







摘要
本周主要学习了Transformer。学习了Self-Attention的基本原理与具体过程;学习了一种叫做“多头”注意力(“multi-headed” attention)的机制,进一步完善了自注意力层;为了解决在Self-Attention中词的顺序信息是不重要的问题,而提出Position Encoding操作;重点是Transformer的整体架构,Transformer采用了Encoder-Decoder框架,以机器翻译为具体实例做了过程讲解;最后学习一些训练模型的tips。
Abstract
This week, the main focus of the study was on Transformer. The basic principles and specific processes of Self-Attention were learned. A mechanism called “multi-headed” attention was also explored to further enhance the self-attention layer. To address the issue of the non-importance of word order information in Self-Attention, Position Encoding was introduced. The emphasis was on the overall architecture of Transformer, which adopts the Encoder-Decoder framework, and a step-by-step explanation was provided using machine translation as a specific example. Lastly, some tips for training models were learned.
1.Seq2Seq和transformer的关系
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。它的输入是一个序列,输出也是一个序列。
Transformer是一个用于解决Seq2Seq问题的模型,用来解决输出长度不确定的问题;是一个利用自注意力机制来提高模型训练速度的深度学习模型;它可以并行化计算;它本身模型的复杂程度较高;它在精度和性能上都要高于之前流行的RNN循环神经网络。下图是seq2seq一般架构和transformer原论文架构。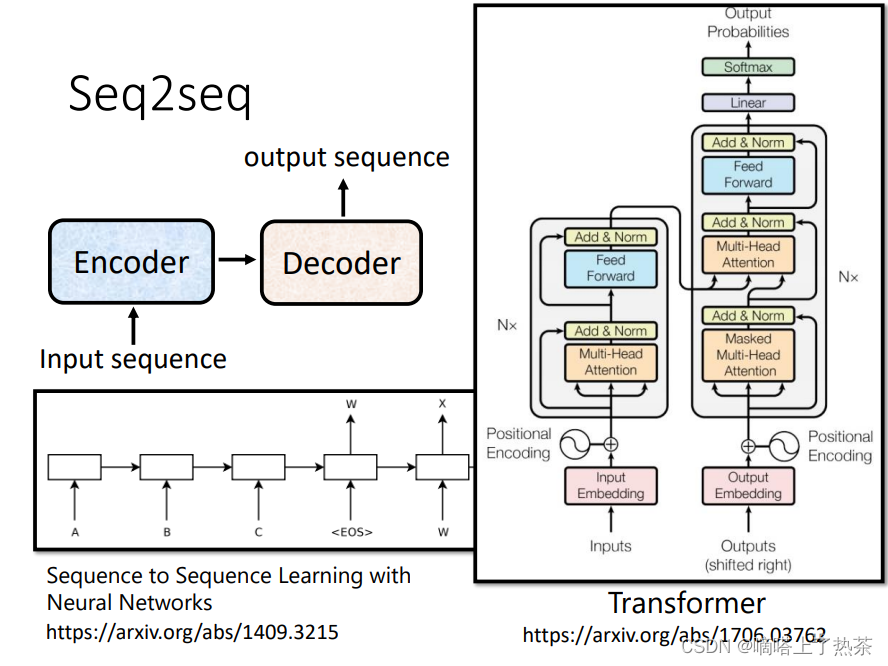
2.Self-Attention
Attention:
传统的Attention机制发生在Target的元素和Source中的所有元素之间。
简单讲就是说Attention机制中的权重的计算需要Target来参与。即在Encoder-Decoder 模型中,Attention权值的计算不仅需要Encoder中的隐状态而且还需要Decoder中的隐状态。
Self-Attention:
不是输入语句和输出语句之间的Attention机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的Attention机制。
例如在Transformer中在计算权重参数时,将文字向量转成对应的KQV,只需要在Source处进行对应的矩阵操作,用不到Target中的信息。
引入自注意力机制的目的:
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译问题(序列到序列的问题,机器自己决定多少个标签),词性标注问题(一个向量对应一个标签),语义分析问题(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
2.1 原理和架构
第一步:
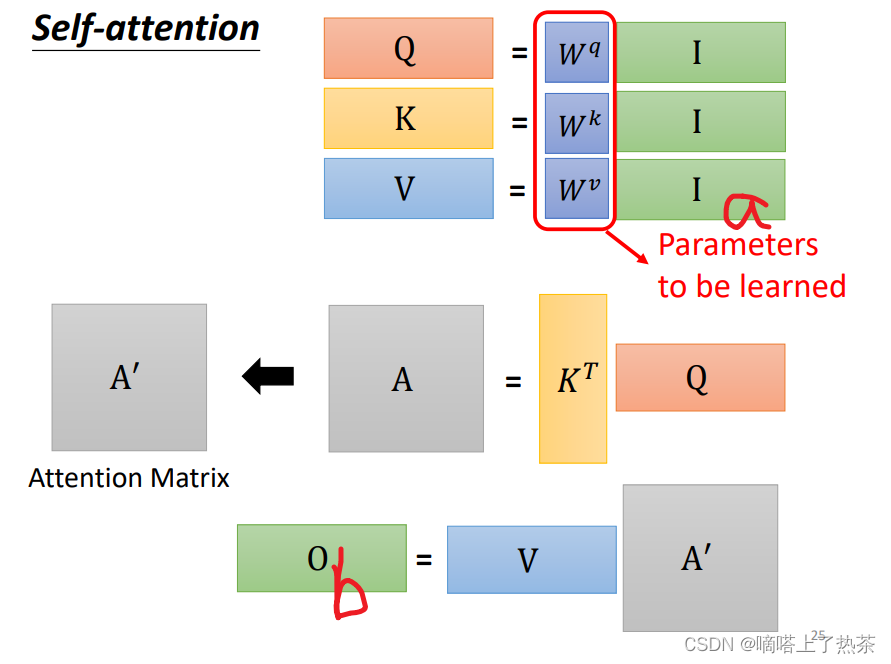
输入sequence a1~a4,丢入Self-attention,每一个输入都分别乘上三个不同的transformation matrix,产生三个不同的vector q,k,v。其中vector q,k,v分别代表:(如下图:)
