







文章目录
摘要
本周学习了机器终身学习(Life Long Learning)的多个方面。在终身学习的简介中,了解了这一方法的核心思想,即使计算机系统能够持续地学习和应用新知识以适应不断变化的环境和任务。在知识保留方面,探讨了多任务训练的限制,介绍了弹性权重保留(Elastic Weight Consolidation)和生成数据(Generating Data)等方法。在知识转移方面,比较了终身学习和迁移学习,讨论了衡量终身学习能力的方法以及梯度片段记忆(Gradient Episodic Memory,GEM)。此外,还研究了模型扩张,包括渐进神经网络(Progressive Neural Networks)和课程学习(Curriculum Learning)。通过这些学习,深入了解了终身学习的原理、方法和应用,以及如何在持续变化的环境中保持和扩展模型的知识。
Abstract
This week’s learning covered various aspects of machine life-long learning. In the introduction to life-long learning, the core concept was elucidated, emphasizing the computer system’s ability to continuously acquire and apply new knowledge to adapt to evolving environments and tasks. Within the realm of knowledge retention, the constraints of multi-task training were explored, and methods such as Elastic Weight Consolidation and Generating Data were introduced. Concerning knowledge transfer, a comparison was made between life-long learning and transfer learning, and discussions were held on methods for assessing life-long learning capability and Gradient Episodic Memory (GEM). Additionally, the study delved into model expansion, encompassing Progressive Neural Networks and Curriculum Learning. Through these studies, a comprehensive understanding of life-long learning principles, methodologies, applications, and the art of sustaining and expanding model knowledge in dynamic environments was gained.
