







文章目录
摘要
本周主要学习自监督学习,如何使用没有标记的数据进行model的训练。学习了知名的大模型BERT和GPT,BERT是一个pre-train model,可以用于许多下游任务,只需要fine-tune一下。fine-tune的方式有许多,具体分为输入和输出两大类别。也学习了预训练的SeqtoSeq model,UniLM model。最后,为了学习pytorch,写了一个线性回归的例子。
Abstract
This week focuses on self-supervised learning, how to train models using unlabeled data. Having learned the well-known large models BERT and GPT, BERT is a pre-train model that can be used for many downstream tasks and only needs to be fine-tuned. There are many ways to fine-tune, which are divided into two categories: input and output. Pre-trained SeqtoSeq model, UniLM model, were also learned. Finally, to learn Pytorch, an example of linear regression was written.
1.Self-supervised Learning
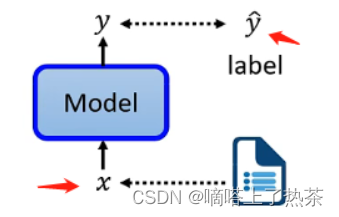
监督学习,当做监督学习时,只有一个模型,这个模型的输入是x,输出是y。假设做情感分析,那就是让机器阅读一篇文章,而机器需要对这篇文章进行分类,是正面的还是负面的,为了对机器进行训练,必须先找到大量的文章,需要对所有的文章进行标注。需要有标签和文章数据来训练监督模型,如下图是一个监督模型训练的大体步骤。
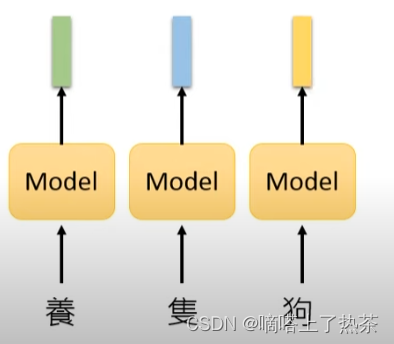
自监督学习是用另一种方式来监督,没有标签。假设只有一堆没有label的文章,例如,一篇文章叫x,把x分成两部分,一部分叫x’,另一部分叫x’’,然后把x’输入模型,让它输出y。