







简介
从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢。针对这种情况下的单机多卡训练,MegEngine中实现了更快的集合通信算法,对多个不同的网络训练相对于NCCL有3%到10%的加速效果
MegEngine v1.5 版本,可以手动切换集合通信后端为 shm(默认是 nccl),只需要改一个参数。(由于 shm 模式对 CPU 有额外的占用,且只有在特定卡下才能提高效率,因此并没有默认打开)
gm = GradManager()
gm.attach(model.parameters(),
callbacks = [dist.make_allreduce_cb("sum", backend="shm")])
目前只实现了单机版本,多机暂不支持
背景
在大规模训练中,数据并行是最简单最常见的训练方式,每张卡运行完全一样的网络结构,然后加上参数同步就可以了。
对于数据并行的参数同步,目前有两种常用的方法,Parameter Server 和 Gradient AllReduce:
- Parameter Server 方案需要额外机器作为参数服务器来更新参数,而且中心式的通讯方式对带宽的压力很大,增加训练机器的同时通信量也线性增加;
- AllReduce 方案只是参与训练的机器之间互相同步参数,不需要额外的机器,可扩展性好。
MegEngine 目前也是使用 AllReduce 方案作为数据并行的参数同步方案。而在AllReduce方案中,大家目前常用的是 NCCL,Nvidia 自家写的 GPU 集合通讯库,通信效率很高。
看到这里,可以得到一个结论,数据并行的情况,用 NCCL 通讯库能达到不错的效果。
到这里就结束了?当然不是,在 2080Ti 8卡训练的情况下,在多个网络下,我们相对 NCCL 有 3% 到 10% 的性能提升。(以 2080Ti 为例子是因为游戏卡不支持 P2P 通信,相对来说通信较慢,通信时间长,节省通信时间能获得的收益较大)
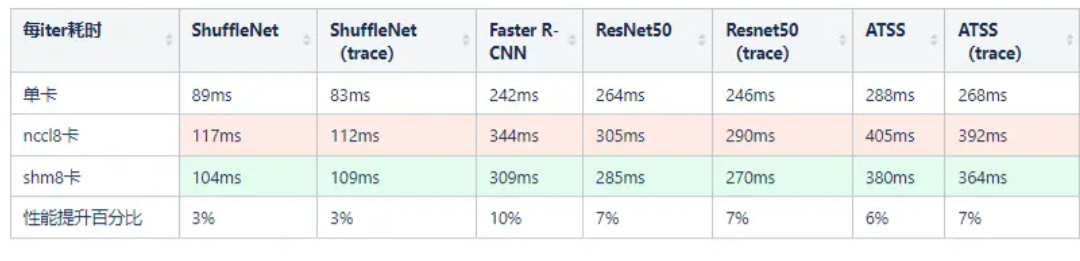
这是怎么做到的呢,我们一步一步来分析(以下数据都是用 megengine.utils.profiler 导出,相关文档在 profiler文档)。
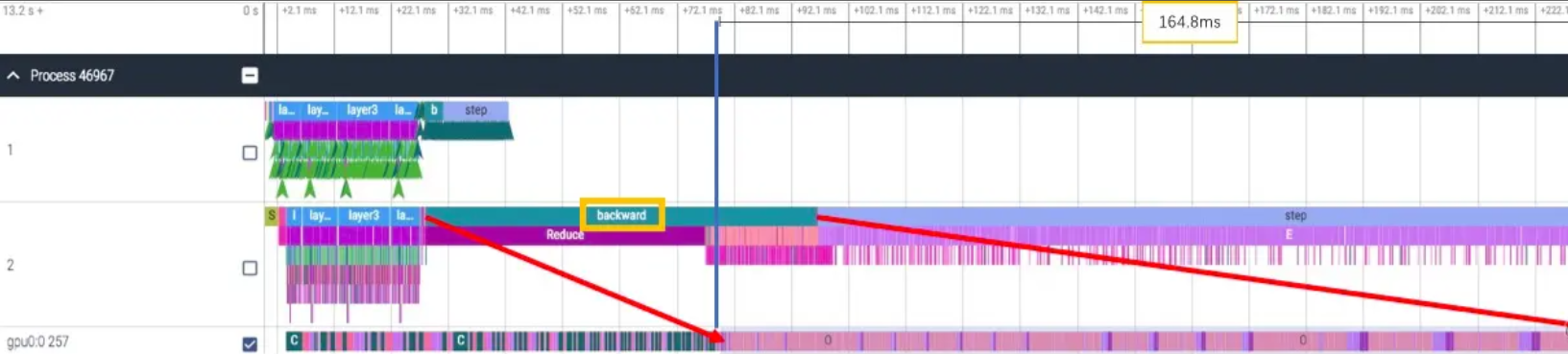
通常我们是在 backward 阶段同时做 gradient 的同步,我们来看单卡的 backward耗时,只有 164ms:
再来看 8 卡训练时 backward 的耗时,增长到了 203ms,比单卡的情况下多了 39ms:
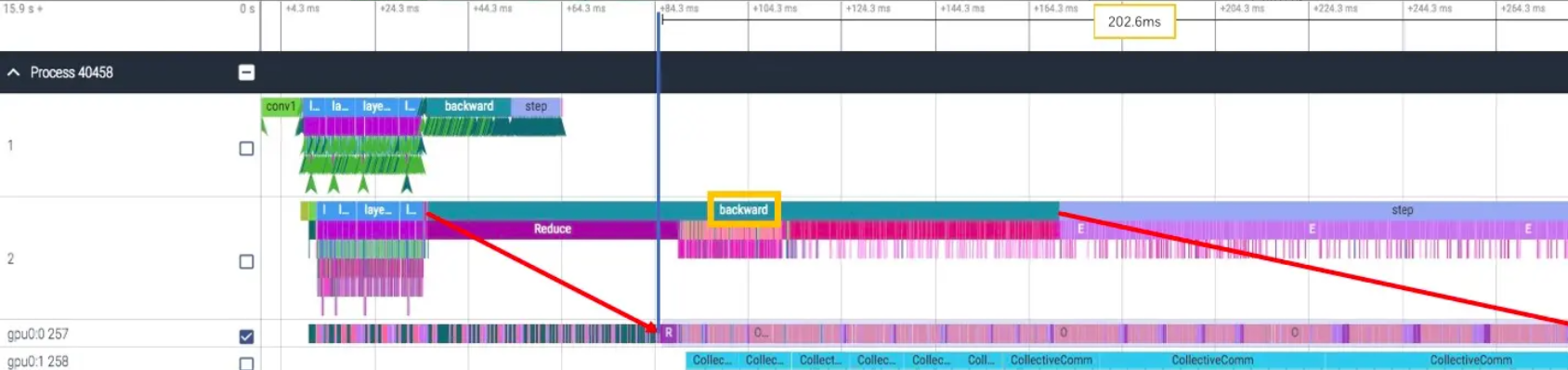
确实,backward 时间变长了不少,可是为什么?我们有没有可能消除它?
