







"我的NVIDIA开发者之旅” | 征文活动进行中.......
以下验证的步骤只适用于CUDAFULL的安装。
前言:
常用windows系统炼丹的同学可能会知道很容易查看自己的CUDA(深度学习)环境是否准备好使用ncvv -V命令即可,那如果是在Linux系统上呢,博主是一个大二小白,今年才拿到了导师的linux GPU服务器,这时候该怎么查看相关环境是否搭建好呢,经过一番学习,我总结了一下知识,分享给大家,希望能帮助到大家啦。
1.首先可以通过查看以下内容验证驱动程序的版本
cat /proc/driver/nvidia/versionLinux:

2.或者是验证CUDA Toolkit的版本
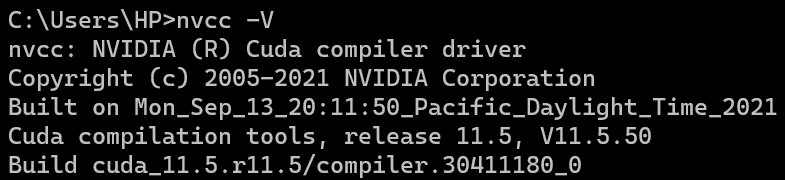
nvcc -VWindows:
3.Linux系统还可以通过编译样本和执行deviceQuery或bandwidthTest程序,验证运行中的CUDA GPU作业。
编译样本:
Ubuntu:
cd ~/
apt-get install cuda-samples-9-0
cd /usr/local/cuda-9.0/samples
make-
运行deviceQuery样本
./bin/ppc64le/linux/release/deviceQuery ./bin/x86_64/linux/release/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1050"
CUDA Driver Version / Runtime Version 9.0 / 9.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 4041 MBytes (4237426688 bytes)
( 5) Multiprocessors, (128) CUDA Cores/MP: 640 CUDA Cores
GPU Max Clock rate: 1493 MHz (1.49 GHz)
Memory Clock rate: 3504 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.0, CUDA Runtime Version = 9.0, NumDevs = 1
Result = PASS-
运行bandwidthTest样本
./bin/x86_64/linux/release/bandwidthTest[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce GTX 1050
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12305.7
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 11576.2
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 94879.0
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











