






循环神经网络RNN
这一章主要介绍了循环神经网络(Recurrent neural network, 简称RNN),主要用来处理序列数据,比如一些文字序列或时序数据。对于这类数据,基本的前馈神经网络会对每一个输入的特征都训练一个单独的参数,而不能很好的进行参数的共享,而RNN就可以通过对不同时间点的特征共享参数而更容易的进行训练,泛化效果也更好。卷积神经网络(CNN)也可以实现参数共享,RNN与其不同的地方在于其每一点的输出还依赖于之前的结果。
展开计算图
对于动态系统,我们常常可以用状态机(state machine)来模拟
s
(
t
)
=
f
(
s
(
t
−
1
)
;
θ
)
s^{(t)} = f(s^{(t-1)};\theta)
s(t)=f(s(t−1);θ) ,RNN中的recurrent也得名于
t
t
t 时刻的状态依赖于
t
−
1
t-1
t−1 时刻的状态。当然,我们可以把该式不断的展开直至可以用对于初始状态
s
(
1
)
s^{(1)}
s(1) 的不断的函数叠加来表示,可以将计算图展开如下:

如果该系统由外部信号驱动,则可以表示为
s
(
t
)
=
f
(
s
(
t
−
1
)
,
x
(
t
)
;
θ
)
s^{(t)} = f(s^{(t-1)},x^{(t)};\theta)
s(t)=f(s(t−1),x(t);θ) 。RNN就采取类似的循环公式,只不过用hidden units来代表状态,即
h
(
t
)
=
f
(
h
(
t
−
1
)
,
x
(
t
)
;
θ
)
h^{(t)} = f(h^{(t-1)},x^{(t)};\theta)
h(t)=f(h(t−1),x(t);θ) 。同样的,可以将其计算图展开如下,展开图可以有助于理解信息传播方向和梯度的反向传播方向:
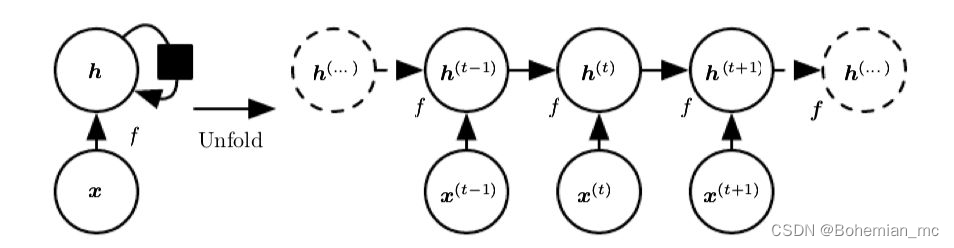
我们可以将
h
(
t
)
h^{(t)}
h(t) 看做是之前的输入向量序列
(
x
(
t
)
,
x
(
t
−
1
)
,
.
.
.
,
x
(
1
)
)
(x^{(t)},x^{(t-1)},...,x^{(1)})
(x(t),x(t−1),...,x(1)) 的一种有损的表示。根据不同的需要,我们可以控制损失的精度,例如对于一些语言模型,可能只有附近的文字信息比较重要,我们就不需要存储所有t之前的序列信息。
循环神经网络
了解了图展开和参数共享的思想,可以设计各种循环神经网络。一种基本的结构如下图所示:
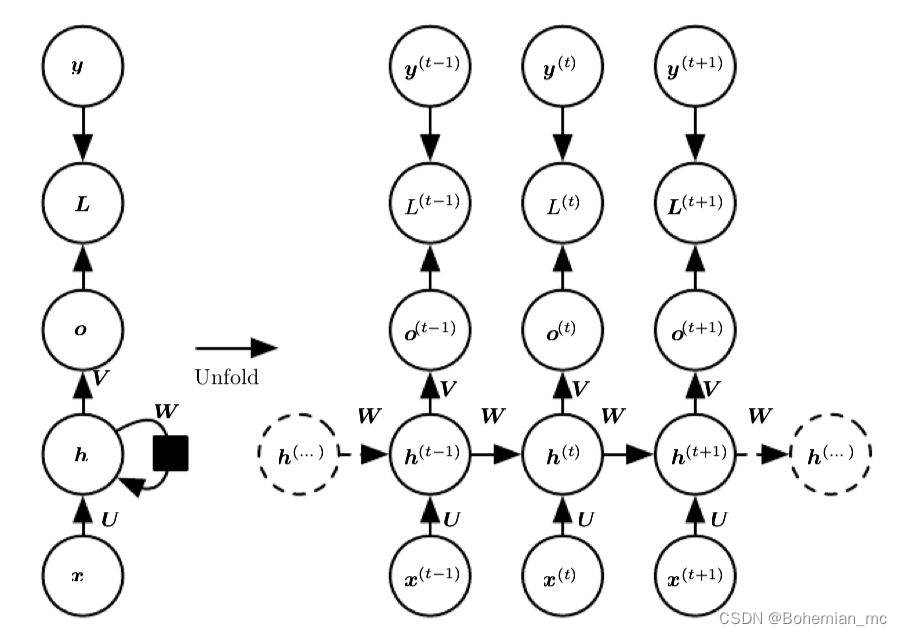
即在每一个时间点都产生输出,并且hidden units之间有循环链接,图中
y
y
y 为该点的真实目标值,
L
L
L 为模型预测的输出值
o
o
o 与真实值
y
y
y 间的损失函数如交叉熵,总的损失为各
L
(
t
)
L^{(t)}
L(t) 之和。由于该结构hidden units间有循环链接,计算时我们需要顺序计算,而不能进行并行计算,所以训练过程较为缓慢。而且该模型需要输入与输出序列长度相同。
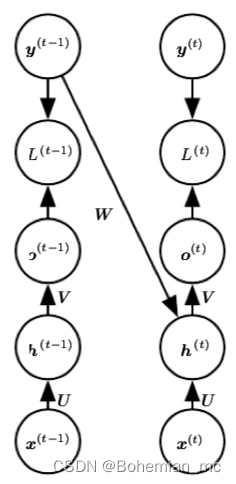
