







文章目录
摘要
本周学习对抗神经网络,知道了生成性模型和对抗神经网络的关系;了解了GAN的网络架构和模型训练流程;GAN的种类也十分多,了解到了有条件和无条件GAN的区别;也对cycle GAN进行了学习;GAN十分难训练,需要一些train的技巧;也学到一些评估GAN生成器好坏的方法。我还阅读了GAN的论文,对理论部分进行了推导,对不懂的知识查了相关概念。最后找了一个运用GAN生成手写数字的demo,进行代码运行和阅读。
Abstract
This week, I studied Generative Adversarial Networks (GANs) and learned about their relationship with generative models. I gained an understanding of the network architecture and training process involved in GANs. I also discovered that there are various types of GANs, including conditional and unconditional GANs, each with their own distinctions. Additionally, I explored Cycle GANs as well.Training GANs proved to be challenging, requiring specific techniques and tricks. I also learned some methods for evaluating the quality of GAN generators. To deepen my understanding, I read research papers on GANs, deriving theoretical concepts and researching unfamiliar topics.Finally, I found a demo that utilizes GANs to generate handwritten digits. I ran and studied the code, gaining insights from the practical implementation.
1.什么是GAN
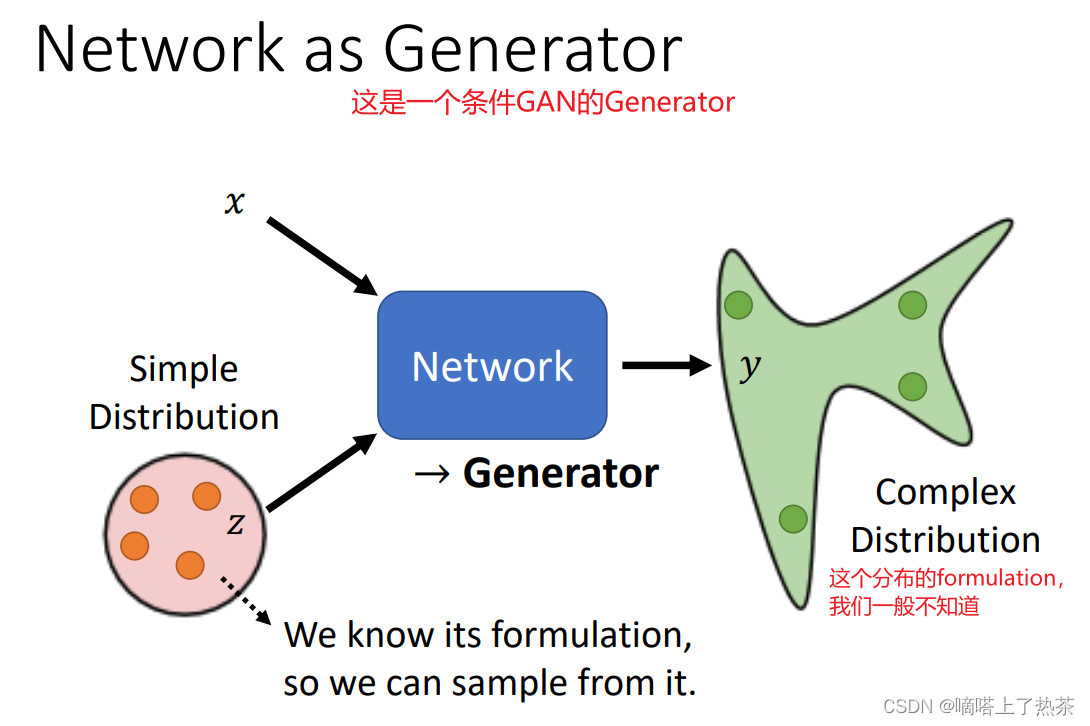
Generative model中最出名的是GAN(Generative Adversarial Network)。GAN其主要的目的是训练机器让机器能够自主生成相对应类型的图片,其中生成器generator就是GAN中进行生成相对应类似分布的网络,而鉴别器Discriminator就是判别生成器生成是否为真假的网络,鉴别器通过将输入的假图像转换成一个判别值来判断真假,值越大,假图像和真图像越接近,让生成器和鉴别器相互博弈,最终达到一种平衡(鉴别器鉴别不出真假图像),最后得到这个生成器就是算法的目标。