







过滤
获取大于105的值
vals = dataset[dataset>105]
使用extract,获取大于90,小于95的值
vals = np.extract((dataset > 90) & (dataset < 95), dataset)
where 方法针对匹配值获取索引(行,列)
rows, cols = np.where(abs(dataset-100) - 1)
indices = [[ rows[index], cols[index]] for (index, _) in np.ndenumerate(rows)]
排序
对每一行进行排序
row = np.sort(dataset)
对每一列进行排序
col = np.sort(dataset, axis=0)
argsort方法不改变原数据集
sorte = np.argsort(dataset)
组合
横向组合

col = np.vstack([halfed_frist[0], halfed_frist[1]])

竖向组合

secol = np.hstack([col, thirds[1]])

重构
重构为一维列表,如果值为-1,则Numpy会自己找出这个值
single = np.reshape(dataset, (1,-1))
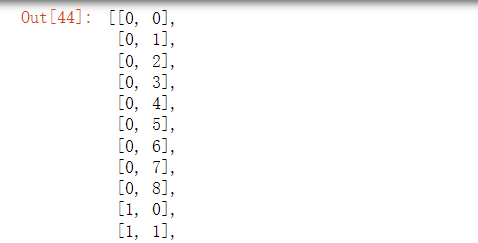
重构为两列
two_col = dataset.reshape(-1,2)
two_col.shape
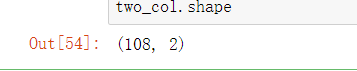















 1691
1691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









