






目录
7.2渐进式训练策略(Progressive Training Strategy)
项目地址:Text2Earth
Git地址:Chen-Yang-Liu/Text2Earth
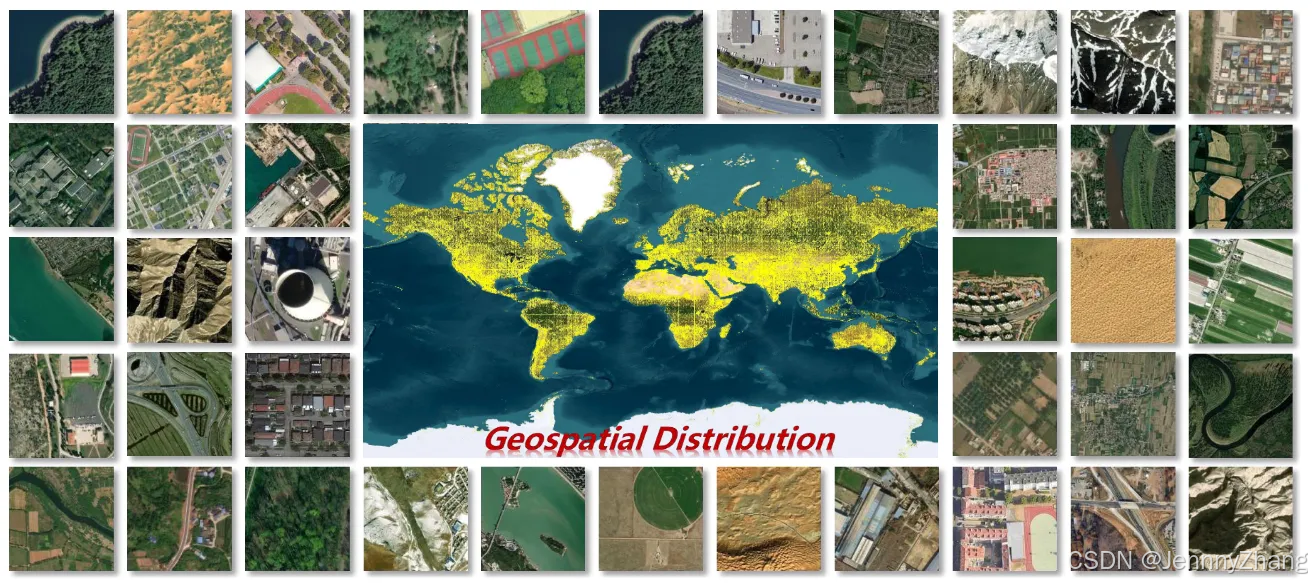
根据不同任务需求,开发了两种专用版本的 Text2Earth 模型:
Text2Earth_t:专为文本到图像生成任务优化,根据用户提供的 文本描述 和 分辨率要求,生成与输入条件匹配的遥感图像。
Text2Earth_e:专为图像编辑任务优化,支持基于输入文本对现有遥感图像进行 局部编辑,如修复、修改或增强特定区域。
1.背景与动机
当前生成式模型在自然图像生成上取得了显著进展,但遥感领域的研究相对较少;现有的遥感图像-文本数据集规模较小、覆盖范围有限并且缺少遥感数据信息,无法支持全局范围的生成需求;当前的方法缺乏在多分辨率可控性和无边界图像生成方面的能力。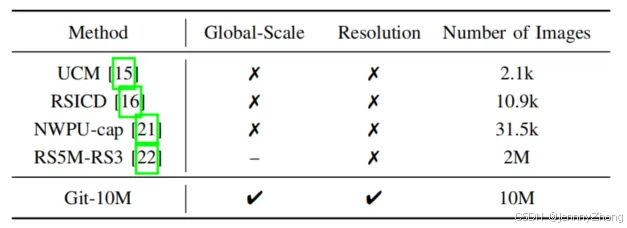
2.主要贡献
构建了全球范围遥感图文数据集,超1000万图文数据对,自由输入文本并控制图像内容和分辨率,通过文本实现“无边界”遥感图像的“无缝”生成;通过文本实现遥感图像编辑;文本驱动的多模态遥感图像生成(全色、红外、SAR);多模态图像转换、图像增强。
3.创新点和关键技术
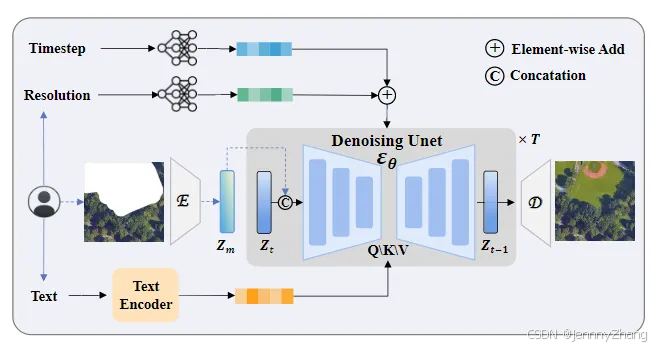
- 分辨率引导机制:为了解决之前模型在分辨率控制方面的不足,Text2Earth 提出了 分辨率引导机制。这个机制将图像的分辨率信息编码并融入到每一步的去噪过程,确保生成的图像符合指定的分辨率需求。
- 动态条件适应策略:这个策略允许模型在训练和推理过程中处理条件输入的缺失。例如,当缺少文本或分辨率输入时,模型仍然能够生成高质量的图像,增强了生成的灵活性和鲁棒性。
- 模型架构:VAE、OpenCLIP ViT-H、U-Net、Cross-Attention
- VAE(变分自编码器):用于图像的高效压缩和重建。
- OpenCLIP ViT-H 文本编码器:将输入的文本描述转化为高维的语义向量。
- U-Net 和交叉注意力机制:通过 U-Net 网络进行多步骤的去噪,确保生成的图像与输入文本语义一致。交叉注意力机制 则帮助模型关注文本描述中的重要细节,确保图像生成的准确性。
4.Git-10M 数据集
- 基于公开数据和从 Google Earth 收集的图像,Million-AID、GeoPile、SSL4EO-S12、SkyScript、DIOR and RSICB 经过严格的去重与质量提升处理,合并成1000万对遥感图像和文本描述,迄今为止规模最大的此类数据集,它覆盖了广泛的全球地理场景,包括城市、森林、山脉等,并包含了图像分辨率和地理位置等丰富的元数据。
- 基于 RSICD 数据集合成了多模态数据集,通过引入 PAN、NIR、SAR、低分辨率和雾霾图像,显著增强了数据集的多样性,拓展了模型在多模态遥感生成任务中的适用性。
- 全色(PAN)图像:
- 生成方式:利用灰度变换将原始 RGB 图像转换为模拟的单色图像。
- 特点:PAN 图像模拟了全色影像,主要用于提供更高的空间分辨率信息。