假如我们损失一点模型普适性,去掉hidden units之间的循环链接,而是建立前一时间点真实目标值与当前hidden unit的链接,则当前点hidden unit并不依赖于前一点hidden unit计算结束,则我们可以有效地将训练过程并行化,当然
y
(
t
−
1
)
y^{(t-1)}
y(t−1) 并不能完全代表
h
(
t
−
1
)
h^{(t-1)}
h(t−1) 所包含的所有信息,所以在提高训练效率的同时降低了一些模型的普适性,这一方法叫做teacher forcing,其计算图可作如下展开:
还有一种常见的结构是将一个向量而不是向量序列作为输入,输出一个序列,这经常用在image caption中,即给定一个图像,我们常常用CNN得到其特征向量,再将这个特征向量作为输入,得到描述该图片的输出文字序列。这种结构如下图所示:
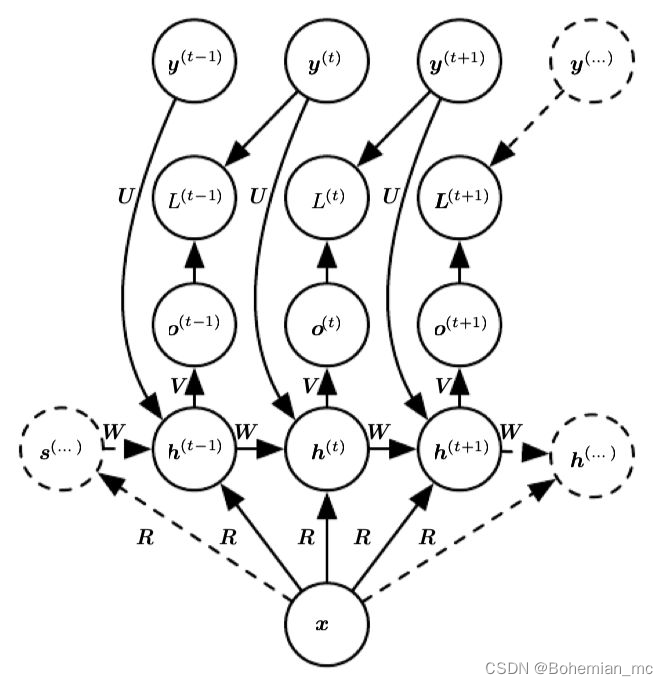
由于之前基本的RNN结构要求输入与输出同等长度,而实际应用如语音识别、机器翻译等往往输入输出的长度不同,为了解决这一问题我们可以把上述两种结构结合起来,即先用一个RNN将输入序列转化为一个向量,通常是其最终的隐藏态的一个函数,这一过程称作encoder或reader,然后再将这一定长的向量作为输入,利用上图所示结构产生序列输出,这一过程称作decoder或reader,结合起来就是经典的encoder-decoder或称作sequence-to-sequence结构。注意经过这两步,输出和输入序列不再需要满足长度相同的条件,如下图所示
n
y
n_y
ny 与
n
x
n_x
nx 可取不同长度:
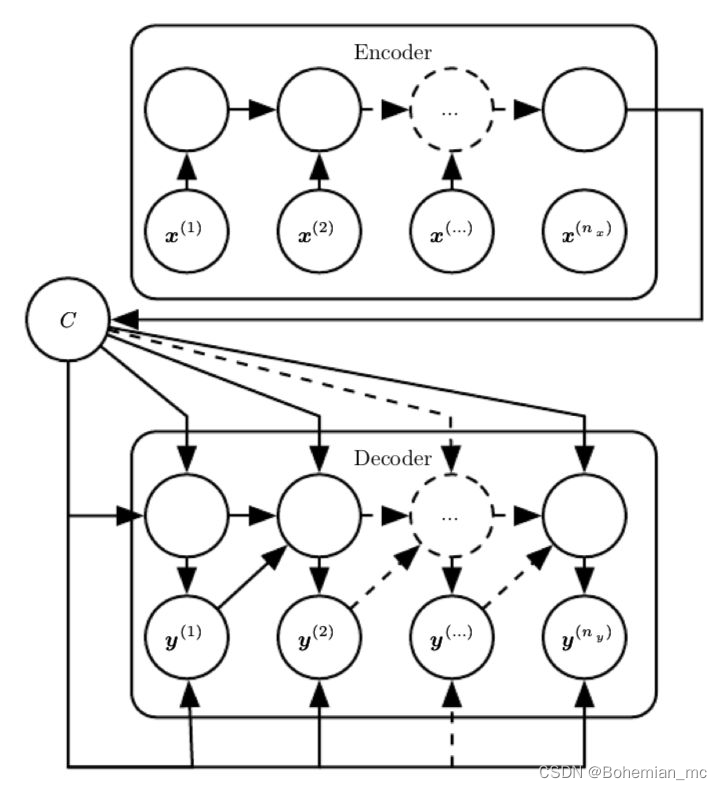
LSTM与GRU
一个需要注意的问题是,在RNN中,由于相同的权重矩阵被不断的在hidden state上叠加,梯度会随着循环次数的增加呈指数的衰减或爆炸,造成模型无法有效的学习long-term的相互作用。即我们每次循环可用 h ( t ) = W h ( t − 1 ) h^{(t)}=Wh^{(t-1)} h(t)=Wh(t−1) 表示,假设对权重矩阵 W W W 可做本征分解 W = Q ⋀ Q T W=Q\bigwedge Q^T W=Q⋀QT ,则 h ( t ) = Q ⋀ t Q h ( 0 ) h^{(t)}=Q\bigwedge ^tQh{(0)} h(t)=Q⋀tQh(0) 为本征值的t次方的形式,对于本征值小于1的方向会衰减至零而本征值大于1的方向爆炸。为了解决这种长程作用的问题,一系列gated RNN模型被提出,其中比较常用的是LSTM和GRU。
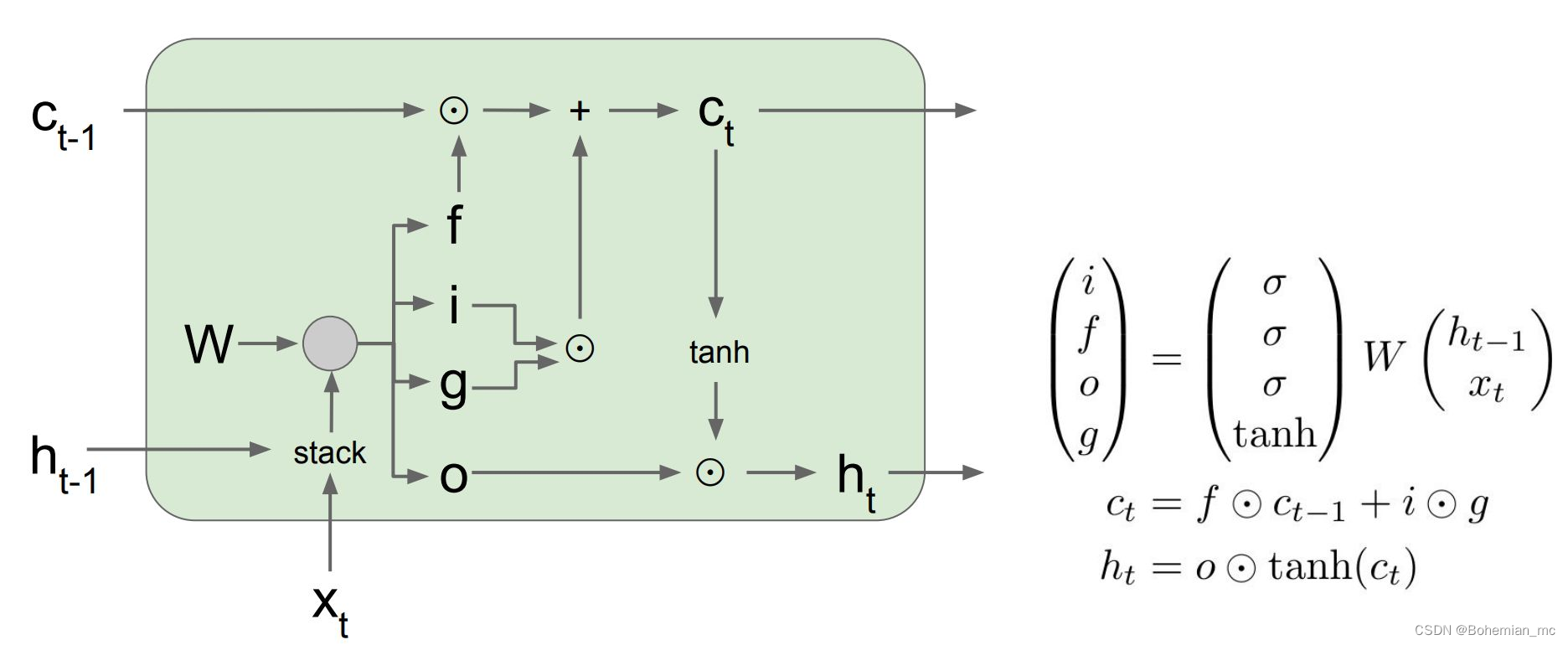
LSTM(Long short-term memory)基本单元结构如下图所示,在hidden state h t h_t ht 的基础上又添加了一个新的cell state c t c_t ct ,旨在长程有效的传递信息。同时引入了四个作用不同的gate:
- f 代表forget gate,经过sigmoid函数,其大小在(0,1]之间,代表了我们会保留之前的cell state的多少信息。
