






残差网络为什么有用?
通常来讲,一个网络越深,它在训练集上训练的效率就会有所减弱,但在训练ResNets网络时,并非完全如此。如果将深层网络的后面若干层学习成恒等映射,那么模型就退化成浅层网络。但是直接去学习这个恒等映射是很困难的,那么就换一种方式,把网络设计成:
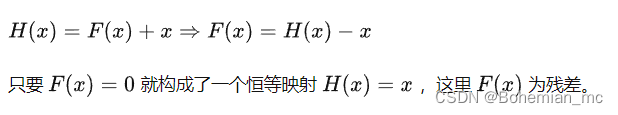
引入残差的映射对输出的变化更加敏感,比如输出由1.1变化到1.2时(假定输入x为1),残差结构的映射F(x)由0.1到0.2,增加了100%。
所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现。残差网络起作用的主要原因就是残差块学习恒等函数非常容易,能保证网络性能不会受到影响,很多时候甚至可以提高效率,至少不会降低网络的效率,因此创建类似残差网络可以提升网络性能。
谷歌Inception网络(Inception network motivation)
在构建卷积层时,需要决定过滤器的大小或者是否添加池化层,Inception 网络的作用就是代替人来决定这些问题,虽然网络架构会因此变得更加复杂,但网络表现却非常好。
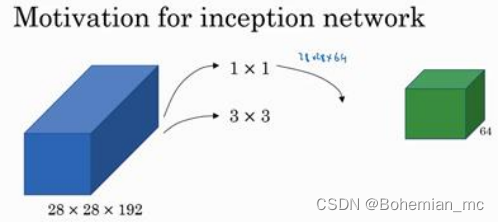
如果使用 1×1 卷积,输出结果会是 28×28×#(某个值),假设输出为 28×28×64,并且这
里只有一个层。
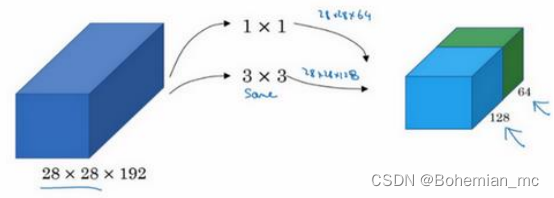
如果使用 3×3 的过滤器,那么输出是 28×28×128。然后把第二个值堆积到第一个值上,为了匹配维度应用 same 卷积,输出维度依然是 28×28,和输入的宽度和高度维度相同。
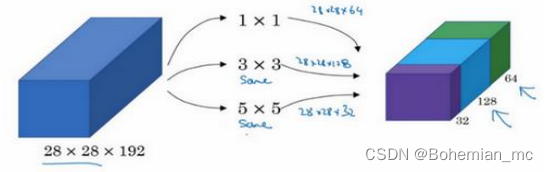
为了提升网络的表现,使用 5×5 过滤器,输出变成 28×28×32,再次使用 same 卷积,保持维度不变。

最后使用池化操作,得到一些不同的输出结果,这里的池化输出是 28×28×32。为了匹配所有维度,需要对最大池化使用 padding,它是一种特殊的池化形式,因为如果输入的高度和宽度为 28×28,则输出的相应维度也是28×28。然后再进行池化,padding 不变,步幅为 1。有了这样的 Inception 模块,就可以输入某个量,因为它累加了所有数字,这里的最终输出为 32+32+128+64=256。Inception 模块的输入为 28×28×192,输出为28×28×256。这就是 Inception 网络的核心内容,提出者包括 Christian Szegedy、刘伟、贾扬清、Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke 和 Andrew Rabinovich。
基本思想是 Inception 网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,可以人为给网络添加这些参数的所有可能值,然后把输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
迁移学习
如果用一句话概括,就是借助已训练好网络结构的权重作为预训练转移到自己的任务上。假如要构建一个猫咪检测器用来检测猫图,有两种猫Tigger和Misty,则构成一个三分类问题,输入图片中的是Tigger或Misty或都不是,忽略两种猫出现在一张图片里的情况,而手中又没有两种猫的大量图片,这时就有必要进行迁移学习。
假设使用ImageNet数据集,它的Softmax单元可以输出1000个可能的类别之一,于是可以去掉Softmax层,创建自己的Softmax单元来输出Tigger、Misty和neither三个类别,当数据集很小时,可以冻结网络中所有层的参数只训练和Softmax层相关的参数;当数据集更大时,冻结的层也应该减少;如果拥有足够多的数据,就应该训练整个网络。
数据增强
1.垂直镜像对称