如下图就是GAN的生成器的示意图,输入从简单的分布中sample出来的向量z和条件x,经过生成器,得到复杂的分布的向量y。
目前的GAN已经发展了许多的种类,有各式各样的GAN网络,如下图是各种各样的GAN的网络。

2.GAN的网络架构和执行流程
2.1 无条件GAN
GAN有无条件是指生成器除了输入噪声数据z(来自均匀分布或者高斯分布等等一些分布)是否还有别的输入x。下图是用无条件GAN来生成动漫人脸。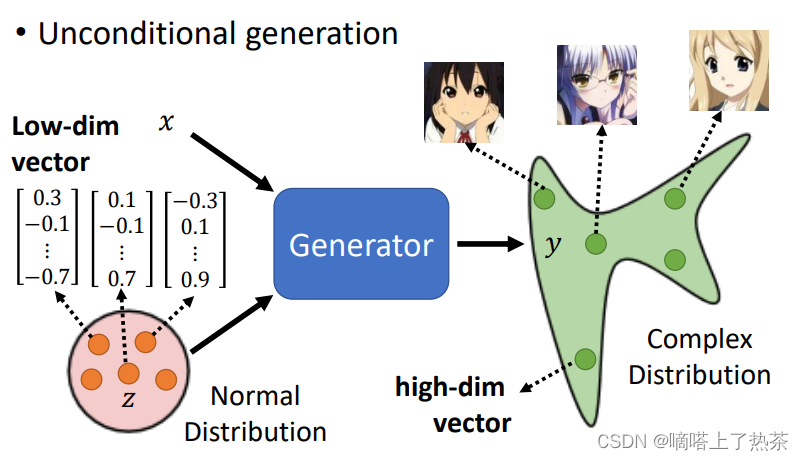
鉴别器来识别真假图像,对于鉴别器来说,对生成器生成的图像的评分越低证明鉴别器越好。下图是一个鉴别动漫人脸的鉴别器。
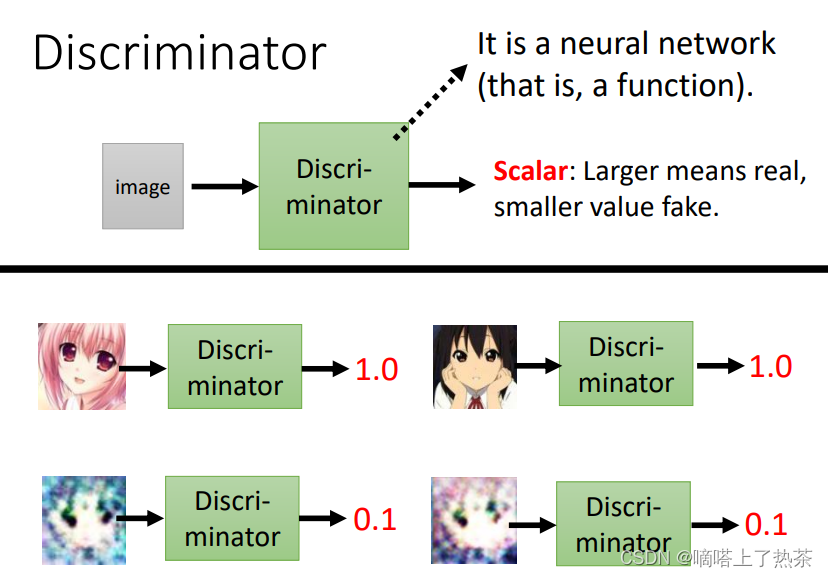
2.2 有条件GAN
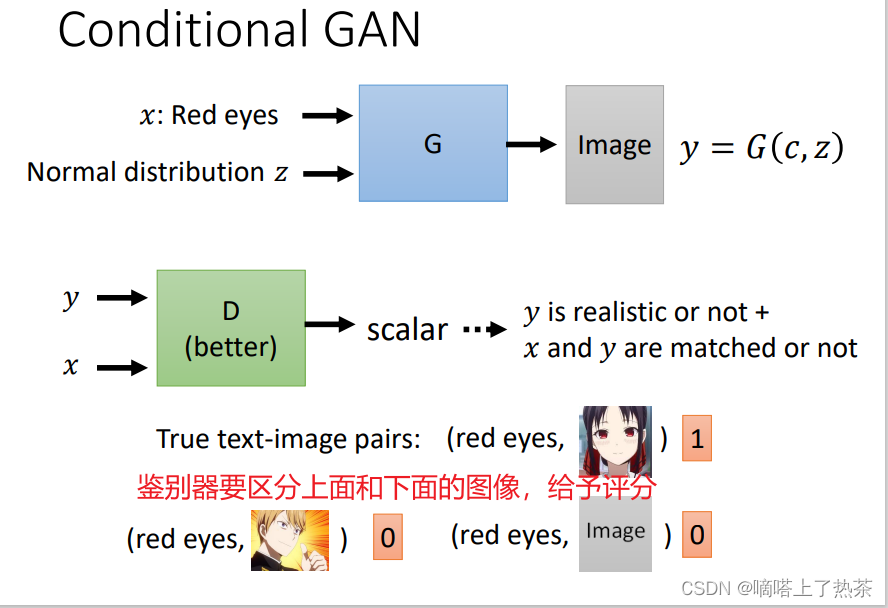
简单来说就是对生成器加限制,比如下图的生成器加上条件红眼,生成的动漫人脸的眼睛都为红色。
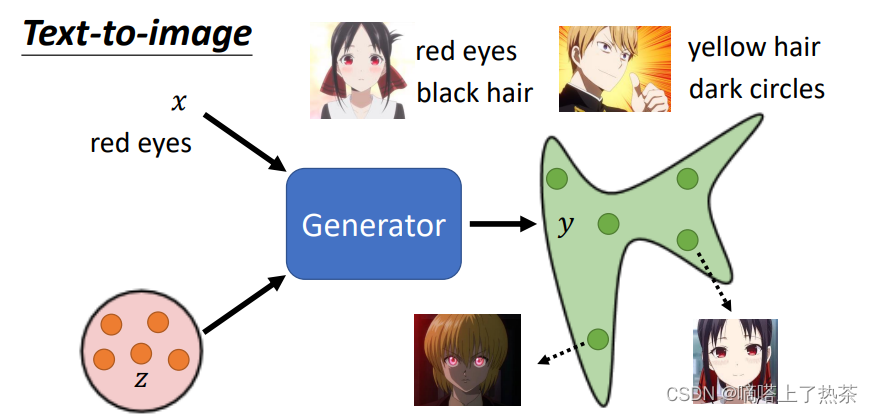
这时候对于鉴别器就不能只关心生成的是否和真图像相似的动漫人脸,还要判断适合真图像相似的人脸并且眼睛必须是红色的,下图就是加条件之后鉴别器需要做的。
2.3 GAN流程