- i 代表input gate,同样的经过sigmoid函数大小在(0,1]之间,代表对于这个cell,有哪些值需要更新。
- g 经过tanh函数,其大小在(-1,1)之间,代表了这些需要更新的值得具体的大小,与input gate做元素积则可求出cell state需要update的值。
- o 代表output gate,即需要将哪些的值输出到hidden state
h
t
h_t
ht 。通过这一结构,在一个单元中,我们可以合理的保存某些前一个单元携带的长程信息,以及本单元的一些更新信息,而不是简单的权重矩阵的乘积,从而解决了长程作用的问题。
GRU(gated recurrent unit)可以看做是将LSTM中的forget gate和input gate合并成了一个update gate,即下式中的 ,同时将cell state也合并到hidden state中。由于该模型相较LSTM更为简化,计算量更小,且最终模型性能类似,所以最近越来越广泛的得到应用。
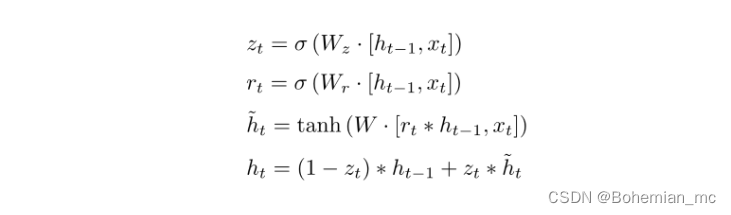
总结
本章主要介绍了为处理序列数据而采用的RNN模型,它的不同架构可以处理各种不同的输入输出格式,如sequence to vector, vector to sequence 及sequence to sequence。而为了解决长程作用的问题,各种gated RNN方法被提出,比较普及的是LSTM以及GRU模型。
线性因子模型
之前总结的方法大部分是在有大量数据情况下的监督学习方法,而假如我们想减小数据量的要求,则需要一些无监督学习及半监督学习方法,虽然有很多无监督学习方法,但是目前还无法达到深度学习在监督学习问题中所达到的精度,这常常是由于我们需要解决的问题的维度过高或计算量过大造成的。
无监督学习常常需要建立一种依赖于观察数据的概率模型 p m o d e l ( x ) p_{model}(x) pmodel(x) ,但由于实际观察的数据x常常比较杂乱没有规律,通常我们会用某种代表了更低维基本特征的隐性变量 h h h(latent variables) 来更好的表征数据,将问题转化为 p m o d e l ( x ) p_{model}(x) pmodel(x)= E h p m o d e l ( x ∣ h ) E_hp_{model}(x|h) Ehpmodel(x∣h) ,这一章主要介绍了最基本的利用隐性变量的概率模型——线性因子模型(Linear Factor model),即假定 h h h取自某种先验分布(prior distribution) h ~ p ( h ) h~p(h) h~p(h) ,而我们观察到的数据是 h h h 的线性变换与一些随机噪声的叠加,用式子表示为 x = W h + b + n o i s e x=Wh+b+noise x=Wh+b+noise ,之后讨论的不同方法会选择不同的 p ( h ) p(h) p(h) 和 n o i s e noise noise 分布。
