







一、图像压缩编码的可能性
图像压缩编码的核心理念在于利用图像数据中的冗余信息。余指的冗是数据中可以被重复、简化或省略的部分,而图像本身常常包含大量的冗余。由于图像的性质,例如相邻像素通常有相似的颜色、亮度等特征,通过分析这些特征,我们可以有效地减少所需存储的数据量。这种减少不仅节省了存储空间,还加速了数据的传输。
二、图像中的冗余类型
1. 空间冗余
空间冗余是指图像中相邻像素之间的相似性。想象一下,一张蓝天的图像,大多数像素都是蓝色的。通过识别这种相似性,压缩算法可以只存储一个蓝色值和它重复出现的次数,而不是记录每一个单独的像素值。这种方法不仅节省了空间,还保留了原始图像的视觉效果。

2. 时间冗余
在视频压缩中,相邻帧通常会有很大相似性。例如,在一段视频中,人物在移动,而背景几乎不变。压缩算法可以只记录帧之间的差异(即运动的部分),这样可以显著减少需要存储的数据量。这种技术在视频编码中非常常见,比如H.264、HEVC等标准。
3. 信息熵冗余
信息熵是一个衡量信息复杂度的指标。在图像中,某些区域的信息量相对较小,比如一片均匀的天空,这部分可以用较少的比特来表达。相反,复杂的图像区域(如细节丰富的树木、建筑等)则需要更多的信息来准确描述。通过不同的编码策略,对于信息熵低的区域使用简单的表示方法,对于信息熵高的区域使用复杂的方法,可以达到更高的压缩效果。
4. 结构冗余
结构冗余类似于我们在观察图像时,能够识别出图像的基本元素(如线条、边缘和形状)。这些结构特征可以通过特定算法(如边缘检测、分块处理)来有效表示,从而减少存储的数据量。例如,分块编码可以将图像分成多个小块,对每个块进行独立处理,从而压缩整体图像。
5. 知识冗余
知识冗余是指在压缩过程中利用已有的知识和模型。例如,某种特定的图像(如风景画、肖像等)可能具有特定的构图和配色规律,我们可以利用这些规律进行更高效的编码。机器学习和深度学习模型在这方面的应用越来越普遍,通过学习大量图像的特征,使得压缩算法可以自动适应不同类型的图像。
6. 心理视觉冗余
人眼对颜色和细节的敏感度是不同的。例如,人眼对蓝色和绿色的变化比对红色和黄色的变化要敏感得多。在图像压缩中,我们可以将那些人眼不太敏感的颜色信息用更少的比特来表示,从而进一步压缩图像。这种方法常见于JPEG压缩中,它通过色彩空间转换(如从RGB到YCbCr)来降低对人眼可见的细节保存。
三、图像压缩编码的分类
一、根据编码方式的分类
-
无损压缩:
- 无损压缩允许图像在压缩后可以完全恢复为原始图像,适合需要高保真度的场景,如医学图像、法律文件等。
- 示例格式:PNG、GIF。
- 应用:在需要精确数据的情况下,如文本图像、医学影像等。
-
有损压缩:
- 有损压缩允许在压缩过程中丢失一些信息,通常肉眼无法察觉,适合于需要快速加载或减少带宽的场景,如网络图片和数字摄影。
- 示例格式:JPEG、WebP。
- 应用:适用于普通照片、网页图像等对文件大小有严格要求的应用。
二、根据编码原理的分类
-
熵编码:
熵编码是基于信号的统计特性进行编码的一种技术,它是一种无损编码方式。熵编码的基本思想是根据符号的出现概率来分配码字:- 目的:通过这种方式,平均码长得以缩短,从而实现压缩效果。
- 低频符号赋予长码字:对出现频率低的像素(或符号)使用较长的码字。
- 高频符号赋予短码字:对出现频率高的像素(或符号)使用较短的码字。
- 常见的熵编码方法:
- 哈夫曼编码:构建一棵二叉树,频率高的符号在树的上层,得到的码字较短;频率低的符号在树的下层,得到的码字较长。
- 算术编码:将整个消息表示为一个数值区间,动态调整区间来适应不同符号频率,实现更高效的压缩。
- 行程编码:记录连续相同符号的数量,例如“红色像素出现10次”可以用“红色+10”来表示,适合于重复信息较多的图像。
-
预测编码:
预测编码基于图像数据的空间或时间冗余特性。它利用相邻像素(或像素块)的值来预测当前像素(或像素块)的值,然后对预测误差进行编码:- 优点:由于相邻像素通常变化不大,预测误差通常较小,因此可以用更少的位数来表示。
- 基本原理:当前像素的值通过周围像素的值进行预测,只存储预测误差(即实际值与预测值之间的差异)。
- 预测编码的分类:
- 帧内预测:在静态图像中,通过同一帧内的已知像素进行预测。
- 帧间预测:在视频编码中,通过利用前后帧的已知数据进行预测,适合处理连续图像序列。
- 常用的预测编码技术:
- 差分脉码调制(DPCM):将当前像素与预测值的差异进行编码,适合静态图像的压缩。
- 运动补偿法:在视频中分析相邻帧的运动,记录运动矢量和差异部分,极大地减少冗余数据。
-
变换编码:
- 通过将图像数据从空间域转换到频率域来减少冗余。常用的算法是离散余弦变换(DCT),此方法可以保留重要的低频信息,压缩高频信息。
- 应用:广泛用于JPEG图像压缩。
-
混合编码:
- 结合了多种编码方法的优点,通常在视频压缩中使用。例如,H.264标准结合了预测编码和熵编码,能够高效处理视频数据。
四、图像压缩编码的系统评价
在评价图像压缩编码的效果时,我们通常考量以下几个重要指标:
1. 压缩比
压缩比是压缩后的文件大小与原始文件大小的比率。一个好的压缩算法应当在尽量小的文件大小下保持图像的质量。
2. 图像质量
图像压缩后的质量是评价压缩效果的重要指标。通常使用PSNR(峰值信噪比)和SSIM(结构相似性指数)等客观指标来衡量。同时,主观评价即用户的视觉感受也是非常重要的,尤其在艺术和视觉设计行业。
3. 计算复杂度
这指的是编码和解码过程所需的计算资源和时间。高效的压缩算法应在保持较高压缩比和图像质量的同时,具备较低的计算复杂度,以保证快速处理。
4. 适应性
压缩算法的适应性是指其对不同类型图像(如风景、肖像、文本等)的表现能力。优秀的算法应能针对不同图像类型优化其压缩策略。
5. 鲁棒性
鲁棒性是指压缩后图像在传输中对噪声和损坏的抵抗能力。尤其在网络传输中,图像可能会受到干扰,鲁棒性强的压缩算法能更好地保持图像的可用性和可视性。
五、熵编码
5.1 哈夫曼编码
哈夫曼编码是一种用于数据压缩的算法,属于熵编码的一种,旨在通过为频率高的符号分配短的码字,为频率低的符号分配长的码字,从而减少整体数据量。
想象一下你在一个派对上,你和朋友们在聊天。你们讨论了很多事情,但有些话题你们讨论的次数非常多(比如“天气”),而有些话题讨论的次数很少(比如“外星人”)。为了节省时间,你们决定给常聊的话题起一个简短的代号,而给那些少聊的话题起一个相对较长的代号。这样,你们在聊天时,就能更快地表达常见的话题,而不需要每次都说完整的句子。

同样,哈夫曼编码通过为频率高的字符或符号分配较短的二进制码(0和1的组合),为频率低的字符或符号分配较长的二进制码。这可以有效地减少需要存储或传输的数据量。
下面是哈夫曼编码的具体步骤:
1. 统计符号频率
首先,我们需要分析待压缩的数据,计算出每个符号出现的频率。举个例子,假设我们有以下字符及其出现频率:
| 字符 | 频率 |
|---|---|
| A | 5 |
| B | 9 |
| C | 12 |
| D | 13 |
| E | 16 |
| F | 45 |
2. 构建哈夫曼树
哈夫曼编码的核心是构建一棵哈夫曼树。构建哈夫曼树的步骤如下:
- 初始化:将每个字符及其频率视作一棵独立的树。
- 构建树:
- 找到频率最小的两棵树,将它们合并成一棵新树,新树的频率为两棵树的频率之和。
- 将新树放回树的集合中。
- 重复以上步骤,直到只剩下一棵树。
示例:
-
初始状态:
A:5, B:9, C:12, D:13, E:16, F:45 -
合并A和B(频率5和9),形成新节点(AB:14):
C:12, D:13, E:16, AB:14, F:45 -
合并C和D(频率12和13),形成新节点(CD:25):
E:16, AB:14, CD:25, F:45 -
合并AB和E(频率14和16),形成新节点(ABE:30):
CD:25, ABE:30, F:45 -
合并CD和ABE(频率25和30),形成新节点(CDA:55):
CDA:55, F:45 -
最后合并CDA和F,形成根节点(CDAF:100)。
最终的哈夫曼树如下:
100
/ \
55 45 (F)
/ \
30 25
/ \ / \
E AB C D
(16) (14) (12) (13)3. 生成哈夫曼编码
现在我们有了哈夫曼树,接下来要为每个字符分配编码。我们从树的根开始走:
- 从根节点出发:
- 左边分配“0”(向左分叉)
- 右边分配“1”(向右分叉)
分配编码:
-
从根节点向左走到E:
根到E的路径是“00”,所以E的编码是00。 -
从根节点向左再向下走到AB:
根到AB的路径是“01”,所以AB的编码是01。接下来,我们再分解AB:- B在AB的右边,所以B的编码是011。
- A在AB的左边,所以A的编码是010。
-
从根节点向右走到CD:
根到CD的路径是“10”,所以CD的编码是10。接下来,我们再分解CD:- D在CD的右边,所以D的编码是101。
- C在CD的左边,所以C的编码是100。
-
F是根节点的右边,直接给它分配“1”,所以F的编码是1。
最终结果
经过以上步骤,我们得到了每个字符对应的哈夫曼编码:
| 字符 | 编码 |
|---|---|
| A | 010 |
| B | 011 |
| C | 100 |
| D | 101 |
| E | 00 |
| F | 1 |
数学公式:
哈夫曼编码的有效性可以通过计算平均码长来理解。假设我们有n个符号,每个符号的概率为pi(i=1, 2, ..., n),对应的码长为 li,那么平均码长 L 可以表示为:
这里的 li 是每个符号所对应的哈夫曼编码的长度(比特数)。
- L:表示平均码长(以比特为单位)。这是我们想要优化的目标,越小越好。
- n:表示编码中符号的总数。例如,如果有 6 个字符(A, B, C, D, E, F),那么 n=6n=6。
- pi:表示第 ii 个符号的出现概率。概率是符号出现的频率除以所有符号频率的总和。例如,如果字符 A 出现 5 次,总共 100 次字符中,pA=5/100=0.05 。
- li:表示第 ii 个符号的编码长度(以比特为单位)。例如,如果字符 A 的哈夫曼编码是 010,这个编码长度就是 3(因为有 3 位)。
这个公式的背后有几个重要的概念和含义:
1. 加权平均
平均码长 L 用于表示整个编码的效率。公式中的求和 实际上是在计算一个加权平均。每个符号的出现概率 pi都在影响其对应的编码长度 lili。简单来说,这个公式在评估整个编码效率时,考虑到不同字符出现的频率。
- 示例:假设字符 A 的编码是 010(长度 3),而 B 的编码是 011(长度 3),但 A 出现的频率较低(比如 5%),而 B 的频率较高(比如 20%)。那么即使它们的编码长度相同,B的出现频率更高,会在总平均中占更大比重。
2. 优化目标
哈夫曼编码的目标是使 L 尽可能小。这个目标意味着我们希望高频符号有更短的编码,而低频符号有更长的编码,这样可以在保持信息完整的前提下减小整体数据量。
- 如果一个符号的频率很高,那么它的 pipi 值大,这样它的贡献 pi⋅lipi⋅li 在求和中将较大。如果这个符号的编码长度 lili 很小,那么它将会有效降低平均码长 LL。
3. 信息理论背景
这个公式的背后也与信息论有关。根据香农的信息理论,一个符号的平均信息量可以通过其概率计算,较低概率的符号携带的信息量较高。因此,频率高的符号应该有较短的编码,而频率低的符号则可以接受较长的编码。
- 信息量计算:信息量 I 可以用公式 I=−log2(p)计算,其中 p 是符号出现的概率。哈夫曼编码通过优化编码长度与符号的概率密切相关,使得整体信息传输更加高效。
例子说明
假设我们有 3 个字符,频率和编码如下:
| 字符 | 频率 | 概率 pi | 编码 li | pi⋅li |
|---|---|---|---|---|
| A | 5 | 0.05 | 010 | 0.05×3=0.150.05×3=0.15 |
| B | 15 | 0.15 | 00 | 0.15×2=0.300.15×2=0.30 |
| C | 80 | 0.80 | 1 | 0.80×1=0.800.80×1=0.80 |
计算平均码长 L:L=0.15+0.30+0.80=1.25 比特
这个计算告诉我们,平均每个符号需要 1.25 比特来表示。如果我们能够进一步优化,减少某些高频符号的编码长度,那么 L会更小,从而提高编码的效率。
具体代码分析:
*mat2huff.m*
function y = mat2huff(x)
%MAT2HUFF Huffman encodes a matrix.