以无条件GAN生成动漫人脸为例讲述GAN的工作流程,下面是具体的步骤:
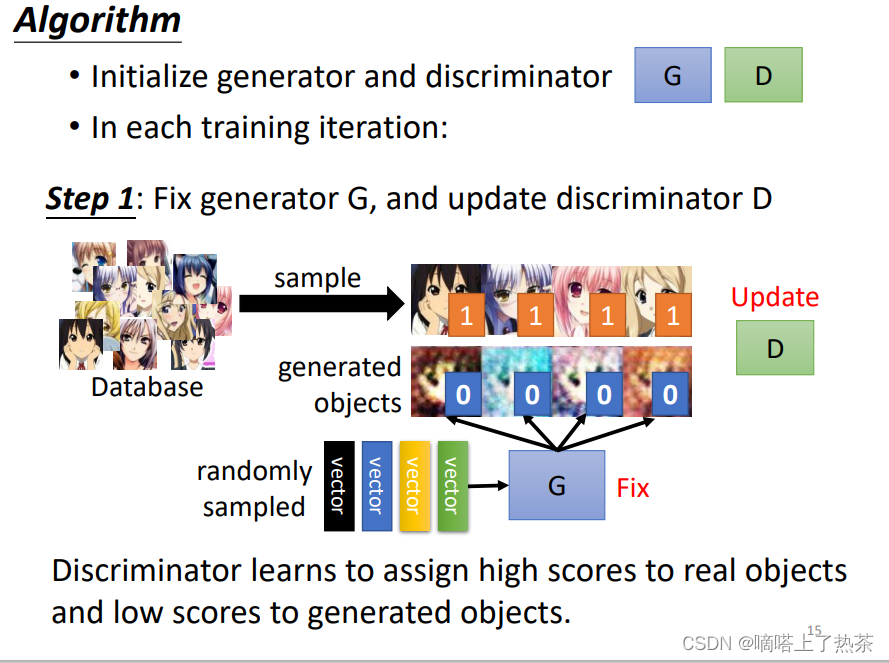
step1:
先初始化生成器和鉴别器的网络,接着让生成器先生成动漫人脸。这时候定住生成器(生成器的参数不允许再变化),然后将真实的动漫人物和生成器生成的动漫人脸输入给鉴别器,对鉴别器进行训练,使鉴别器将两者分开。
注:鉴别器有两种方案:
(1)看作一个分类问题,把真正的人脸当作类别1,Generator产生出来的图片当作类别2,然后训练一个classifier就结束了。
(2)看做一个回归的问题,输出的值越接近1,就代表越接近真实图片;而越接近1,就代表越接近假的图片,这两种办法都可以。
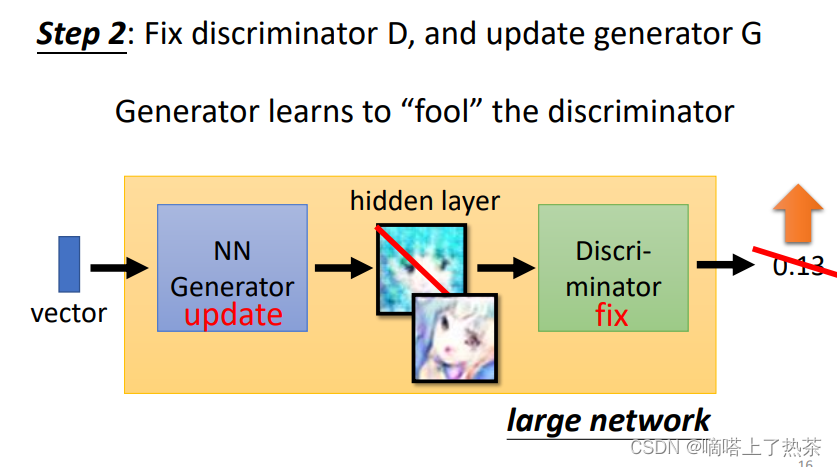
step2:
鉴别器训练完后,这时候定住鉴别器(鉴别器的参数不允许再变化),然后从分布里面sample一些向量输入到生成器中,生成动漫人物图像,再将人物动漫图像输入给鉴别器,使得鉴别器分辨不出真假(也就是输出的值大)。
step3:
定住生成器,训练鉴别器,使鉴别器能分辨真假图片。
step4:
定住鉴别器,训练生成器,使鉴别器不能分辨真假图片。
循环往复,当生成器生成的图片和真图片的分布相似或一样的时候,鉴别器再也分辨不出来真假图片,这时候算法结束,得到最终的生成器。
2.4 GAN理论
