







混合高斯模型就是把每一个类都用一个高斯分布来描述。K-Means对每一个类是没有建模的,它只是给一个中心点,GMM进一步的用高斯模型来描绘这个类里面的数据。也就是说,现在每一个类是一个概率模型,也就可以给出每一个点属于哪一个类的概率。
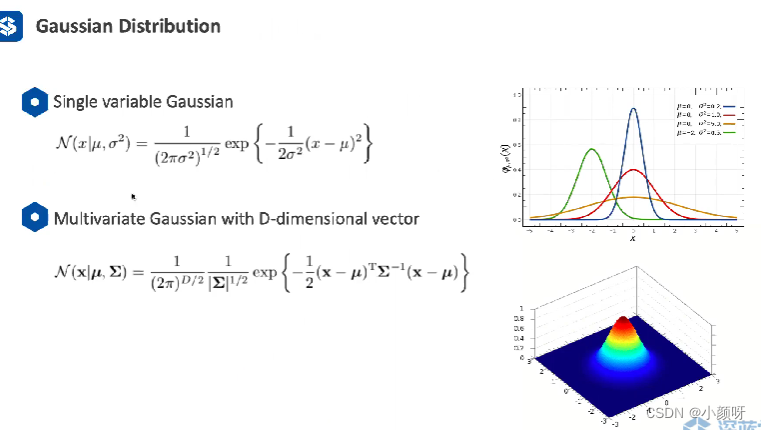
一维高斯模型比较简单,就是它的中心点 、平均值,
是它的方差、标准差。不同的平均值,方差,就会有不同的图形。到二维(2*2),
、
、x都是向量或矩阵,平方变成向量的转置后矩阵的乘法。数学上,GMM表达成多个高斯模型的线性组合,有K个高斯模型,K是事先给定的,与K-Means一样,都需要人工给定有多少个。线性组合长这个样子,
表示每个不同高斯模型占的权重,所以一个GMM是由三个参数
、
、
来描述的。
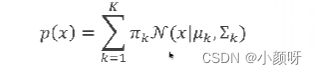
可以从已知的高斯模型里面去产生数据,但我们想知道的是给定一堆点,想要知道每一个点在每个高斯模型的概率,仅有P(x)是解决不了的。
一个点属于一个类或者说属于一个高斯模型在数学上如何表达的?每一个数据点如果属于第k类,那么Zk = 1,Zk用来表达一个点属于一个类的事件。P(Zk = 1)这个概率涉及到先验分布问题。若没有告诉这个点在空间中的位置,就确定这个数据点属于哪一个类的概率分别是什么,这就是先验分布。先告诉x在空间中的位置,且也知道这个高斯模型的形状,也就是x是已知的,且、
、x都已知,以此来计算它属于每一个高斯模型的概率,这就是后验概率P(z|x)。可用贝叶斯公式计算P(z|x),如图。

P(x)就是整个GMM概率模型,公式如图。
既然一个GMM是多个高斯模型的线性组合,那么就可以把它建模成一个有向图,z表示一个数据点属于哪一个高斯分布,x表示选中的高斯分布。既然是线性组合,那么每一个高斯模型都有一个权重,z是很多个向量放在一起的标量,每次只能选中一个。

如果已经知道Zk = 1,也就是一个数据点它是属于第k个高斯模型,那就可以拆开成一个简单的高斯分布,如下图第一个式子。将P(x|z)写成第二个式子的形式, 只有当Zk = 1的时候,它才会变成高斯模型,其他时候都为1,因为Zk = 1。
综上,P(x)、P(x|z)都知道了,那么就可以得到P(x,z),对它积分,就得到整个GMM的概率模型P(x)。
现在计算后验概率P(z|x)(给定一个数据点x,它属于每一个高斯模型的概率分别是什么),把后验概率P(Zk = 1|x)写成(Zk),计算公式如下:

但是给定一堆数据点以及k,如何计算高斯模型参数呢?方法就是Maxinum likelihood,也就是我有一个模型,有数据点,我需要这些数据点最大可能性符合我的模型,那么概率就很大,但是概率的乘积不好计算,所有加个ln,就变成了加法,如下式,也就是需要最大化下式这个损失函数,求到x、、
、
。

但此时我们需要考虑一个singularity问题,也就是GMM在Maxinmum Likelihood下的奇点问题。我们可以把高斯模型套到一个点,一个点方差为0,此时系统就崩了。要避免,那就不使用MLE方法,使用MAP或者贝叶斯。
但我们依然选择MLE,如果出现某一个方差等于或者很小,我们将其随机初始化为另一个数值就好。
如何求解最大似然(MLE)?固定其他两个,来求解另一个。
简化后:
观察这个式子, k是这些数据点的加权平均。
同理得到k,这里
k也是加权平均,是方差的加权平均,权重是后验概率。
 在GMM里面,对于
在GMM里面,对于k、
k是没有限制的(没有先验的),但
k不一样,它有限制,它是不同高斯模型线性组合的权重,全部加起来为1。所以解
k用拉格朗日重组法。

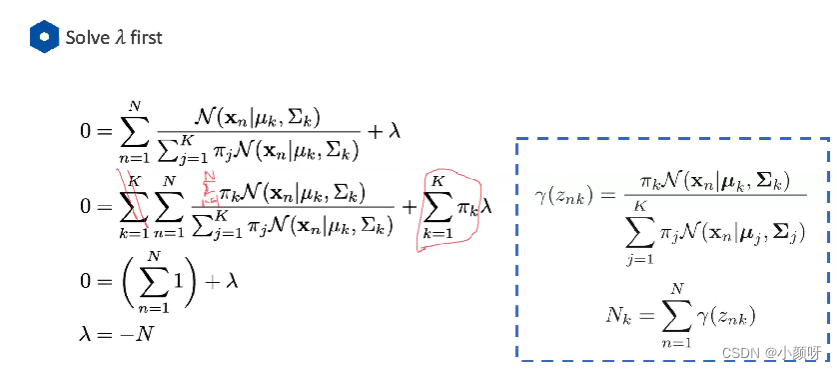

由结果看到k就是权重。
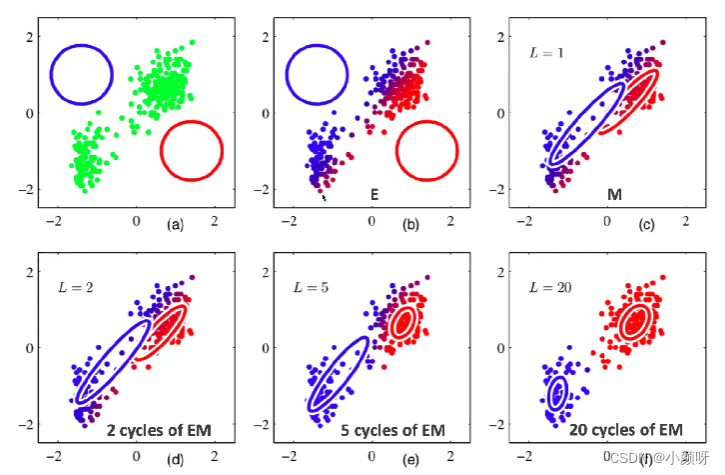
总结:
















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