q代表query,用来match其他人
k代表key,用来被query匹配的
v代表要被抽取出来的information
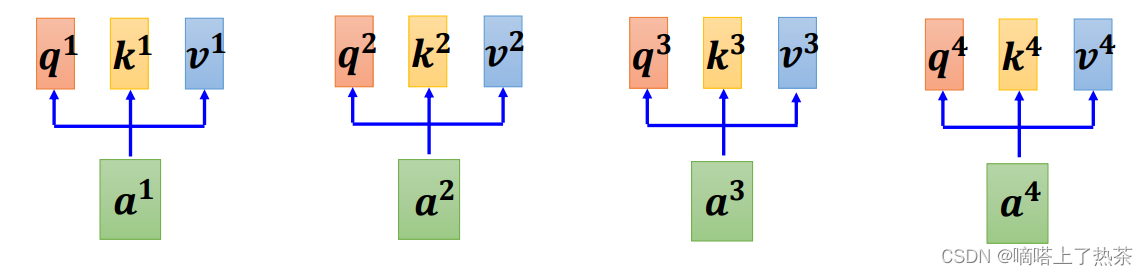
第二步:
拿每个query q去对每个key k 做attention,我们这里用到的计算attention的方法是dot-product Attention ,attention本质就是输入两个向量,输出一个分数。(做attention的方法有很多)
第三步:
将得到的a11-a14通过一个softmax函数得到一个新的α11-a14,然后用变形α11-a14分别乘以Vi 然后求和计算得到b1,如下图:
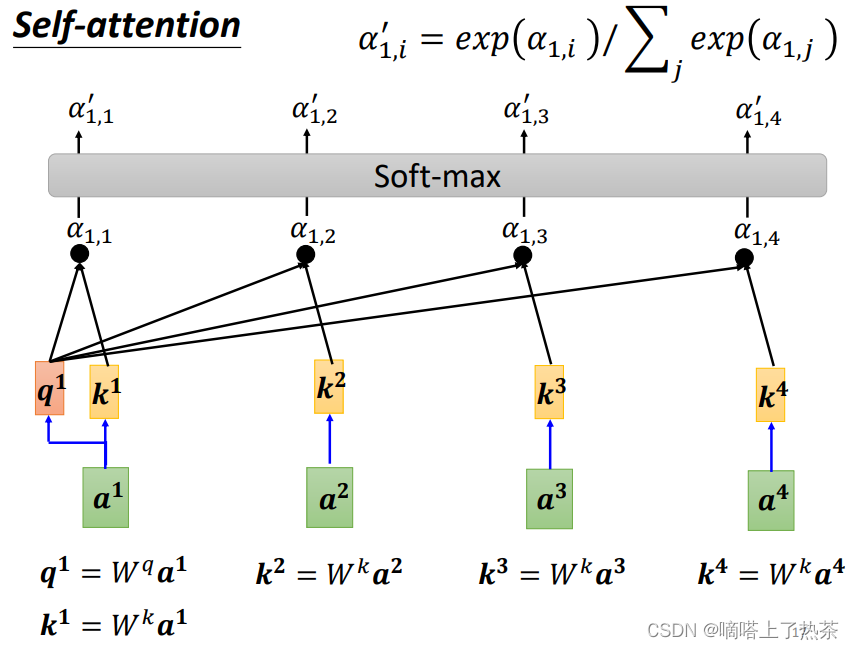
注:也可以使用其他的函数,不一定非要使用softmax。
下图是计算b1的过程,考虑了全部的input:
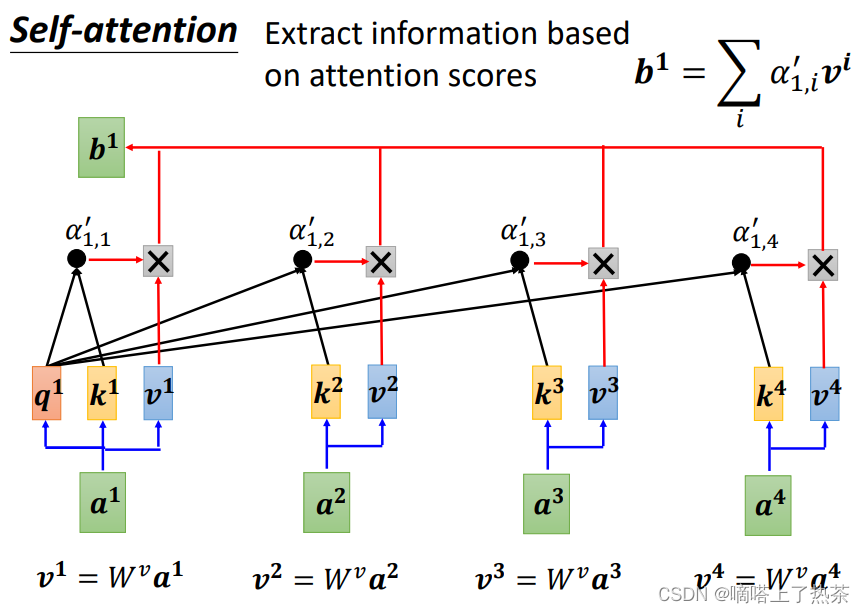
同理也可计算出b2,b3,b4,如下图:
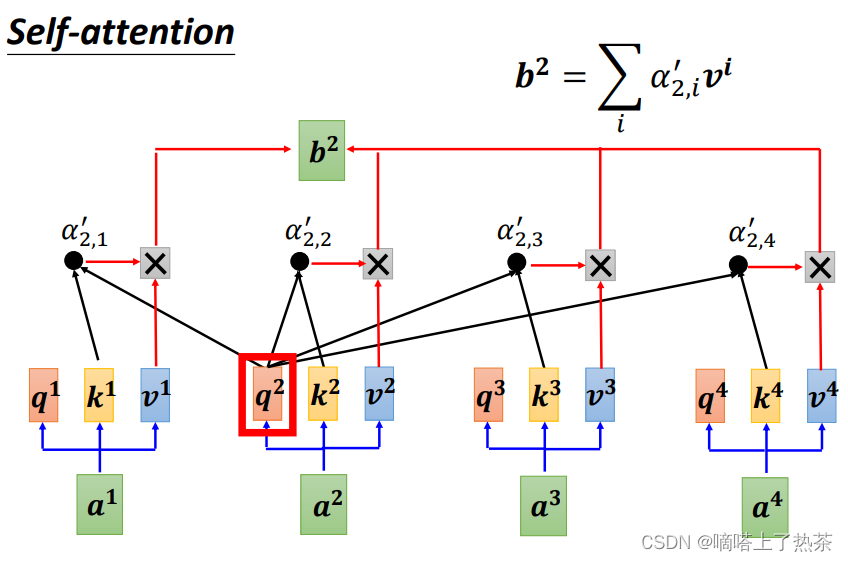
注意这里的b1-b4在实际运算中是同时计算出来的
2.2 矩阵运算(平行计算)
把4个输入a拼成一个矩阵I,这个矩阵有4个column,也就是a1到a4,I乘上相应的权重矩阵W,得到相应的矩阵Q、K、V,分别表示query,key和value,这里的权重矩阵Wq、k、v都是需要机器自己学习得到的。下图是对应的矩阵形式:
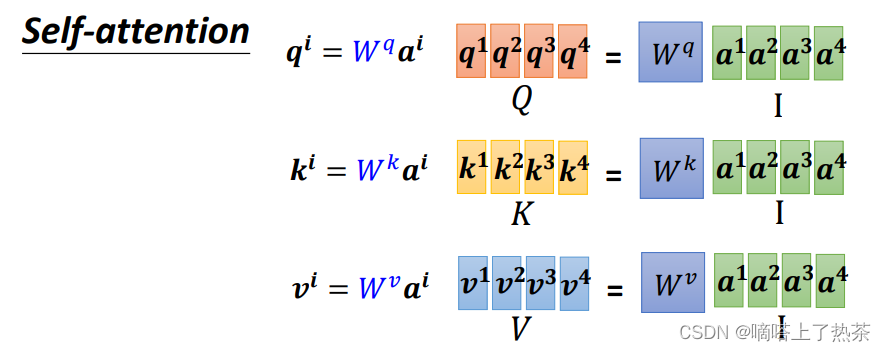
利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α, α的计算方法有多种,通常采用点乘的方式。
先针对q1,通过与k1到k4拼接成的矩阵K相乘,得到α的矩阵。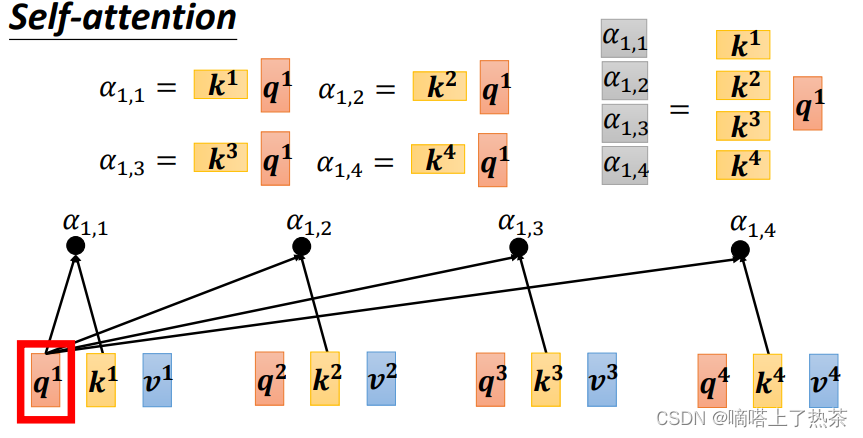
同理针对q2、q3、q4也可以使用相同的矩阵乘法得到,综合一下使用矩阵表示运算过程,如下图:
最后再将其乘以Vi矩阵,得到最终的b1-b4,如下图:
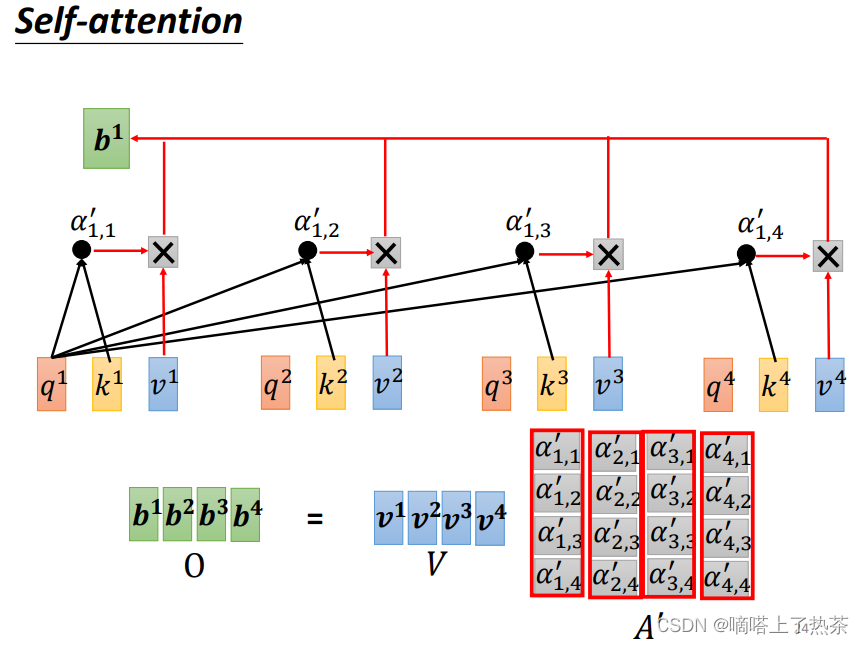
综合以上步骤,简单进行一下梳理,从输入到输出的所有矩阵运算,如下图:
2.3 Multi-headed-Attention
上节讲述的是输入之间只有一种关联信息时的自注意力机制,现在来看一下多种关联关系的自注意力机制,其实本质上与上节的无太大区别,各自计算各自的关联信息,如下图所示,下图是两种关联信息的情况下,应该如何计算。
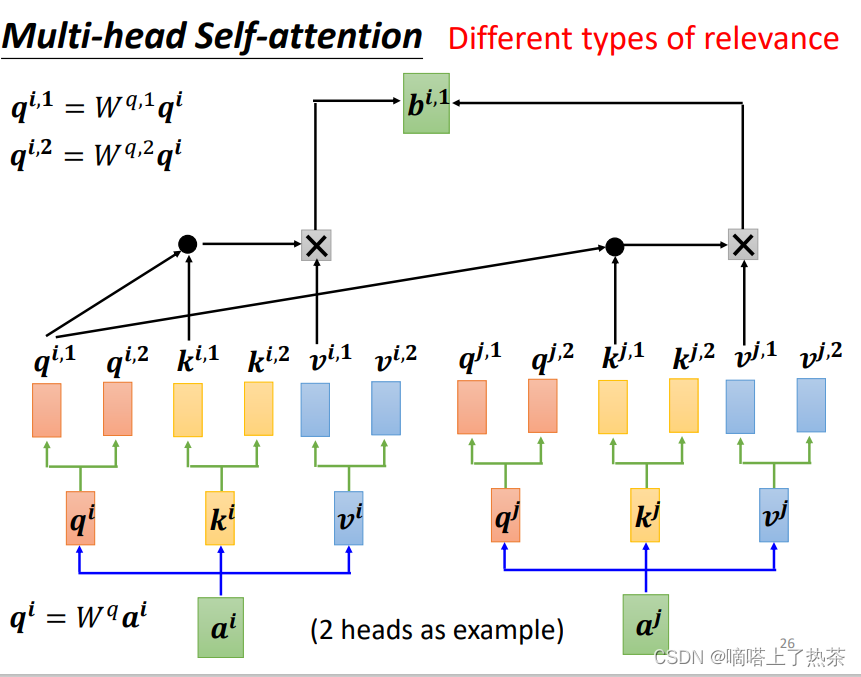
计算出bi,1之后,再将其乘以一个transform martix,得到最终的bi,如下图所所示:
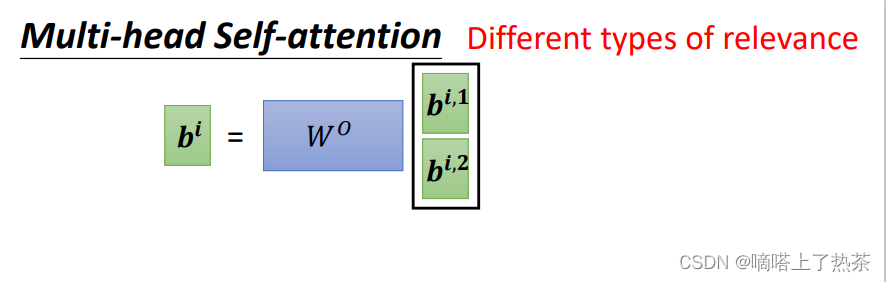
注意:这里的W0也是需要机器机自己学习的
2.4 Position Encoding
在训练self attention的时候,实际上对于位置的信息是缺失的,没有前后的区别,上面讲的a1,a2,a3不代表输入的顺序,只是指输入的向量数量,不像rnn,对于输入有明显的前后顺序,比如在翻译任务里面,对于“机器学习”,机器学习依次输入。而self-attention的输入是同时输入,输出也是同时产生然后输出的。
如何在Self-Attention里面体现位置信息呢? 就是使用Positional Encoding,也就是新引入了一个位置向量ei,这个向量一般都是one-hot,如下图: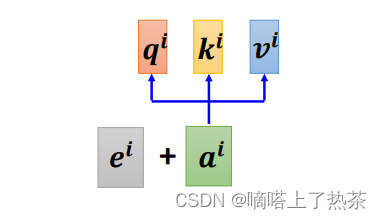
每一个位置设置一个vector,叫做positional vector,用ei
表示,不同的位置有一个专属的ei。
如果ai加上了ei,就会体现出位置的信息,i是多少,位置就是多少。
vector长度是人为设定的,也可以从数据中训练出来。
3.transformer
前面说过,Transormer属于Seq2Seq模型的一种,所以其也是Encoder-Decoder的结构。
3.1 transformer架构
先看一下transformer的整体架构,如下图:
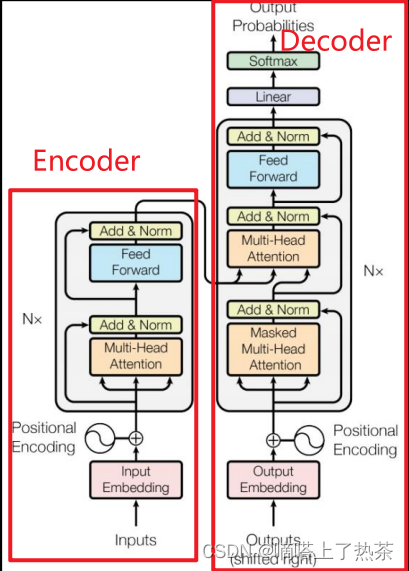
3.2 Encoder
输入一个向量,输出一个同样长度的向量,如下图所示:
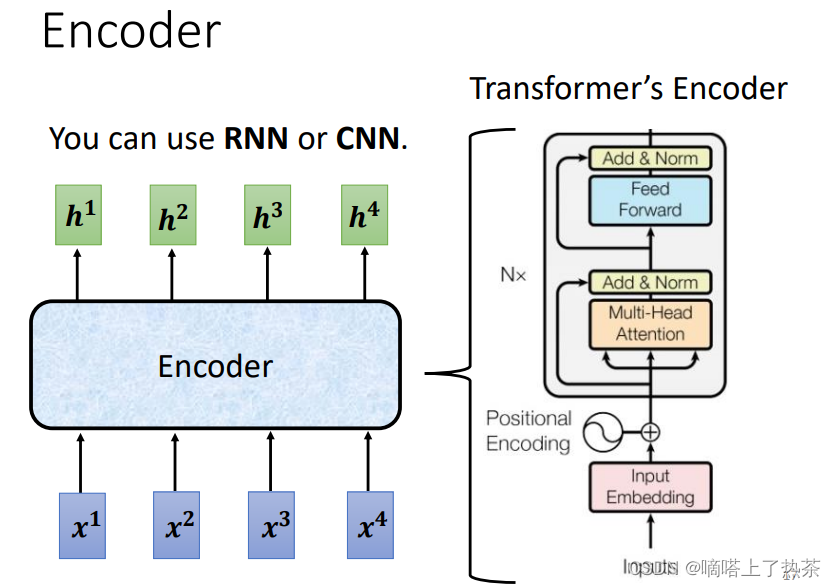
输入和输出之间有很多个Block,每个Block里面一般有好几层,例如下图所示,输入先通过一层Self-Attention收集自身咨询,然后再通过全连接层进行特征提取,如下图所示:
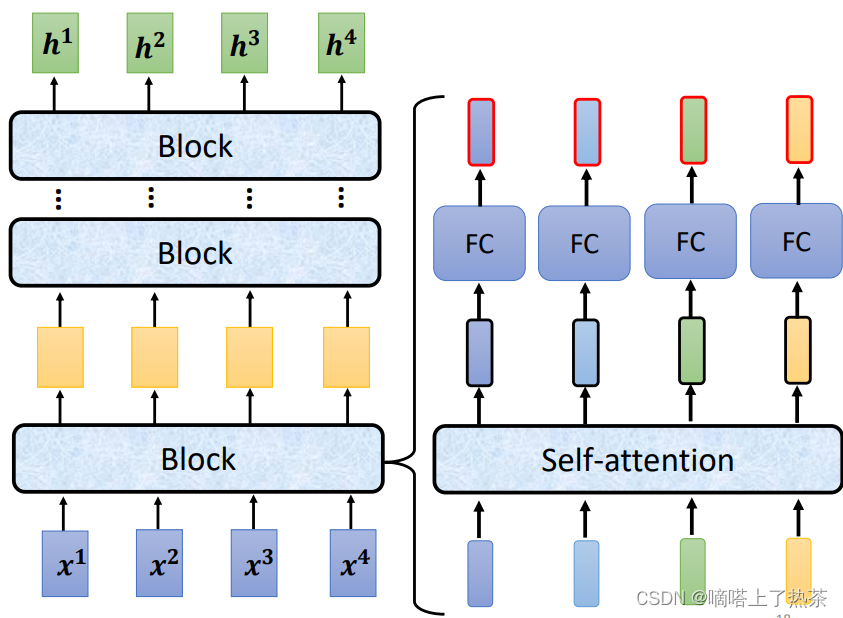
这里的Self-Attention地输出还会加上其本身,这被称为Residual Connection,残差连接,主要为了缓解梯度弥散和梯度爆炸的问题。然后a+b的结果会进行Layer Normalization,最终得到输出。
在全连接层也是一样,用到了残差连接和层标准化。如下图所示:
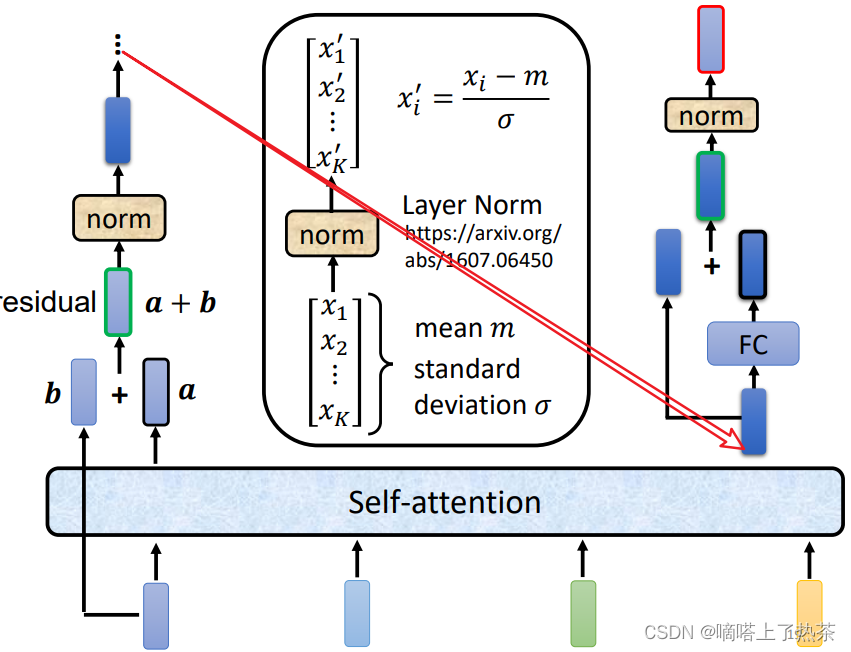
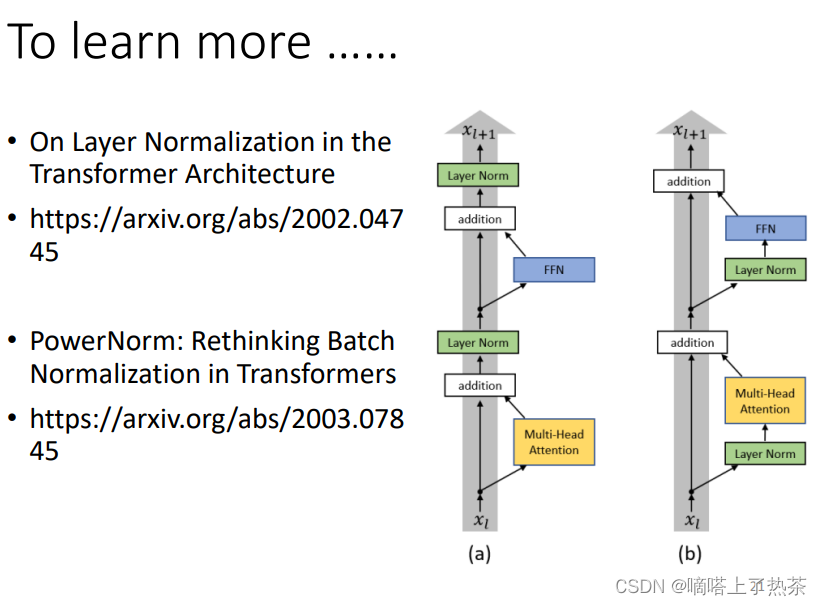
关于Encoder的设计不一定要局限于上面的结构(非要先残差链接在标准化),有人做了研究,如果把层标准化放在addition之前效果会更好,如下图所示。
3.3 Decoder
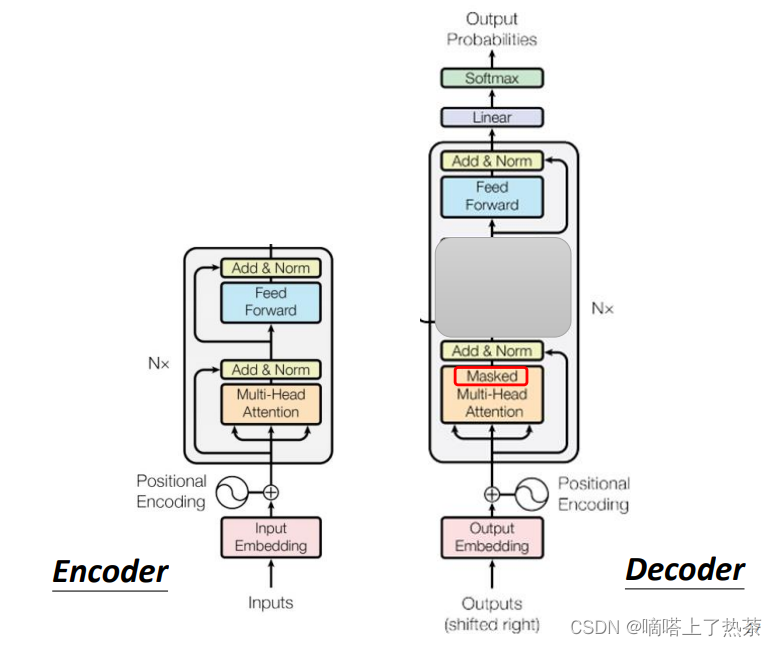
Decoder和Encoder有些相似,如果遮盖住Cross Attention部分,transformer的Encoder和Decoder的对比如下图所示。
3.3.1 Masked Multi-Head Attention
在Decoder中自注意力机制,只考虑左边的的输入的信息(关系),例如语音辨识,只考虑一个词前面的词,如下图就是一个Masked Multi-Head Attention的关系。

这里b1只考虑a1的信息,b2只考虑a1,a2的信息,以此类推…
为什么Decoder要用Masked Self-Attention呢?这是因为Decoder在运作的时候,是依靠前面的输出,作为当前输入的,也就是说,在当前时刻,Decoder没有办法知道后面的咨询,所以就使用了Masked Self-Attention
