






论文地址:https://arxiv.org/abs/2103.14030
代码地址:https://github.com/microsoft/Swin-Transformer
问题:
1 Transomer结构因为应用在CV领域,使用图像来计算Attention矩阵,计算量太大。
2 NLP领域中的Scale是固定的,图像中的Scale变化范围很大。
文章核心点:
1 把CNN中的层次化结构应用在了Transfomer结构中。(实现了感受野的变大)
2 新的相对位置编码方法
3 移动窗口机制SW-Transformer
效果:
image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-theart by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K 。(在分割、目标检测、分割等多个公共数据集上的效果目前是最强的)。
一、CNN层次化结构以及window结构的创新
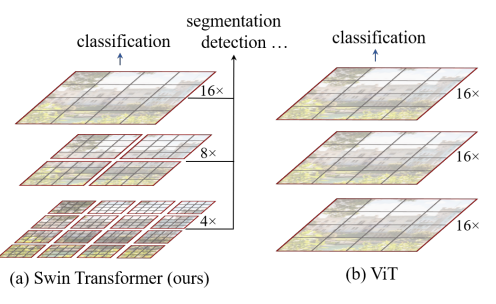
左图是:Swin-Transformer中的层级化结构,右图是ViT中的结构。文章中作者采用了不一样的下采样,进而实现了类似CNN中的池化效果,实现了图像感受野的不断扩大。通过划分多个WIndow,在Window内进行了Attention的计算,从而实现了Attention矩阵的计算量减少。(图来自论文中)
模型结构:
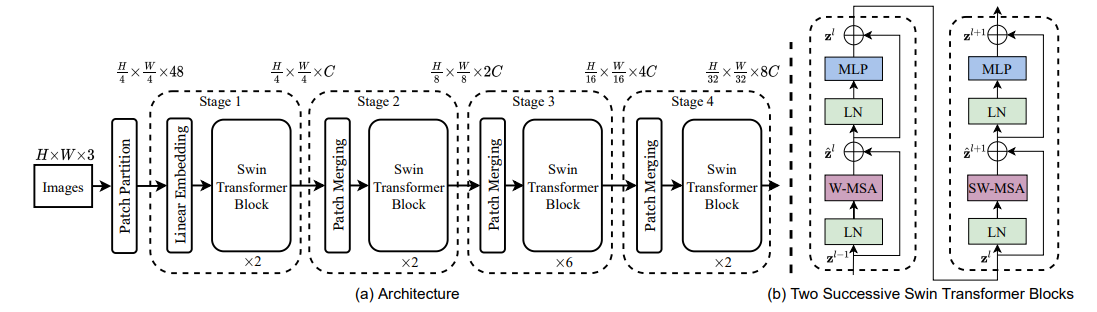
SwinTransformer Block块,是将ViT中的Transformer结构中的MSA替换为了W-MSA(窗口注意力机制)和SW-MSA(滑动窗口自注意力机制)。值得注意的是:该模型中的SwinTransformer Block块均是成对出现的。是因为一个SwinTransformerBlock块里面仅有W-MSA和SW-MSA其中一个,文中需要讲这W-MSA和SW-MSA结合使用的。下面会将为啥要这么做。(图来自论文中)
Patch Partition的操作:
对原始图像做4*4的Windows的划分,划分之后将Windows展平。
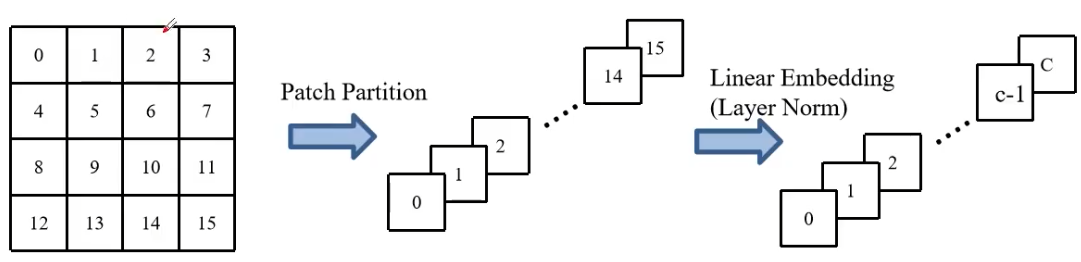
假如对图片进行4*4的Windows窗口划分,得到的图像则为4*4*3(H*W*C)C为通道,H、W为图像的高与宽。上图仅使用了一个通道,之后讲4*4的图像展平,做LayerNorm。(方便Swin-Transfromer结构的接入)。
代码部分:
初始化部分
图像默认按照224*224*3输入,patch_size为4*4
to_2tuple():查看代码中,是用来讲224->元组 224,224.
