







学习了哔哩哔哩up主——兰斯诺特 视频后做的学习笔记
代码网址 https://github.com/lansinuote/Huggingface_Toturials
upz主推荐书:《基于Bert的自然语言处理模型实战》
hugging face是一个开源社区提供了开源的nlp模型数据集和其他的工具
http//huggingface.co/datasets 数据集地址
http//huggingface.co/models 代码地址
http//huggingface.co/docs 官方文档
包含热门的数据集比如glue imdb wikitext等
主要的模型
自回归 GPT2 Transformer-XL XLNet
自编码:BERT ALBERT ROBERT ELECTRA
seq to seq :BARE Pegasus T5
安装环境: 需要安装transformers datasets
1.字典和分词工具:tokenizer 加载tokenizer时要传入一个name
(1)如何加载预训练字典和分词方法
tokenizer = BertTokenizer.from_pretrained( pretrained_model_name_or_path=‘thunlp/Lawformer’, cache_dir=None, force_download=False,)预训练字典分词模型就加载进去了
#这里的pretrained_model要用huggingface中有的网址https://huggingface.co/models
sents = [ ‘’,]
tokenizer, sents
(2)简单的编码函数
#编码两个句子
out = tokenizer.encode( text=sents[0], text_pair=sents[1], truncation=True, padding=‘max_length’, add_special_tokens=True, max_length=30, return_tensors=None
print(out)
tokenizer.decode(out)
(3)增强编码函数:前面一样 加入return_token_type_ids=True, #返回attention_mask return_attention_mask=True, #返回special_tokens_mask ,return_special_tokens_mask=True, for k, v in out.items(): print(k, ‘:’, v) tokenizer.decode(out[‘input_ids’])
(4)批量编码 out = tokenizer.batch_encode_plus(batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])],…)
(5)字典操作 #获取字典 zidian = tokenizer.get_vocab(),#添加新词tokenizer.add_tokens(new_tokens=[‘月光’, ‘希望’])
#添加新符号 tokenizer.add_special_tokens({‘eos_token’: ‘[EOS]’})
2.数据集的操作
(1)加载数据集 from datasets import load_datasets #加载数据dataset = load_dataset(path=‘seamew/ChnSentiCorp’, split=‘train’)
(2)操作函数 排序和打乱 #sort sorted_dataset = dataset.sort(‘label’)print(sorted_dataset[‘label’][:10])print(sorted_dataset[‘label’][-10:])
#shuffle#打乱顺序shuffled_dataset = sorted_dataset.shuffle(seed=42)
#select dataset.select([0, 10, 20, 30, 40, 50])
#filterdef f(data): return data[‘text’].startswith(‘选择’) start_with_ar = dataset.filter(f) len(start_with_ar), start_with_ar[‘text’]
#train_test_split, 切分训练集和测试集dataset.train_test_split(test_size=0.1)
from datasets import load_from_disk
dataset = load_dataset(path=‘seamew/ChnSentiCorp’, split=‘train’)
#保存和加载dataset.save_to_disk(“./”)
dataset = load_from_disk(“./”)
#导出为其他格式
#dataset.to_csv(‘./datasets.csv’)
#dataset.to_json(‘./datasets.json’)
实战任务:用bert实现中文分类问题
第一步首先要定义数据集
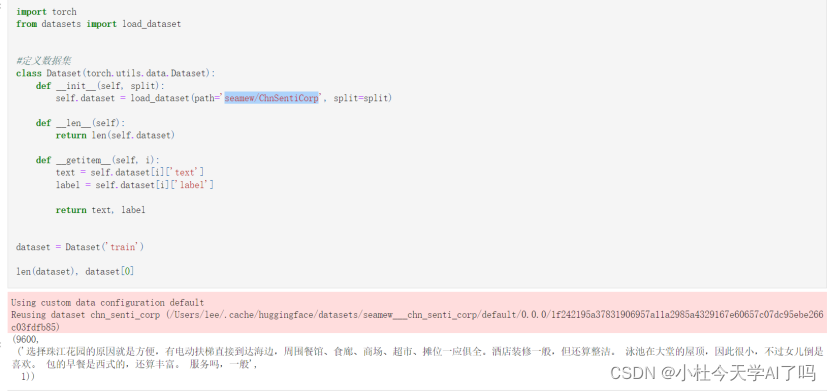
本次实战应用的数据集是ChnSentiCrop 情感分类数据集可以通过huggingface网站上导入具体实现过程是通过定义了一个Dataset的类来继承torch加载数据集的方法
通过load_dataset 将huggingface上的ChnSentiCorp数据集加载进入我们的模型,这里我们返回的是dataset的长度 还有text 和label
第二步加载tokenizer 来加载字典和分词工具本次任务使用的分词工具是bert-base-chinese 和我们的预训练模型相匹配