2.随机裁剪
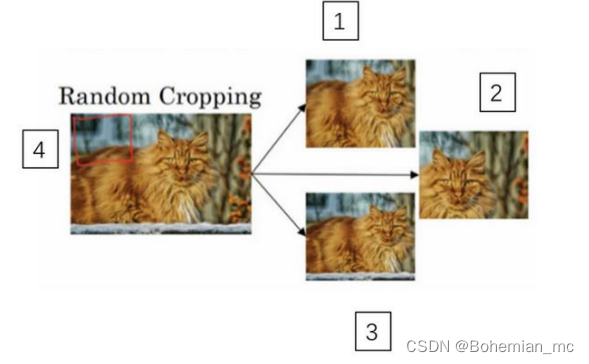
3.彩色转换
针对一张图片,给 R、G 和 B 三个通道上加上不同的失真值。
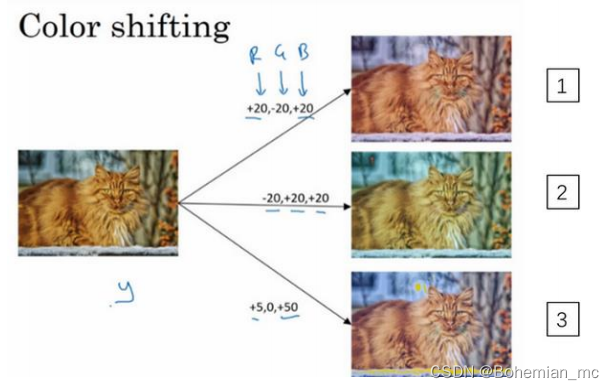
影响颜色失真的算法——PCA
如果图片呈现紫色,即主要含有红色和蓝色,绿色很少, PCA 颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,使总体的颜色保持一致。
4.CPU线程
不停的从硬盘中读取数据形成图片数据流。用CPU 线程来实现图片的失真变形,可以是随机裁剪、颜色变化,或者是镜像。但是对每张图片得到对应的某一种变形失真形式,从而得到不同颜色的猫。与此同时,CPU 线程持续加载数据,然后实现任意失真变形,从而构成批数据或者最小批数据,这些数据持续的传输给其他线程或者其他的进程,然后开始训练,在 CPU 或者 GPU 上实现一个大型网络的训练。
有助于在基准测试中表现出色的小技巧
1.集成
独立训练几个神经网络,并平均它们的输出。
缺点:增大计算成本,占用更多计算机内存。
2. Multi-crop at test time
将数据增强应用到测试图像中。
缺点:运行时间变慢。
目标检测
1.目标定位
图片分类问题就是用算法遍历图片,判断图片中的对象是不是汽车。而目标定位问题不仅需要判断图片中是不是一辆汽车,还需要在图片中标记出它的位置。监督学习任务的目标标签y被定义为:
y = [𝑝𝑐 𝑏𝑥 𝑏𝑦 𝑏ℎ 𝑏𝑤 c1 𝑐2 𝑐3 ]T
𝑝𝑐表示是否含有对象
①当存在对象时,pc=1,bx、by、bh、bw指明边界框位置。
②不存在对象时,pc=0,此时y的其他参数没有意义。
2.特征点检测
选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
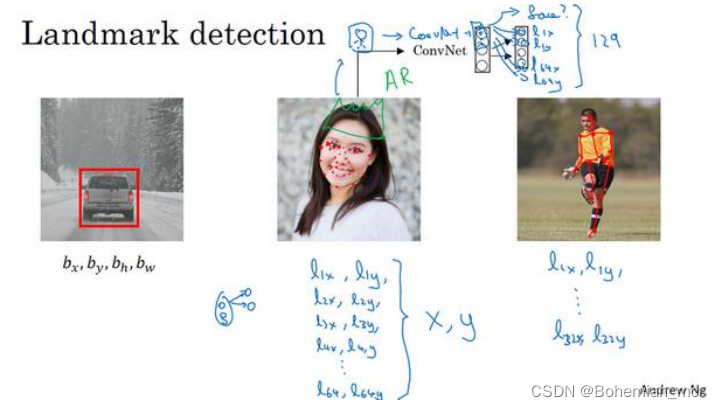
3.目标检测
要构建一个目标检测算法,首先要创建一个标签训练集,也就是𝑥和𝑦表示适当剪切的汽车图片样本,样本需要适当的窗口裁剪。