1.Life Long Learning
Life Long Learning(终身学习)是一种机器学习方法,旨在使计算机系统能够在其整个使用寿命内持续积累和应用新知识,以适应不断变化的环境和任务。与传统的机器学习方法不同,终身学习关注于持续学习和迁移学习,通过不断地从新数据中学习,逐步改进模型,提高其性能和适应能力,从而更好地适应不断演变的现实世界需求。
1.1 简介
人从小到大用同一个脑袋学习,那许许多多个任务可以使用同一个神经网络吗?这就是Life Long Learning,机器终身学习。
终身学习的不同称呼
- LLL(life long learning)
- continuous learning
- never ending learning
- incremental learning
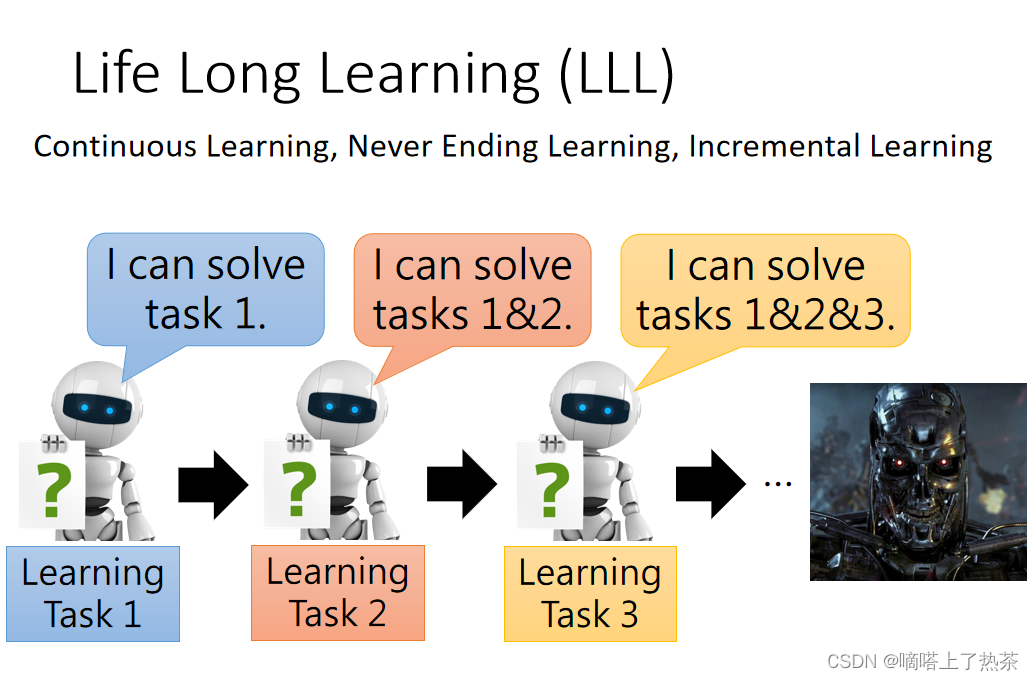
如上图所示,机器学习了task 1,之后又学习了task 2,这时候机器同时掌握了task 1和task 2,如果机器继续学习别的task的话,就同时拥有了更多的技能,假设机器学习了很多的技能,机器就十分无敌,就可以变成天网了!这是理想中的机器学习形态,但是众所周知,现在还没有达到这种情况。
想要实现机器终生学习,首先要实现以下三个问题,如下图所示。
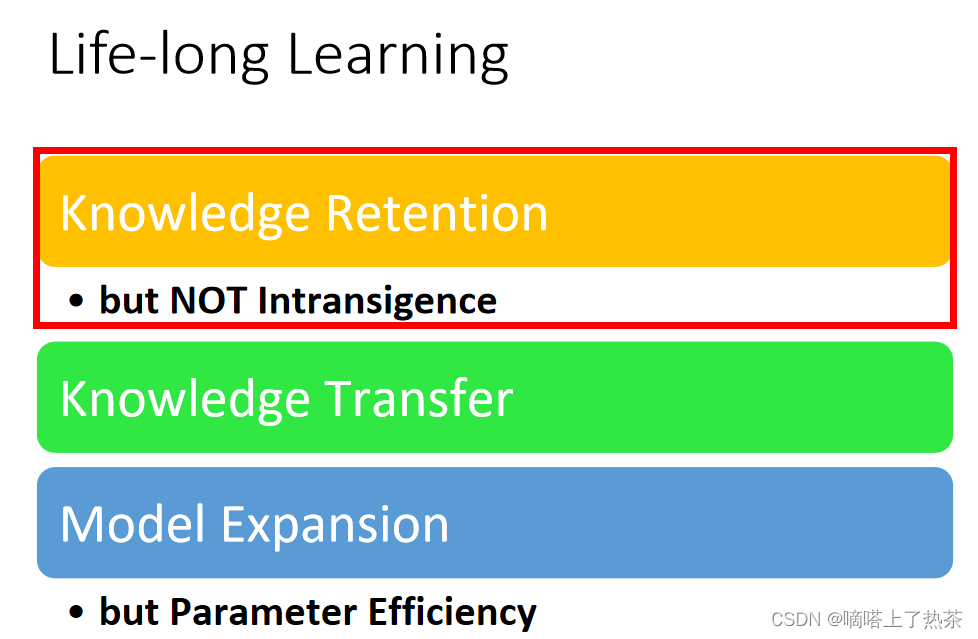
1.2 Knowledge Retention(知识保留)
第一个就是知识的保留,就是机器要把自己原来学过的知识进行保留,不可以学习了一个新的,就忘记旧的。但是机器又不能对这个妥协,其实就是机器不可以因为不可以忘记旧的知识,就拒绝一切新的知识。
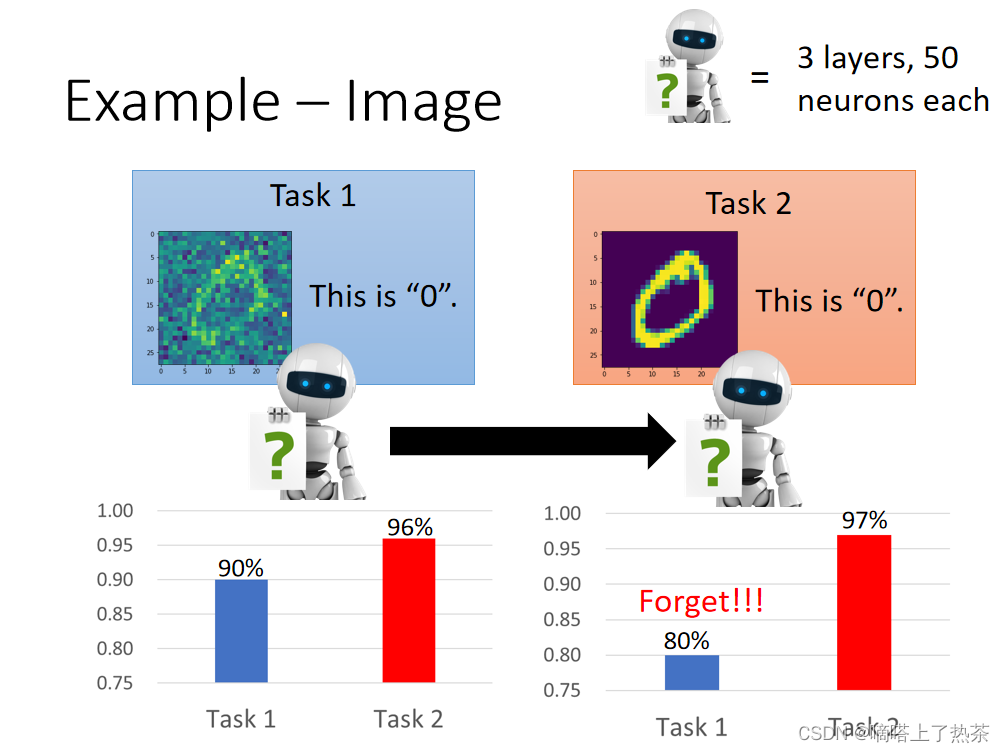
例子:手写数字辨识
在一个三层的网络中学习第一个有噪音的任务,在任务1学到的东西可以用在任务2上。任务1的正确率甚至没有任务2高,这个可以视为迁移学习。让机器学任务2后,任务2的准确率更高,但是任务1的准确率下降,如下图所示。
是否是因为网络过于简单?不是的,因为同时学任务1和任务2,能够学的比较好,如下图所示。
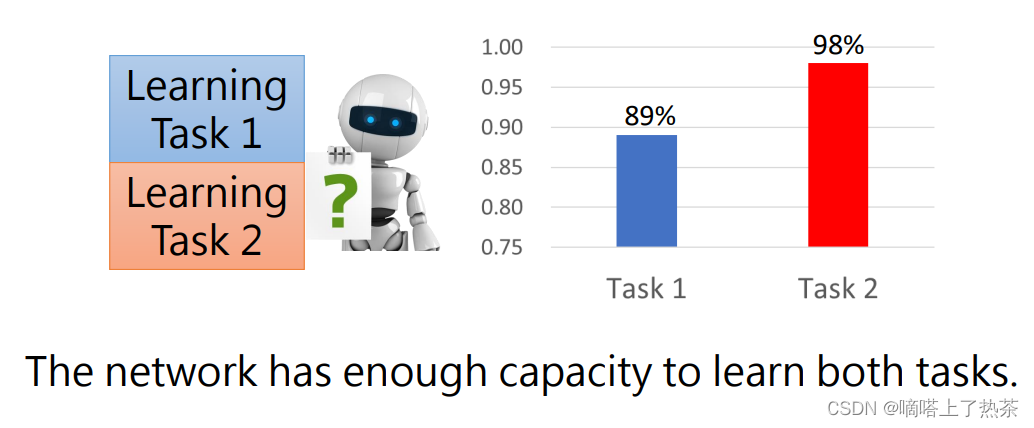
证明网络有能力学完这些东西,但是没有做到,这种现象叫做Catastrophic Forgetting(灾难性遗忘)。
-
为何会出现灾难性遗忘的问题?