% Y = mat2huff(X) Huffman encodes matrix X using symbol
% probabilities in unit-width histogram bins between X's minimum
% and maximum value s. The encoded data is returned as a structure
% Y :
% Y.code the Huffman - encoded values of X, stored in
% a uint16 vector. The other fields of Y contain
% additional decoding information , including :
% Y.min the minimum value of X plus 32768
% Y.size the size of X
% Y.hist the histogram of X
%
% If X is logical, uintB, uint16 ,uint32 ,intB ,int16, or double,
% with integer values, it can be input directly to MAT2HUF F. The
% minimum value of X must be representable as an int16.
%
% If X is double with non - integer values --- for example, an image
% with values between O and 1 --- first scale X to an appropriate
% integer range before the call.For example, use Y
% MAT2HUFF (255 * X) for 256 gray level encoding.
%
% NOTE : The number of Huffman code words is round(max(X(:)))
% round (min(X(:)))+1. You may need to scale input X to generate
% codes of reasonable length. The maximum row or column dimension
% of X is 65535.
if ~ismatrix(x) || ~isreal(x) || (~isnumeric(x) && ~islogical(x))
error('X must be a 2-D real numeric or logical matrix.');
end
% Store the size of input x.
y.size = uint32(size(x));
% Find the range of x values
% by +32768 as a uint16.
x = round(double(x));
xmin = min(x(:));
xmax = max(x(:));
pmin = double(int16(xmin));
pmin = uint16(pmin+32768);
y.min = pmin;
% Compute the input histogram between xmin and xmax with unit
% width bins , scale to uint16 , and store.
x = x(:)';
h = histc(x, xmin:xmax);
if max(h) > 65535
h = 65535 * h / max(h);
end
h = uint16(h);
y.hist = h;
% Code the input mat rix and store t h e r e s u lt .
map = huffman(double(h)); % Make Huffman code map
hx = map(x(:) - xmin + 1); % Map image
hx = char(hx)'; % Convert to char array
hx = hx(:)';
hx(hx == ' ') = [ ]; % Remove blanks
ysize = ceil(length(hx) / 16); % Compute encoded size
hx16 = repmat('0', 1, ysize * 16); % Pre-allocate modulo-16 vector
hx16(1:length(hx)) = hx; % Make hx modulo-16 in length
hx16 = reshape(hx16, 16, ysize); % Reshape to 16-character words
hx16 = hx16' - '0'; % Convert binary string to decimal
twos = pow2(15 : - 1 : 0);
y.code = uint16(sum(hx16 .* twos(ones(ysize ,1), :), 2))';上述 mat2huff 函数的主要目的是对输入的矩阵进行霍夫曼编码(Huffman encoding)。霍夫曼编码是一种常用的无损数据压缩方法,适用于符号(值)频率不均匀分布的情况。该函数将输入矩阵转换为更小的编码形式,并提供一些附加信息以便于解码。
函数输入和输出
输入:
x: 一个二维矩阵,要求是实数类型或逻辑类型的数值数组。
输出:
y: 一个结构体,包含以下字段:
`y.code`: 霍夫曼编码后的值,以 `uint16` 向量形式存储。
`y.min`: 输入矩阵 `x` 的最小值加上 32768,作为偏移量,使其适合存储在 `uint16` 中。
`y.size`: 输入矩阵的大小。
`y.hist`: 输入数据的直方图。
详细流程
1. 输入验证:
if ~ismatrix(x) || ~isreal(x) || (~isnumeric(x) && ~islogical(x))
error('X must be a 2-D real numeric or logical matrix.');
end检查输入 `x` 是否为二维矩阵,且必须为实数且为数值或逻辑类型。如果不符合条件则抛出错误。
2. 存储矩阵大小:
y.size = uint32(size(x));获取输入矩阵 `x` 的大小并以 `uint32` 类型存储。
3. 查找输入范围:
x = round(double(x));
xmin = min(x(:));
xmax = max(x(:));
pmin = double(int16(xmin));
pmin = uint16(pmin + 32768);
y.min = pmin; 将矩阵 `x` 转换为 `double` 类型并四舍五入,然后找到其最小值 `xmin` 和最大值 `xmax`。
将最小值转换为 `int16` 类型,再加上 32768 以确保可存储在 `uint16` 中,并将结果存入 `y.min`。
4. 计算直方图:
x = x(:)';
h = histc(x, xmin:xmax);
if max(h) > 65535
h = 65535 * h / max(h);
end
h = uint16(h);
y.hist = h;
将矩阵 `x` 转换为行向量,并使用 `histc` 函数计算在 `xmin` 到 `xmax` 范围内的直方图 `h`。
如果直方图的最大值超过 65535(`uint16` 的最大值),则进行归一化处理。
最后,将直方图转换为 `uint16` 类型并存储在 `y.hist` 中。
5. 霍夫曼编码:
map = huffman(double(h)); % Make Huffman code map
hx = map(x(:) - xmin + 1); % Map image
hx = char(hx)'; % Convert to char array
hx = hx(:)'; % Reshape to a row vector
hx(hx == ' ') = [ ]; % Remove blanks
``` 调用 `huffman` 函数生成霍夫曼编码映射表 `map`。`map` 是一个数组,其元素表示每个符号的霍夫曼编码。
将输入矩阵 `x` 的每个值映射到其霍夫曼编码,`hx` 将存储这些编码。
将 `hx` 转换为字符数组,并去除其中的空格字符。
6. 转换为二进制形式:
ysize = ceil(length(hx) / 16); % Compute encoded size
hx16 = repmat('0', 1, ysize * 16); % Pre-allocate modulo-16 vector
hx16(1:length(hx)) = hx; % Make hx modulo-16 in length
hx16 = reshape(hx16, 16, ysize); % Reshape to 16-character words
hx16 = hx16' - '0'; % Convert binary string to decimal计算编码后的大小 `ysize`,以便按 16 位分组。
创建一个全为 '0' 的字符串 `hx16`,并用霍夫曼编码填充它。
将 `hx16` 重塑为 16 行的矩阵,并将其转换为数字。
7. 最终编码:
twos = pow2(15 : - 1 : 0);
y.code = uint16(sum(hx16 .* twos(ones(ysize ,1), :), 2))';
- 创建一个表示 2 的幂的数组 `twos`,用于将每个 16 位二进制数转换为十进制数。
- 通过逐行求和,将每个 16 位二进制数转换为 `uint16` 型的编码值并存储到 `y.code` 中。
总结
整个函数通过以下过程完成霍夫曼编码:
1. 验证输入并获取矩阵大小。
2. 计算输入数据的极值及其直方图。
3. 利用霍夫曼算法生成编码映射,并将输入数据编码为二进制形式。
4. 最终将编码结果以结构化的方式返回,便于后续解码和使用。
这个方法特别适合用于图像压缩和其他需要减少数据存储的应用场景。
5.2 香农—范诺编码
同样以哈夫曼的那个比喻为例, 你和朋友们在一个派对上,讨论多种话题。为了在聊天时更加高效,你们决定给不同的话题分配代号。不同的话题出现的频率不同,有些话题常常被提及(高频),有些则很少被讨论(低频)。
香农—范诺编码的比喻
-
观察与收集频率: 在派对上,你们开始记录每个话题被提及的次数。比如:
- “天气”(出现频率高)
- “电影”(出现频率适中)
- “运动”(较少提及)
- “外星人”(几乎不提及)
-
按频率排序: 你们将这些话题按出现频率排序,从高到低。常聊的话题会排在前面,而不常聊的话题则排在后面。
-
分组与代号分配:
- 你们决定将这些话题分为两组,努力让每组的频率尽量接近。比如:
- 组 1:天气、电影
- 组 2:运动、外星人
- 对于组 1(频率高的话题),你们分配短代号,例如:
- 天气:A
- 电影:B
- 对于组 2(频率低的话题),你们可能分配较长的代号,例如:
- 运动:C
- 外星人:D
- 你们决定将这些话题分为两组,努力让每组的频率尽量接近。比如:
-
总结: 最终,你们的代号系统易于使用,频繁被提及的话题使用更短的代号,从而提高了沟通效率。
回顾哈夫曼编码的比喻:
-
观察与收集频率: 同样地,你们记录每个话题的出现频率。
-
建立优先队列: 与香农—范诺不同的是,哈夫曼编码更注重构建一个编码树。你们会考虑将频率最低的两个话题合并。例如,假设“运动”和“外星人”的频率最低,你们将这两个话题看作一个组合。
-
构建树结构:
- 首先,合并“运动”和“外星人”,形成一个新的节点。这时,你们会把这个新的节点分配为一个代号,比如“C1”。
- 然后,将这个新节点与“天气”和“电影”进一步合并,形成一个更大的树结构。最终,生成的编码可能如下:
- 天气:0
- 电影:10
- 运动:110
- 外星人:111
-
总结: 哈夫曼编码通过构建树形结构,确保每个话题的代号长度与其频率成反比,保证了编码的最优性。也就是说,出现频率高的话题获得更短的代号,而频率低的话题则获得相对较长的代号。
香农—范诺编码的详细过程:
1. 统计字符频率
首先,需要统计每个字符在数据中的出现频率。比如,同样还是之前的例子:
| 字符 | 频率 |
|---|---|
| A | 5 |
| B | 9 |
| C | 12 |
| D | 13 |
| E | 16 |
| F | 45 |
2. 计算概率
接下来,我们计算每个字符的概率 pi,即字符频率占总频率的比例。在上面的例子中,总频率为 5+9+12+13+16+45=100。
| 字符 | 频率 | 概率 pi |
|---|---|---|
| A | 5 | 0.05 |
| B | 9 | 0.09 |
| C | 12 | 0.12 |
| D | 13 | 0.13 |
| E | 16 | 0.16 |
| F | 45 | 0.45 |
3. 按概率排序
将字符根据它们的概率从高到低排序,结果如下:
- F (0.45)
- E (0.16)
- D (0.13)
- C (0.12)
- B (0.09)
- A (0.05)
4. 递归划分
接下来,我们需要将这些字符划分成两组,使得两个组的总概率尽可能接近。这个过程要递归进行。
-
初始分组:
- 高频字符:F (0.45)
- 低频字符:E, D, C, B, A (0.16 + 0.13 + 0.12 + 0.09 + 0.05 = 0.55)
-
继续分组(对低频组):
- E (0.16) 和 D, C, B, A (0.13 + 0.12 + 0.09 + 0.05 = 0.39)
- 这里我们可以把 E 和 D 放在一组,C、B、A 放在另一组。
进一步细分:
- 在 E 和 D 中,因为 E 的概率更高,所以可以按以下方式分组:
- 组 1:E (0.16)
- 组 2:D, C, B, A (0.13 + 0.12 + 0.09 + 0.05)
这样将继续进行,直到每个组中只剩一个字符。
5. 分配编码
分配编码时,从根节点开始向下走,左边分配“0”,右边分配“1”。最终得到的编码如下:
- F: 0
- E: 10
- D: 110
- C: 1110
- B: 11110
- A: 11111
数学公式
香农—范诺编码的核心思想和公式可以用以下公式来描述字符的编码长度(li):
- li:字符 ii 的编码长度。
- pi:字符 ii 的概率。
这个公式的意思是,字符的编码长度与它的概率 pi相关。概率越低,编码长度越长;概率越高,编码长度越短。
例子计算
对于上述字符,使用公式计算它们的编码长度:
- A: lA=⌈−log2(0.05)⌉≈5
- B: lB=⌈−log2(0.09)⌉≈4
- C: lC=⌈−log2(0.12)⌉≈4
- D: lD=⌈−log2(0.13)⌉≈4
- E: lE=⌈−log2(0.16)⌉≈3
- F: lF=⌈−log2(0.45)⌉≈2
香农—范诺编码与哈夫曼编码的核心思想区别
1. 构造方式
-
哈夫曼编码:
- 使用贪心算法,通过构建最优二叉树来生成编码。它从频率最低的字符开始合并,逐步构建树,确保每次合并都选择当前频率最低的两个节点。
- 编码长度是动态计算的,基于树的结构,确保编码是最优的。
-
香农—范诺编码:
- 使用概率排序和递归划分的方式来生成编码。它通过将字符分成两组,使每组的总概率尽量接近来构造编码。虽然目标是获得有效的编码,但在某些情况下可能没有达到最优。
- 编码长度是基于概率的计算,不一定是完全最优的。
2. 编码长度的最优性
-
哈夫曼编码:
- 在任何情况下都是生成最优编码的,确保最短的平均码长。
-
香农—范诺编码:
- 可能生成的编码不是最优的,特别是在字符分布不均匀时,可能会产生较长的编码。
3. 计算复杂度
-
哈夫曼编码:
- 在构造哈夫曼树的过程中,需要维护优先队列,复杂度通常为 O(nlogn)。
-
香农—范诺编码:
- 主要依赖于排序和递归分组,复杂度通常为 O(nlogn),但由于不需要维护复杂的树结构,可能在实现上相对简单。
提问:
在实时流媒体传输系统中,当传输带宽动态变化且需实时调整编码效率时,为何哈夫曼编码可能面临动态更新困难,而香农—范诺编码却能通过概率分布的快速重组实现更灵活的自适应压缩?