这里的x’'充当了label的作用,但是是从原本无标签的训练数据中划分出来的,所以叫做自监督学习。由于在Self-supervised学习中不使用标签,Self-supervised学习也是一种无监督的学习方法。但之所以叫Self-supervised Learning,是为了让定义更清晰,如下图就是自监督学习的大体流程。

2.Pre-train Model
Pre-train Model简单来说,就是用嵌入向量表示每个token(输入个模型的单位,例如中文的token是一个方块字)。
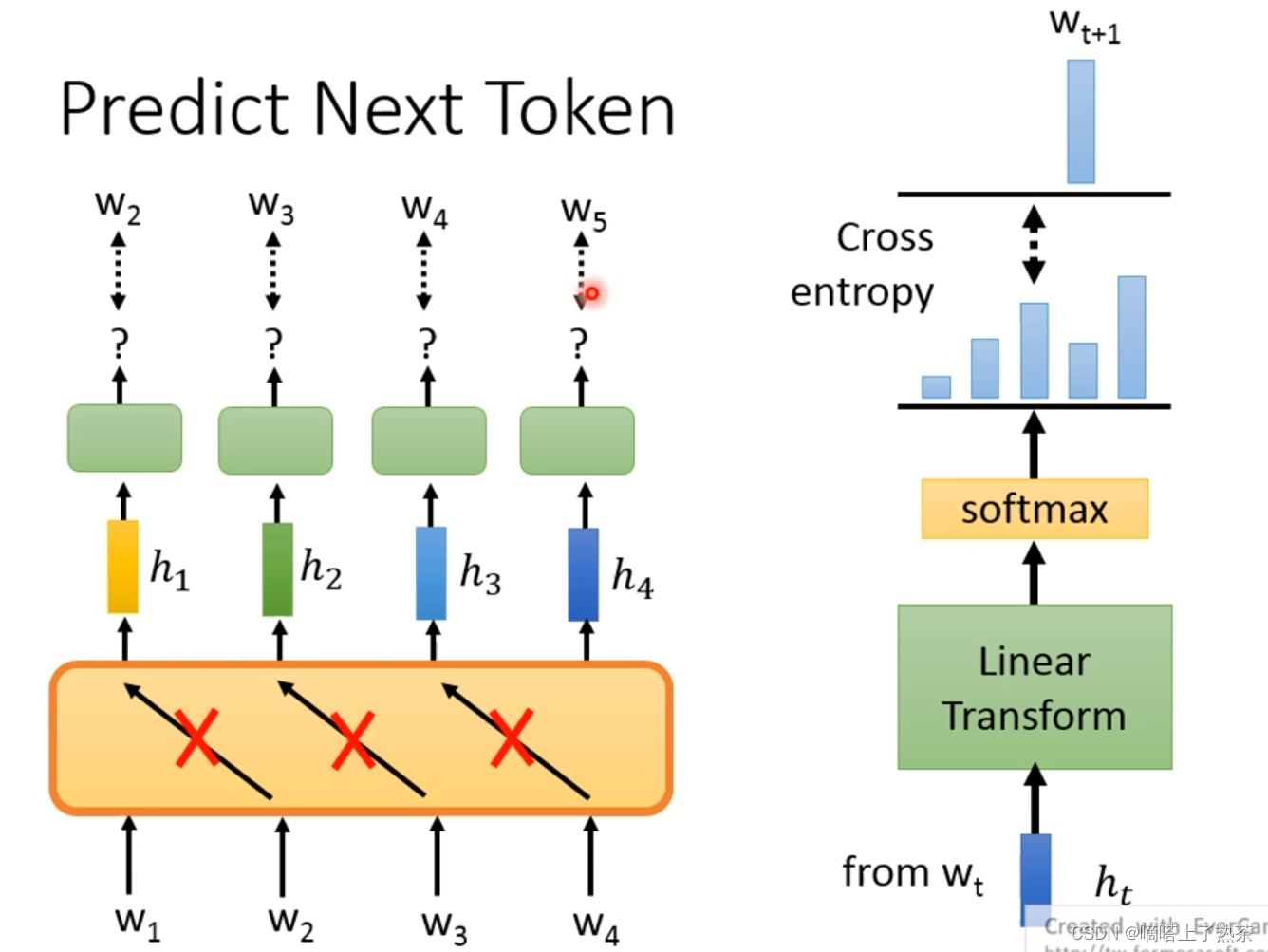
如何训练一个Pre-train Model?
根据具体的需求,比如做predict next token,训练的model不能看右边的资讯(就是使用W1去预测W2的时候不能让model看见W2的资讯,使用W2预测W3也是同理),这里可以使用有限制的自注意力机制(只看左边资讯)。详见我的第四次周报中的3.3.1 Masked Multi-Head Attention。当然也可以使用LSTM。