如下图所示,假设有两个任务,网络有两个参数θ,颜色越深,说明loss越小
学习任务1时,参数从θ0学到θb,再学习任务2时,继续训练,学习到θ*,此时任务2的loss变小,但是任务1的loss变大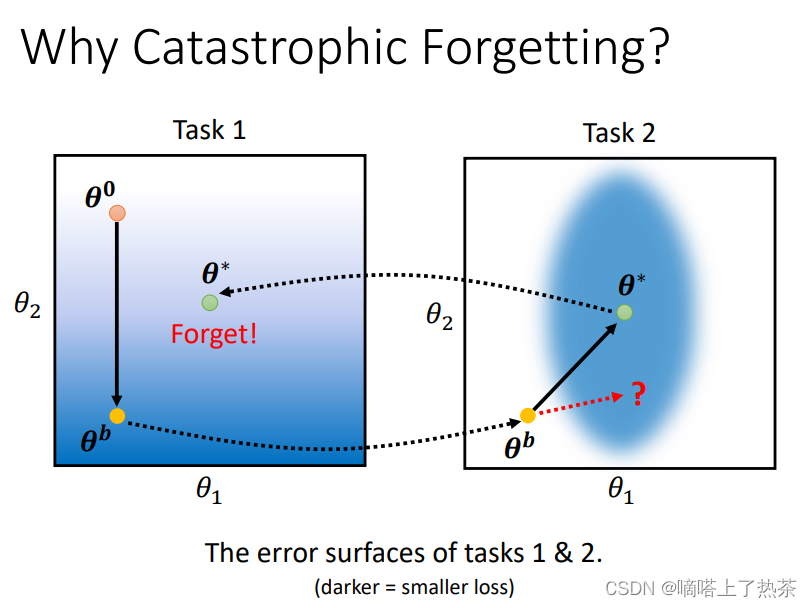
-
如何解决灾难性遗忘的问题呢?
下面介绍几种方法。
1.2.1 多任务训练的弊端
很多人说,解决catastrophic forgetting的方法已经出现了啊,就是很多任务同时进行训练!
但是这种multi task的方法在训练任务少的时候还可以,一旦训练任务过多就存在一定的弊端,如下图所示。

- 首先就是storage issue(存储问题):假设我们一共又一千个任务,我们如果之前训练好了999个任务,我们想训练1000个任务的时候,我们就要把之前999个任务的数据全部放入计算机,这将造成计算机存储爆掉
- 第二个问题就是computation issue(计算问题),仍然是训练第1000个任务的时候,我们将1000个任务的数据都放入模型中进行计算,机器要计算那么多数据,将对机器造成很大的计算压力。
以上是对multi task问题的解读,机器终生学习所想要解决的其实就是如何在不使用multi task的情况下,让模型把每一个不同的任务都学好。
1.2.2 Elastic Weight Consolidation(EWC)
基本思想:
有一些weight重要,但是有一些不重要;保护重要weight,只调不重要的额。
做法:对于每一个θ,有一个守卫参数b,修改loss,计算当前参数与之前的参数之间的距离,如下图所示。

b用来表示保护θ的程度,可以将θ视为一种regularization,如下图说所示。
- 如果bi很大的话,后一项如果括号中的变大,就会使新的损失函数瞬间变大,因此这些参数只能小幅度的改变;
- 如果bi很小的话,即使括号中的内容变大,损失函数依然不会很大,因此这些参数可以较大幅度的改变

那么现在的问题就是怎么找b?