家用智能监控摄像头在存储动态图像时,为何普遍采用哈夫曼编码而非香农—范诺编码来实现压缩?请结合两种算法对运动模糊区域(低频信息)和物体边缘(高频信息)的编码效率差异,解释其在减少存储空间占用方面的实际优势。
深度解析方向:
- 图像特征匹配:哈夫曼树如何通过动态调整编码长度,更高效压缩监控画面中频繁出现的静态背景(如墙壁、家具)与突发动态事件(如人物移动)的混合数据流;
- 硬件加速瓶颈:摄像头芯片的有限计算能力下,哈夫曼编码器如何利用固定码表预生成技术降低实时编码延迟;
- 误码容错需求:家庭WiFi网络不稳定时,香农—范诺编码的递归划分特性为何可能加剧数据包错误传播;
- 生活场景延伸:分析智能门铃、运动相机等设备在夜间模式(高噪声图像)下,哈夫曼编码如何通过权重分配优化减少红外噪点的存储冗余。
此问题将压缩算法选择与安防监控、智能家居等生活场景结合,揭示算法特性如何影响设备续航、存储成本等消费者敏感指标。
六、算法编码
例子:
下面以符号集 {a, b, c, d} 及其概率为例进行详细分析算法编码的过程。
假设我们有以下符号和对应的概率:
| 符号 | 概率 |
|---|---|
| a | 0.2 |
| b | 0.1 |
| c | 0.5 |
| d | 0.2 |
1. 初始化
初始区间:[0, 1)
StartB (开始位置) = 0
EndB (结束位置) = 1
L (区间长度) = EndB - StartB = 1
2. 编码过程详解
(1)编码第一个符号 a
概率区间:
a 的概率是 0.2,因此它在区间 [0, 1) 中占据的区间是 [0, 0.2)。
计算新区间:
新区间为 [0, 0.2)。
更新区间的长度:
(2)编码第二个符号 c
概率区间:
c 的概率是 0.5。由于我们现在的区间是 [0, 0.2),c 的实际占比在这个区间内需要重新计算。
在区间 [0, 0.2) 中,c 的占比为 [0.2, 0.7),具体计算如下:
LeftC = a的结束位置 = 0.2
RightC = a的结束位置 + b的结束位置 = 0.2 + 0.1 = 0.3
因此,c 的区间在当前区间中的位置为 [LeftC, RightC] = [0.2, 0.7)。
计算新区间:
新区间为 [0.04, 0.14)。
更新区间的长度:
(3)编码第三个符号 d
概率区间:
d 的概率是 0.2。在当前区间 [0.04, 0.14),我们需要计算 d 的位置。
d 的占比为 [0.7, 0.9) 在整个概率区间中。
计算新区间:
新区间为 [0.11, 0.13)。
更新区间的长度:
L = EndN - StartN = 0.13 - 0.11 = 0.02
最终编码值
在经过上述步骤后,我们可以选择一个代表性的值来进行编码。假设我们选择的是区间的中间值:
中间值 =
3. 解码过程
解码步骤
1. 根据编码值找到区间:
假设我们最后得到的编码值为 0.12。我们需要找到这个值落在哪个区间。
0.12 在区间 [0.11, 0.13) 中,因此第一个符号是 d。
2. 更新区间:
减去 d 的起始位置,并缩放:
因此,接下来的解码符号会是:
通过类似的方式继续解码下一个符号。
matlab代码示例:
% 定义符号及其概率
symbols = {'a', 'b', 'c', 'd'};
probabilities = [0.2, 0.1, 0.5, 0.2];
% 计算符号的累积概率
cumulative_prob = cumsum([0, probabilities]);
% 初始化
StartB = 0; % 起始位置
EndB = 1; % 结束位置
L = EndB - StartB; % 区间长度
encoded_values = []; % 用于存储编码过程中的值
% 编码过程
message = {'a', 'c', 'd', 'a', 'c'}; % 需要编码的消息
for i = 1:length(message)
symbol = message{i};
symbol_index = find(strcmp(symbols, symbol)); % 找到符号的索引
LeftC = cumulative_prob(symbol_index); % 左端概率
RightC = cumulative_prob(symbol_index + 1); % 右端概率
% 计算新的区间
StartN = StartB + L * LeftC;
EndN = StartB + L * RightC;
% 更新区间
StartB = StartN;
EndB = EndN;
L = EndB - StartB;
% 记录编码的开始和结束位置
encoded_values = [encoded_values; StartB, EndB];
end
% 选择一个编码值(选择最后区间的中间值)
final_encoded_value = (StartB + EndB) / 2;
% 解码过程
decoded_message = {};
current_value = final_encoded_value;
for i = 1:length(message)
for j = 1:length(symbols)
LeftC = cumulative_prob(j);
RightC = cumulative_prob(j + 1);
% 计算当前区间
StartN = StartB + L * LeftC;
EndN = StartB + L * RightC;
% 如果当前值落在这个区间中
if current_value >= StartN && current_value < EndN
decoded_message{end+1} = symbols{j}; % 记录符号
% 更新区间
StartB = StartN;
EndB = EndN;
L = EndB - StartB;
break;
end
end
end
% 输出结果
disp('编码值:');
disp(final_encoded_value);
disp('解码得到的消息:');
disp(decoded_message);
% 可视化编码过程
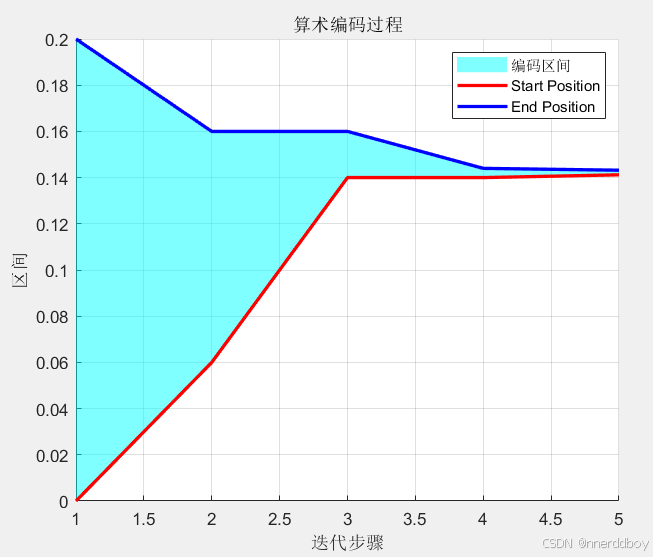
figure;
hold on;
title('算术编码过程');
xlabel('迭代步骤');
ylabel('区间');
x = 1:length(encoded_values);
y1 = encoded_values(:, 1);
y2 = encoded_values(:, 2);
fill([x, fliplr(x)], [y1', fliplr(y2')], 'c', 'FaceAlpha', 0.5, 'EdgeColor', 'none');
plot(x, y1, 'r', 'LineWidth', 2); % 起始位置线
plot(x, y2, 'b', 'LineWidth', 2); % 结束位置线
legend('编码区间', 'Start Position', 'End Position');
grid on;
hold off;
七、预测编码
一、预测编码的基本概念
预测编码的基本思想是利用前面的样本(例如像素值)来预测当前样本的值。由于信号数据(如图像或音频)通常具有较强的时间或空间相关性,因此预测可以有效地减少数据量。
相关性:
在图像处理中,相邻像素的灰度值往往是相似的,因此可以利用之前几个已知像素值对当前像素值进行预测。通过预测相邻像素的值,编码器只需编码当前值与预测值之间的差异(即预测误差),从而节省存储空间。
同样以最初的比喻,你和一群朋友在一个派对上聊天,讨论各种话题。你们之间的交流非常自然,但你们发现,有些话题频繁被提及,比如“天气”,而另一些话题则几乎不被讨论,比如“外星人”。你们开始思考如何提高聊天的效率。
1. 话题的相关性
在派对上,许多话题之间是有联系的。比如当你们谈论“天气”时,可能会顺势提到“气候变化”或“季节”。这种相关性意味着你们可以通过之前的讨论来预测接下来的话题。
预测的思想:
- 假设你们刚刚讨论过“天气”,当有人开始说话时,你们可以预测下一个话题可能还是跟“天气”有关的,因此可以直接跳到相关的讨论,而不是从头开始。
2. 预测的过程
在预测编码中,当前时刻的值(话题)可以通过之前的几个值来预测。例如,假设你们正在讨论“天气”,接下来可能会提到“气候变化”:
- 当前话题 xn:天气
- 预测话题
:气候变化(根据之前的聊天内容推测)
- 误差 en:实际提到的话题和预测话题之间的差别
如果你们的预计是准确的,聊天会进行得更加顺畅,这样就能减少不必要的重复和冗余。
3. 编码新信息
在这个过程中,你们并不需要每次都重复地说“天气”这个词。相反,聊天时你们只需传达新的信息——即“天气”的变化或者新的见解。这个新信息就是当前话题和预测话题之间的差异:
- 新信息:如果说的是“气候变化”,而不是“天气”,那么你们只需说出这点不同的信息(例如:天气变化如何影响气候)。
在这样的情况下,你们会把“气候变化”与“天气”的关系看作一种“预测误差”,并将其量化。这种处理减少了信息量,因为你们不需要重复已经讨论过的话题。
4. 量化与传输
如果你们的讨论中提到的天气问题是一个简单的概念,那么可以用简单的代号来表示,比如:
- “天气” → A
- “气候变化” → A1
- “季节” → A2
相对于频繁提及的“天气”,较少提及的“外星人”可能使用更复杂的代号,甚至需要完整的描述。如果你们每次讨论这些话题时都能用较短的代号替换掉长篇的描述,就能提高交流的效率。
二、差分脉冲编码调制(DPCM)
在DPCM中,你们的聊天可以被看作一个时间序列,你们每次讨论的内容都是一个“样本”。假设你们正在讨论“天气”,并且已经谈论了“气候变化”,然后又提到“降雨”,此时你们的聊天记录可以这样进行:
- 当前话题 xn:降雨
- 预测话题
- 误差 en=xn−
在DPCM中,你们只需记录这个差异(即“误差”),而不是整个“降雨”的话题。这意味着,如果你们的预测准确,聊天会更加高效,因为只需传达新信息。
量化:假如你们用代号来代表这些新信息,比如:
- “降雨” → A
- 预测的“气候变化” → A1
那么你们实际上只需传达的就是“降雨”相较于“气候变化”的新信息。这种方式减少了信息的冗余,使得交流更加迅速。
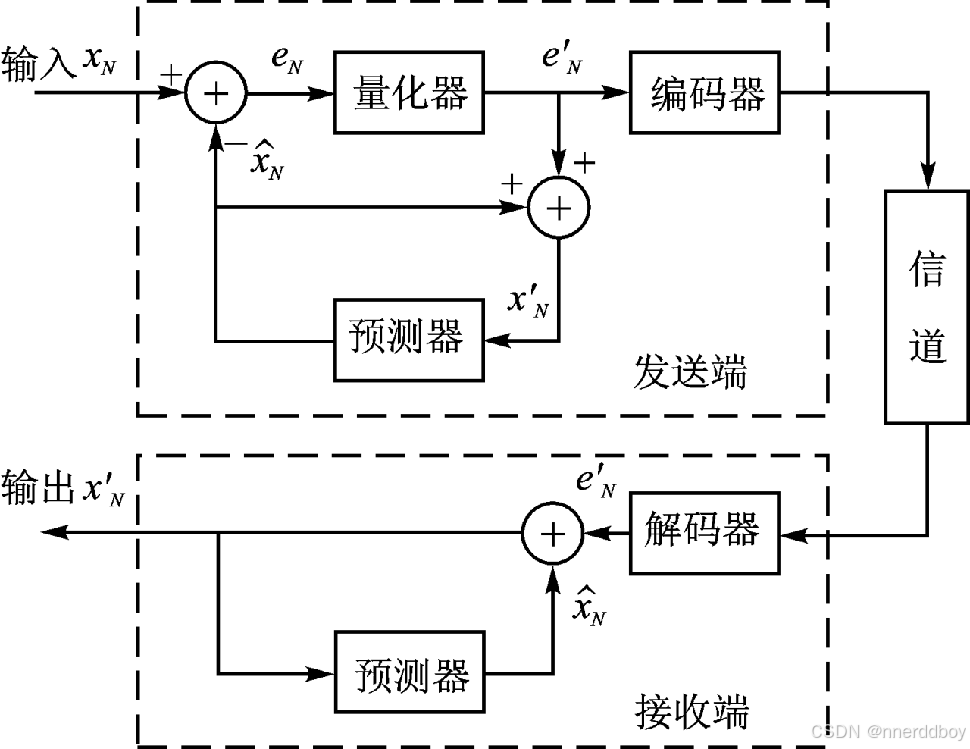
1. DPCM的基本原理
在DPCM中,每个像素的当前值 xn由先前像素值的线性组合来预测。设定以下变量:
- xn:当前时刻的像素值
- en=xn−
在DPCM中,主要编码的对象是预测误差 en,而不是原始信号 xn。预测过程通常可以表示为:
这里 a1,a2,…,ak是预测系数,表示各个前向像素对当前像素的影响。
2. 量化与编码
误差信号 en 在被量化后,生成量化误差,并将其编码后进行传输。量化步骤可能引入一些误差,但这是可接受的,因为它大幅减少了数据量。
=Q(en)
其中 Q 是量化函数。接收端的复原过程如下:
在DPCM中,主要的数学公式如下:
-
预测公式:
-
误差信号:
-
量化误差:
该Q(e)一般为:
将连续幅度信号(如模拟信号)转换为离散幅度值。这一过程涉及将信号的幅度范围划分为若干个区间,然后将每个区间的值映射到一个特定的离散值。
matlab代码如下:
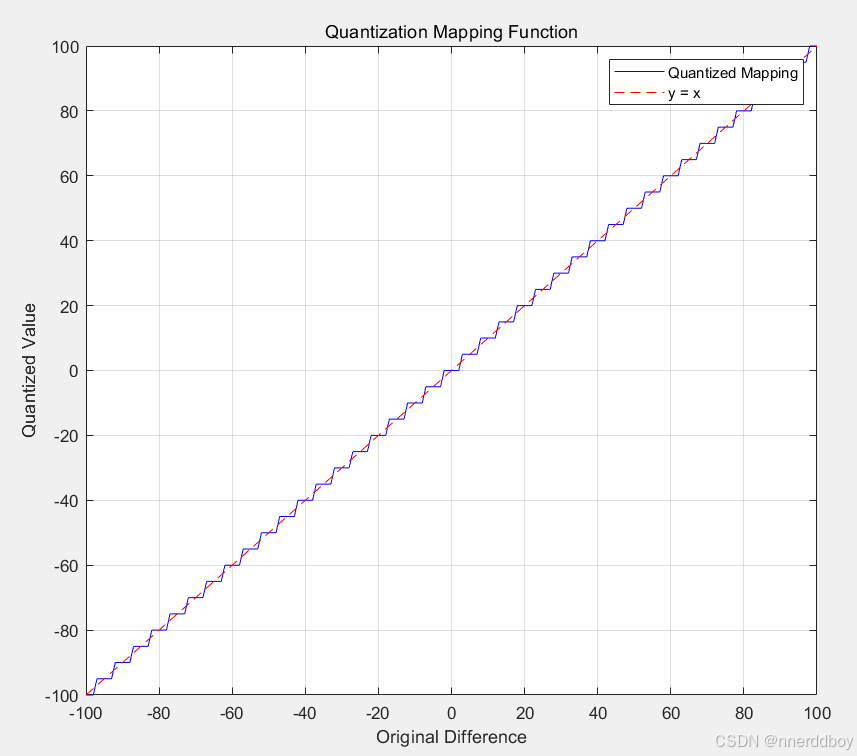
% 定义量化步长
step_size = 5;
% 定义差分值范围
x = -100:1:100; % 可以根据需要调整范围
% 计算量化后的值
quantizedValues = round(x / step_size) * step_size;
% 绘制映射关系
figure;
plot(x, quantizedValues, 'b-'); % 绘制量化函数
hold on;
plot(x, x, 'r--'); % 绘制 y=x 线,以便比较
xlabel('Original Difference');
ylabel('Quantized Value');
title('Quantization Mapping Function');
legend('Quantized Mapping', 'y = x');
grid on;
hold off;
这个函数用matlab可视化为:
4.复原信号:
5.误差分析:实际输入信号与复原信号之间的误差为:
示例
假设我们有一组像素值:[100, 102, 101, 104, 103]。我们使用简单的预测方法(例如只使用前一个像素来预测当前像素)。
-
初始化:
- 第一个像素 x1=100,没有前一个像素可用,所以直接编码。
,预测误差
。
-
第二个像素:
- x2=102
- 预测
- 误差
-
第三个像素:
- x3=101
- 预测
- 误差
-
第四个像素:
- x4=104
- 预测
- 误差
-
第五个像素:
- x5=103
- 预测
- 误差
matlab示例代码如下:
% 读取图像并转换为灰度图像
originalImage = imread('C:\Users\Lenovo\OneDrive\桌面\医学图像处理相关\代码\class3\Barbara.bmp'); % 替换为你的图像文件路径
if size(originalImage, 3) == 3
originalImage = rgb2gray(originalImage); % 转换为灰度图像
end
originalImage = double(originalImage); % 转换为 double 类型以便处理
% DPCM 编码参数
step_size = 10; % 量化步长
height = size(originalImage, 1);
width = size(originalImage, 2);
dpcmImage = zeros(height, width); % 存储 DPCM 结果
quantizedDifferences = zeros(height, width); % 存储量化后的差分值
% DPCM 编码过程
for i = 1:height
for j = 1:width
if j == 1
% 第一列没有前像素,直接赋值
dpcmImage(i, j) = originalImage(i, j);
else
% 计算差分
difference = originalImage(i, j) - originalImage(i, j-1);
% 量化
quantizedValue = round(difference / step_size) * step_size;
quantizedDifferences(i, j) = quantizedValue; % 存储量化结果
% 生成 DPCM 图像
dpcmImage(i, j) = dpcmImage(i, j-1) + quantizedValue; % 恢复图像
end
end
end
% 可视化对比
figure;
% 原始图像
subplot(1, 2, 1);
imshow(uint8(originalImage));
title('Original Image');
% DPCM 压缩后的图像
subplot(1, 2, 2);
imshow(uint8(dpcmImage));
title('DPCM Compressed Image');
% 打印量化差分值以便观察
disp('Quantized Differences:');
disp(quantizedDifferences);

如果还是不理解DPCM的话,我们可以回到一维信号的DPCM试着理解一下该方法的流程:
-
生成原始信号:
- 使用一个正弦信号加上随机噪声生成原始信号。
- 采样频率设置为
fs = 100Hz。
-
DPCM参数设置:
- 初始化预测信号、差分信号和量化信号的数组。
- 设置量化步长
step_size,用于量化差分信号。
-
DPCM过程:
- 使用一个 for 循环从第二个样本开始进行 DPCM 处理。
- 预测:使用前一个样本来预测当前样本的值。predicted_signal(n) = original_signal(n-1); % 线性预测(这里简单使用前一个样本)
- 计算差分:通过减去预测值来得到当前样本与预测样本之间的差。
- 量化:差分值被量化为离散值。
- 解码:重建信号是通过将量化值加回预测值。
代码:
% 清空环境
clear; clc; close all;
% 1. 生成原始信号
fs = 100; % 采样频率
t = 0:1/fs:1; % 时间向量
original_signal = sin(2*pi*5*t) + 0.5*randn(size(t)); % 原始信号(正弦信号 + 噪声)
% 2. DPCM参数设置
N = length(original_signal); % 信号长度
predicted_signal = zeros(size(original_signal)); % 初始化预测信号
difference_signal = zeros(size(original_signal)); % 初始化差分信号
quantized_signal = zeros(size(original_signal)); % 初始化量化信号
reconstructed_signal = zeros(size(original_signal)); % 初始化重建信号
step_size = 0.1; % 量化步长
% 3. DPCM过程
for n = 2:N
% 预测步骤
predicted_signal(n) = original_signal(n-1); % 线性预测(这里简单使用前一个样本)
% 计算差分
difference_signal(n) = original_signal(n) - predicted_signal(n);
% 量化
quantized_signal(n) = round(difference_signal(n) / step_size) * step_size; % 量化
% 解码(重建信号)
reconstructed_signal(n) = predicted_signal(n) + quantized_signal(n);
end
% 4. 可视化
figure;
subplot(5,1,1);
plot(t, original_signal, 'b');
title('原始信号');
xlabel('时间 (s)');
ylabel('幅度');
grid on;