之后通过相除来获得patch之后的图像数量。
方法部分:
x = self.proj(x).flatten(2).transpose(1, 2) 通过对图像进行划分和展平。值得注意的是,文中进行图像划分采用了卷积的操作,通过4*4卷积核和步长为4的二维卷积。(为了防止图像打框产生重叠)
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flopsPatch Merging
(下采样的过程。通道数翻倍,采样倍数,取决于windows的大小)。
方法:打框划分在一个window的多个图片,相同部位的元素取出来,构成新的window,之后将这部分图像做深度方向的拼接(直接叠起来),深度方向在进行归一化和线性映射。
例如取4*4图像,按照顺序对像素进行编号(从左上到右下),那么取0,2,8,10为相同部位,构成一个新的2*2图像,其他同理。
(不偷懒了VIsio画图解释吧。)
 取相同元素
取相同元素 深度方向做拼接
深度方向做拼接 深度方向归一化
深度方向归一化 进行线型映射(4-2)
进行线型映射(4-2)
对比原来的图像能够明显的发现,图像的尺寸从4*4*1变成了2*2*2,实现了通道数翻倍,图像的H*W缩小为原来一倍。
代码部分:
x0、x1、x2、x3部分则是对图像的B和C两者不变,H和W进行除2的操作,进行等同于上图中的取了相同位置元素,得到了相同元素的四张图。之后通过cat对四个图像进行深度方向拼接。进而norm进行深度方向归一化,最后的reduction(x)在源代码中为:线型层,做了4-2的线性映射,从而讲图像由4个通道映射为2通道,实现了模型结构中的通道数翻倍,H、W缩小原来一半的操作。
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return xW-MSA(窗口注意力机制的计算)
优点:减少计算量。缺点:但是会导致窗口之间的信息丢失。
理解:
(一)减少计算量:文中给了公式:
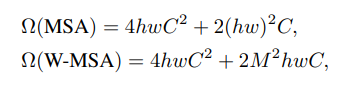