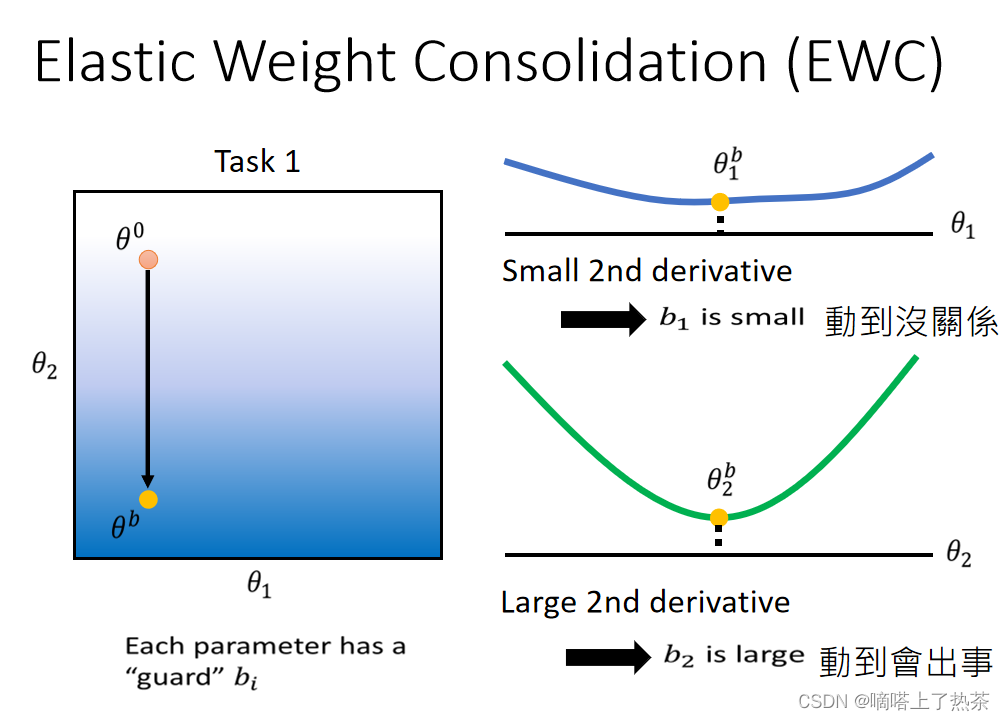
EWC的想法是:引入了一个参数叫做bi来衡量参数θi的重要性,而bi 可以是L ( θ )关于每个参数θ 的二次微分!
如下图所示:如果二次微分比较平坦的话,就意味着在θ1方向(x轴)的重要性是很低的,意味着在x轴方向可以进行大得移动
如下图所示:如果二次微分比较忐忑,就意味着在θ2(y轴)方向的重要性是比较高的,所以就不能在y轴方向进行太大得移动
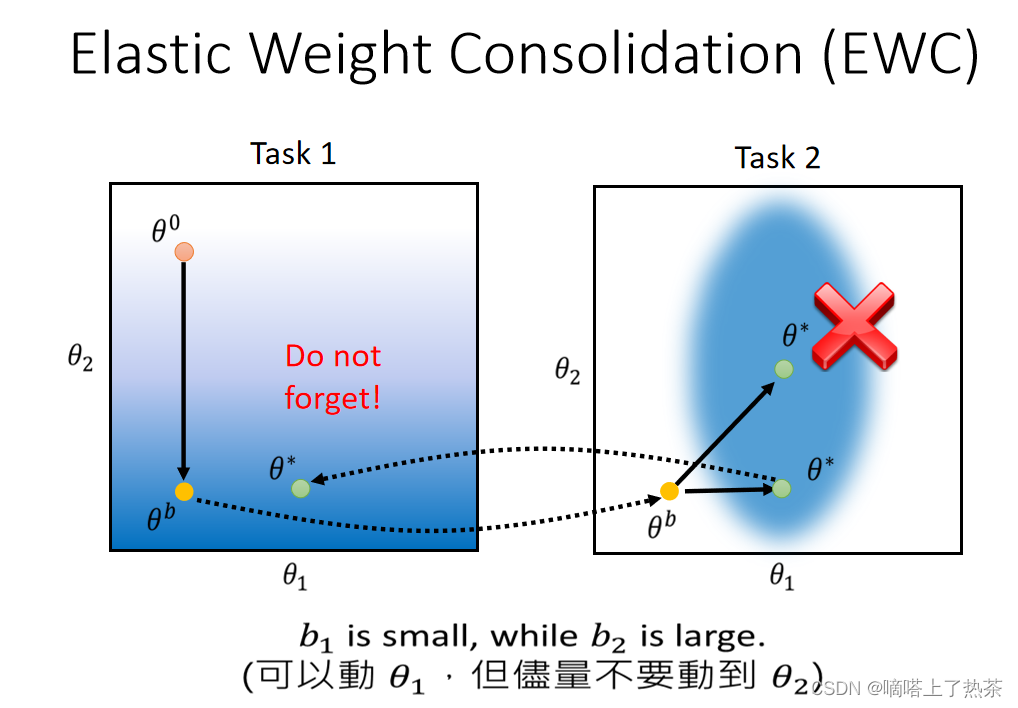
基于EWC的想法,此时更新参数就不能像之前那样直接更新为θ*
在图中表示的话,就是在x轴方向可以进行比较大得移动,但是在y轴就不要进行较大得移动。所以原本像右侧四十五度方向的移动就变为了平移,平移之后的参数θ在task1中的损失函数也和之前训练时候相比差距不大,所以实现了不忘记的要求,如下图所示。
1.2.3 Generating Data
生成数据,来缓解数据过多占用内存的问题
基本思想是在学习解决task问题时,再额外训练一个生成器,生成器用于生成task任务的数据。
先让机器学task1,然后学task2,同时要训练generator,学会生成task1的数据,此时就可以把task1的data丢掉,用生成的数据和task2的放在一起训练,如下图所示。

我们不再存储之前任务的数据集,我们通过数据训练一个生成器,生成这种数据集,但是这种方法存在弊端,就是现在生成器是很难生成十分高清的影像的,所以这种方法能否被广泛应用依然是问题。
1.3 Knowledge Transfer
第二个需要解决的问题是,在训练不同任务的时候,如何将知识进行transfer。
思考一下:我们不就是想要解决很多的任务吗!那为什么不直接拿出很多的模型去训练呢?
首先:我们想让机器在学完task1之后,学习task2会更加的快,同样在学完task1,task2之后,学习task3会更快。就像我们学习完线性代数,会对学习机器学习有帮助,做到触类旁通。
其次:我们知道机器的存储是有一定极限的,我们如果存储一千个模型的话,就会对机器的存储造成影响。
那用Transfer learning是不是可以解决这个问题?