然后通过训练的卷积网络实现滑动窗口目标检测。

遍历图像的每一个区域,把窗口剪切后的小图输入卷积网络,对每个位置按照 0 或 1 进行分类。
接着选择更大的窗口重复上述操作,保证无论汽车在图片的什么位置总有一个窗口能够检测到。
缺点:计算成本大,在图片中剪切出太多小方块,卷积网络要一个个地处理。如果选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,计算成本也会增大。
4.滑动窗口的卷积实现
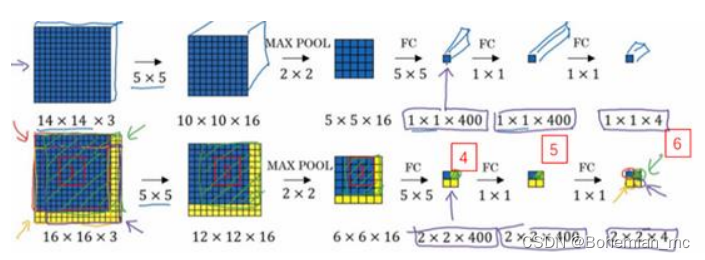
假设输入给卷积网络的图片大小是 14×14×3,测试集图片是 16×16×3,使用滑动窗口卷积网络运行4次,但其中存在着大量重复计算。而执行滑动窗口的卷积操作将原本输出的400个数字的集合转换为输出层1×1×400的数字层,图片中划分了四个窗口,输出层为2×2×400,再进行一次全连接操作得到2×2×4 的输出层。
这种方法能够提高整个算法的效率,但也存在着一个问题,边界框的位置可能不够准确。
5.Bounding Box 预测(Bounding box predictions)
在滑动窗口法中,可能没有一个边界框能够完美地匹配汽车位置,也可能会出现边界框的形状与窗口不同等,如图。

一个能够得到更精确边界框的算法是YOLO(You only look once)算法,这是由 Joseph Redmon,Santosh Divvala,Ross Girshick 和 Ali Farhadi 提出的算法。
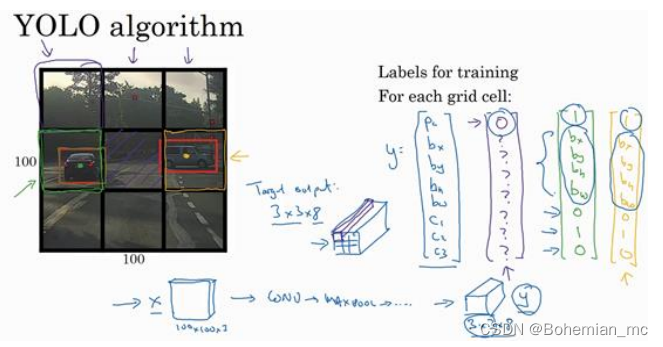
把对象分配到一个格子的过程是,观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到 9 个格子其中之一,就是 3×3 网络的其中一个格子。当网络划分的格子数更多时,两个对象的中点被分配到概率就会更低。
6.交并比
IOU=(A∩B)/(A∪B)