subplot(5,1,2);
plot(t, predicted_signal, 'r');
title('预测信号');
xlabel('时间 (s)');
ylabel('幅度');
grid on;
subplot(5,1,3);
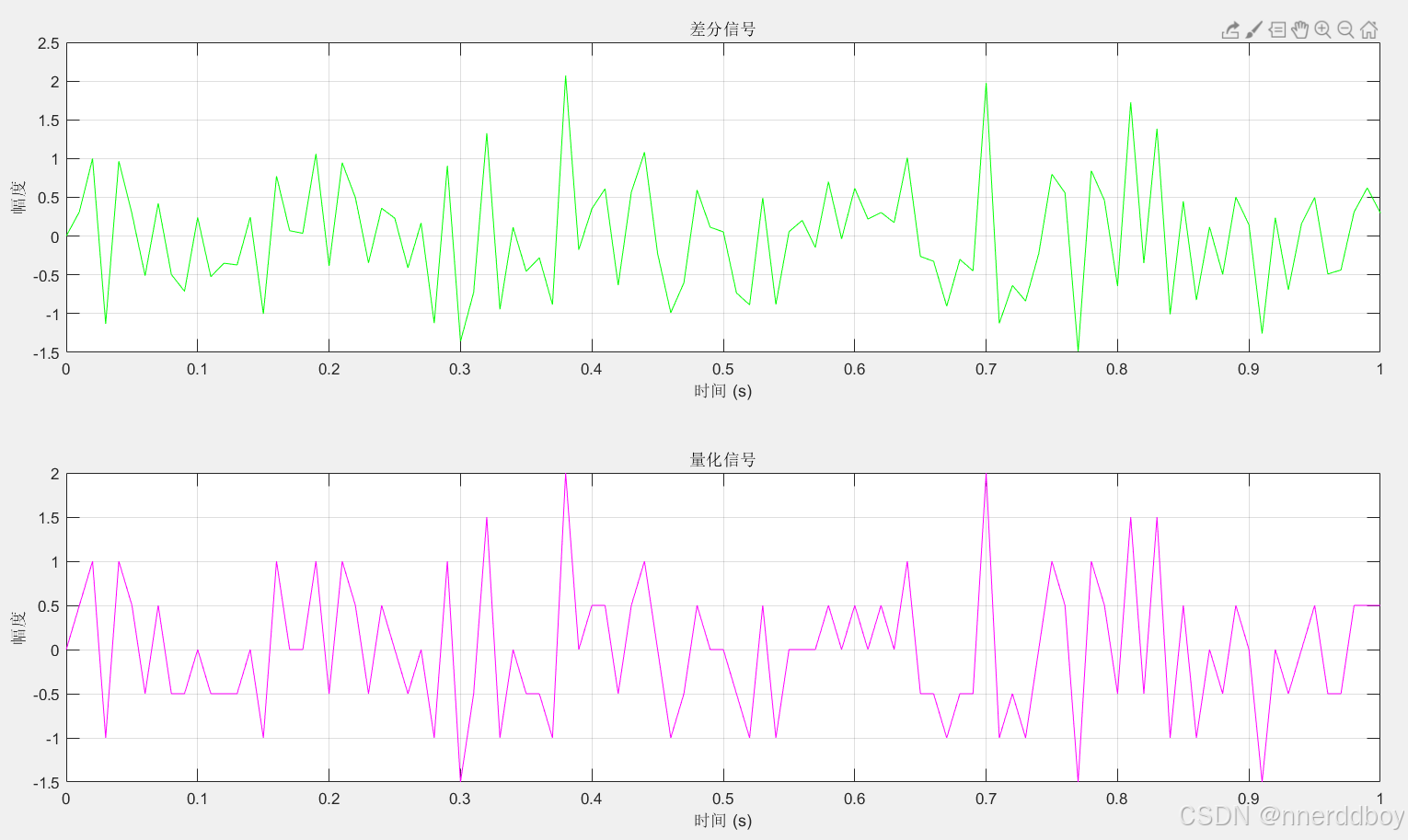
plot(t, difference_signal, 'g');
title('差分信号');
xlabel('时间 (s)');
ylabel('幅度');
grid on;
subplot(5,1,4);
plot(t, quantized_signal, 'm');
title('量化信号');
xlabel('时间 (s)');
ylabel('幅度');
grid on;
subplot(5,1,5);
plot(t, reconstructed_signal, 'k');
title('重建信号');
xlabel('时间 (s)');
ylabel('幅度');
grid on;
% 5. 计算和显示信号的均方误差
mse = mean((original_signal - reconstructed_signal).^2);
disp(['均方误差: ', num2str(mse)]);
结果:
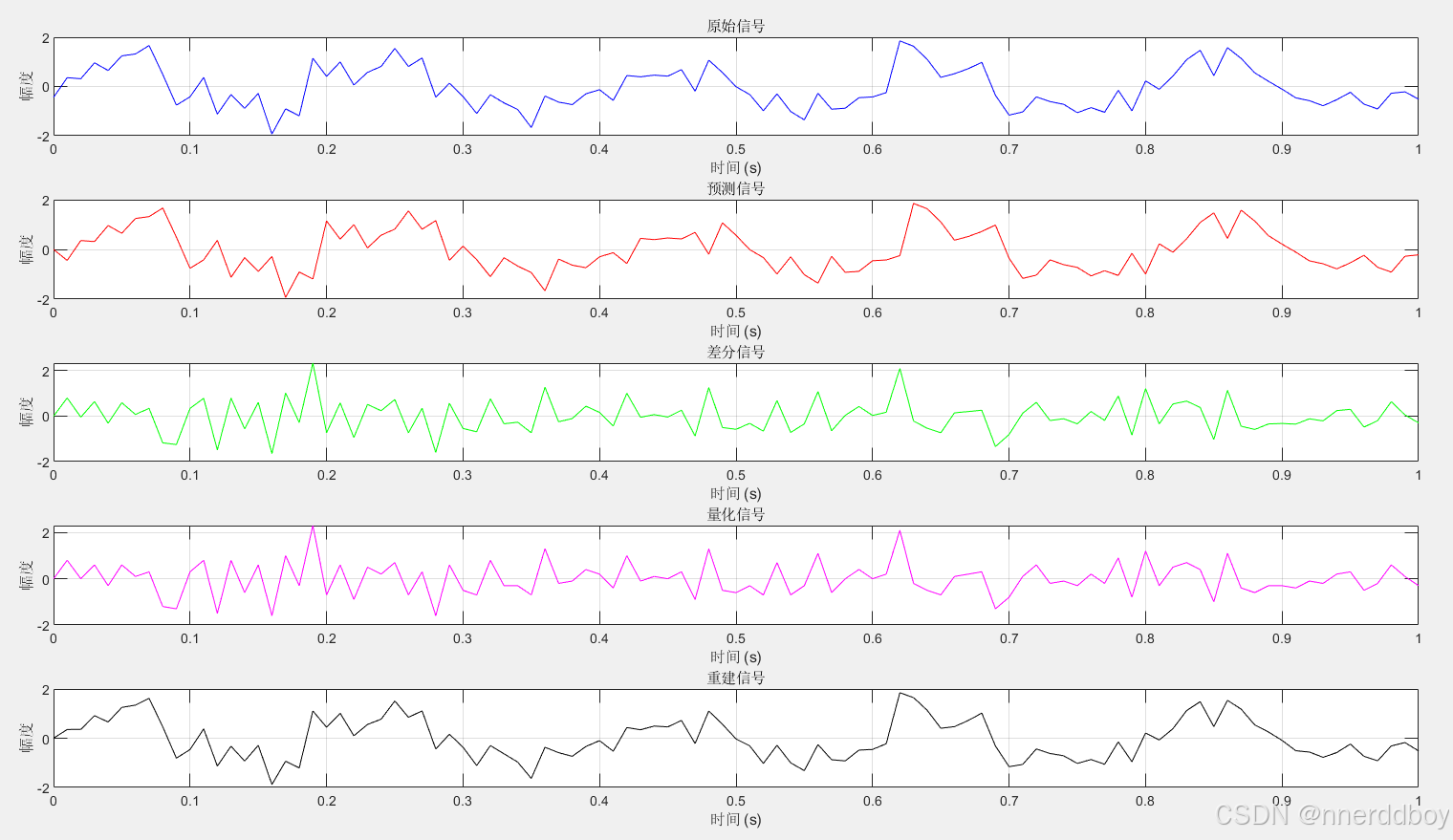
量化前后的结果对比:
step_size = 0.1 均方误差 (量化前后): 0.00093103
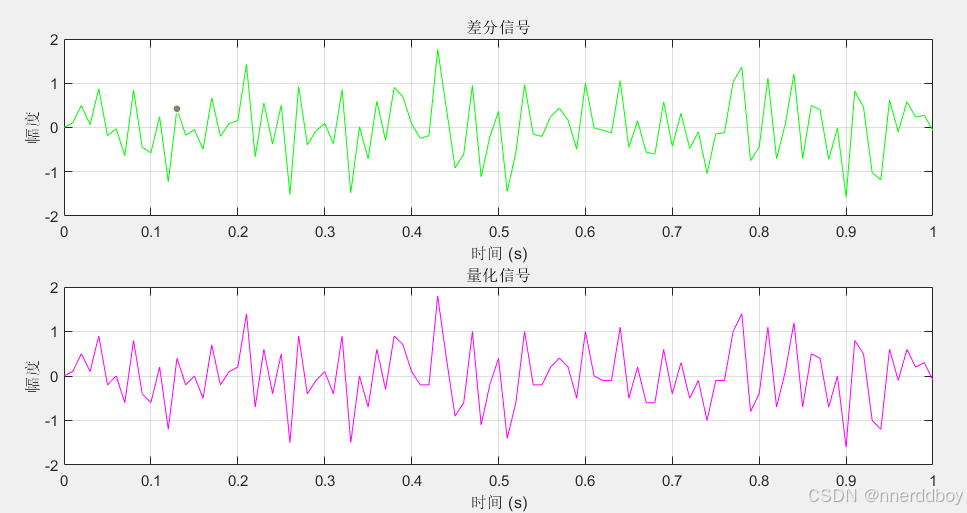
step_size = 0.5 均方误差 (量化前后): 0.019801
三、自适应预测编码
假设在这个派对上,你们发现聊天的主题和内容会随着时间而变化,朋友们的兴趣和注意力也会有所不同。因此,你们决定在聊天过程中调整自己的预测模型,使其更加贴合当前的讨论。
1. 自适应预测
在自适应预测编码中,你们不仅仅依赖于之前的话题来预测当前的讨论,而且会根据最近的讨论内容不断调整你们的预测策略。例如:
- 当第一次聊“天气”时,你们可能把预测基于“气候变化”。
- 随着讨论的深入,可能会转而关注“降雨”或“季节变化”,这时你们的预测模型会适应这种变化。
在这种情况下,你们可能会使用更复杂的模型来预测当前讨论的内容,以适应派对氛围的变化。这就类似于使用动态的预测系数来更好地估计当前输入信号。
2. 量化与更新
在自适应预测编码中,随着时间的推移,你们的聊天记录中会不断更新预测的信息。例如:
- 如果讨论开始转向“外星人”,你们可能会为这个话题重新定义预测模型,以便能够更好地适应当前的聊天环境。
你们可能在聊天时发现,当朋友们越来越多地提到“外星人”时,你们的预测模型需要调整,这样你们可以更好地捕捉到新话题的变化。
与DPCM的区别与联系:
- DPCM:是基于固定预测模型的编码方法,其预测模型不随时间变化,依赖于之前的几个固定样本来进行预测。在聊天中,DPCM就好比你们一直使用相同的方法来预测下一个话题,虽然有时会很有效,但在话题快速变化的情况下可能会不够灵活。
- 自适应预测编码:则通过不断调整预测模型来适应当前讨论内容的变化。在派对聊天中,自适应预测编码就像是你们在不断调整话题预测的方式,能够更灵活地跟上朋友们的兴趣和讨论动态。
- 自适应编码的matlab示例:
-
% 清空环境 clear; clc; close all; % 1. 读取图像 original_image = imread('cameraman.tif'); % 使用 MATLAB 自带的测试图像 original_image = double(original_image); % 转换为 double 类型以便处理 % 2. 图像参数设置 [N, M] = size(original_image); % 图像的大小 predicted_image = zeros(N, M); % 初始化预测图像 difference_image = zeros(N, M); % 初始化差分图像 quantized_image = zeros(N, M); % 初始化量化图像 step_size = 10; % 初始量化步长 alpha = 0.1; % 自适应步长的调整因子 step_sizes = zeros(N, M); % 存储每个像素的步长 % 3. 自适应预测编码过程 for i = 1:N for j = 1:M % 预测步骤:考虑周围像素的非线性关系 if i > 1 && j > 1 % 使用4个邻域像素进行非线性预测 predicted_value = (original_image(i-1, j) + original_image(i, j-1)) / 2; elseif i > 1 predicted_value = original_image(i-1, j); % 上方像素 elseif j > 1 predicted_value = original_image(i, j-1); % 左侧像素 else predicted_value = 0; % 第一个像素没有预测 end predicted_image(i, j) = predicted_value; % 计算差分 difference_image(i, j) = original_image(i, j) - predicted_image(i, j); % 量化 quantized_image(i, j) = round(difference_image(i, j) / step_size) * step_size; % 量化 % 自适应步长更新 step_size = step_size + alpha * abs(difference_image(i, j)); % 更新步长 step_sizes(i, j) = step_size; % 记录当前步长 end end % 4. 可视化每一步的过程 figure; % 原始图像 subplot(3, 2, 1); imshow(uint8(original_image)); % 显示原始图像 title('原始图像'); axis on; % 预测图像 subplot(3, 2, 2); imshow(uint8(predicted_image)); % 显示预测图像 title('预测图像'); axis on; % 差分图像 subplot(3, 2, 3); imshow(uint8(difference_image + 128)); % 显示差分图像(偏移以显示负值) title('差分图像'); axis on; % 量化图像 subplot(3, 2, 4); imshow(uint8(quantized_image + 128)); % 显示量化图像(偏移以显示负值) title('量化图像'); axis on; % 自适应步长变化 subplot(3, 2, 5); imagesc(step_sizes); % 使用 imagesc 显示步长图 colorbar; % 显示颜色条 title('图像中各像素的自适应步长'); xlabel('列索引'); ylabel('行索引'); axis on; % 计算和显示图像的均方误差(量化前后的误差) mse = mean((difference_image(:) - quantized_image(:)).^2); disp(['均方误差 (量化前后): ', num2str(mse)]); 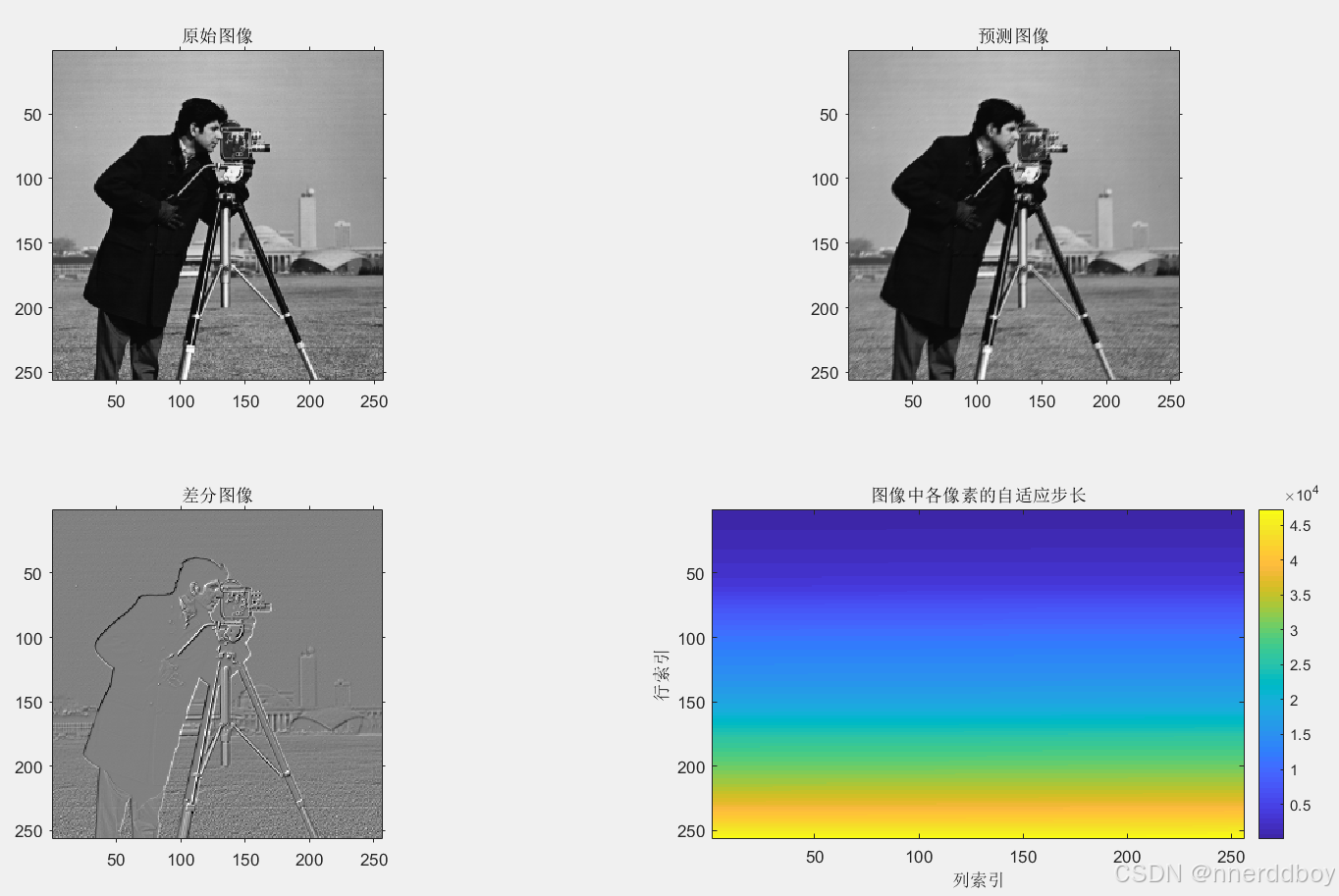

公式:中的
是我们要预测的第 N 个像素的亮度值。
x1和 x4 是与当前像素相关的前几个像素的亮度值。例如,x1可能是左边的像素,而 x4 可能是上面的像素。
a1和 a4是权重,表示我们在预测中应该给这些前像素多大影响。在这个例子中,a1= 0.75,a4 = 0.25,意味着左边的像素对当前像素的预测影响更大。
在预测中,还引入了一个叫做 K的自适应参数:
是前一个像素的预测误差(即实际值与预测值的差)。
是最小化的预测误差,
是最大化的预测误差。
根据的大小,K会调整:
如果预测误差大于最大阈值 ,则 K增加(提升预测的灵敏度)。
如果预测误差小于最小阈值 ,则 K减小(降低预测的灵敏度)。
如果误差在两者之间,K保持不变。
示例过程:
1. 获取像素值:
假设我们正在处理图像中的某个像素。我们查看左边的像素x1上面的像素x4。
假设 x1 = 100 和 x4 = 120。
2. 计算预测:
使用权重计算预测:
先计算内部部分:
假设此时 K = 1.0,则:
3. 计算误差:
假设实际的像素值 ,那么预测误差为:
4. 调整自适应参数 K:
如果误差 大于某个阈值(例如
),那么我们将 K 调整为1.125。
如果误差在允许范围内(如大于 但小于
),则保持 K = 1.0。
如果误差非常小(等于 ),那么 K 变为 0.875。
八、变换编码
变换编码其实就是把图像或信号从一种表现形式(空间域)转换为另一种表现形式(变换域),以便更有效地存储和处理这些数据。我们用派对上的聊天来比喻这个过程。
又又又是之前的例子,想象你在一个派对上:
- 你和朋友们在聊天,聊天的主题和内容会随着时间而变化。
- 一开始,你们可能在聊“天气”,然后转到“外星人”或者“电影”。