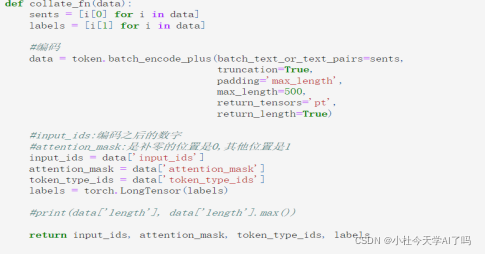
第三步 定义了一个批处理函数collate_fn,因为在训练和测试的时候我们需要对数据集中的数据一批一批的处理这些数据在这个函数中我们要进行分词和编码,然后把分词以后的结果input_ids, attention_mask, token_type_ids, labels取出来,用于后续处理这些数据 这里这个函数返回的是input_ids, attention_mask, token_type_ids, labels这些数据
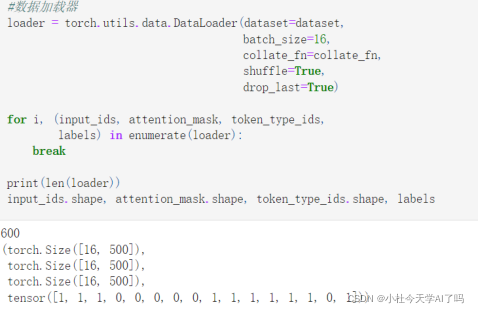
第四步定义一个数据加载器 并查看数据样例,每个批次有16个数据把批处理函数放入数据加载器,
这里input_ids, attention_mask维度是16500(之前定义分词最大长度是500句子长度 不够的在后面补0)这里loader长度为600是因为一共有9600个数据分为16批次以后数据被分成了600组 需要加载600次
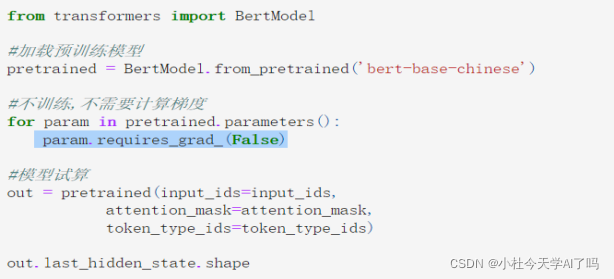
第五步加载中文模型 这里我们用的中文模型是bert-base-Chinese这里我们先不进行训练不计算梯度把预训练模型给冻结住,只训练下游任务模型对模型预训练本身参数不做调整( param.requires_grad_(False))
计算的结果是一个16500(分词长度)768(词编码维度把每一个词编码为维度768维度的向量)
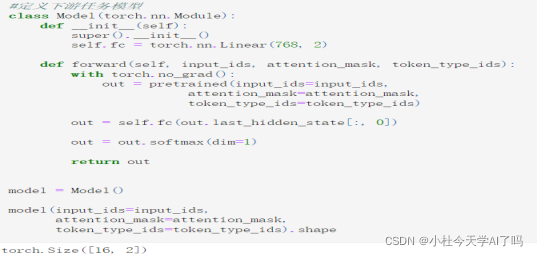
第六步我们定义一下下游任务模型 这个Model非常简单,只应用到了一个全连接神经网络torch.nn.Linear(768, 2)768接上游任务的输出16500768,我们拿预训练模型进行一个计算抽取数据当中的特征input_ids=input_ids,attention_mask,
token_type_ids,然后把抽取出来的特征放到全连接神经网络中进行计算,这个特征结果只需要用第零个特征[cls]因为在bert中cls通过transformer attention 机制已经包含了一个句子所有的特征[cls]可用于分类任务,输出是维度一个162的结果 也就是说模型把句子分为了两类 1 /0
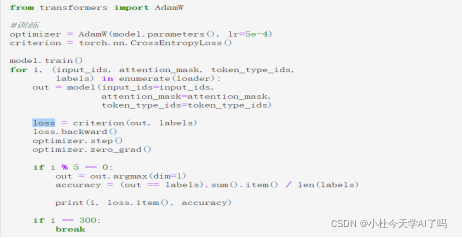
最后一步训练下游任务模型 然后在测试集上进行测试,这里优化器我们选择的是AdamW 损失函数应用的是CrossEntropyLoss()把输出的out预测值和标签值labels进行CrossEntropyLoss计算,然后进行反向传播梯度计算
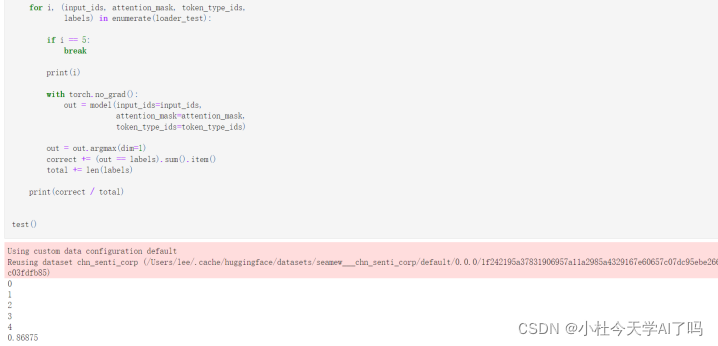
训练数据实验结果

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