想计算其实可以直接计算。我举个例子理解吧:原图像是16*16*1,那么我计算Attention矩阵,我就需要进行(16*16)^2的计算量,因为Attention矩阵需要每一个像素都要对全部的元素进行Attention的计算么。如果我划分了4*4的窗口,那么16*16的图像,就变成了(16*16)/(4*4)= 16,16个4*4的图像,我这个时候进行Attention的同步计算,(4*4)^2*16.对比两次的计算结果:65536和4096,很明显的就是计算参数少了一大堆。从而解决了Transformer结构应用在CV领域中经常内存爆了和计算缓慢的问题。
(二)窗口信息的丢失:
一个图像划分了多个块,计算Attention的时候块之间的信息肯定是没有的,比如你将一个完整狗的图像放进去,你划分了4*4的窗口,那么可能计算Attention的时候狗的耳朵和鼻子之间划分在了不同窗口,进行计算Attention矩阵的时候,信息就出现了丢失。
代码:就是Transfromer结构中的Attention在windows之间的计算。
SW-MSA(滑动窗口注意力机制的计算)
问题:解决WMSA之间窗口数据的丢失。
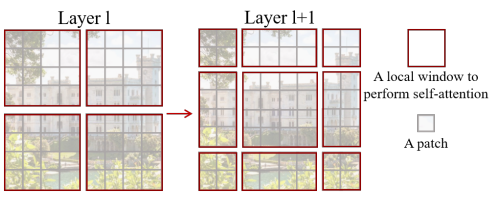
文章中的图,左边是W-MSA划分的窗口,右边是SW-MSA划分的窗口。
那么如何在W-MSA之后的图变成右边SW-MSA的图呢。文中给出的方式则是通过左边图向右下移动2个像素。 如下图:橘色的是框框。


之后打上序号:


此时1框内的图像就融合了之前12区域之间的信息,3则融合了之前图像中23区域之间信息。中间的4融合之前四个区域之间的信息。从而实现了不同Windows信息之间的交互。(区域1234是之前W-MSA之间的四个区域,顺时针编号)
但是此时出现了一个问题就是在进行计算的Attention的时候,0-8这几个区域之间的尺寸不一样的,不能够同时和并行计算,并且从原来的4个Attention矩阵的计算,变成了9个,相当于增加了计算量。此时文中剔除了一个新的方法。
通过移动不同的1-9窗口实现拼接。从而只用计算4*4的Attention信息。 类似这样子的移动。(012区域移动到最下面--在讲360区域移动到最右边)。
从而能够对四个一样大小的Windows进行Attention计算。均为4*4的大小。
但是这样子又会引入一个新的问题,例如右下角那4个2*2的图像,本质上在原始图像是不相邻的,如果直接计算Attention信息将会融合错的(以为在原图上是不相邻的),导致不必要的信息被计算。