对于生成器和鉴别器的训练,需要先定义损失函数,然后进行梯度下降。损失函数如何定义是一个问题。对于生成器而言,希望真实数据和生成数据的分布一样,思路很清晰,使用两个分布之间的divergence的差值来更新生成器。生成数据的分布是不知道的,真实数据的分布可能也不知道。那么如何计算divergence(PG,Pdata)?问题转向如何计算divergence(PG,Pdata)。
注:PG表示生成器生成的数据的分布,Pdata表示真实数据的分布
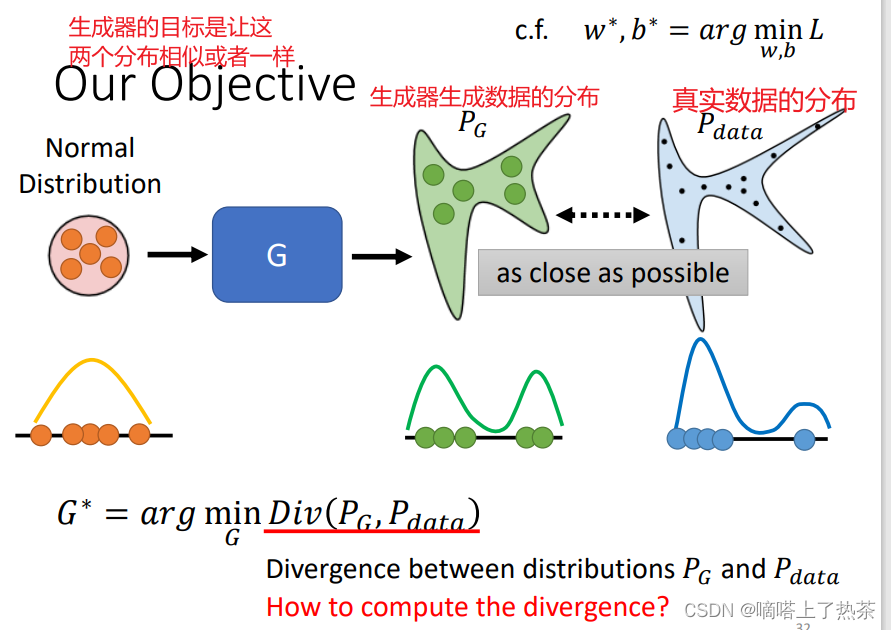
虽然不知道两个分布,但是可以从两个分布中sample出来向量(图片),可以使用sample的向量(图片)计算divergence(PG,Pdata)。

对于鉴别器而言,分辨两种图片,那不就相当于训练一个二分类器。希望这个二分类器可以将两类图片分的越开越好,就是划分出一个边界。于是就得到鉴别器的损失函数。这个损失函数和JS divergence有关。

因为鉴别器的损失函数和JS divergence有关,那么可以将生成器的损失韩式进行替换,如下图。

还有一些其他的divergence,如此下图。

即使知道了可以使用JS divergence计算损失,但是JS divergence是不适合的,因为对于PG和Pdata除非两者分布重合,否则计算的结果永远是log2,如下图所示。这就导致在训练model时,没法评估model生成图片的好坏,只有在最终的时候才能看出来,但是你能保证最终两个分布一定能重合吗?