1)为什么
一句话:NCCL AllReduce 占用了 cuda 计算资源,所以计算变慢。
具体原因是 NCCL AllReduce 对应的 cuda kernel 需要既做通信又做计算,所以占用了计算对应需要的计算资源,但是大部分时间都花在了通信上,导致计算资源的利用率不够高。
2)能不能消除它
当然是可以的,cuda 计算和通信是可以并行的,让计算和通信运行在两个不同的 cuda stream 上,就可以并行起来,这一点在 cuda 开发者文档中有提到。
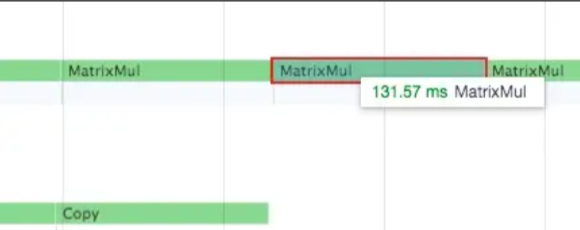
3)实际测试计算和通信并行的例子
stream0 进行矩阵乘法运算,stream1 进行拷贝,前后矩阵乘法的速度没有受到影响:


实现思路
这里先介绍一下 AllReduce 的两种实现方法。
1)ReduceScatter + AllGather

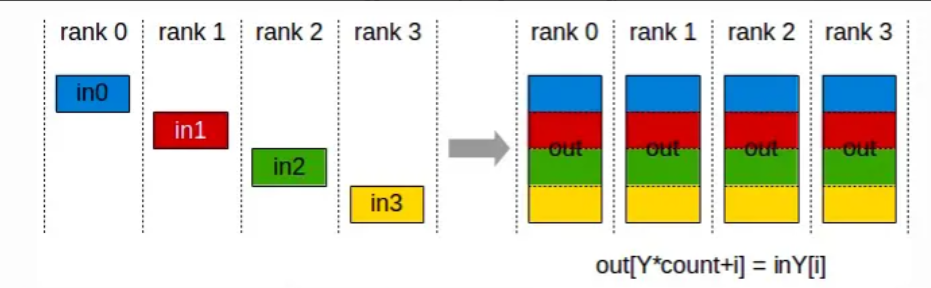
Ring AllReduce 就是用的 ReduceScatter + AllGather 的模式:首先第一轮通信在各个节点上计算出部分和,然后第二轮通信把部分和聚集一下得到最终结果。
2)Reduce + Broadcast
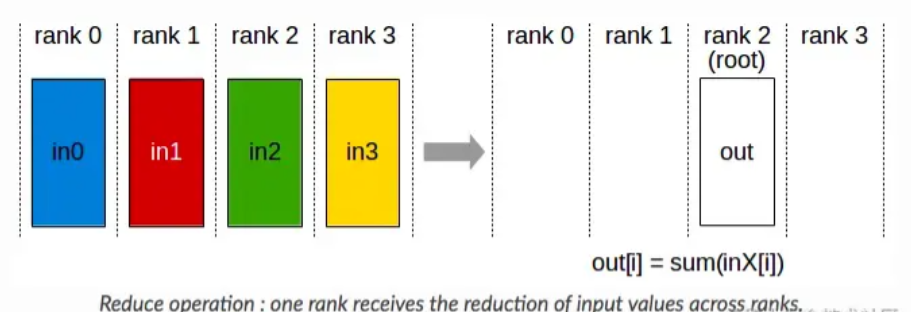
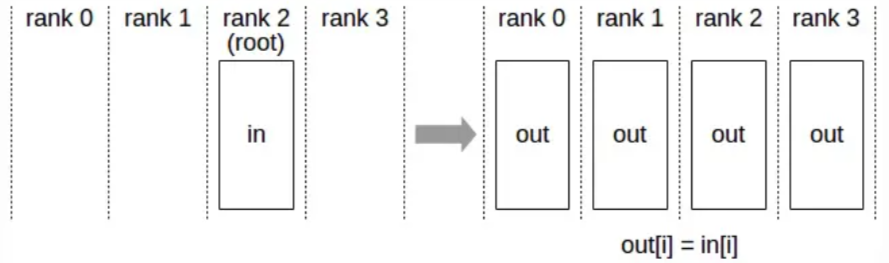
Reduce + Broadcast 的方式像 Parameter Server,会先在一个节点计算出完整的累加和,然后再广播到各个节点上。
新的算法采用的是 Reduce + Broadcast 的方法,首先将数据全部拷贝到 cpu(使用 Shared Memory),然后由 cpu 进行累加,再拷贝回 gpu。
由于直接拷贝累加没有把计算和通信 overlap 起来,我们还采用了类似 Ring AllReduce 的分块策略,让通信和计算充分 overlap,如下图所示。
因为用到了 Shared Memory,所以把这个后端简称为 SHM。
实现效果
1)算子性能