因子分析(Factor Analysis) 模型中, h h h 满足单位高斯分布 h ~ N ( h ; 0 , I ) h~N(h;0,I) h~N(h;0,I) ,而观察数据 x x x 相对于 h h h 则相互条件独立,noise来自于对角协方差高斯分布,其协方差矩阵 ψ = d i a g ( σ 2 ) \psi=diag(\sigma^2) ψ=diag(σ2) ,其中 σ 2 = [ σ 1 2 , σ 2 2 , . . . , σ n 2 ] T \sigma^2=[\sigma^2_1,\sigma^2_2,...,\sigma^2_n]^T σ2=[σ12,σ22,...,σn2]T 是每个变量的协方差。
概率主成分分析(Probabilistic PCA)模型 与因子分析模型类似,但是我们令所有的协方差 σ i 2 \sigma^2_i σi2 都相等,即 x = W h + b + σ z x=Wh+b+\sigma z x=Wh+b+σz 其中 z ~ N ( z ; 0 , I ) z ~N(z;0,I) z~N(z;0,I) 是单位高斯噪声。
独立成分分析(Independent Component Analysis) 简称ICA,希望隐性变量尽量互相独立,通常应用于将多元叠加的信号分割成各自独立的信号,例如将收集到的不同人的语音信息的叠加分割成原本每个人的语音。由于目的是隐性变量相互独立,所以其先验分布为非高斯分布。另外,ICA并不一定需要生成模型即知道怎样模拟 h h h 的生成概率分布 p ( h ) p(h) p(h),许多ICA的变种只是将目标定为尽量提高 h = W − 1 x h=W^{-1}x h=W−1x 的峰度以尽可能偏离高斯分布,而无需明确的表示 h h h 的生成概率分布 p ( h ) p(h) p(h)。
慢特征分析(Slow Feature Analysis) 简称SFA,希望学习随时间变化较为缓慢的特征,其核心思想是认为一些重要的特征通常相对于时间来讲相对变化较慢,例如视频图像识别中,假如我们要探测图片中是否包含斑马,两帧之间单个像素可能从黑突变为白,所以我们需要一些随时间变化更慢的特征来决定我们的预测结果。假设我们的特征提取函数为 f f f ,则慢特征原则希望减小如下的损失函数 λ ∑ t L ( f ( x ( t + 1 ) ) , f ( x ( t ) ) ) \lambda\sum_tL(f(x^{(t+1)}),f(x^{(t)})) λ∑tL(f(x(t+1)),f(x(t))) 。SFA即假定特征提取函数 f ( x ; θ ) f(x;\theta) f(x;θ) 为线性变换,进而解决如下的优化问题:
m i n θ E t ( f ( x ( t + 1 ) ) i − f ( x ( t ) ) i ) 2 min_{\theta}E_t(f(x^{(t+1)})_i-f(x^{(t)})_i)^2 minθEt(f(x(t+1))i−f(x(t))i)2
并要求限制条件 E t ( f ( x ( t ) ) i ) = 0 E_t(f(x^{(t)})_i)=0 Et(f(x(t))i)=0 及 E t [ f ( x ( t ) ) i 2 ] = 1 E_t[f(x^{(t)})_i^2]=1 Et[f(x(t))i2]=1 以保证解的唯一性。
