







CSP认证2023-03:田地丈量、垦田计划、LDAP,python满分解答代码
目录
一、田地丈量
问题描述

输入输出

输入
4 10 10
0 0 5 5
5 -2 15 3
8 8 15 15
-2 10 3 15输出
44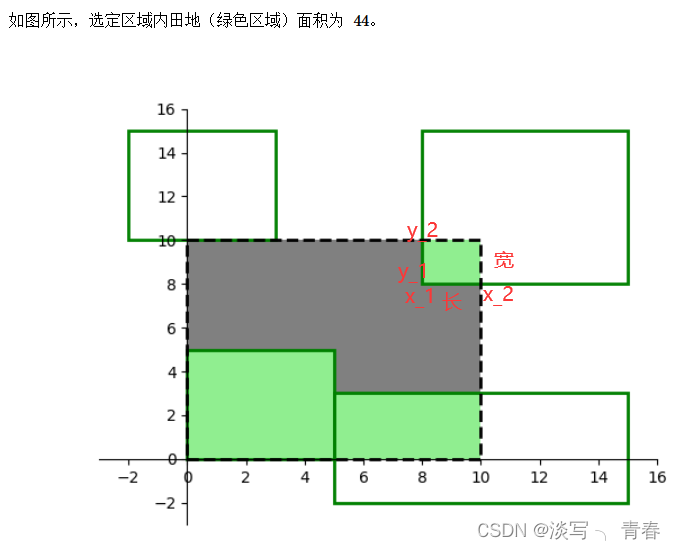
思路
对于每一个选定区域,我们只需要知道此区域的长和宽,即可求出,如上图所示。对于长,需要算出x_1,x_2值(x_1<=x_2,x_2-x_1即为长)。观察上图,x_1实际上是max(x1,0),x_2为min(a,x2)。同理,宽=y_1-y_2,其中y_1<=y_2,y_1=max(0,y1),y_2=min(b,y2)
代码和结果
n,a,b = list(map(int,input().split()))
result = 0
for i in range(n):
x1,y1,x2,y2 = list(map(int,input().split()))
x = min(a,x2)-max(0,x1)
y = min(b,y2)-max(0,y1)
if x>0 and y>0:
result+=x*y
print(result)
二、垦田计划
问题描述

输入和输出

输入
4 9 2
6 1
5 1
6 2
7 1输出
5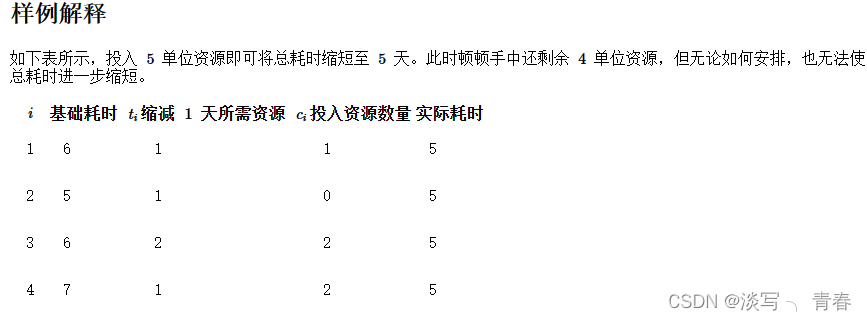
思路
1.将开垦耗时 相同 的 区域,其耗时缩短1天所需资源数量 进行累加存入字典中,因为总的耗时是由耗时最长的区域所决定的(可以看成是木桶效应)
2.从所有区域中耗时最长的时间开始,所需时间不断减少1,直到时间等于每块区域的最少开垦天数或资源不够为止
具体步骤如下:
- 首先判断需要的资源数是否超过拥有的资源数,若超过则退出循环,否则继续。
- 记录总耗时减少一天所需要的资源数,它等于 所有耗时超过max_t的区域 耗时减少1天所需的资源数的总和
- 消耗的资源添加到需要的资源数中
代码和结果
n, m, k = list(map(int, input().split()))
result = 0
t_dict = {}
for i in range(n):
t_i, c_i = list(map(int, input().split()))
'''
将开垦耗时 相同 的 区域,其耗时缩短1天所需资源数量 进行累加,因为总的耗时是由耗时最长的区域所决定的(可以看成是木桶效应)
例如下述例子:
3 9 2
6 1
5 1
6 2
要想让耗时从6变成5,所需资源必须大于等于1+2
'''
if t_i not in t_dict.keys():
t_dict[t_i] = 0
t_dict[t_i] += c_i
# 对字典进行排序
t_dict = dict(sorted(t_dict.items(), key=lambda d: d[0], reverse=True))#从大到小进行排序,先满足耗时最长的
t_key_list = list(t_dict.keys())
max_t = t_key_list[0]#在不使用任何资源情况下,所需的最长时间
all_resource = 0#所用到的总资源数
des = 0 #耗时减少一天所需要的资源数,它等于 所有 耗时超过max_t的区域 耗时减少1天所需的资源数
while max_t >=k:
all_resource += des#总资源数进行累加
if all_resource>m:#需要的资源数超过拥有的资源数
break
if t_dict.get(max_t):
des = des + t_dict[max_t]
max_t-=1
print(max_t+1)
三、LDAP
问题描述