1. 空间域
聊天初始:
- 一开始,聊天的话题是“天气”。大家各自分享自己的经历和看法:
- 朋友A:我觉得这几天的天气特别热,总是想待在空调下。
- 朋友B:对啊,前几天还下了大雨,真是让人受不了。
- 朋友C:你们说的都是对的,不过我觉得秋天的天气最好,凉爽又舒服。
在这个阶段,讨论围绕“天气”这个主题进行,但每个人的发言都是分散的,涵盖了不同的天气现象(热、雨、秋天等)。这就像在图像的空间域中,所有的像素信息都是分散的,没有明确的集中。
2. 变换域
话题深入:
- 随着聊得深入,大家的注意力开始转向一个更具体的主题,比如“气候变化”:
- 朋友A:说到天气,我看到最近一些报道说气候变化真的很严重。
- 朋友B:是啊,去年那个热浪影响了很多地区,真的让人担心。
- 朋友C:我也关注这个问题,很多人都开始提倡环保了。
在这个阶段,讨论不再分散,而是集中在一个共同的兴趣点上——“气候变化”。这个过程就像是在变换域中,将多个小话题(天气的各个方面)整合为一个主要话题(气候变化),让信息的能量得以集中。
3.变换的意义
- 在这个派对的比喻中,空间域的聊天方式就像是图像中的原始数据,每个像素的信息都是独立的。而变换域则是通过深入讨论将这些信息整合在一起,更加聚焦,从而使得讨论变得更有深度和连贯性。
- 类似于在变换编码中,将图像数据从空间域转换到变换域,可以将原本分散的像素信息通过变换集中在少数几个重要的系数上,使得信息的传递更加高效。
4.变换的过程
在变换编码中,我们通过数学变换(如傅立叶变换、离散余弦变换等)来实现从空间域到变换域的转换。这个过程可以用以下步骤描述:
-
数学变换:
- 假设你们在讨论“天气”的时候,所有的聊天内容都是分散的(关于阳光、雨、气温等)。
- 通过变换编码,将这些分散的内容(像素值)转换成一种更集中、高效的方式(变换域的系数),例如,强调最重要的主题。
-
能量集中:
- 在变换域中,信息的能量会集中在少数几个系数上,就像你们的聊天中,随着讨论的深入,话题会集中在一个点上(比如气候变化)。
- 这种集中能量的方式使得我们可以更方便地处理和存储信息。
5. 信息论与正交变换的熵值
想象你在派对上,朋友们在聊天时,虽然主题一直在变化,但每个人的兴趣和讨论的广度没有减少。无论讨论哪个话题,大家的参与度和热情都保持不变,这就像信息论中的熵值一样。
- 熵值:表示信息的复杂性和不确定性。在派对上,尽管你们的讨论主题不断变化,但参与者的关注和信息量没有减少,反而可能因为具体话题的深入而更加集中。
6. 通过正交变换保持信息量不变
- 在讨论过程中,你们并没有失去任何信息,只是将众多分散的观点整合为一个更集中的话题。这就类似于正交变换,在变换前后的信息量没有损失,仍然保留了每个人的观点(能通过讨论回忆起所有的信息)。
7. 变换系数与量化
-
在深入讨论“气候变化”时,你们发现有些朋友的发言(观点)并不那么重要,可能只是在提到天气的一些小细节(比如“我觉得下个月可能会有点冷”)。此时,你们可以选择忽略这些不太重要的发言,专注于更有深度的讨论(像是变换系数中保留更重要的信息)。
-
量化:你们可以把不重要的讨论(那些小的发言)当作“零”,而把重要的观点(关于气候变化的深刻看法)保留下来。这样在回忆时,虽然会丢失一些细节,但整体讨论的质量不会受到影响。
8. 子图像与分块
子图像的选择
想象你们在派对上讨论“气候变化”这个大话题时,可能会将其分成几个小话题,例如“温室气体”、“极端天气”、“政策应对”等。每个小话题就像一个子图像(n×n的子图像),这样讨论会更集中,也更容易深入。
-
小块讨论的好处: 通过分块讨论,大家能够更容易参与,避免了因为话题过于广泛而导致的信息混乱。
6. 编码过程
- 在讨论结束时,你们决定记录下最重要的观点。你们将这些观点整理,形成一个简短明了的总结,而将那些不重要的细节省略掉。
- 图像分块:就像你们把“气候变化”分成多个小话题讨论。
- 变换:是将所有重要观点整合。
- 量化:选择那些影响大的发言,省略掉不重要的细节。
- 编码:将这些重要的信息记录下来,形成一个易于理解的总结。
7. 变换选择(K-L变换与DCT变换)
- 在选择如何讨论时,有些朋友可能会提出更有效的方式(如使用更系统的方法来整理信息),这种方式可能更全面(K-L变换),但实施起来有些复杂。大多数情况下,大家更倾向于使用简单的方法(DCT变换),这样能够快速有效地进行讨论而不影响信息的质量。
8. 子图像尺寸的选择
- 如果你们将讨论分成太小的主题,虽然每个人发言容易,但可能很快就会没话可说。而如果主题太大,虽然讨论深入但难以把握,容易让人迷失。因此,选择合适的主题大小(比如4×4、8×8等)就像找到一个平衡点,使得讨论既能有深度又不至于失去方向。
9. 变换区域编码
- 在记录总结时,你们会专注于那些最重要的观点(例如,气候变化的核心因素),而将次要的细节(例如细节数据)省略。这就像在变换编码中,保留重要的变换区域,确保信息的核心部分不被丢失。
10. DC 系数和 AC 系数
在图像编码,特别是 JPEG 图像压缩中,DCT(离散余弦变换)被用来将图像信号从空间域转换到频率域。DCT 变换后的系数分为两类:DC 系数和 AC 系数。
它们的划分和定义如下:
1. DC 系数
定义:DC 系数是 DCT 变换后的第一个系数,表示图像块的直流分量(低频信息)。它反映了该 块的平均亮度或亮度偏移。
重要性:DC 系数提供了关于图像块整体亮度的信息。由于人眼对亮度变化的敏感度高,DC 系数通常在压缩中被优先保留。
编码方法:在 JPEG 编码中,DC 系数通常会使用差分编码(Differential coding)。即存储当前块的 DC 系数与前一块的 DC 系数之间的差值。这种方法可以有效减少所需存储的位数,因为相邻图像块的 DC 系数往往相差不大,差值较小。
2. AC 系数
定义:AC 系数是 DCT 变换后从第二个系数开始的其余系数,表示图像块的交流分量(高频信息)。这些系数反映了图像块中细节和变化的信息。
重要性:AC 系数提供了图像块中细节和纹理的信息,如边缘、纹理等。由于这些高频信息对图像的视觉质量影响较大,因此在压缩过程中也需要适当保留。
编码方式:AC 系数通常会被量化和使用 Huffman 编码或其他变长编码方法进行编码。DCT 之后的 AC 系数往往会有许多零值,JPEG 编码利用这一特性进行零值的处理,通常采用 Run-Length Encoding(RLE)技术来优化存储。
3. 划分示例
在一个 的 DCT 块中,变换后得到的系数可以表示为:
DC 系数:
AC 系数:
具体代码分析:
*jpegCompress.m*
function y = jpegCompress(x, quality)
% y = jpegCompress(x, quality) compresses an image X based on 8 x 8 DCT
% transforms, coefficient quantization and Huffman symbol coding. Input
% quality determines the amount of information that is lost and compression achieved. y is the encoding structure containing fields:
% y.size size of x
% y.numblocks number of 8 x 8 encoded blocks
% y.quality quality factor as percent
% y.huffman Huffman coding structure
narginchk(1, 2); % check number of input arguments
if ~ismatrix(x) || ~isreal(x) || ~ isnumeric(x) || ~ isa(x, 'uint8')
error('The input must be a uint8 image.');
end
if nargin < 2
quality = 1; % default value for quality
end
if quality <= 0
error('Input parameter QUALITY must be greater than zero.');
end
m = [16 11 10 16 24 40 51 61 % default JPEG normalizing array
12 12 14 19 26 58 60 55 % and zig-zag reordering pattern
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99] * quality;
order = [1 9 2 3 10 17 25 18 11 4 5 12 19 26 33 ...
41 34 27 20 13 6 7 14 21 28 35 42 49 57 50 ...
43 36 29 22 15 8 16 23 30 37 44 51 58 59 52 ...
45 38 31 24 32 39 46 53 60 61 54 47 40 48 55 ...
62 63 56 64];