另外我们还要求各个不同特征之间是去相关的 ∀ i < j \forall i<j ∀i<j , E t [ f ( x ( t ) ) i f ( x ( t ) ) j ] = 0 E_t[f(x^{(t)})_if(x^{(t)})_j]=0 Et[f(x(t))if(x(t))j]=0 , 否则所有的特征都会变成最慢的那个信号的不同表征。
稀疏编码(Sparse Coding) 希望隐性特征更稀疏,即集中在少数几个特征上,所以它的先验函数通常选为在零点附近有比较陡峭的峰值的函数,例如拉普拉斯函数:
p
(
h
i
)
=
L
a
p
l
a
c
e
(
h
i
;
0
,
2
λ
)
=
λ
4
e
−
1
2
λ
∣
h
i
∣
p(h_i)=Laplace(h_i;0,{2 \over \lambda} )={\lambda\over4}e^{-{1\over2}\lambda|h_i|}
p(hi)=Laplace(hi;0,λ2)=4λe−21λ∣hi∣
而noise是高斯噪声 p ( x ∣ h ) = N ( x ; W h + b , 1 β I ) p(x|h)=N(x;Wh+b,{1\over\beta}I) p(x∣h)=N(x;Wh+b,β1I) 。
优化问题是 a r g m i n h λ ∣ ∣ h ∣ ∣ 1 + β ∣ ∣ x − W h ∣ ∣ 2 2 argmin_h\lambda||h||_1+\beta||x-Wh||_2^2 argminhλ∣∣h∣∣1+β∣∣x−Wh∣∣22 。
总结
子分析,概率PCA,ICA,SFA即稀疏编码等线性因子模型是比较简单的学习数据的高效表征的方法,而且它们也可以扩展为之后更复杂的自编码网络以及深度概率模型,所以有必要对其有基本的理解。
自编码器
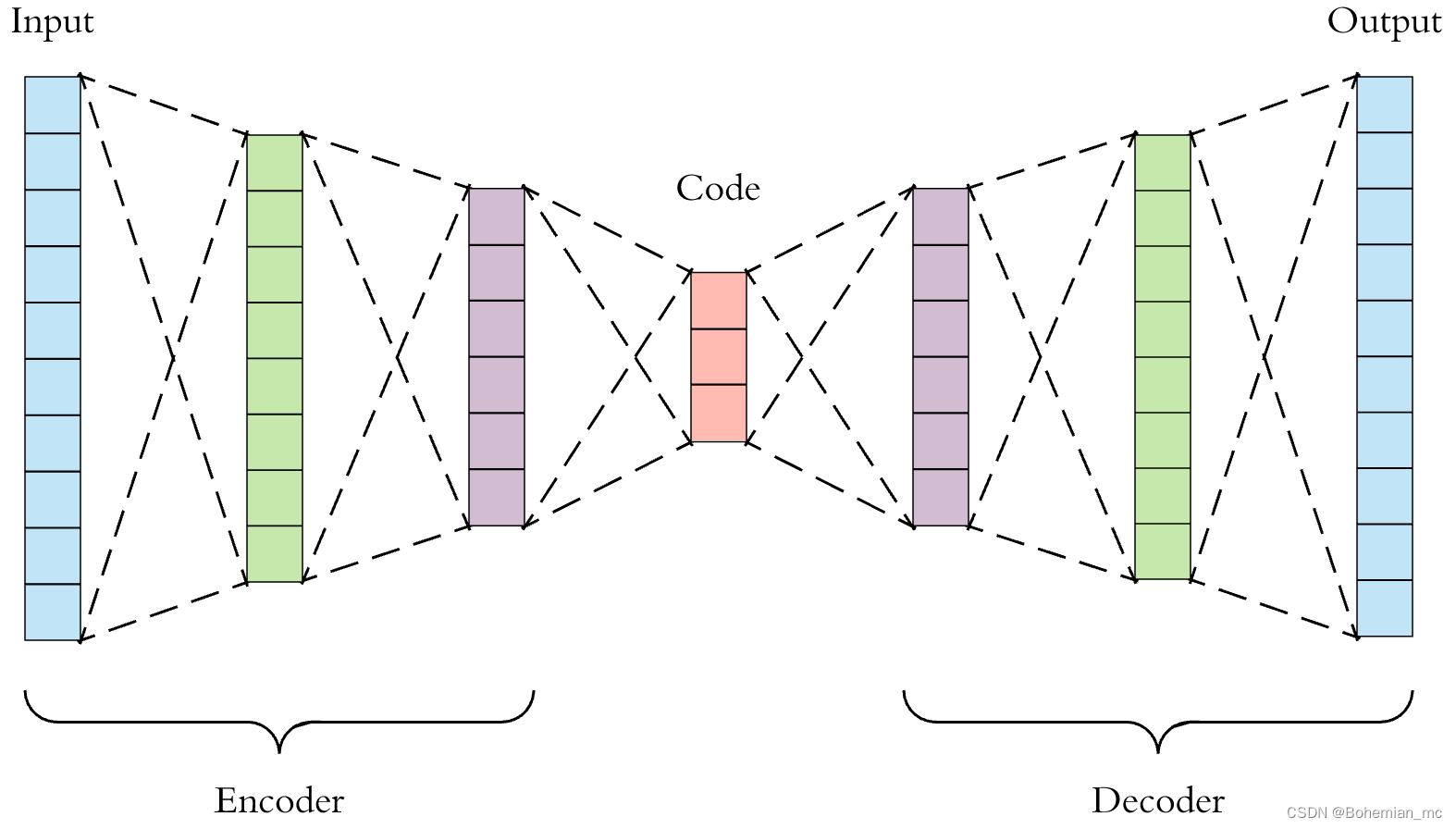
自编码器(Autoencoder) 是一种特定的神经网络结构,其目的是为了将输入信息映射到某个更低维度的空间,生成包含重要特征的编码code,这部分称为Encoder,可用函数
h
=
f
(
x
)
h=f(x)
h=f(x) 表示,然后再利用Decoder将code重构成为尽量能还原原输入的结果,用函数
r
=
g
(
h
)
r=g(h)
r=g(h) 。我们的目的就是尽量使
g
(
f
(
x
)
)
=
x
g(f(x))=x
g(f(x))=x ,当然如果只是简单的将输入复制到输出是没有任何意义的,我们需要加一定的限制条件,使我们的模型学习到数据中更重要的特征。有的时候,我们也需要将这种确定性的函数拓展到具有随机性的概率分布
p
e
n
c
o
d
e
r
(
h
∣
x
)
p_{encoder}(h|x)
pencoder(h∣x) 和
p
e
n
c
o
d
e
r
(
x
∣
h
)
p_{encoder}(x|h)
pencoder(x∣h) 。