- 近红外(NIR)图像:
- 生成方式:使用预训练模型生成,模拟可见光之外的光谱信息。
- 特点:近红外图像在植被分析和土地覆盖分类中具有重要应用。
- 合成孔径雷达(SAR)图像:
- 生成方式:基于 Pix2Pix 框架 的预训练模型生成,提供雷达样式的图像表示。
- 特点:SAR 图像能穿透云层和植被,适用于全天候遥感应用。
- 低分辨率图像:
- **生成方式:**通过对 RGB 图像进行降采样,模拟空间分辨率受限的场景。
- 特点:低分辨率图像用于训练模型在低清晰度数据中的生成能力。
- 雾霾图像:
- 生成方式:使用经典的雾模拟算法,在原始图像上合成雾霾效果。
- 特点:模拟恶劣天气条件下的遥感场景,为复杂环境下生成任务提供数据支持
- 全色(PAN)图像:
5.Text2Earth 模型
- 基础架构:Text2Earth 是一个基于扩散框架的生成式基础模型,拥有 13亿个参数,用于生成全球范围的遥感图像。
- 生成流程:为了解决现有方法在生成大规模遥感图像时的计算负担,Text2Earth 使用 变分自编码器(VAE) 来压缩图像至紧凑的特征空间,从而显著降低计算量。然后,在该特征空间内进行扩散过程,保持图像的高保真度。
- 文本理解:为提升模型对文本的理解,Text2Earth 使用了 OpenCLIP ViT-H 编码器,将文本转化为高维的语义嵌入,并通过 U-Net 网络 和 交叉注意力机制(Cross-Attention) 实现对图像的精准去噪。
6.应用场景
- **零样本生成:**根据用户提供的文本描述,生成具体的遥感图像,而无需针对特定场景进行微调(即零样本生成)。这意味着用户可以直接输入文本描述,模型即可生成对应的遥感图像。
- **无边界场景生成:**实现 无边界图像生成,即用户可以通过连续输入文本描述,逐步扩展生成的图像,形成广阔的、连续的地理场景
- **图像编辑:**不仅能够生成图像,还可以对已有图像进行 编辑
- 修复(Inpainting):填补图像中的缺失部分
- 去云(Cloud Removal):去除卫星图像中的云层
- 局部内容修改:根据用户需求修改图像的特定区域。
- 超分辨率
- **跨模态生成:**不仅限于根据文本生成遥感图像,还可以进行多种图像模态的生成和转换
- 文本驱动的多模态图像生成:根据文本生成不同类型的遥感图像,如近红外图像(NIR)或合成孔径雷达图像(SAR);
- 图像到图像的转换(Image-to-Image Translation):将一种图像(如RGB图像)转换为另一种类型(如SAR、NIR),或者进行图像的超分辨率处理(低分辨率图像转为高分辨率图像)。
7.实验与性能
7.1训练硬件与配置
使用 8块 NVIDIA A100 GPU 进行分布式训练,采用 AdamW 优化器,设置学习率为 0.0001, **批量大小1024,**模型生成图像的尺寸为 256 × 256 像素
7.2渐进式训练策略(Progressive Training Strategy)
为了提升模型生成多样化和高质量遥感图像的能力,训练过程分为两个阶段:
阶段 1:广泛学习阶段
- 数据来源:在完整的 Git-10M 数据集 上训练,利用数据集的广泛多样性学习各种地理特征,包括空间和光谱特性。