[xm, xn] = size(x); % retrieve size of input image
x = double(x) - 128; % level shift input
t = dctmtx(8); % compute 8 x 8 DCT matrix
% Compute DCTs pf 8 x 8 blocks and quantize coefficients
y = blockproc(x, [8 8], @(block) t * block.data * t');
y = blockproc(y, [8 8], @(block) round(block.data ./ m));
y = im2col(y, [8 8], 'distinct'); % break 8 x 8 blocks into columns
xb = size(y, 2); % get number of blocks
y = y(order, :); % reorder column elements
eob = max(x(:)) + 1; % create end-of-block symbol
r = zeros(numel(y) + size(y, 2), 1);
count = 0;
for j = 1:xb % process one block(one column) at a time
i = find(y(:, j), 1, 'last'); % find last non-zero element
if isempty(i) % check if there are no non-zero values
i = 0;
end
p = count + 1;
q = p + i;
r(p:q) = [y(1:i, j); eob]; % truncate trailing zeros, add eob
count = count + i + 1; % and add to output vector
end
r((count + 1):end) = []; % delete unused portion of r
y = struct;
y.size = uint16([xm xn]);
y.numblocks = uint16(xb);
y.quality = uint16(quality * 100);
y.huffman = mat2huff(r);代码详细解释:
对上述 JPEG 压缩过程进行更详细的解析,特别是在输入输出数据范围和数学细节方面进行更深入的说明。
1. 输入验证:
输入参数 `x`:
期望是一个大小为的灰度图像矩阵。
数据类型应为 uint8,数据范围为 [0, 255],表示每个像素的亮度值。
输入参数 `quality`:
这是一个可选参数,控制压缩的质量。若未提供,默认为 1。质量因子必须大于 0。
- 量化过程:JPEG 压缩中的重要步骤是将 DCT(离散余弦变换)系数进行量化。量化过程会损失一些信息,但通过调整质量参数,可以控制这种损失的程度。
- 质量因子:
quality是一个正数,通常用百分比表示(0% 到 100%)。高值意味着较少的压缩、较少的信息损失及更好的图像质量;低值则意味着较高的压缩率、更大的信息损失及更差的图像质量。
实际意义:
-
高质量(如 90%-100%):
- 图像几乎不失真,细节保留良好,适用于对图像质量要求严格的场合,例如打印或高质量显示。
- 例如,
quality = 95会生成高质量的图像,压缩率相对较低,文件体积较大。
-
中等质量(如 50%-80%):
- 图像质量与文件大小之间的平衡,适用于一般用途,如网络共享和常规显示。
- 例如,
quality = 75%会在保持合理质量的同时,压缩文件大小,提高存储和传输的效率。
-
低质量(如 1%-50%):
- 图像可能会显著失真,适用于对文件大小要求极高的场合,例如低带宽的传输。
- 例如,
quality = 30%可能导致明显的块效应和模糊,适合快速预览或较小的存储需求。
2. 质量因子设置:
默认质量因子:
如果用户未提供,`quality` 被设置为 1,用于缩放量化矩阵。
3. 量化矩阵生成:
标准 JPEG 量化矩阵:
量化矩阵调整:
量化矩阵会根据质量因子调整:
这将影响后续的量化过程,通常使高频成分的系数被更多地压缩。
此外,量化矩阵 m 的每个元素代表了 DCT 系数的量化因子。矩阵的前景和背景实际上反映了人眼对不同频率成分的敏感度:
- 低频成分:图像中大部分视觉信息集中在低频成分。因此,低频 DCT 系数(位于矩阵的左上角)所对应的量化因子较小,表示这些系数的重要性较高,应该尽量保留更多的信息。
- 高频成分:图像中的细节和噪声往往集中在高频成分。由于人眼对高频细节的敏感度相对较低,量化因子较大,表示这些系数可以接受较大程度的信息损失。
2. 矩阵的具体数值设计
量化矩阵设计中,数值的选择是基于视觉感知实验的结果,具体取值如下:
- 例如,矩阵的左上角(对应于低频成分)的值较小(如 16、11、10),以保证这些重要的低频信息能被较好地保留。
- 随着矩阵向右下角移动,对应的数值逐渐增大(如 51、61、70 等),这意味着高频信息的量化程度更高,允许更大的信息损失。
4. DCT 转换:
(1)中心化:
图像 `x` 的像素值进行中心化处理:
x' = x - 128
因此,原始值 [0, 255] 的范围被转换为 [-128, 127],这是为了使 DCT 更有效工作,因为 DCT 对于以 0 为中心的信号更为敏感。
对应代码:
[xm, xn] = size(x); % retrieve size of input image
x = double(x) - 128; % level shift input (2)DCT 计算:
对于每个的块,计算 DCT:
输出 DCT 块:
DCT 变换的结果仍为 块,每个块的值范围通常在 [-1020, 1020] 之间,具体取决于输入图像内容。
对应代码:
y = blockproc(x, [8 8], @(block) t * block.data * t');`blockproc` 函数: - 这个函数用于处理图像 `x` 的每个 块。
它的作用是对图像进行分块处理,每个块沿着指定的尺寸进行操作,这里是 `[8 8]`。 -`block.data`: `block.data` 是当前处理的 块(一个小矩阵),其元素范围是图像的灰度值,经过中心化后范围为 [-128, 127]。
`t` 矩阵: `t` 是 DCT 转换矩阵,通常为:
其中 是 DCT 的归一化因子,具体取值为:
计算 DCT: 在 `blockproc` 内部,DCT 是通过对每个块执行矩阵乘法计算的。每个块的结果(DCT 系数)被保存在 y 中,这里的 `t * block.data * t'` 表达式实际上将 块的 DCT 变换应用于该块。结果仍然是
的矩阵,但每个元素是 DCT 系数。
(3)量化 DCT 系数
y = blockproc(y, [8 8], @(block) round(block.data ./ m)); 量化过程:
这一步同样使用 `blockproc`,对 DCT 系数矩阵 y 中的每个 块应用量化。
通过`round(block.data ./ m)`来进行量化。
这里:`block.data` 是当前的 DCT 系数块。
`m` 是之前生成的量化矩阵,经过质量因子的调整。 每个 DCT 系数通过除以对应量化矩阵的值被缩放并进行四舍五入。量化的结果是减少了高频成分的影响,使得高频部分的系数(通常是小值或零)受到了更强的压缩。
量化公式: DCT 系数经过量化:
这一步骤会减少高频成分的影响,使低频成分更为显著。量化过程是将连续的 DCT 系数转换为离散值,这一过程不可避免地会导致信息损失。四舍五入的使用可以减少这种损失的程度。通过将 DCT 系数四舍五入到最接近的整数值,可以更好地保留图像的视觉信息,而不是简单地向下取整或向上取整。
输出量化块:
每个块经过量化后,其值范围依赖于量化矩阵的值和 DCT 的输出,通常为负整数和小于或等于最大量化值的正整数。
(4)将 8×8 块重组为列
y = im2col(y, [8 8], 'distinct');
-
im2col函数:- 这个函数将 8×8 的块重组为列向量。每个 8×8 块被展平为一个长度为 64 的列,这里
distinct选项表示每个块之间没有重叠。
- 这个函数将 8×8 的块重组为列向量。每个 8×8 块被展平为一个长度为 64 的列,这里
-
输出:
- 经过此操作,y 的尺寸将是 64×N,其中 N 是图像中块的总数。每一列对应一个块的量化 DCT 系数。
- 将所有
的量化块重组为列向量,形成一个大小为
的矩阵,其中
。
(5) 获取块的数量
xb = size(y, 2);- 获取块的数量:
size(y, 2)返回矩阵 y 的第二维大小,即块的数量 N。这将用于后续的数据处理。
(6)Zig-Zag 重排列 DCT 系数
y = y(order, :);
-
order是一个预定义的数组,表示 Zig-Zag 扫描的顺序。它将量化后的 DCT 系数按照 Zig-Zag 的访问顺序重新排列,使得低频系数优先
根据:
order = [1 9 2 3 10 17 25 18 11 4 5 12 19 26 33 ...
