







基础
-
img.convert():是图像实例化对象的一个方法,接受一个mode 参数,用以指定一个色彩模式。

-
os.path.join():用于拼接文件路径
-
os.listdir():返回指定路径下的所有文件和文件夹的名字。
-
endswith():判断字符串或字符是否以指定的字符串或者字符结尾。
-
Batchnorm层: 批量归一化。
作用:加速神经网络训练,加速收敛速度及稳定性的算法。 -
图像分割输出是图片,损失值是对比输出图片与标签图片的像素差。
-
参考链接:宠物图像分割
-
关于模型组网:就是把网络分成小模块,然后组织起来。
Attention U-Net
注意力机制是在计算资源一定的情况下,把有限的计算资源更多地调整分配给相对重要的任务,使得计算机能合理规划并且处理大量信息的一种模型。U.Net网络提取的低层特征中存在较多的冗余信息,注意力机制的融入可以抑制网络模型学习无关任务,达到抑制冗余信息被激活的目的,同时提高模型学习重要特征的能力。
环境设置
import os
import io
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image as PilImage
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
paddle.set_device('gpu')
paddle.__version__
数据处理
提取划分图片
作用:将图片数据划分,并保存为txt文件。
IMAGE_SIZE = (160, 160)
train_images_path = "images/"
label_images_path = "annotations/trimaps/"
image_count = len([os.path.join(train_images_path, image_name)
for image_name in os.listdir(train_images_path)
if image_name.endswith('.jpg')])
print("用于训练的图片样本数量:", image_count)
# 对数据集进行处理,划分训练集、测试集
def _sort_images(image_dir, image_type):
"""
对文件夹内的图像进行按照文件名排序
"""
files = []
for image_name in os.listdir(image_dir):
if image_name.endswith('.{}'.format(image_type)) \
and not image_name.startswith('.'):
files.append(os.path.join(image_dir, image_name))
return sorted(files)
def write_file(mode, images, labels):
with open('./{}.txt'.format(mode), 'w') as f:
for i in range(len(images)):
f.write('{}\t{}\n'.format(images[i], labels[i]))
images = _sort_images(train_images_path, 'jpg')
labels = _sort_images(label_images_path, 'png')
eval_num = int(image_count * 0.15)
write_file('train', images[:-eval_num], labels[:-eval_num])
write_file('test', images[-eval_num:], labels[-eval_num:])
write_file('predict', images[-eval_num:], labels[-eval_num:])
图片和标签展示
with open('./train.txt', 'r') as f:
i = 0
for line in f.readlines():
image_path, label_path = line.strip().split('\t')
image = np.array(PilImage.open(image_path))
label = np.array(PilImage.open(label_path))
if i > 2:
break
# 进行图片的展示
plt.figure()
plt.subplot(1,2,1),
plt.title('Train Image')
plt.imshow(image.astype('uint8'))
plt.axis('off')
plt.subplot(1,2,2),
plt.title('Label')
plt.imshow(label.astype('uint8'), cmap='gray')
plt.axis('off')
plt.show()
i = i + 1