- 目标:捕获遥感图像的基础特征,确保模型对多样化场景的泛化能力。
阶段 2:高质量细化阶段
- 数据来源:使用高质量子集进行微调,子集中的样本评分大于 4.8(参考 Fig. 5 的图像质量评估)。
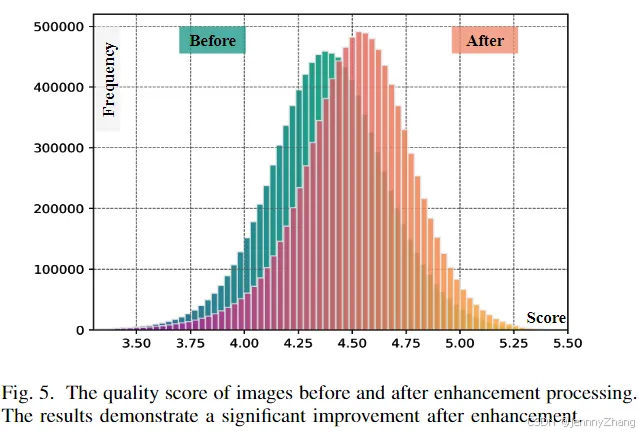
- 目标:提高生成图像的保真度和细节表现,优化模型对高质量遥感场景的生成能力。
- 效果:这种两阶段训练方法结合了数据集的广泛覆盖和高质量样本的细化,既增强了模型的泛化能力,又提升了图像生成的细节和精确性。
7.3评估指标
- LoRA(低秩适应)微调:为了验证 Text2Earth 的基础模型能力,研究团队使用了 LoRA(低秩适应) 技术对模型进行了微调。LoRA 通过引入少量可学习的低秩矩阵,在保持原始模型参数不变的情况下进行高效的迁移学习。
- 在 RSICD 数据集上的验证:FID 降低26.23,Zero-shot Cls-OA 提高20.95%
- FID 改进:使用 Inception-v3 网络 提取图像特征,比较两组图像在共享特征空间中的分布,衡量生成图像与真实图像在感知上的相似性,可以同时反映生成图像的 质量 和 多样性。FID 分数越低,表示生成图像的分布与真实图像的分布越接近,质量和多样性越高。
- Zero-shot Cls-OA 改进:衡量生成图像与文本描述之间的语义一致性,Cls-OA 的高分表示生成图像与文本描述的语义对齐度高,能够有效反映文本的语义信息
- 训练分类模型:使用生成图像和对应的文本描述(来自测试集)训练一个分类模型(例如 ResNet18)
- 零样本分类:将训练好的分类模型应用于真实测试集(该测试集在训练期间未被模型接触)
- 评估语义一致性:通过分类模型的整体准确率(Overall Accuracy, OA)来衡量生成图像与输入文本描述的语义相关性
8.Future work
- 探索Text2Earth的更广泛应用:
- Text2Earth能够理解图像的语义和结构信息,这使得它不仅在图像生成中有优势,还可以扩展到图像增强、目标检测和变化检测等领域。
- 未来的研究可以探讨如何将Text2Earth适应这些领域,扩展其在遥感中的应用。
- 开发自回归生成基础模型:
- 自回归生成模型(如DALL-E和VAR模型)在大数据集的图像生成中表现出色,尤其是在扩展性和表现力上。
- 未来研究可以探索如何使用Git10M数据集训练具有更强表示能力的自回归遥感生成基础模型。这些模型可能在扩展性、性能和捕捉空间-时间依赖性上具有优势。
- 构建大规模、多样化的多模态配对数据集:
- 数据集的规模和多样性是推动生成模型进步的关键因素。目前的数据集主要关注可见光图像和文本的配对,但遥感数据还包含其他重要模态,如SAR、NIR和高光谱图像,这些模态有独特的物理特性和应用场景。
- 未来的工作可以致力于构建涵盖更广泛配对模态的大规模遥感数据集,推动跨模态生成任务的深入研究,同时促进遥感领域的多模态学习。


















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









