







目录
scikit-learn库函数实现
代码部分:
import seaborn as sns
from sklearn.model_selection import train_test_split #导入切分训练集、测试集模块
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
df = pd.read_csv('breastCancer.csv')# 导入训练集
df.head() # 查看数据集前五行
X1=df.iloc[:,df.columns!="Class"] # 选择所有行和列,但排除type的那一列
X=X1.iloc[:,1:]
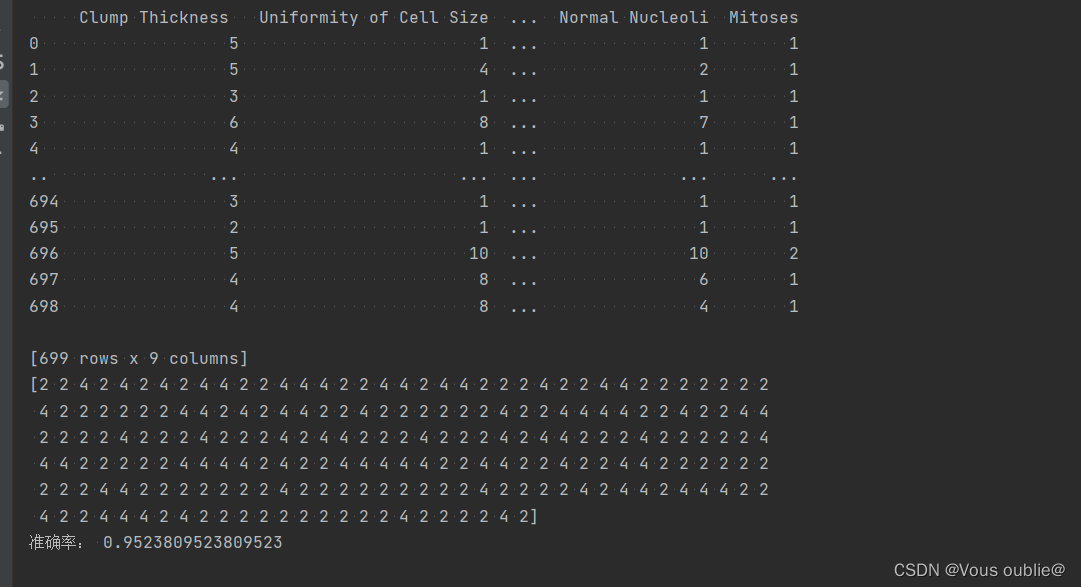
print(X)
y=df['Class'] # 将Class列作为预测值
# # 划分数据集
X_train, X_valid, y_train, y_valid = train_test_split(X, y,test_size = 0.3,random_state=0)
def model():
knn = KNeighborsClassifier(8) #实例化KNN模型
knn.fit(X_train, y_train) #放入训练数据进行训练
print(knn.predict(X_valid)) #打印预测内容
# print(y_valid) #实际标签
print("准确率:",knn.score(X_valid, y_valid))
return knn
def show():
prediction=model().predict(X_valid)
plt.figure(figsize=(10, 7))
cm = confusion_matrix(y_valid, prediction)
ax = sns.heatmap(cm, annot=True, fmt="d", cmap='Blues')
plt.ylabel('Actual label') # x轴标题
plt.xlabel('Predicted label') # y轴标题
plt.show()
if __name__ == '__main__':
show()
最后结果:
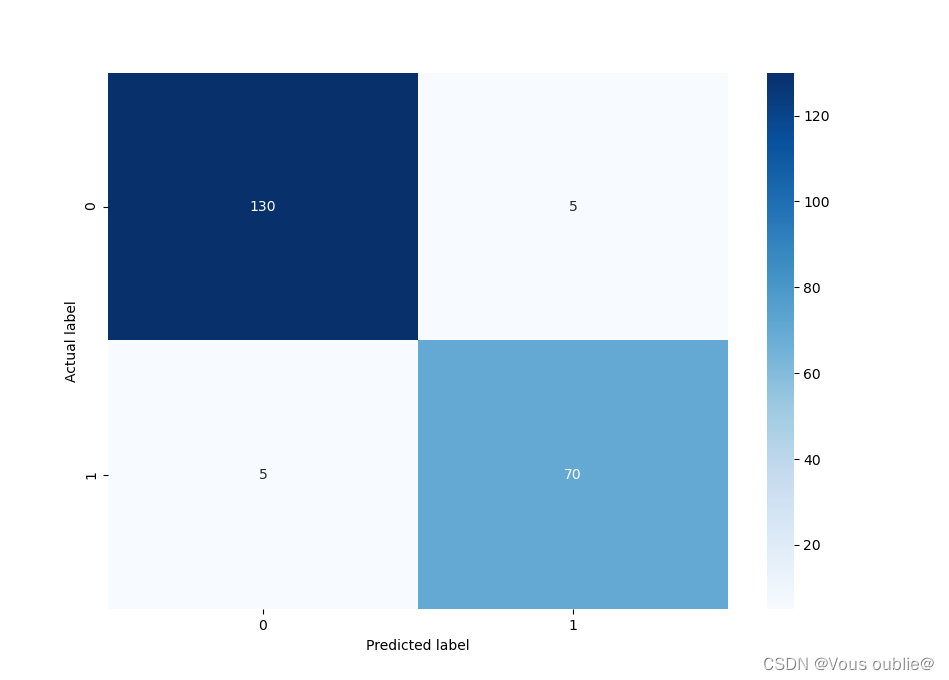
在对最后数据进行展现的时候只用了一个混淆矩阵进行显示,个人觉得没有很好进行数据对比和展现,由于比较懒,也就没有进行优化和更改,希望谅解,最后的准确率还是比较高的。
自编函数
代码部分:
import numpy as np
import operator
import pandas as pd
def createDataSet():
# group - 数据集
# labels - 分类标签
df = pd.read_csv('breastCancer.csv')# 导入训练集
group_01=df.iloc[:,df.columns!="Class"] # 选择所有行和列,但排除type的那一列
group=group_01.iloc[:,1:] # 由于第一行是编码数字,与预测分类没有关系,就直接去掉了
labels=df['Class'] # 将Class列作为预测值
# # 划分数据集
return group,labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndices = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndices[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group,labels=createDataSet()
group_01=np.array(group)
labels=np.array(labels)
test=np.array(group.iloc[:5,:]).tolist() #转为列表
print("测试集",test)
# kNN分类
results=[] # 预测的结果
for i in test:
test_class = classify0(i, group, labels, 3)
# 打印分类结果
results.append(test_class)
print(results)
# 最终得到最后的预测结果最后结果:

原本想再创建一个show()函数,来对最后预测数据进行一个可视化处理同时与原始数据进行对比的,但是由于期末月的原因,暂时没有时间来进行修改,就只是打印了一下最后的预测结果,测试集也就只是在原始数据集上截取前面5行来进行测试,最后结果还是不错的。
最后,代码中还有很多需要修改和优化的地方,希望大家谅解,同时也希望大家提出不足之处,数据的话可以在在评论区说一下我发给你,谢谢大家!
















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