为了学习到重要的特征,我们可以限制编码 h h h 的维度小于输入,这种编码器成为欠完备编码器(Undercomplete Autoencoder)。其损失函数可以表示为 L ( x , g ( f ( x ) ) ) L(x,g(f(x))) L(x,g(f(x))) ,函数 L L L 度量 g ( f ( x ) ) g(f(x)) g(f(x)) 偏离输入 x x x 的程度。当decoder函数 g g g 是线性函数, L L L 是均方差的时候,欠完备编码器学习到的空间与PCA(主成分分析)相同。对于带有非线性函数编码解码函数的欠完备编码器,即使编码 h h h 的维度小于输入,我们也可以任意的改变非线性函数,将输入复制到输出而无需学习到有效的信息,所以怎样限制模型的容量才是关键。
正则自编码器(Regularized Autoencoder)通过向损失函数中加入对模型复杂度的惩罚项可以有效的解决模型容量过大的问题。模型的训练过程就需要在如下两种冲突中寻找平衡:1. 学习输入数据的有效表示 ,使得decoder可以有效的通过重构。2.满足惩罚项带来的限制条件,这可以通过限制模型的容量大小,也可以通过改变模型的重构损失,通常会使模型对于输入的扰动更不敏感。根据损失函数的不同形式主要有如下几种:
- 稀疏自编码器(Sparse Autoencoder) 向损失函数中加入关于编码的稀疏惩罚项 Ω ( h ) \Omega (h) Ω(h) ,例如 Ω ( h ) = λ ∑ i ∣ h i ∣ \Omega (h)=\lambda\sum_i|h_i| Ω(h)=λ∑i∣hi∣ 。这样学习到的稀疏的表示提取了原数据中更重要的一些特征。
- 去噪自编码器(Denoising Autoencoder) 简称DAE,其输入是被损坏的数据,结果是希望能够重构未损坏的原数据。其训练过程是
- 1.从训练数据中取样样本 x x x 。
- 2.取样对应的损坏的结果 x ~ \widetilde{x} x ,这可以用条件概率 C ( x ~ ∣ x = x ) C(\widetilde{x}|x=x) C(x ∣x=x) 来表示。
- 3.将 ( x , x ~ ) (x,\widetilde{x}) (x,x ) 作为训练数据来预测重构分布 p r e c o n s t r u c t ( x , x ~ ) = p d e c o d e r ( x ∣ h ) p_{reconstruct}(x,\widetilde{x})=p_{decoder}(x|h) preconstruct(x,x )=pdecoder(x∣h) ,其中 h h h 是编码器 f ( x ~ ) f(\widetilde{x}) f(x ) 的输出。
我们可以将DAE训练过程看做是对于如下的期望的随机梯度下降过程
E
x
~
p
^
d
a
t
a
(
x
)
E
x
~
~
C
(
x
~
∣
x
)
l
o
g
p
d
e
c
o
d
e
r
(
x
∣
h
=
f
(
x
~
)
)
E_{x~\hat{p}_{data}(x)}E_{\widetilde{x}~C(\widetilde{x}|x)}logp_{decoder}(x|h=f(\widetilde{x}))
Ex~p^data(x)Ex
~C(x
∣x)logpdecoder(x∣h=f(x
)) 。如下图所示我们利用
g
⋅
f
g\cdot f
g⋅f 操作将受损数据
x
~
\widetilde{x}