1.3.1 Life-Long v.s. Transfer
终生学习会和迁移学习有点相似的地方。没错,迁移学习和终生学习都是想让机器在学习完task1之后会对task2有帮助,做到触类旁通,两者的区别如下图所示。
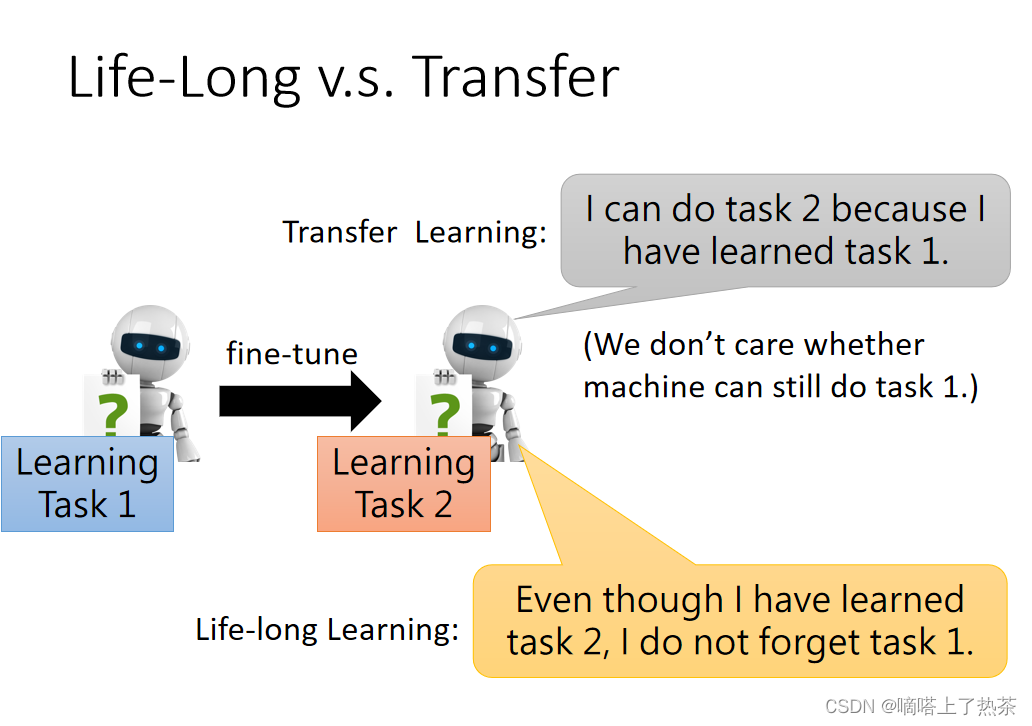
但是迁移学习会和终身学习有区别的地方在于:迁移学习只是想做到学习task1会对task2有帮助,但是学完task2是否会忘记task1却没有任何要求(这里不考虑Transfer中的Multitask Learning(多任务学习),因为它是直接一起学习的),但是终身学习要求学完task2以后,不要忘记task1。
就是说,迁移学习是很容易得了芝麻丢了西瓜的,但是终身学习却不会忘记之前的情况,终身学习包括了迁移学习想做到知识的transfer,但是终身学习还想做到的是保证知识的retention。
1.3.2 Evaluation(衡量终生学习能力的方法)
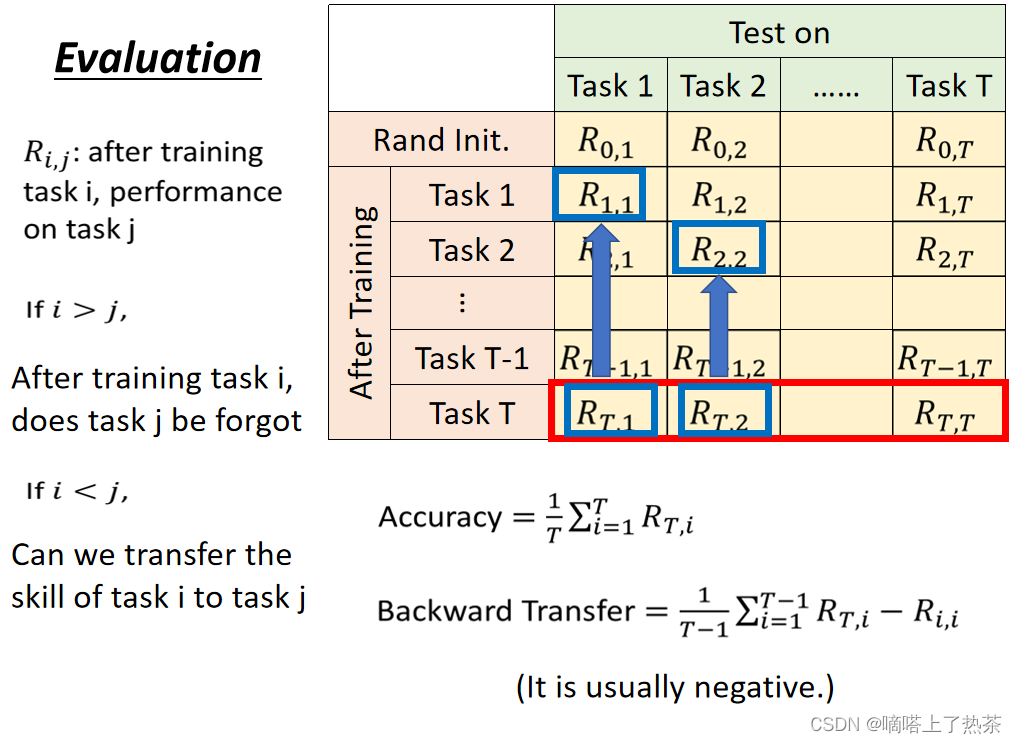
如上图所示,通常用matrix,每个row代表学习的阶段,column表示在任务X上的表现。
Accuracy是最后一行的平均
多不会遗忘:backward Transfer,学到某个阶段时减去刚学过时的表现,求平均(通常为负)
