






学习目标:
- 深度学习吴恩达lesson1-week4
- 深度学习吴恩达lesson2-week1
学习内容:
目录
4.1 深层神经网络(Deep L-layer neural network)
4.2 深层网络中的前向传播(Forward propagation in a Deep Network)
4.3 核对矩阵的维数(Getting your matrix dimensions right)
4.4 搭建神经网络块(Building blocks of deep neural networks)
4.5 参数VS超参数(Parameters vs Hyperparameters)
1.1 训练,验证,测试集(Train / Dev / Test sets)
4.1 深层神经网络(Deep L-layer neural network)
4.2 深层网络中的前向传播(Forward propagation in a Deep Network)
4.3 核对矩阵的维数(Getting your matrix dimensions right)
4.4 搭建神经网络块(Building blocks of deep neural networks)
4.5 参数VS超参数(Parameters vs Hyperparameters)
1.1 训练,验证,测试集(Train / Dev / Test sets)
1.2 偏差,方差(Bias /Variance)
1.3 机器学习基础(Basic Recipe for Machine Learning)
1.4 正则化(Regularization)
1.5 为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)
1.6 dropout 正则化(Dropout Regularization)
1.8 其他正则化方法(Other regularization methods)--随机失活
学习时间:
10.10-10.16
学习产出:
复习:我们学过了逻辑回归、浅层神经网络、一个单独隐藏层的神经网络的正向传播和反向传播、向量化、随机初始化权重等知识,就可以进行深层神经网络的搭建。
lesson1-week4
4.1 深层神经网络(Deep L-layer neural network)
浅层神经网络与深层神经网络的区别。
取决于层数的多少,浅层神经网络层数少计算量少。
为什么需要深层神经网络?
举例1:对于人脸识别等应用,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
举例2:这是一个类比的例子,例如在电路中的逻辑门操作,如果将所有的逻辑门放在同一层,那么所有可以表示的情况就只能是各个逻辑门情况的和,但是如果放在不同层上进行叠加就会是他们的乘积,这样能表示的情况更复杂。深层神经网络也有类似的性质。
随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
总的来说:浅层神经网络解决初步问题的基础上远远不够,所以我们需要更加深层的神经网络实现问题的具体化。
4.2 深层网络中的前向传播(Forward propagation in a Deep Network)
可以查看这位博主所说明的前向传播与反向传播的图片实例,浅显易懂:
4.3 核对矩阵的维数(Getting your matrix dimensions right)
这里吴教授给大家讲解了他在进行深层网络的实现时保证各个矩阵维数正确的小技巧。
正确的矩阵维数是保证程序不出现bug的基本条件。
向量化之前各个矩阵大小:

向量化之后:

在你做深度神经网络的反向传播时,一定要确认所有的矩阵维数是前后一致的,可以大大提高代码通过率。
4.4 搭建神经网络块(Building blocks of deep neural networks)
神经网络的搭建可以总结成一下的流程(四层为例):
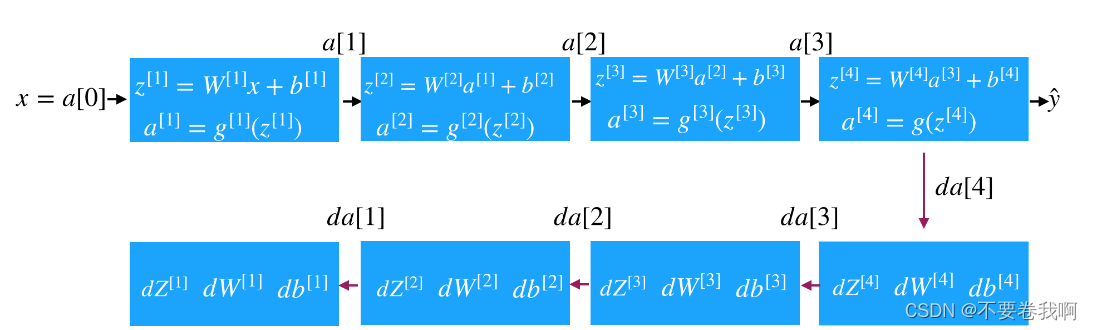
4.5 参数VS超参数(Parameters vs Hyperparameters)
什么是超参数?
比如算法中的learning rate a(学习率)、iterations(梯度下降法循环的数量)、L(隐藏层数目)、n[l](隐藏层单元数目)、choice of activation function(激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数W和b的值,所以它们被称作超参数。
实际上深度学习有很多不同的超参数,之后我们也会介绍一些其他的超参数,如momentum、mini batch size、regularization parameters等等。
可以理解成C语言中的全局变量,或者是可以在程序中进行认为调整并且影响整个程序的参数。这些参数不是程序运行中确定的,而是在程序设计时就需要完全确定。
什么是参数:
比如算法中的W(x输入的系数)、b(偏移量)
如何寻找超参数的最优值?
经验(想法)->修改程序->观察效果(成本函数是否降低)->重新思考
通过上面的循环进行不断改进,可以说,超参数的设计是在寻找一个最佳的可以使得代价函数更接近最低点的数值。
lesson2-week1
1.1 训练,验证,测试集(Train / Dev / Test sets)
超参数取值的确定问题
实际上,应用型机器学习是一个高度迭代的过程,通常在项目启动时,我们会先有一个初步想法,比如构建一个含有特定层数,隐藏单元数量或数据集个数等等的神经网络,然后编码,并尝试运行这些代码,通过运行和测试得到该神经网络或这些配置信息的运行结果,你可能会根据输出结果重新完善自己的想法,改变策略,或者为了找到更好的神经网络不断迭代更新自己的方案。
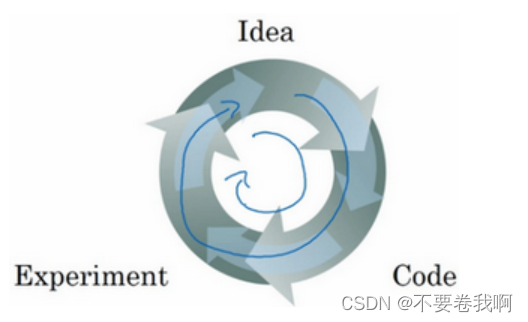
总结为以上图例,通过想法设计编码的超参数,实验获得结果,根据经验进行超参数的再次调整以获得更好的局部解。
我们通常会将这些数据划分成几部分:
- 训练集
- 简单交叉验证集,也称验证集(dev set)
- 测试集
数据集的比例划分:
在机器学习中,我们通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例(6:2:2),数据集规模较大的,验证集和测试集要小于数据总量的20%或10%(99:1)。后面我会给出如何划分验证集和测试集的具体指导。
小数据集:划分比例6:2:2
大数据集:划分比例99:1(一般会变化,但是经验就是验证集与测试机往往可以取少量即可,例如1000个样例)
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。当然,如果你不需要无偏估计,那就再好不过了。
总结来说:测试集可以没有,只有训练和验证集合也可以,测试集的用处在于做无偏估计,验证集是为了选择合适的模型,或者说选择合适的超参数。
Not have a test set might be Okay.(Only dev set).
1.2 偏差,方差(Bias /Variance)
偏差:预测值和真实值之间的误差。
方差:可以理解为训练数据集精度和测试数据集精度之间的差异。
我的理解:偏差即我们所做的预测函数与放入的训练集合的拟合程度。方差即我们训练好的预测函数在实际应用中的应用效果。
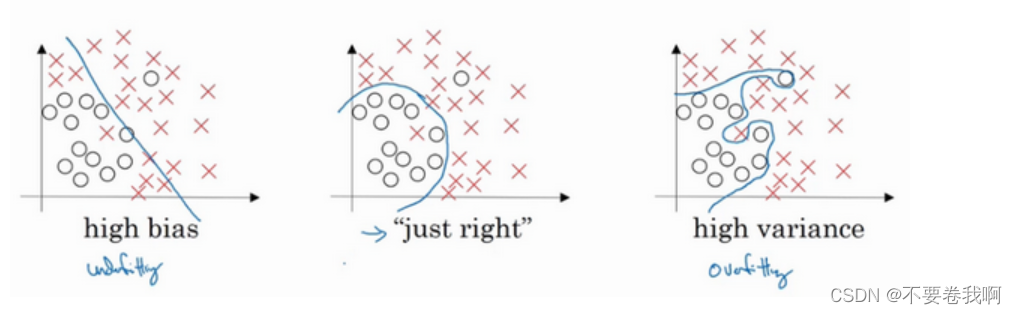
拟合概念:
欠拟合:训练出来的模型不能很好地匹配训练集合,表现得很差,甚至样本本身都无法高效的识别。
过拟合:其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。过拟合就是学到了很多没必要的特征,比如你说的长得像猫的狗,和长得像狗的猫,其实这只是特例,但神经网络为了更好的降低Loss,就只能被迫学习这些特征用来区分猫和狗,导致模型并不能很好的区分这两种动物,原因就是对于某些不重要特征的在意程度太高。
拟合与偏差、方差的关系:















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