3.3.2 Cross Attention
Cross Attention是Encoder和Decoder之间的桥梁,Corss Attention接受encoder的输出,并将其和Decoder的Self-attention (Mask)的输出结果进行运算,具体如何运作请看下图:
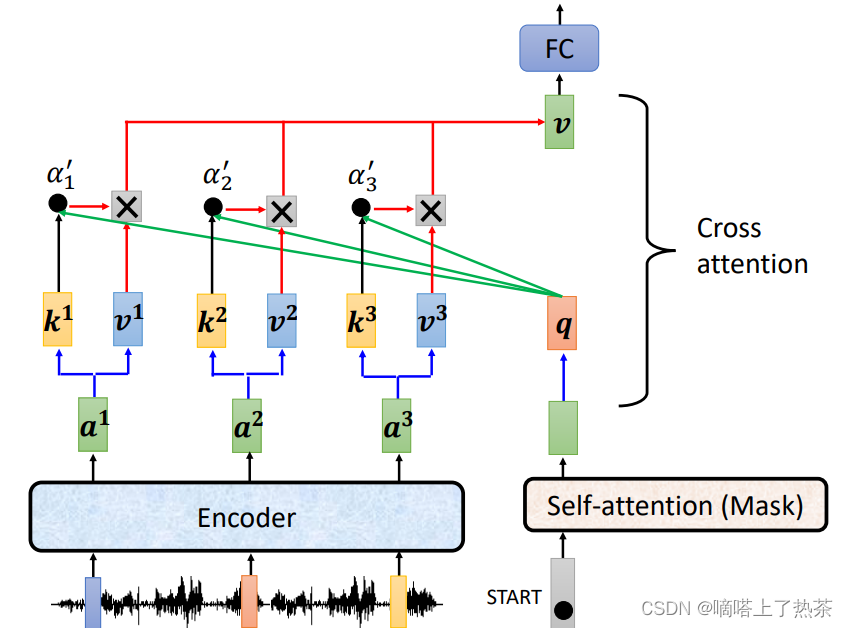
在计算Attention的时候,Q来自Decoder,K和V来自Encoder,然后进行Attention的计算,这被称为是Cross Attention
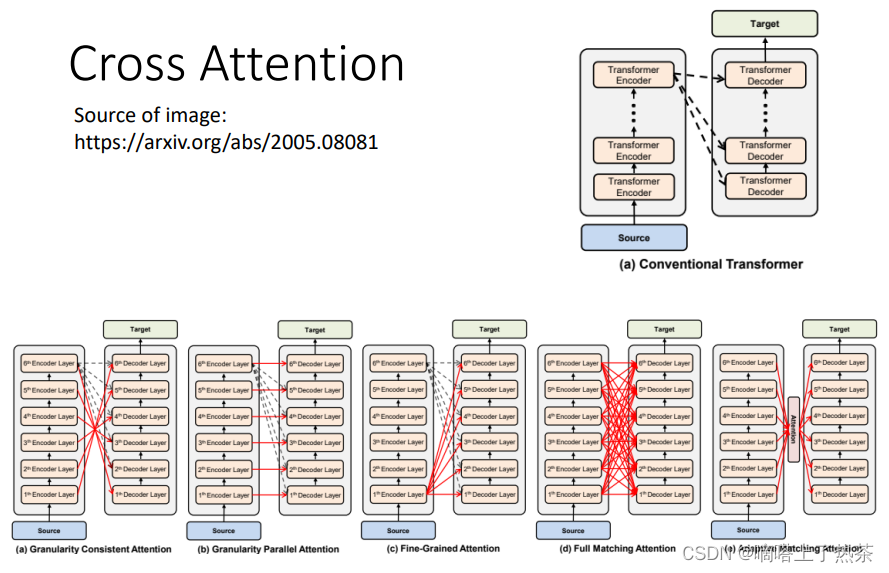
在原始论文中,Cross Attention是拿Encoder最后一层进行Cross的,但是一定要拿Encoder最后一层吗?不一定,可以尝试各种各样的Cross方式,这都是可以研究的课题。如下图是各式各样的Cross Attention连接方式:
3.4 Autoregressive(AT)V.S. Non-Autoregressive(NAT)
Autoregressive(AT)
输入begin token 开始,然后得到一个output,在输入一个 token(上次得到output结果),然后得到另外一个output,运作机制是一个一个输入,一个一个产生结果。如何终止?当output得到一个事先定义好的结束字符,输出就结束。如下图所示,是一个Autoregressive的架构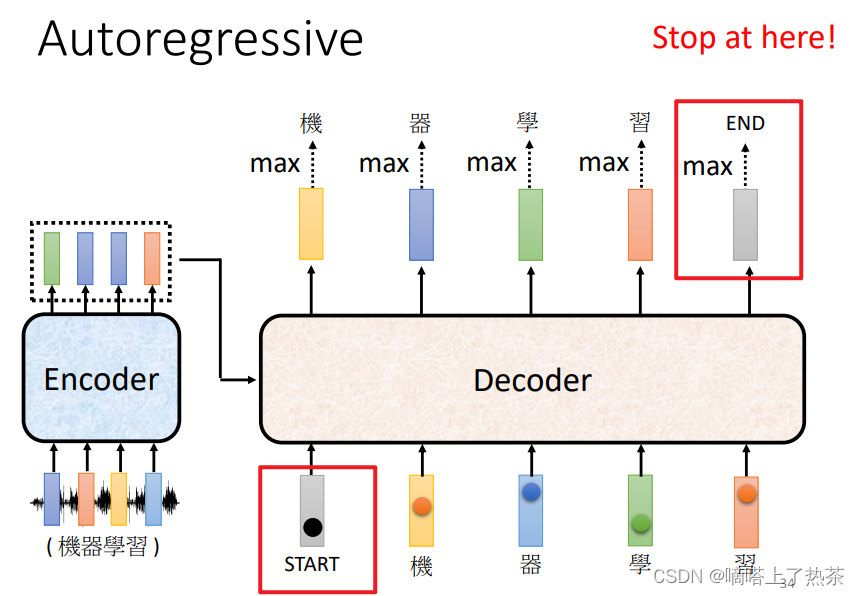
。
Non-Autoregressive(NAT)
直接输入一排begin token,直接得到所要的结果。如何确定输入的begin token个数?1.可以训练一个专门确定begin token个数的classifier ,使用encoder的output。2.也可以使用大量的begin token 直接扔进decoder得到output,在output中寻找终止字符,保留左边的,舍弃右边的。如下图所示,是一个简单的Non-Autoregressive架构。