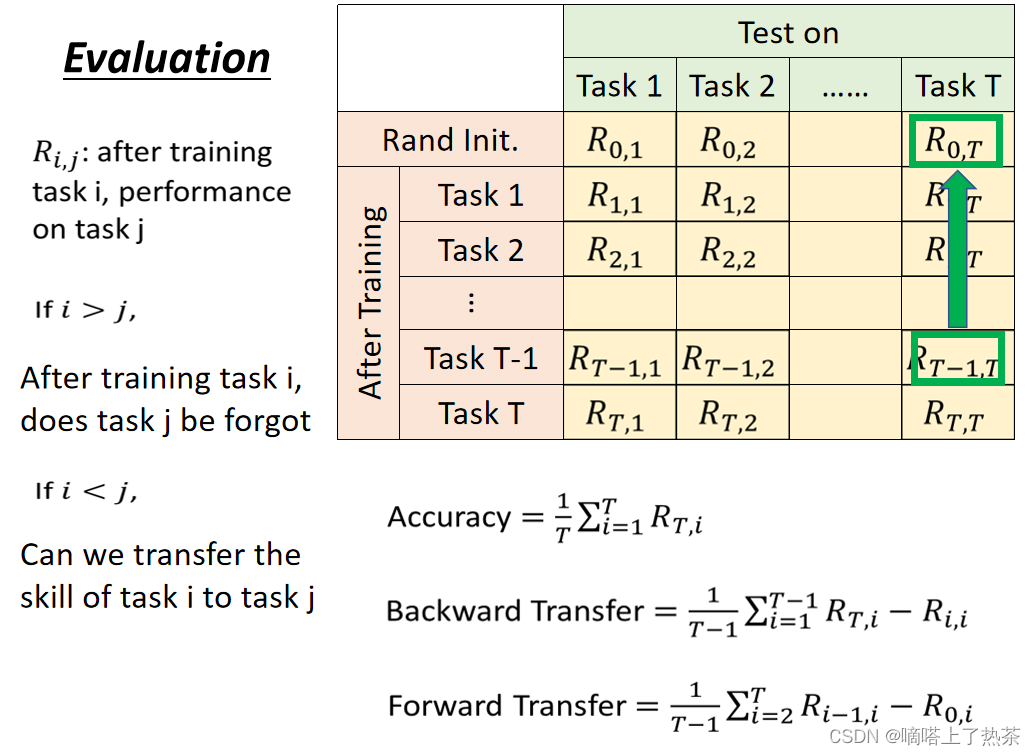
forward Transfer:表示能transfer到没学的任务的表现,如下图所示。
1.3.3 Gradient Episodic Memory (GEM,梯度片段记忆)
我们举一个例子:GEM。假设我们有三个任务,task1,task2,task3。之前1,2都已经学习完毕,下面我们想学习task3。
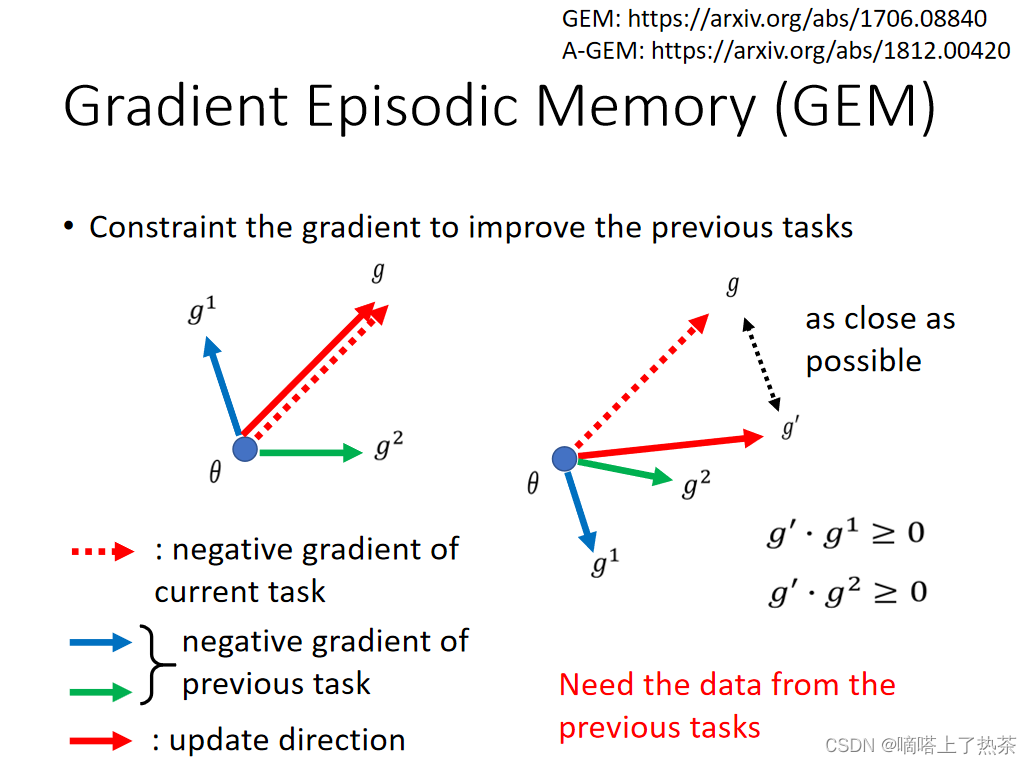
我们计算出更新task3参数方向是红色虚线的方向,我们对这个g和之前第一个任务的g1 ,第二个任务的g2(g1,g2是通过保存的以前的一部分数据来计算之前task的梯度)做内积,这个内积都是正数,所以如果是按照虚线方向更新的话,对之前两个任务是没有任何影响的,就按照虚线方向更新参数。
但是如果像右图一般,g和g1的内积是负数的话,这个g就会对之前task1造成影响,就不可以这么做了,转换g到实线的方向(但是注意,g′的方向和g方向应该是差别不大的)。
其实就是每一次更新g都和之前的g1,g2进行一个内积的运算,如果运算结果是正的话,就进行更新,如果运算结果是负的话,就调整一下g,但调整后的g ′ 要尽可能和g接近。之后按照调整之后的g进行更新。
但是这个方法有一定的弊端,就是每训练下一个任务的时候,都要保存一些旧的数据,因为g1,g2 是每一次都要重新计算的。
