别的:


上图是一个典型的求解贝尔曼公式id一个迭代算法,但是马上就有新的东西要出现了:

为什么叫 truncated 呢?从上图容易知道,就是因为从 j 出发到后边无穷的这些步全都没有了,全部都截断了,因此 truncated policy iteration 显然是 value iteration 和 policy iteration 更一般化的形式。
还有一个需要强调的点是,policy iteration 这个算法其只在理论上存在,在实际当中是不可能存在的,因为它需要计算无穷多步,在实际当中是不可能计算无穷多步的。
我们经常做的实际上就是判断比如说 VΠ1(j) 和 VΠ1(j-1) 这两个直接的误差是不是已经足够小了,如果足够小那么就可以停止迭代了,而这显然是有限步的操作。
因此实际上我们平常所做的 policy iteration 其实就是 truncated policy iteration。
其伪代码思路如下:

然而上图有一个明显的问题就是其没有计算无穷多步,因此计算出来的 Vk 实际上并不是 VΠk,那么这种截断会不会带来一些问题呢?
不会的:

上面的结果可以通过下面的图示更好的展示:
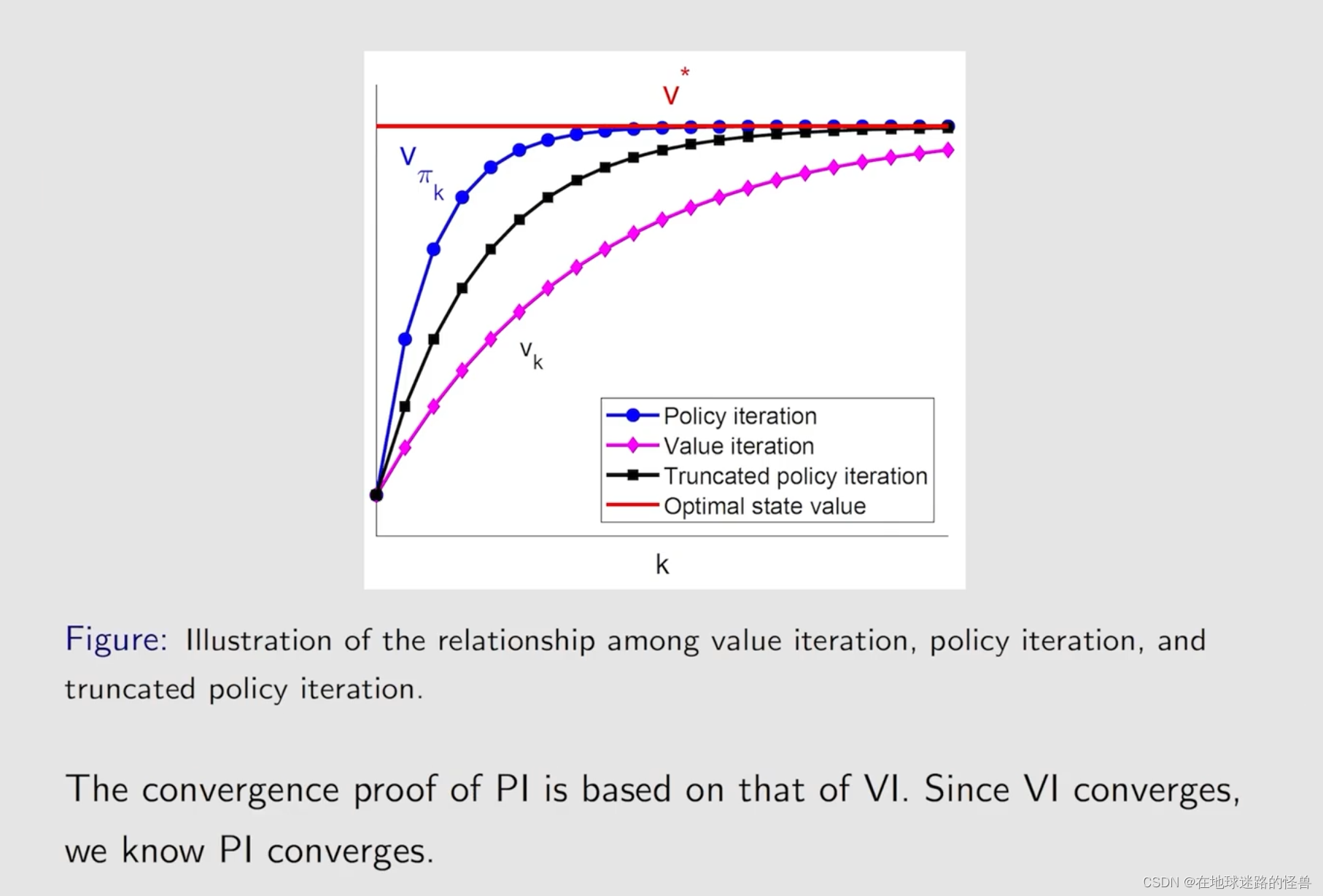
Summary

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