数据集类定义
import random
from paddle.io import Dataset
from paddle.vision.transforms import transforms as T
class PetDataset(Dataset):
"""
数据集定义
"""
def __init__(self, mode='train'):
"""
构造函数
"""
self.image_size = IMAGE_SIZE
self.mode = mode.lower()
assert self.mode in ['train', 'test', 'predict'], \
"mode should be 'train' or 'test' or 'predict', but got {}".format(self.mode)
self.train_images = []
self.label_images = []
with open('./{}.txt'.format(self.mode), 'r') as f:
for line in f.readlines():
image, label = line.strip().split('\t')
self.train_images.append(image)
self.label_images.append(label)
def _load_img(self, path, color_mode='rgb', transforms=[]):
"""
统一的图像处理接口封装,用于规整图像大小和通道
"""
with open(path, 'rb') as f:
img = PilImage.open(io.BytesIO(f.read()))
if color_mode == 'grayscale':
# if image is not already an 8-bit, 16-bit or 32-bit grayscale image
# convert it to an 8-bit grayscale image.
if img.mode not in ('L', 'I;16', 'I'):
img = img.convert('L')
elif color_mode == 'rgba':
if img.mode != 'RGBA':
img = img.convert('RGBA')
elif color_mode == 'rgb':
if img.mode != 'RGB':
img = img.convert('RGB')
else:
raise ValueError('color_mode must be "grayscale", "rgb", or "rgba"')
return T.Compose([
T.Resize(self.image_size)
] + transforms)(img)
def __getitem__(self, idx):
"""
返回 image, label
"""
train_image = self._load_img(self.train_images[idx],
transforms=[
T.Transpose(),
T.Normalize(mean=127.5, std=127.5)
]) # 加载原始图像
label_image = self._load_img(self.label_images[idx],
color_mode='grayscale',
transforms=[T.Grayscale()]) # 加载Label图像
# 返回image, label
train_image = np.array(train_image, dtype='float32')
label_image = np.array(label_image, dtype='int64')
return train_image, label_image
def __len__(self):
"""
返回数据集总数
"""
return len(self.train_images)
模型组网
基础模块
class conv_block(nn.Layer):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU(),
nn.Conv2D(ch_out, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
)
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Layer):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
)
def forward(self, x):
x = self.up(x)
return x
class single_conv(nn.Layer):
def __init__(self, ch_in, ch_out):
super(single_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
)
def forward(self, x):
x = self.conv(x)
return x
Attention块
class Attention_block(nn.Layer):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2D(F_g, F_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2D(F_l, F_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(F_int)
)
self.psi = nn.Sequential(
nn.Conv2D(F_int, 1, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(1),
nn.Sigmoid()
)
self.relu = nn.ReLU()
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
Attention U-Net
class AttU_Net(nn.Layer):
def __init__(self, img_ch=3, output_ch=1):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool3 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2D(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool1(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool2(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool3(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = paddle.concat(x=[x4, d5], axis=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = paddle.concat(x=[x3, d4], axis=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = paddle.concat(x=[x2, d3], axis=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = paddle.concat(x=[x1, d2], axis=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
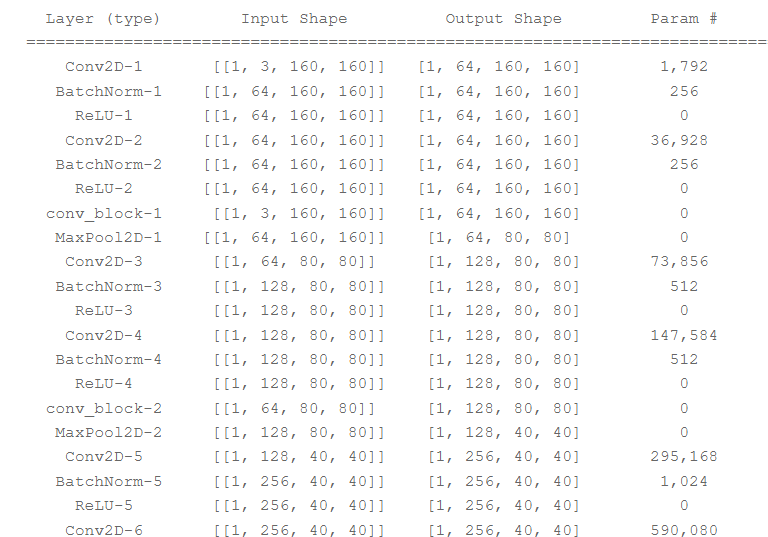
模型可视化
num_classes = 4
network = AttU_Net(img_ch=3, output_ch=num_classes)
model = paddle.Model(network)
model.summary((-1, 3,) + IMAGE_SIZE)
训练及预测
训练
train_dataset = PetDataset(mode='train') # 训练数据集
val_dataset = PetDataset(mode='test') # 验证数据集
optim = paddle.optimizer.RMSProp(learning_rate=0.001,
rho=0.9,
momentum=0.0,
epsilon=1e-07,
centered=False,
parameters=model.parameters())
model.prepare(optim, paddle.nn.CrossEntropyLoss(axis=1))
model.fit(train_dataset,
val_dataset,
epochs=15,
batch_size=32,
verbose=1)
预测
predict_dataset = PetDataset(mode='predict')
predict_results = model.predict(predict_dataset)
plt.figure(figsize=(10, 10))
i = 0
mask_idx = 0
with open('./predict.txt', 'r') as f:
for line in f.readlines():
image_path, label_path = line.strip().split('\t')
resize_t = T.Compose([
T.Resize(IMAGE_SIZE)
])
image = resize_t(PilImage.open(image_path))
label = resize_t(PilImage.open(label_path))
image = np.array(image).astype('uint8')
label = np.array(label).astype('uint8')
if i > 8:
break
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title('Input Image')
plt.axis("off")
plt.subplot(3, 3, i + 2)
plt.imshow(label, cmap='gray')
plt.title('Label')
plt.axis("off")
# 模型只有一个输出,通过predict_results[0]来取出1000个预测的结果
# 映射原始图片的index来取出预测结果,提取mask进行展示
data = predict_results[0][mask_idx][0].transpose((1, 2, 0))
mask = np.argmax(data, axis=-1)
plt.subplot(3, 3, i + 3)
plt.imshow(mask.astype('uint8'), cmap='gray')
plt.title('Predict')
plt.axis("off")
i += 3
mask_idx += 1
plt.show()















 5178
5178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