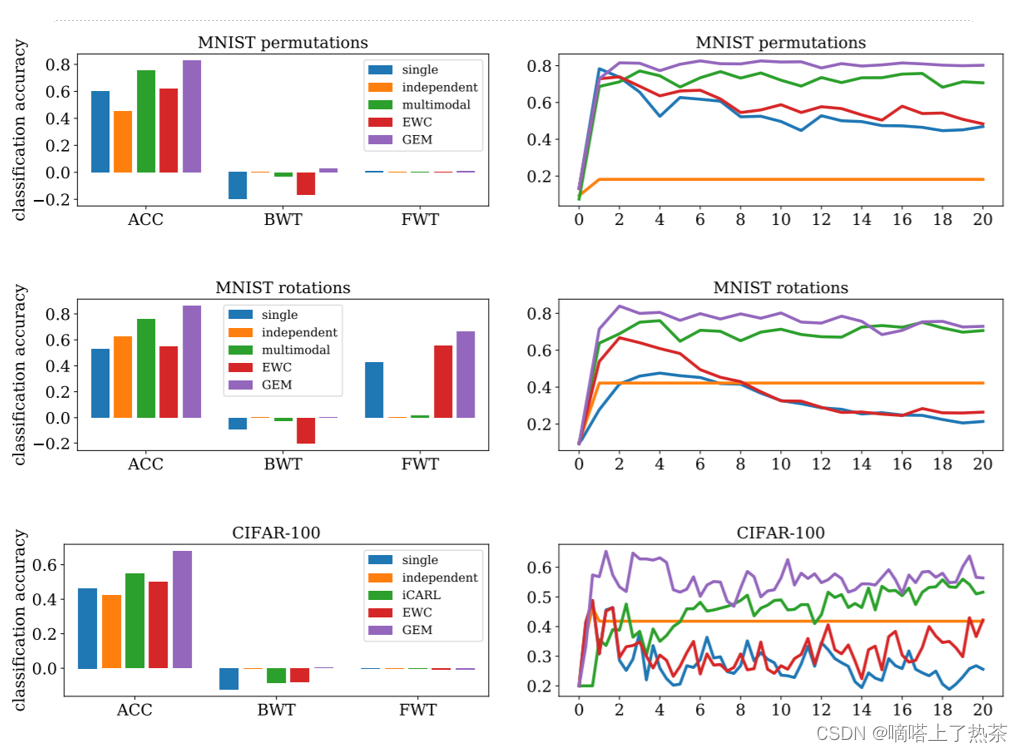
这个便是GEM的结果,图中single的意思就是一个模型从第一个任务开始逐个训练到最后一个任务,independent的意思是每一个任务对应一个模型进行训练,multimodal是指所有的task的数据全部都放入到一个multimodal中。我们可以看出来,GEM是一个很棒的方法,因为GEM的BWT是正的,证明他不但没有忘记之前学过的知识,反而一定情况下做到了触类旁通。
1.4 Model Expansion(模型扩张)
第三个要解决得问题是,模型的扩张。在之前的学习中,都假定当前的模型是足够大的,以至于可以学好所有的task,但是在实际问题中,有时候模型并不能学好所有的知识,所以就需要将模型进行扩张,但是我们想要的扩张时希望可以有效率的进行扩张,其实不希望每进来一个新的task,模型就进行扩张,这样的结果只能时模型太大,导致存储不足,希望模型扩张的速度比任务添加的速度要慢。
1.4.1 progressive neural networks
任务1的参数就不要动它了,直接用于任务2,再增加神经网络来解决任务2,这个适用于任务少的情况下,如下图所示。
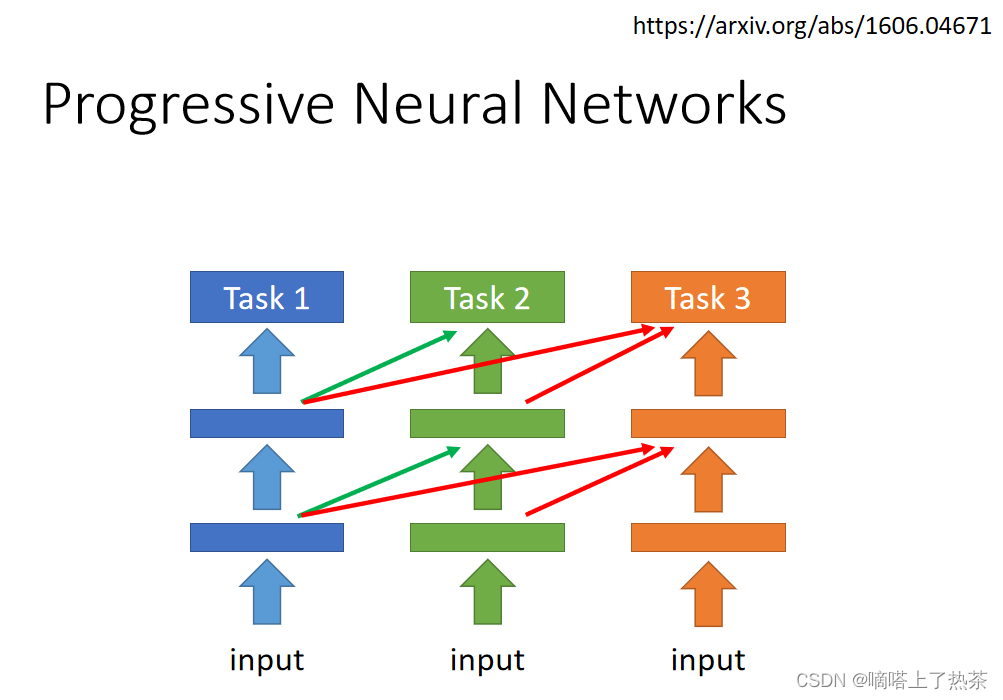
1.5 Curriculum Learning