41 34 27 20 13 6 7 14 21 28 35 42 49 57 50 ...
43 36 29 22 15 8 16 23 30 37 44 51 58 59 52 ...
45 38 31 24 32 39 46 53 60 61 54 47 40 48 55 ...
62 63 56 64];我们可以绘制排序示意图如下:
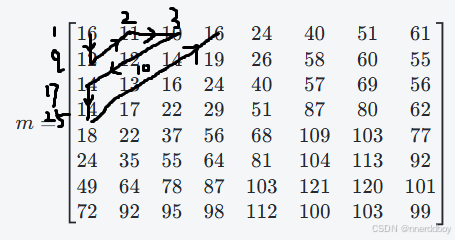
-
Zig-Zag 扫描顺序:
- 通过 Zig-Zag 的方式,量化后的 DCT 系数被重排,通常是这样的顺序:
- 低频系数(接近矩阵左上角的值);
- 随后是高频部分(靠近右下角的值)。
- 此操作使得后续步骤(如霍夫曼编码)更高效,因为霍夫曼编码会利用低频系数的出现频率更高的特性,减少编码长度。
- 通过 Zig-Zag 的方式,量化后的 DCT 系数被重排,通常是这样的顺序:
5.零系数处理和结束符:
处理零系数:
由于在量化后的 DCT 系数中,许多块(8x8 像素的块)可能包含大量的零,尤其是在高频信息被压缩的情况下。为了有效地表示这些块,JPEG 使用了一个特殊的符号——EOB,表示“块结束”。对于每个块,找到最后一个非零元素,构造一维数组 `r`,并在结束符 EOB 处加上标记。这个 EOB 通常选择一个值,保证它在量化结果中不出现。
输出数组 `r`:
数组 `r` 包含非零量化值和 EOB,大小依赖于所有块的非零元素数量。
具体步骤如下:
eob = max(x(:)) + 1; % create end-of-block symbol创建结束符(EOB)
eob(End of Block)符号被定义为输入图像x中最大值加1。- 这个符号用于标识当前块的结束。它的选择通常是为了避免与任何可能的量化 DCT 系数值冲突。由于 DCT 系数大多为负数或接近于量化矩阵所限制的范围,选择最大值加1 相对安全。
max(x(:)) + 1的目的是选择一个不可能出现在图像中任何有效 DCT 系数的值作为 EOB 符号。这里,max(x(:))是图像中可能出现的最大像素值(在 8 位图像中通常为 255),因此选择max(x(:)) + 1确保了 EOB 永远不会与任何实际的 DCT 系数发生冲突。
r = zeros(numel(y) + size(y, 2), 1);
count = 0;
r是一个预分配的零向量,它将用于存储最终的编码输出,包括量化后的 DCT 系数和 EOB 符号。numel(y)是量化后 DCT 系数的总数,而size(y, 2)是块的数量。这样初始化可以保证r有足够的空间来存放所有的系数及其后面的 EOB 符号。- 处理每个块的编码:
for j = 1:xb % process one block(one column) at a time
i = find(y(:, j), 1, 'last'); % find last non-zero element
if isempty(i) % check if there are no non-zero values
i = 0;
end
p = count + 1;
q = p + i;
r(p:q) = [y(1:i, j); eob]; % truncate trailing zeros, add eob
count = count + i + 1; % and add to output vector
end
- 这个循环遍历每一个块(每一列
y),并处理每个块的 DCT 系数。 find(y(:, j), 1, 'last')的作用是找到该块中最后一个非零 DCT 系数的位置。如果块中没有非零值,i被设置为 0。r(p:q) = [y(1:i, j); eob];将从当前块的前i个非零 DCT 系数复制到输出数组r中,并在这些系数后加上 EOB 符号,表示该块数据的结束。count变量用于跟踪r数组中已填充的元素数量,以便为下一个块的填充找到正确的位置。
清理未使用的部分:
r((count + 1):end) = []; % delete unused portion of r
在所有块都处理完成后,可能存在 r 数组中未被使用的部分。清除这些未使用元素是为了确保最终输出结果的整洁,避免不必要的零值。
- 稀疏性:JPEG 压缩利用 DCT 变换后的稀疏性,高频成分通常为零。EOB 符号的引入有助于有效地表示这些零,以减少存储空间。
- 有效编码:EOB 允许解码器知道何时停止读取当前块的数据,这使得解码过程更高效。
- 提升压缩率:通过使用 EOB 和其他压缩手段(如霍夫曼编码),JPEG 能够显著降低文件大小,同时尽可能保留图像质量。
6. 霍夫曼编码:
输入:
数组 `r` 的长度取决于图像内容,可能会有大量的 EOB 标记和少量的非零系数。
输出:
霍夫曼编码压缩后的数据会被存储在结构体 `y.huffman` 中,具体大小依赖于 Huffman 表的构建以及输入数据的特征。
7. 输出结果:
最终返回的结构体 `y` 包含以下字段:
- `y.size`: 图像原始大小,类型为 `uint16`,维度为 [H, W]。
- `y.numblocks`: 编码后的块数量,类型为 `uint16`,值为 。
- `y.quality`: 质量因子,类型为 `uint16`,值为。
- `y.huffman`: 霍夫曼编码的结构体,大小取决于编码后的数据长度。
输入输出大小总结
输入:
图像 `x`: (uint8,值范围 [0, 255])
质量因子: 标量(默认为 1)
输出:
输出结构体 `y`:
`y.size`: [H, W](uint16)
`y.numblocks`: 标量(uint16),值为
`y.quality`: 标量(uint16),值为
`y.huffman`: 一维数组,大小为压缩后的数据长度(具体取决于图像内容和质量因子)
结论:
通过上述详细解析,JPEG 压缩过程中的各个步骤及其对应的输入输出大小、数据范围得到了充分的阐述。这样的细节有助于理解 JPEG 压缩的数学基础和实际实现中的数据流动,并确保在处理图像时能够有效地理解其行为与效果。质量因子和输入图像的内容将决定最终的压缩效率和图像质量。
为了更清晰的展示,画了一个流程图
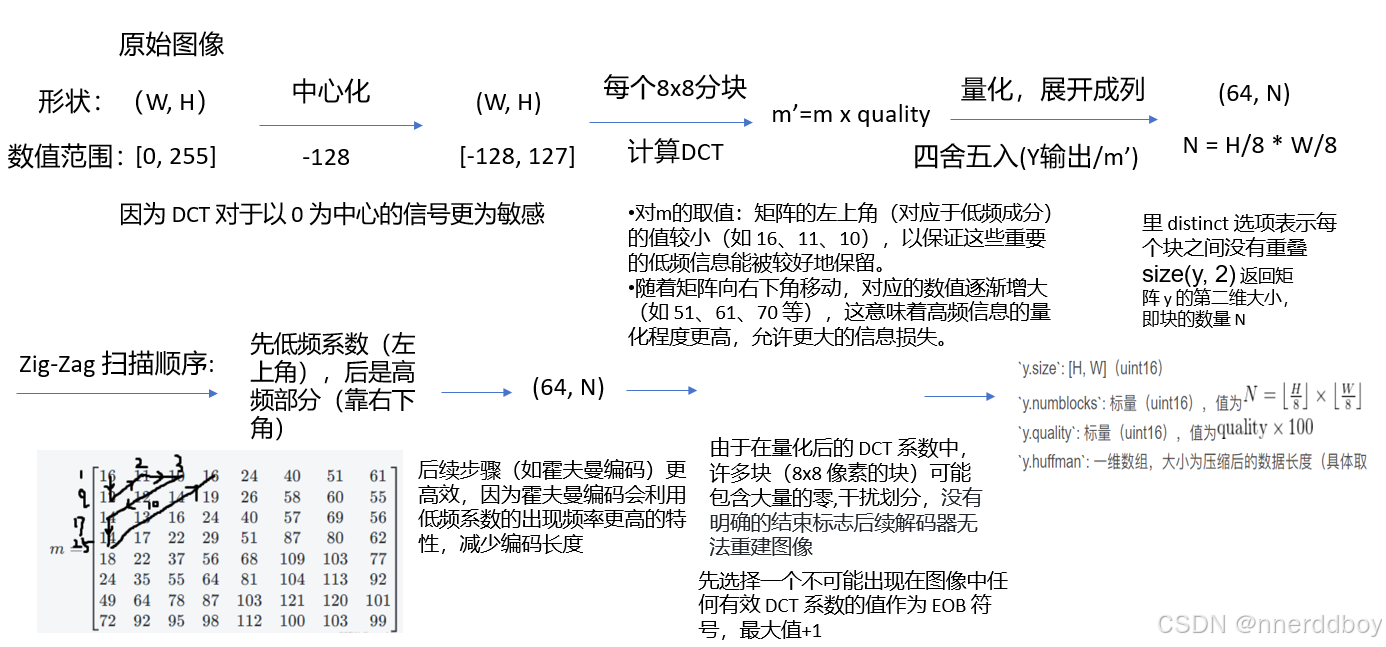


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