思路
1.通过问题描述可知,我们要处理的数据EXPR形式为
BASE_EXPR 或者 (LOGIC "(" EXPR ")" "(" EXPR ")")为此可以针对这两种情况分开处理。其中,BASE_EXPR由ATTRIBUTE OPERATOR VALUE组成,这种情况好处理,按照要求进行匹配(查字典)即可;重点是(LOGIC "(" EXPR ")" "(" EXPR ")"),其中涉及了嵌套,即EXPR中包含了EXPR,在处理时首先就要想到使用栈来处理,具体为通过 左右括号 提取出表达式(数据结构栈的常用作用),不断进行栈进栈出,从而获得结果。
2.在读取用户属性和属性值时,可以考虑将属性和属性值拼起来作为键存入字典中,以便后续的查询计算,代码如下:
attr_and_attr_of_value= str(attr)+":"+str(attr_of_value) if not user_data.get(attr_and_attr_of_value): user_data[attr_and_attr_of_value] = [] user_data[attr_and_attr_of_value].append(DN)3.定义一个字典用于记录用户是否拥有该属性,代码如下:
has_attr={}#用于记录用户是否拥有该属性 #记录用户是否拥有key属性 if not has_attr.get(key): has_attr[key] =[] has_attr[key].append(DN)
代码和结果
n = int(input())
'''
用字典存储用户的数据,具体存储形式如下:
#{'attr:attr_value':[DN_1,DN_2],'attr_1:attr_value_2':[DN_1,DN_2],}
'''
def my_print(result):
result = sorted(result)
for r in result:
print(r, end=' ')
print()
def compute_base(judge):#计算原子式
'''
:param judge:原子式
:return:
'''
#提取中间的值
if ":" in judge:
result = user_data.get(judge)#DN列表,这里也能为空,需要加一个判断
if not result:
result = []
else:
judge_list = judge.split('~')
attr = int(judge_list[0])
attr_of_value = judge_list[1]
# 做差集即可
has_attr_user = has_attr[attr] # 拥有该属性的用户
# 读取拥有该属性attr,且值为attr_of_value的用户
has_attr_and_attr_of_value_is = user_data.get(str(attr) + ":" + attr_of_value)
if not has_attr_and_attr_of_value_is:
result = has_attr_user
else:
result = set(has_attr_user) - set(has_attr_and_attr_of_value_is)
return result
def get_result(judge):
#给两边加上括号
judge = '('+judge+')'#通过 左右括号 提取表达式,数据结构 栈的常用操作
# 使用栈结构处理数据
stack = []
BASE_COMPUTE = []#用于存放原子式的结果
for i in judge:
easy_expr =''
stack.append(i)
if stack[-1]==')':
while len(stack)!=0:#栈不为空
top_stack = stack.pop()
if top_stack!='(' and top_stack!=')':#不要把括号加进来
easy_expr=top_stack+easy_expr
if top_stack=='(':
break
if easy_expr[0]=='&' or easy_expr[0]=='|':
base_1 = set(BASE_COMPUTE.pop())#转成集合类型 直接用set的交 并操作
base_2 = set(BASE_COMPUTE.pop())
if easy_expr[0]=='&':
base = base_1 & base_2
else:
base = base_1 | base_2
BASE_COMPUTE.append(base)
else:#当运算为原子式时
base_result = compute_base(easy_expr)
BASE_COMPUTE.append(base_result)
return BASE_COMPUTE.pop()
user_data ={}
has_attr={}#用于记录用户是否拥有该属性
for i in range(n):
data = list(map(int,input().split()))
DN = data[0]#用户DN
number_of_attr = data[1]#用户包含的属性值
for j in range(1,number_of_attr+1):
key = data[2*j]
#记录用户是否拥有key属性
if not has_attr.get(key):
has_attr[key] =[]
has_attr[key].append(DN)
value = data[2*j+1]
attr_and_attr_of_value= str(key)+":"+str(value)
if not user_data.get(attr_and_attr_of_value):
user_data[attr_and_attr_of_value] = []
user_data[attr_and_attr_of_value].append(DN)
m = int(input())
for i in range(m):
judge = input()
if len(judge)==3:#原子表达式,长度为3
result = compute_base(judge)
my_print(result)
else:#否则为复合式
result = get_result(judge)
my_print(result)
















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