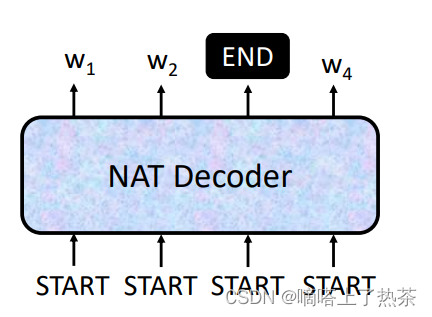
注意:使用第二种方法,需要知道大概的输出输入长度是多少。
这两者的各自优缺点:
- 平行化,AT的Decoder在输出句子的时候,是一个一个字产生的(如果句子长度为100,那就要进行101次的Decoder);而NAT的Decoder是一次性产生整个句子的,所以在速度上NAT要快于AT
- NAT可以更好地控制输出句子的最大长度
- NAT的结果往往不如AT的好
3.5 Training 训练过程
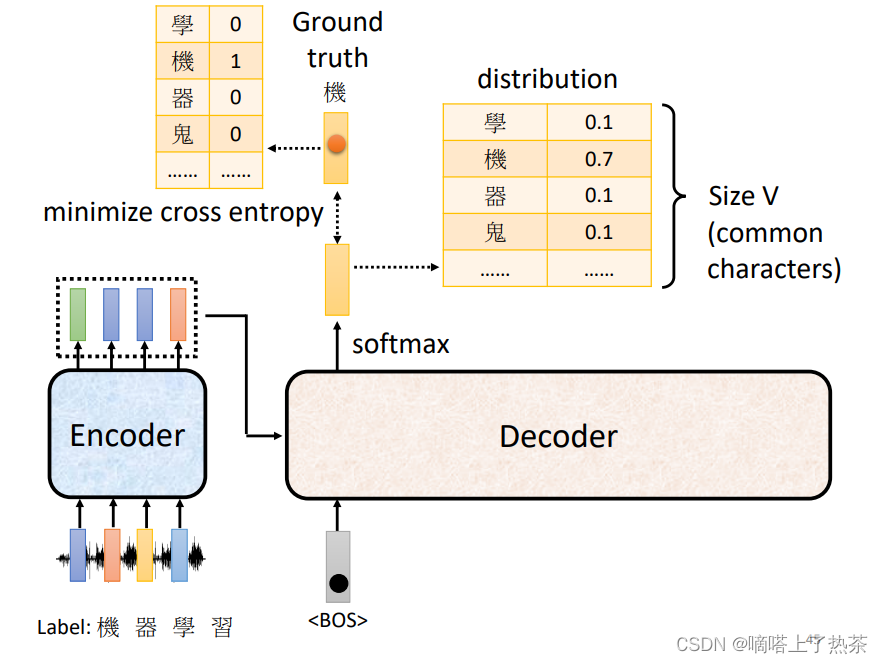
再训练时将model得到的输出结果与真实结果相比(真实结果是一个one-hot向量,输出的结果也是一个向量),损失函数使用cross entropy,对模型进行训练。model最后得到的是一个概率分布,概率大的作为最后的model输出结果。下图是模型训练的整体流程。
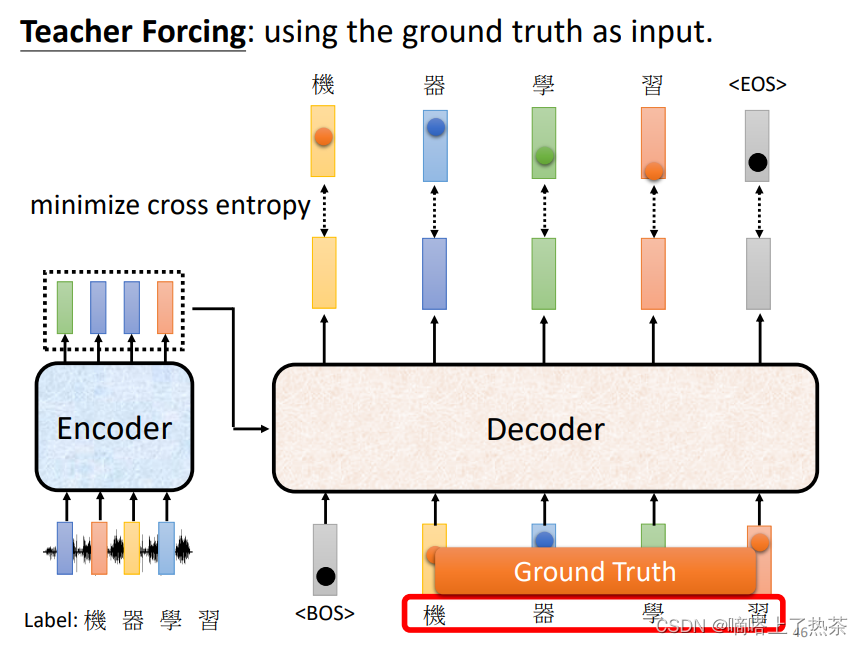
model训练的时候使用Teacher Forcing方法进行训练,也就是使用真实值作为输入。具体来说,假设Decoder输出了四个字,和一个END符号,那就希望前四个字和Label的交叉熵总和+后面的字符和END符号的交叉熵损失总和越小越好;在训练的时候,不会拿上一时刻的输出作为Decoder的输入,而是会直接拿正确的Label作为Decoder的输入。下图就是Teacher Forcing的展示。
3.6 Tips
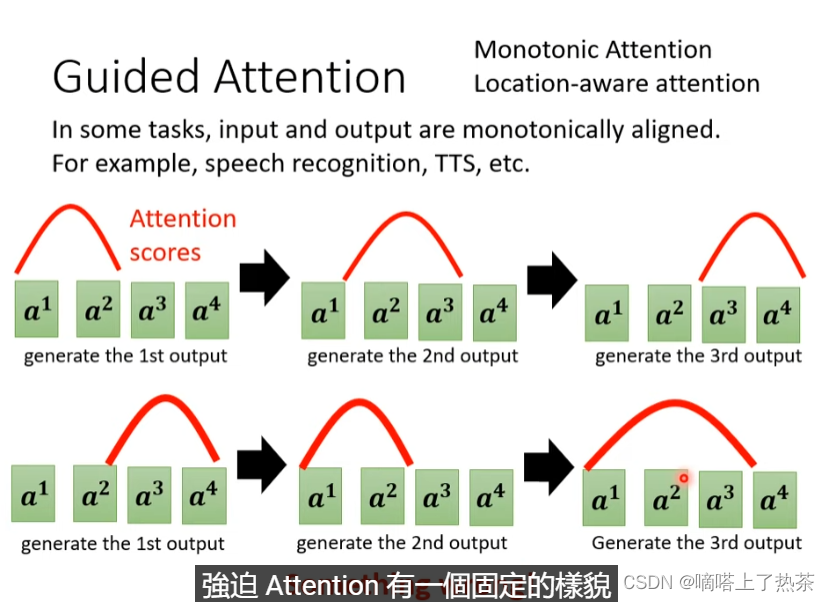
3.6.1 Guided Attention 引导性注意力机制
当在做某些事情的model,例如语音合成,语音辨识等任务时,需要限定注意力机制。就以语音合成为例,注意力机制需要去看前面的输入而不考虑后面的输入。
3.6.2 Optimizing Evaluation Metrics
对于语音合成,语音辨识,翻译等任务,使用交叉熵损失函数来优化模型,使用BLEU Score来评估模型。