这时候就需要再找一个评估指标,使用Wasserstein distance。下图就是wassertein distance。使用这个指标的就叫做WGAN。

2.5 Learning from Unpaired Data (Cycle GAN)
GAN 的妙用:unsupervised learning ,也就是接下来要介绍的 Cycle GAN。
一个例子就是 Style Transfer,例如图像风格转换,假设有一些人脸图片,另外有一些动漫头像,两者没有对应关系,也就是 unpaired data,如下图所示。我们的目标是让两者建立起对应的关系。

与前面介绍的 GAN 不同,Cycle GAN 的输入不是从分布中采样,而是从 original data 采样,经过生成器x->y生成动漫头像图片,紧接着将动漫头像图片再经过生成器y->x还原成原本图像,这样就避免生成器胡乱匹配,如下图所示。
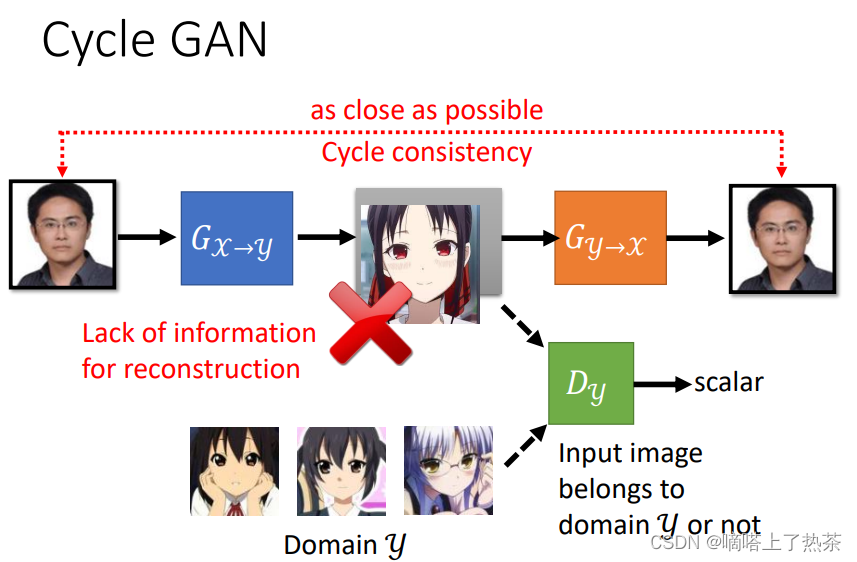
也可以反向来做,输入动漫头像得到人脸,如下图。
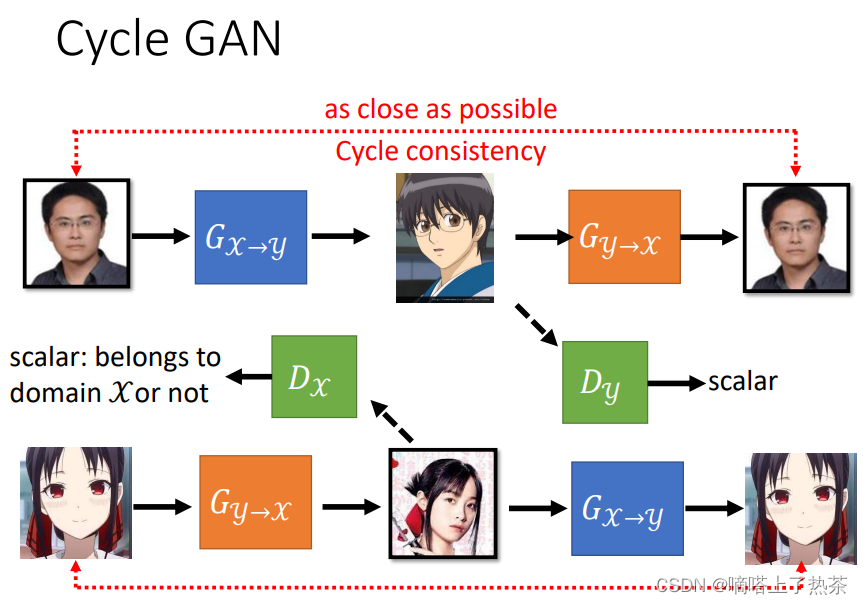
2.6 Evaluation of Generation
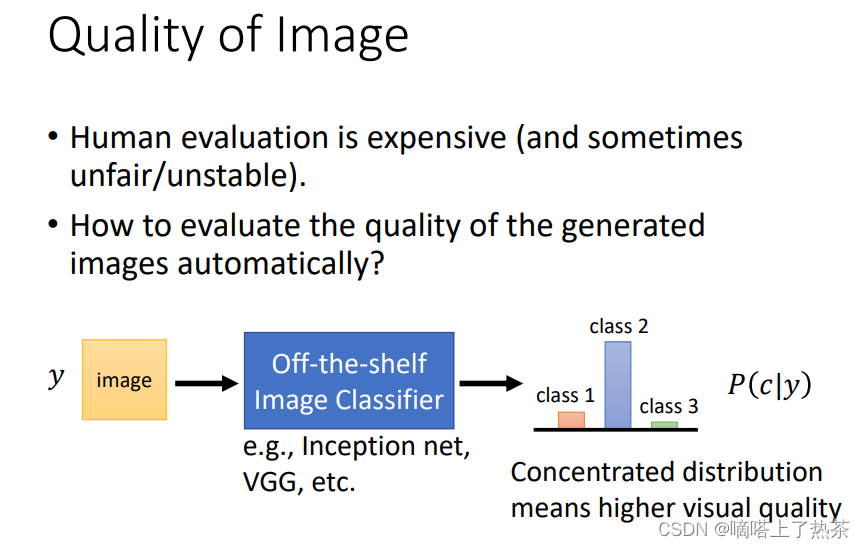
对于 Generative Model,怎么评估生成数据,比如生成图片的好坏呢?有监督学习可以和 label 比对,而 Generator 生成的图片与原来的图片相似但不相同,如何去判断呢?
