







k-means
一、k-means :无监督分类
聚类和分类:
聚类是一种无监督学习方法,其目标是将数据样本分成不同的组,使得同一组内的样本彼此相似,而不同组之间的样本差异较大。聚类算法根据数据点之间的相似性或距离,将它们分配到不同的聚类簇中。聚类算法不需要先验标签或类别信息,而是根据数据本身的特征进行分组。聚类可以帮助发现数据的内在结构、相似性和模式,对于数据探索、分割和预处理等任务非常有用。
分类是一种有监督学习方法,它使用已有的标签或类别信息来训练模型,并预测新的未知数据点所属的类别。分类任务的目标是学习一个模型,能够将输入数据映射到预定义的类别中。分类算法需要有已知的标签或类别信息作为训练数据,并根据这些标签来学习分类规则或决策边界。常见的分类算法包括决策树、支持向量机和神经网络等。
聚类常用于数据探索、分割和预处理等任务,有助于发现数据的相似性和群组结构;分类常用于预测和判别任务,对新的未知数据进行分类。
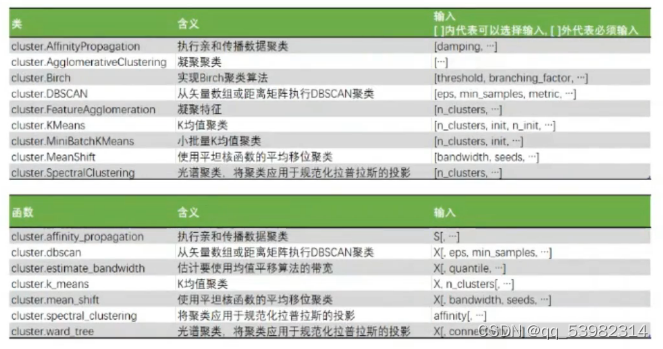
1.sklearn中的聚类算法
两种表现形式:类和函数
-
对于k-means:
簇:同一簇就是一类
质心:一簇数据的横纵坐标的平均值
过程:随机抽取k个样本作为最初质心;开始循环:每个样本点分配到离他最近的质心,生成k簇;对于每个簇计算新的质心,当质心位置不再发生改变时,聚类完成。 -
样本到质心的距离的度量:

n表示特征数目,例如,二维数据的x,y,则n=2;x表示样本点,u表示质心。
如果k-means采用欧几里得距离,所有样本点的距离之和是:
前者是簇内平方和,后者是整平方和。k-means追求的是簇内平方和最小的质心。这是k-means的模型评估指标,而不是损失函数。
1.1 sklearn.cluster.K-means
代码:
- 创建一个数据集:
from sklean.datasets import make_blobs as mb
import matplotlib.pyplot as pt
x,y=mb(n_samples=500,n_features=2,centers=4,random_sate=1)
print(x.shape)
fig,ax1=pt.subplots 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