我们只想让0-8每一个之和自己相同区域的元素做Attention。进而文中提出来相对位置编码。
relative_position(相对位置编码)
此时去右下角的4个2*2的块做讲解。
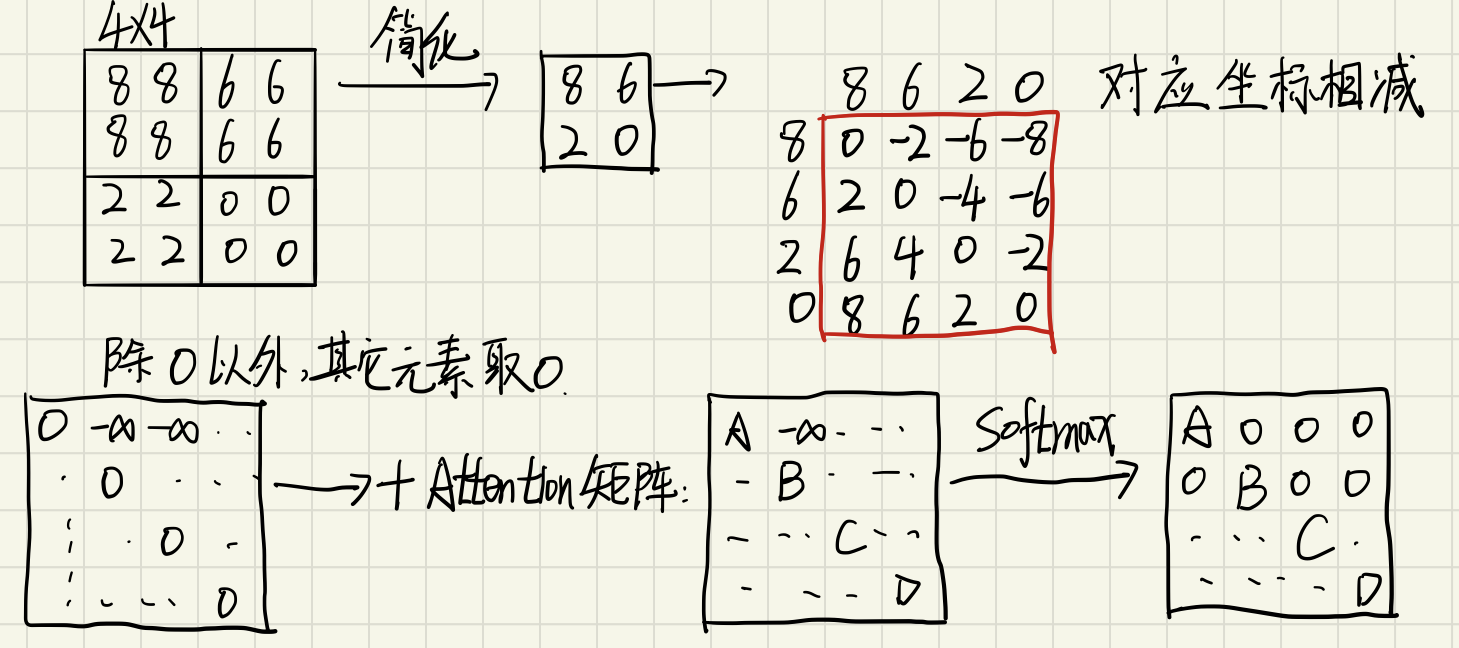
对每个块进行编码,然后讲全部元素展平,然后在进行翻转,对应元素做相减。从而构成了新的位置矩阵。那么我们能够发现,对应位置的元素的相减均为0,其余均有数值,此时,对全部有数据的元素全部取-无穷。文中取是-100,此时在进行Softmax的时候,那么-100的位置均为0了,从而实现了每个区域自己的Attention计算。
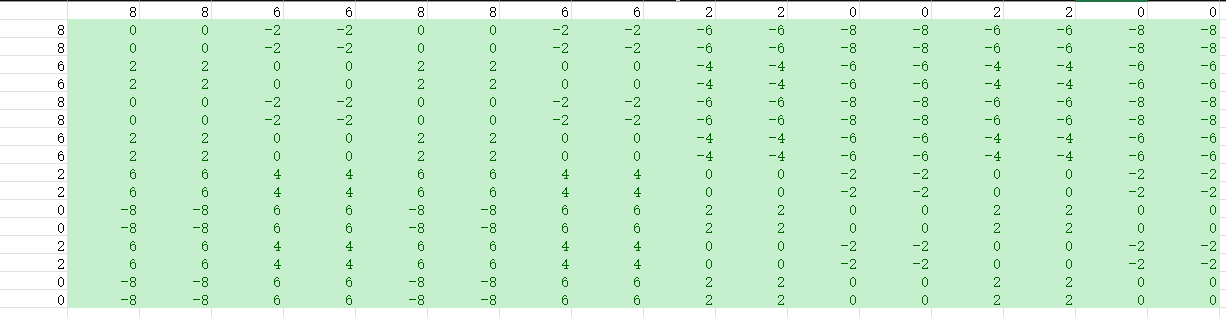
上面的表格则是8620这四个块生成的相对位置编码。此时还不能讲改位置编码矩阵融入Attention矩阵,文章中采用了和VIT一样的方式,通过学习生成一个对应大小的相对位置编码的索引,通过上述的位置编码矩阵从索引里面取值。进而得到一个新的B矩阵,这个B矩阵即为真正融入到Attention中的相对位置矩阵。
文章中的公式:
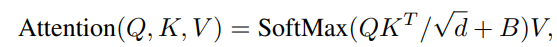
代码部分:
通过relatice_coodes,对每一个块进行编码。此时生成位置编码。
进而通过在:
self.relative_position_bias_table[self.relative_position_index.view(-1)].view( self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
在relative_position_bias_table的所以表中取得相对应索引的数据。
attn = attn + relative_position_bias.unsqueeze(0)通过讲索引信息融入到Attention矩阵中。
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
以上为:Swin-Transformer中的,作者对于该文章和代码的理解和思考。如果想要更加深入的了解,可以去看一下原文和代码。
















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