2.6.1 Quality of Image(针对一张图片来说的)
对于作业中的二次元人物头像,可以用人脸检测,看生成的一组图片中能检测出多少人脸。
对于更一般的情况,生成多种类的图片,比如有猫、狗等不同种类,可以设计一个 Image Classifier。如果概率分布集中在某个类别,说明 Classifier 对于输出的类别很确定,也就是说Generator 生成的图片质量好;而如果概率分布平均,说明 Classifier 不太确定看到的图片属于哪个类别,Generator 生成的图片质量不佳。
但是这样也有一些问题,就是生成的数据可能集中在某部分区域,比如下面两种情况。
- Mode Collapse: generated data 集中在某一个 real data 周围的情况,这个区域可以认为是 discriminator 的“盲区”,区域内的图片判定为真的可能性大,因此 generator “投机取巧”,反复生成这种图片,如下图所示。

- Mode Dropping:生成器生成数据的分布只是真实数据的一部分,如下图中的左边的黄色的星星和蓝色的星星,咋一看分布好像差不多,其实本质上,黄色的星星分布只是蓝色星星的一部分。

如何解决上面的问题呢?见2.6.2.
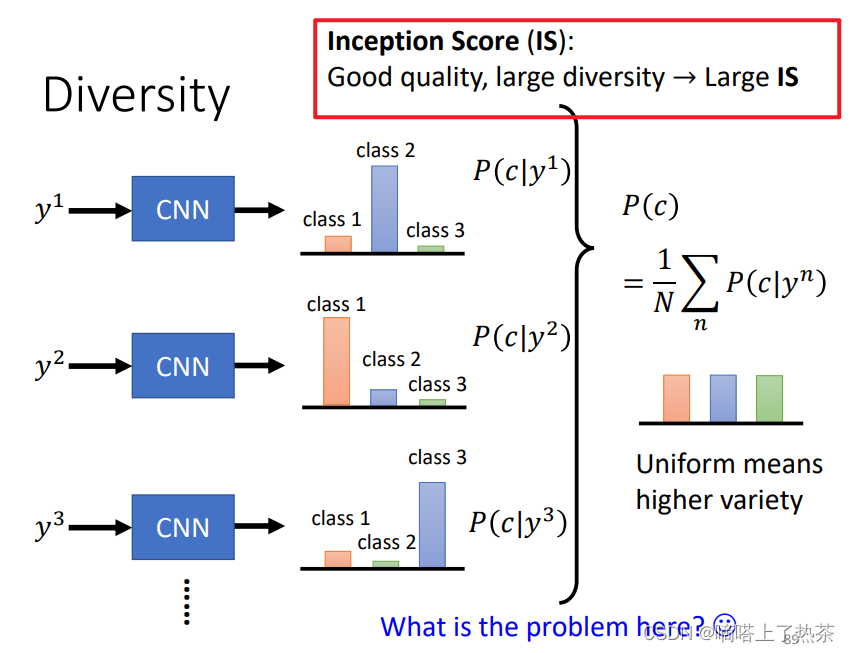
2.6.2 Diversity(针对一堆图片而言的)
可以把一组 generated data 输入 CNN Classifier,然后把得到的各分类概率分布取平均作为结果。如果这个平均概率分布中,各类别的分布比较平均,那就说明 generated data 有足够的 diversity。
为什么前面 Quality of Image 说要概率分布集中在某个类别好,这里 Diversity 又说要概率分布均匀好,这不是互相矛盾吗?