Curriculum Learning 类似于一个课程系的学习, 研究的是如何安排课程学习的先后顺序。
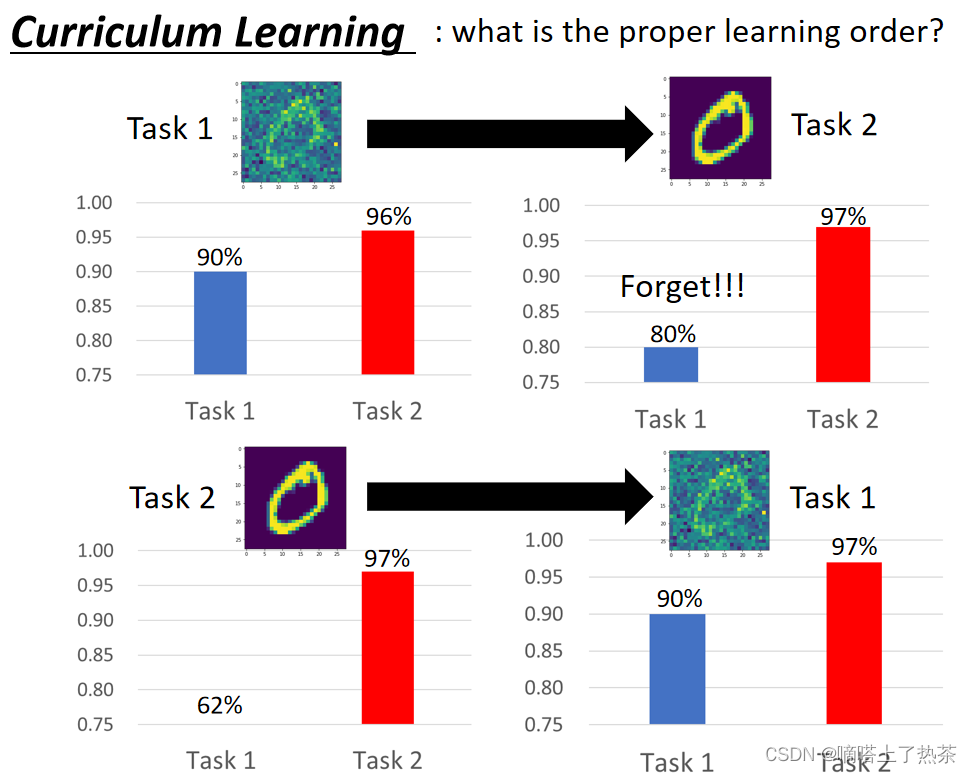
我们之前是将带杂讯的作为task1,之后再将没有杂讯的作为task2,我们发现学习完task2以后,机器完全忘记了task1的知识;但是,如果将没有杂讯的作为task1,将有杂讯的作为task2以后,发现机器不但学会了带杂讯的,反而在不带杂讯的情况下学习的很好,任务的先后次序,确实会对学习的效果起到帮助。
总结
本周的学习内容涵盖了机器终身学习的多个方面。我深入了解了终身学习的核心思想,了解了知识保留和知识转移的不同方法。在知识保留中,我学习了解决多任务训练限制的方法,如弹性权重保留和生成数据。在知识转移中,我比较了终身学习和迁移学习,研究了衡量终身学习能力的方法以及梯度片段记忆。我还了解了模型扩张的概念,包括渐进神经网络和课程学习。通过这些学习,我深入认识了终身学习的重要性和方法,以及如何在不断变化的环境中保持和拓展模型的知识。
本文参考以下文章:
https://blog.csdn.net/qq_44766883/article/details/112910323














 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