x
尽量映射回原数据
x
x
x 所在的线上,也可以理解为DAE就是令重构函数更能抵抗输入中的微扰。
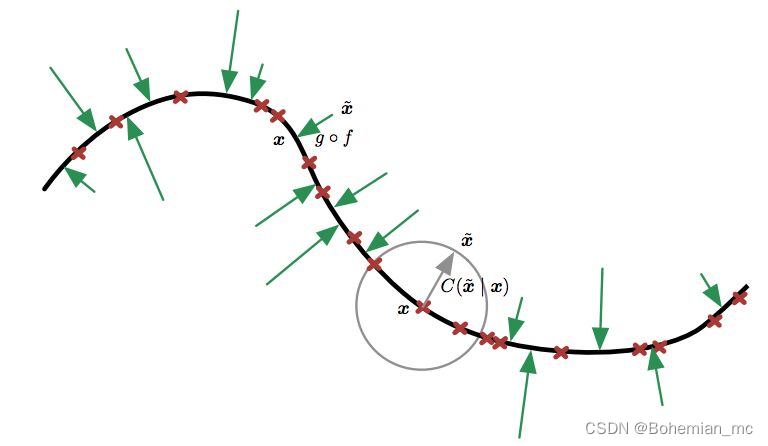
- 收缩自编码器(Contractive Autoencoder) 的惩罚项表示为 Ω ( h ) = λ ∣ ∣ ∂ f ( x ) ∂ x ∣ ∣ F 2 \Omega(h)=\lambda||{{\partial f(x)}\over{\partial x}}||^2_F Ω(h)=λ∣∣∂x∂f(x)∣∣F2 ,是雅可比矩阵的Frobenius范数,可理解为使得encoder更能抵抗输入中的微扰
应用
自编码器的主要应用有降维(dimensionality reduction)和信息检索(information retrieval)。通过encoder我们可以将较复杂的输入编码到维度较低的空间中。信息检索主要是指从数据库中找到与用户的查询条目相近的条目,如果我们利用Autoencoder有效的将每个条目降维并用二进制编码每个维度上的值,则我们可以将数据库中的所有条目产生对应的在低维空间上的哈希码,我们可以有效的提取与用户的查询相同的哈希码,也可以通过改变某几个位上的比特值来寻找与用户查询相类似的条目,这种方法称为semantic hashing。
另外,某些生成模型也可以看做是一种特殊的自编码器,例如变分自编码器(variational autoencoder)。
表示学习
机器学习的主要问题就是如何更合理高效的将特征表示出来。怎么判定某种表示更好通常依赖于后续的学习任务是否能够得益于这种表示。通常,我们是进行某些无监督学习提取出特征,而这些特征可用来我们更好的进行监督学习,或者将这些特征迁移到其他相关任务中。我们也可以将监督学习训练的前馈神经网络看做是一种表示学习,通常神经网络的最后一层是个分类器如softmax,它之前的隐藏层可以看做是给这个分类器提供一个高效的表征。
在深度学习的再次兴起中,贪心逐层无监督预训练(Greedy Layer-Wise Unsupervised Pretraining) 作为无监督学习的代表起了重要的作用,这其中包括了RBM(restricted boltzmann machine),单层自编码器,稀疏自编码器等等,它可以通过无监督学习得到输入数据的分布,常常用来提供神经网络的合理的初始值设置。一个常用例子是word embedding,如果我们仅仅用one-hot encoding即用某个元素上为1其他元素为零的向量来表示所有单词的时候,所有的单侧的距离都是相同的
2
\sqrt{2}
2,而我们用word embedding将其映射到新的空间,令词义更相近的单词靠得更近,如下图所示。如果我们有某些字符串类型的数据,则利用word embedding可以更有效的表示数据之间的关系。
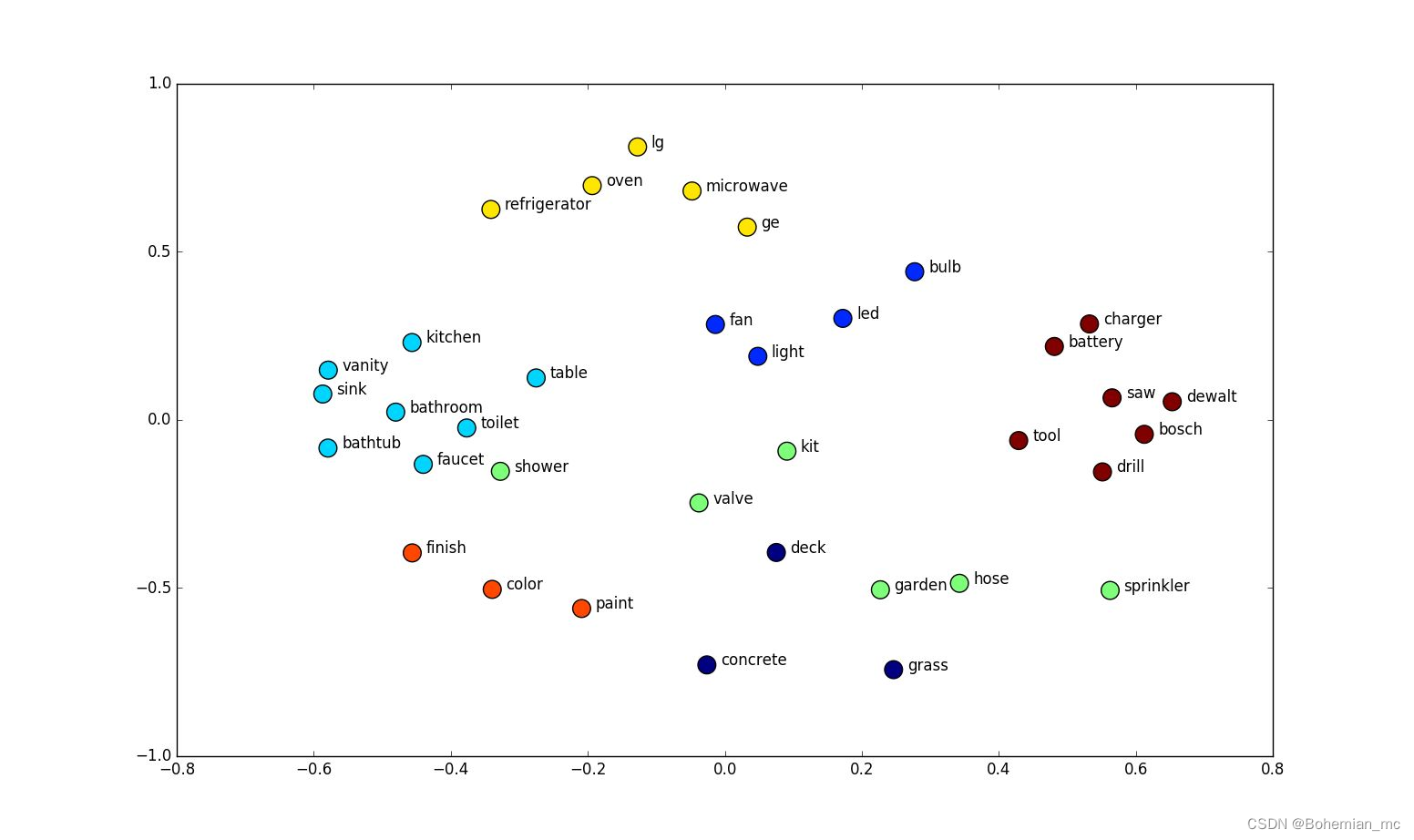
随着深度学习的发展,无监督预训练重要性逐渐下降,除了自然语言处理外,在其他应用场景如图像识别渐渐被监督预训练所取代,即利用某些在大量有标记图像数据下学习到的公开的较好的配置来初始化我们具体问题的模型。