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。它是用来评估机器翻译质量的工具。BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我们的翻译很成功。
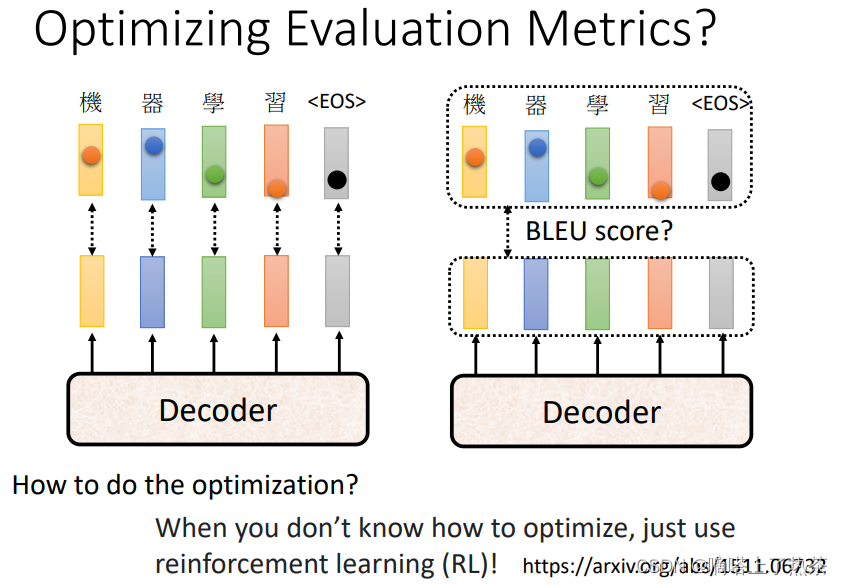
BLEU Score的缺点是它不能微分,所以不能直接作为神经网络的损失函数进行梯度下降优化。
3.6.3 Scheduled Sampling
在Train的过程中,会给Decoder输入正确的Label,但是这样有个缺点,就是在训练的时候,Decoder只看过正确的输入,所以可能在正确的输入下,它也能正确的输出,但是一旦有错误输出,它就很难得到正确的输出了,即很容易出现“一步错,步步错”的情况。
为了解决这种问题,可以在训练时就输入一些noise的Label给Decoder,以增强它的泛化能力。
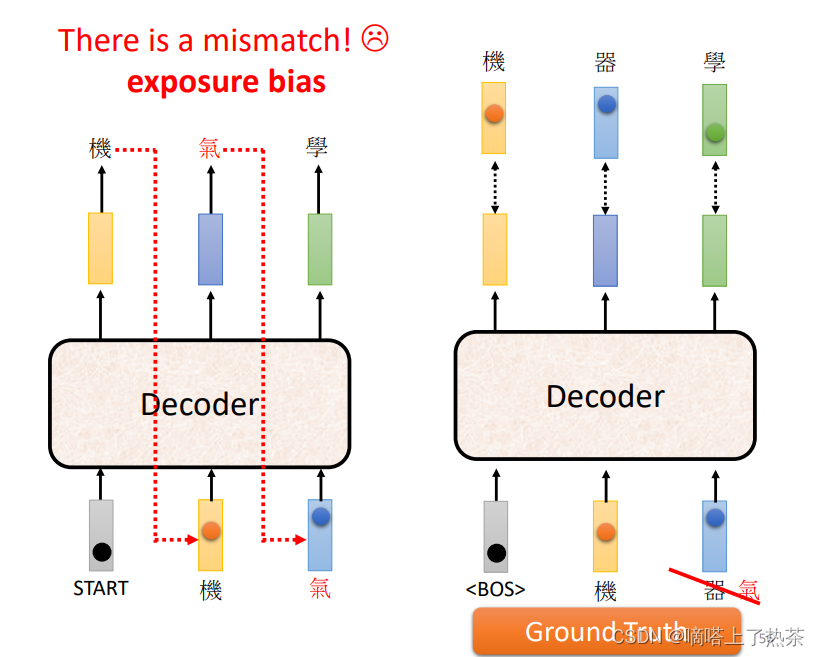
Scheduled Sampling以一定概率将生成的元素作为解码器输入,这样即使前面生成错误,其训练目标仍然是最大化真实目标序列的概率,模型会朝着正确的方向进行训练。因此这种方式增加了模型的容错能力
总结
本周学习了transformer的架构以及自注意力机制的一般架构。了解到了平行运算的重要性,还有模型都是非常灵活的,可以改变一下架构的顺序或者架构某一块有些部分的想法,这些都是值得一试,但这需要坚实的基础。还有模型训练的小技巧也要明白其原理。
本文若有错误,恳请批评指正。
本文参考以下博文:
https://blog.csdn.net/m0_56659208/article/details/124065950
https://blog.csdn.net/weixin_51545953/article/details/127800142


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