一般约定,在计算机检测任务中,如果𝑙𝑜𝑈 ≥ 0.5,就说检测正确(阈值一般不会低于0.5)
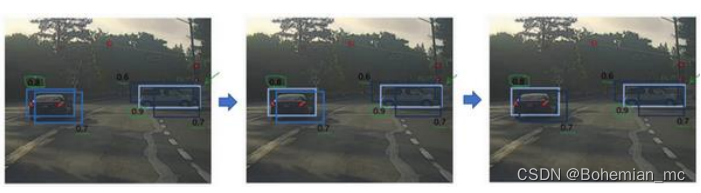
7.非极大值抑制(Non-max suppression)
只输出概率最大的分类结果,抑制很接近、但不是最大的其他预测结果(即𝑙𝑜𝑈值较大),所以这方法叫做非极大值抑制。
8.Anchor Boxes
对象检测中存在的一个问题是每个格子只能检测出一个对象,anchor box可以实现一个格子检测出多个对象。每个对象都分配到对象中点所在的格子中,并匹配与对象形状交并比最高的 anchor box 。
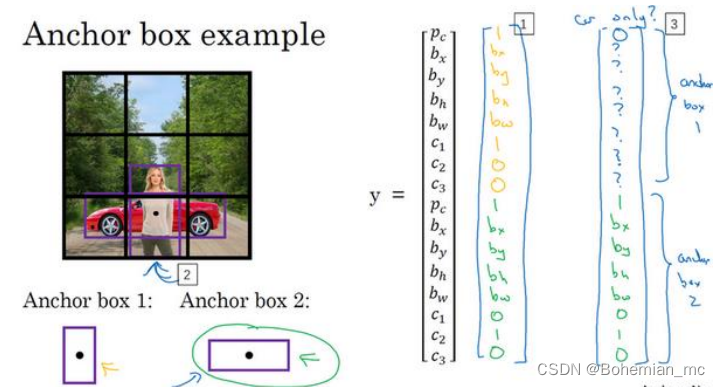
行人更类似于 anchor box 1 的形状,所以对于行人来说,信息表示存放在向量的上半部分;车子的形状更像 anchor box 2,信息存放在下半部分。
更高级的做法是采用 k-平均算法 ,可以将两类对象形状聚类,这其实是自动选择 anchor box 的高级方法。
9.YOLO算法(Putting it together: YOLO algorithm)
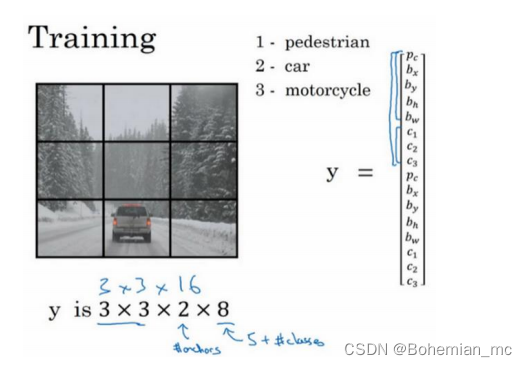
假定有 3 个类别标签,两个 anchor box,那么输出 𝑦 就是 3×3×2×8,其中 3×3 表示 3×3 个网格,2 是 anchor box 的数量,8 是向量维度,8 实际上先是 5(𝑝𝑐, 𝑏𝑥, 𝑏𝑦, 𝑏ℎ, 𝑏𝑤)再加上类别的数量(𝑐1, 𝑐2, 𝑐3)。可以看成是 3×3×2×8或者 3×3×16。要构造训练集,需要遍历 9 个格子构成对应的目标向量𝑦。
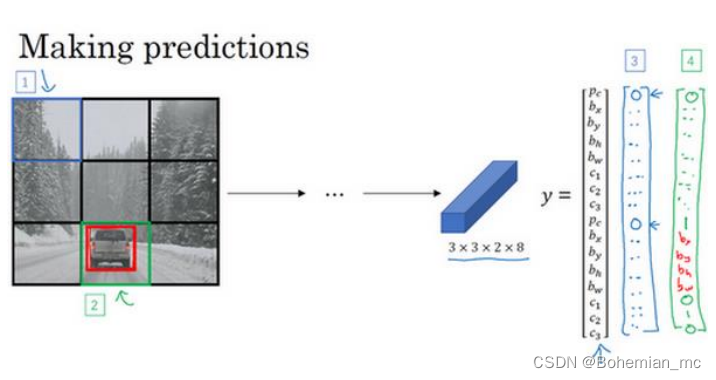
对于边界框1,里面没有任何我们想要的东西,因此输出的两个𝑝𝑐都为0;对于边界框2,anchor box 2 对应汽车,检测到格子中存在汽车,因此向量下半部𝑝𝑐为1。
最后运行非极大值抑制,对于 9 个格子中任何一个都会有两个预测的边界框,对每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框。















 1590
1590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