迁移学习(Transfer Learning) 指的是我们将在某种设置下学习到的知识迁移到一个新的领域中,这有点类似于我们人类举一反三的能力。其基本思想是对于某类任务,其输入或输出遵循一定的基本的共通的规律,学习其中一个则其他任务也可以受益。其中极端的例子是zero-shot learning,即在没有相应的具有标记的数据的情况下进行学习,例如在机器翻译中,假如我们想将X语言中的单词A翻译成Y语言中的单词B,而我们并没有直接的将X中A对应到Y中B单词的训练数据,但我们之前已经得到了A在X中的表征,B在Y中的表征,假如我们学习过X与Y的表征空间的映射(例如我们只需要一些X和Y中哪些句子是成对的数据而不需要单词一一对应的数据即可学习这种映射),则我们可以推断A的对应的翻译B。
分布式表示(Distributed Representation) 指的是我们希望学习到的表示是由各个相互独立的基本元素组成的,这样我们可以高效的将空间进行分割。例如如下图中人脸的表示,我们可以学习独立的特征如是男性还是女性,戴眼镜还是不戴。这样分布式表示的好处是我们并不需要数据中囊括所有元素的所有的组合如我们并不需要戴眼镜的女性的训练数据,而且我们可以通过这些基本元素合成新的数据。

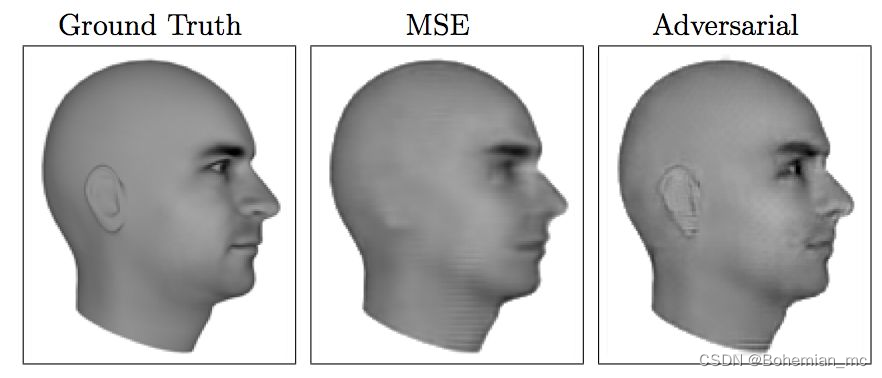
不可否认的是之前很多的无监督学习方法有一定的局限性,比如我们常常需要设定特定的优化目标,比如均方差尽量小,这决定了哪些特征可以是显著的特征而忽略了其他特征。例如图像合成领域某些局域的对比度变化不高的图案会被忽略掉。所以Ian提出了生成对抗网络(Generative Adversarial Network) 简称GAN,其基本思想就是我们训练生成模型取欺骗另一个分类器,而分类器则是尽量提高能区分出我们的生成模型与真实的训练数据的准确度。这样两个模型都不断改进,并且能提取所有的关键信息而不产生遗漏。如下图中所示,采用均方差为训练目标的传统无监督学习的合成图像会丢失掉耳朵的信息,而GAN合成的图像则可以以假乱真。
怎样判定某种表示优于另一种表示呢?这里总结一些大致的指导思想,当然具体问题还需要选取合适的判定条件:
- 平滑性。即对于输入的微小变化,输出不受影响,我们可以比较容易的从训练数据推广到与它们相邻的数据。
- 线性。即假定某些变量是线性相关的,这样我们可以利用已有数据延展到分布较远的数据,当然这一点不一定适用所有问题。
- 影响因素独立性。这样我们就可以将概率分布简单的分解为若干更基本的概率分布的乘积 P ( h ) = ∏ i P ( h i ) P(h)=\prod_i P(h_i) P(h)=∏iP(hi)。
- 等级性,即我们可以不断的从简单的概念逐级叠加成更复杂的结构。
- 不同任务间的基本因素的可共享性。
- 特征在时间空间变换上的缓慢性。例如前面的慢特征分析模型(线性因子模型——深度学习第十三章)。
- 稀疏性,即只有少数重要的特征。
总结
合理的特征表示是机器学习的核心思想之一,怎样使知识迁移,使机器能像人类一样自然地学习,也是比较活跃的研究课题之一。














 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