相对 NCCL 来说,SHM 的延迟稍微高了一些,带宽低了一些,数据大一些的情况可以达到 NCCL 的 90% 左右的性能。
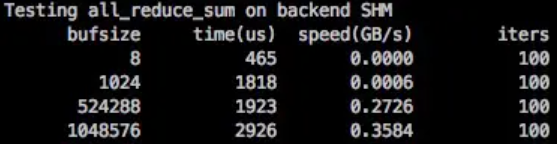
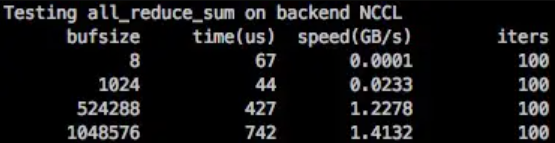
SHM 性能需要在数据包大的情况发挥,和 ParamPack 策略搭配能最大发挥 SHM 的作用(在 MegEngine 中 distributed.make_allreduce_cb 中使用了 ParamPack 策略, 默认打包大小为 10M)。ParamPack 策略是指将参数对应的梯度打包进行发送,减少小包发送,以减少通信延迟增加带宽利用率。
2)实际训练效果
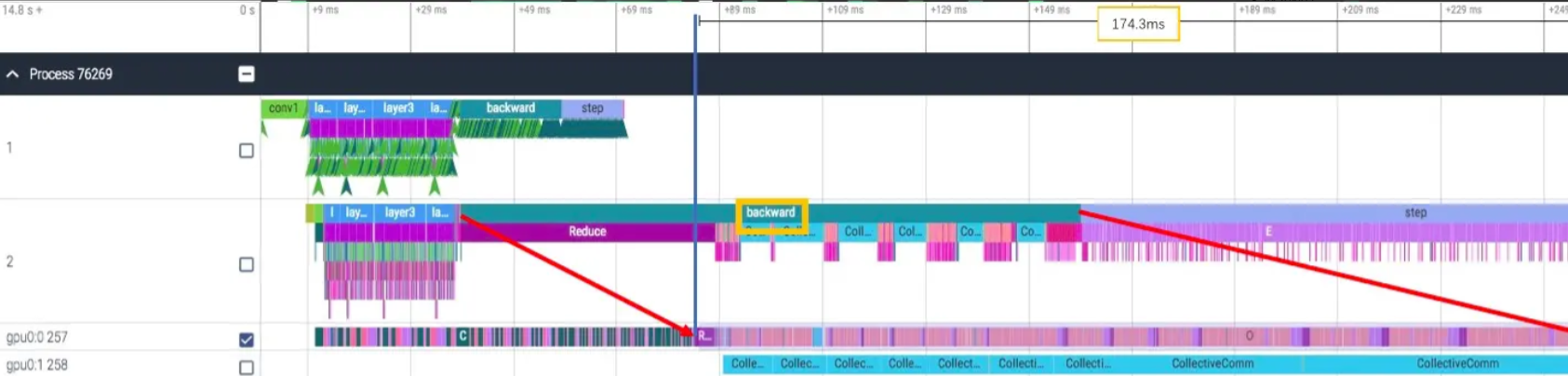
继续使用 ResNet50 8卡训练的例子,SHM 与 NCCL 相比,backward 时间快了近 30ms(203ms->174ms)。
3)Shared Memory AllReduce 的不足之处/后续改进
1)cpu 占用多
因为占用了 cpu 资源做 reduce 运算,所以在 cpu 资源紧张的情况下会比较慢,需要确定 cpu 资源是否够用再进行使用。
2)额外通信成本
因为 copy 和 reduce 之间有数据依赖关系,copy需要等待上一次的reduce完成才能开始,reduce要等待copy数据就位才能开始,所以中间插入了信号量的同步,引入了额外的通信成本,在分块越多的情况越明显。
3)多进程负载均衡
各个进程的 copy 和 reduce 速度不一致导致了进度不同步的问题,会造成多余的等待时间,根据实际运行速度进行分配任务性能会有进一步的提升。
4)更多的 overlap
目前只用到了 copy 和 reduce 之间的 overlap,但是其实 h2d 和 d2h 拷贝也是可以 overlap 起来的,可以有进一步加速。















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