看 Quality of Image 时,Classifier 的输入是一张图片。看 Diversity 时,Classifier 的输入是 Generater 生成的所有图片,对所有的输出取平均来衡量。
Inception Score (IS) 就是结合了 Quality of Image 和 Diversity。Quality 高, Diversity 大,对应的 IS 就大。
3.手推GAN流程
下图是本人手画的gan训练步骤
下面时阅读GAN论文的一些公式推导和知识点记录



4.GAN的小demo
使用GAN来生成手写数字,使用cpu跑的代码。代码不是太懂,需要加强对pytorch这个库的学习。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
import torch.autograd
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
# 创建文件夹
if not os.path.exists('./img'):
os.mkdir('./img')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
batch_size = 128
num_epoch = 100
z_dimension = 100
# 图像预处理
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std
])
# mnist dataset mnist数据集下载
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True
)
# data loader 数据载入
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True
)
# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
# 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256), # 输入特征数为784,输出为256
nn.LeakyReLU(0.2), # 进行非线性映射
nn.Linear(256, 256), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x = self.dis(x)
return x
# ###### 定义生成器 Generator #####
# 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
# 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
# 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布
# 能够在-1~1之间。
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 256), # 线性变换
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x
# 创建对象
D = discriminator()
G = generator()
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
# 首先需要定义loss的度量方式 (二分类的交叉熵)
# 其次定义 优化函数,优化函数的学习率为0.0003
criterion = nn.BCELoss() # 是单目标二分类交叉熵函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
# ##########################进入训练# #判别器的判断过程#####################
for epoch in range(num_epoch): # 进行多个epoch的训练
for i, (img, _) in enumerate(dataloader):
num_img = img.size(0)
# view()函数作用是将一个多行的Tensor,拼接成一行
# 第一个参数是要拼接的tensor,第二个参数是-1
# =============================训练判别器==================
img = img.view(num_img, -1) # 将图片展开为28*28=784
real_img = Variable(img).cpu() # 将tensor变成Variable放入计算图中
real_label = Variable(torch.ones(num_img)).cpu() # 定义真实的图片label为1
fake_label = Variable(torch.zeros(num_img)).cpu() # 定义假的图片的label为0
# ########判别器训练train#####################
# 分为两部分:1、真的图像判别为真;2、假的图像判别为假
# 计算真实图片的损失
real_out = D(real_img) # 将真实图片放入判别器中
real_out = real_out.squeeze() # (128,1) -> (128,)
d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cpu() # 随机生成一些噪声
fake_img = G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离
fake_out = D(fake_img) # 判别器判断假的图片,
fake_out = fake_out.squeeze() # (128,1) -> (128,)
d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss
fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失
d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
d_optimizer.step() # 更新参数
# ==================训练生成器============================
# ###############################生成网络的训练###############################
# 原理:目的是希望生成的假的图片被判别器判断为真的图片,
# 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
# 反向传播更新的参数是生成网络里面的参数,
# 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的
# 这样就达到了对抗的目的
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cpu() # 得到随机噪声
fake_img = G(z) # 随机噪声输入到生成器中,得到一副假的图片
output = D(fake_img) # 经过判别器得到的结果
output = output.squeeze()
g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
# bp and optimize
g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
# 打印中间的损失
if (i + 1) % 100 == 0:
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} '
'D real: {:.6f},D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.data.item(), g_loss.data.item(),
real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值
))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))
# 保存模型
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
训练了100个epoch的结果图如下

本文理论内容参考以下博客:
https://blog.csdn.net/qq_43711697/article/details/120001421
https://blog.csdn.net/applebear1123/article/details/125323622
本文代码部分参考以下博客:
https://blog.csdn.net/jizhidexiaoming/article/details/96485095















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