但是只看左边的资讯可能会有些问题,因为句子中的词是有上下文的,相同的词在不同的句子中的含义不同,那么嵌入向量也应该不同,这样就需要使用别的办法来进行pre-train madel。这就要看BERT,它本质上是transformer的encoder,里面使用的是自注意力机制(没有限制的)。
pre-train model的本质还是将token转换为Embedding vector,对于语言任务来说就是让它懂语义。
3.Fine-tune
个人理解,fine-tune是在训练好的pre-train model加一些下游任务,对于不同的NLP任务,使用不同fine-tune。fine-tune的NLP任务从输入和输出的角度来看,大体分为以下几种,如下图。
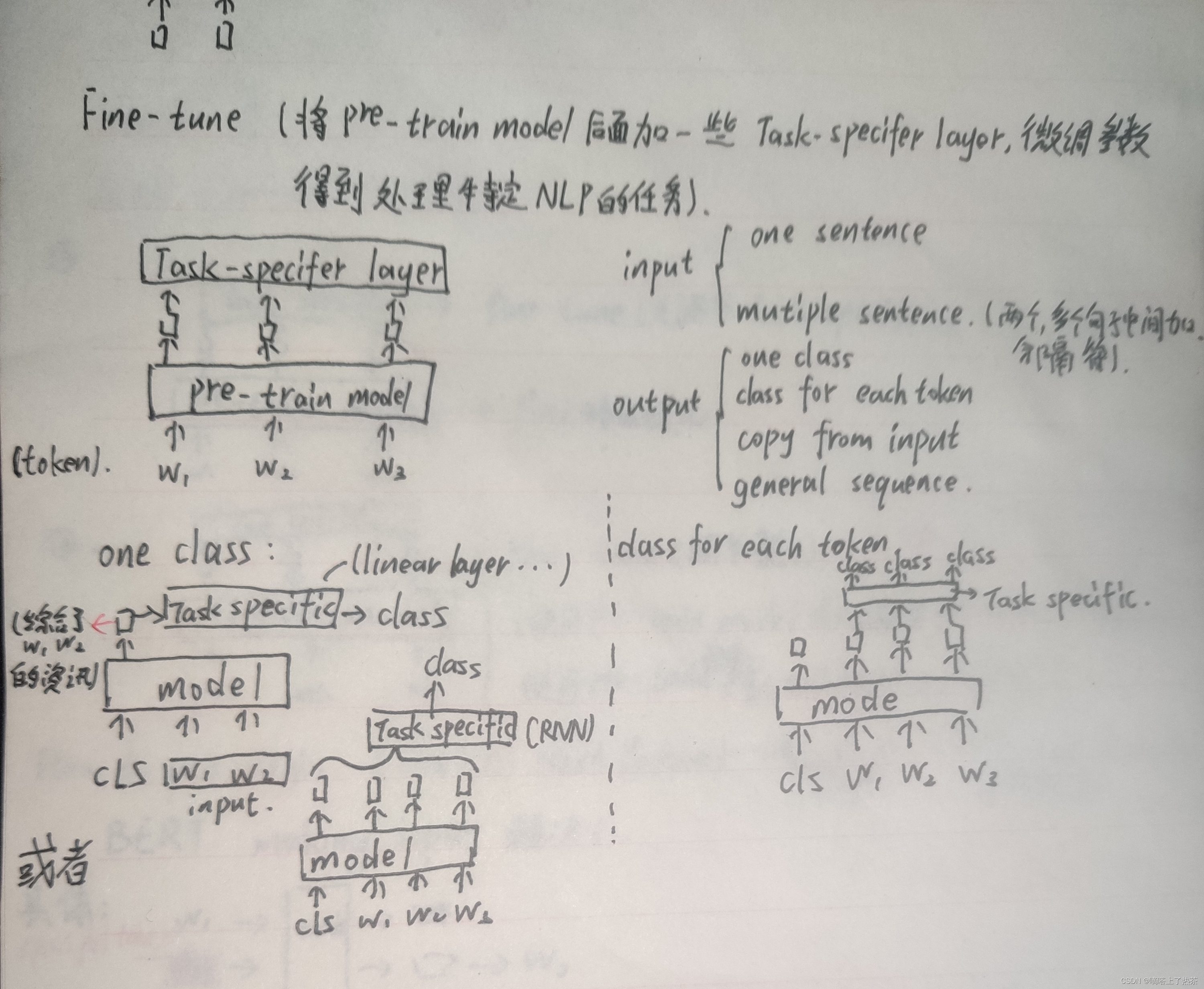
fine-tune的两种方式,一种是定住pre-train model的参数不动,只调节后面的下游任务(eg:linear的参数),还有一种是将pre-train和下游任务一起调参。
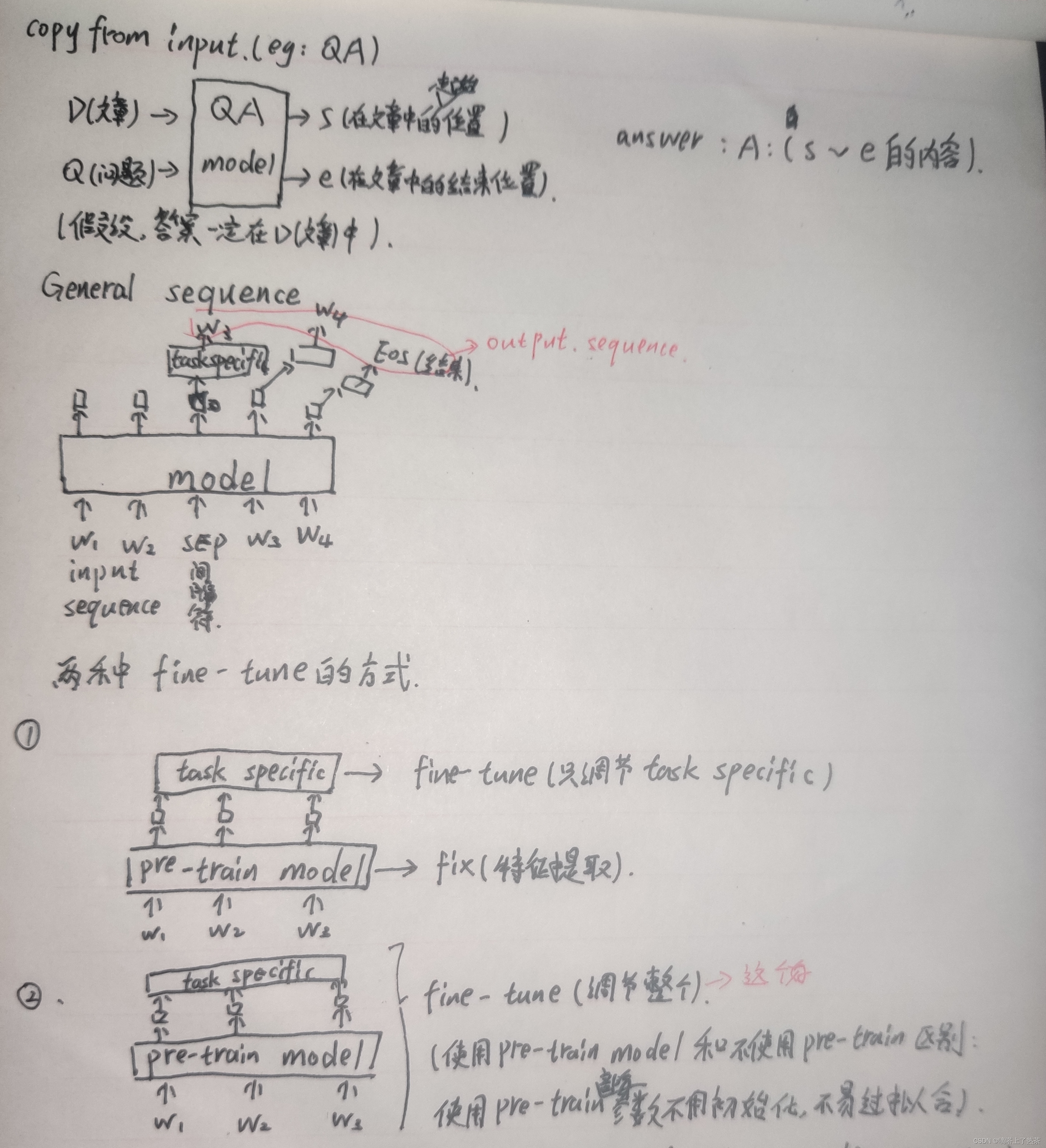
使用pre-train model的好处,可以防止过拟合,训练一个pre-train model可以用于多个下游任务。
4.BERT
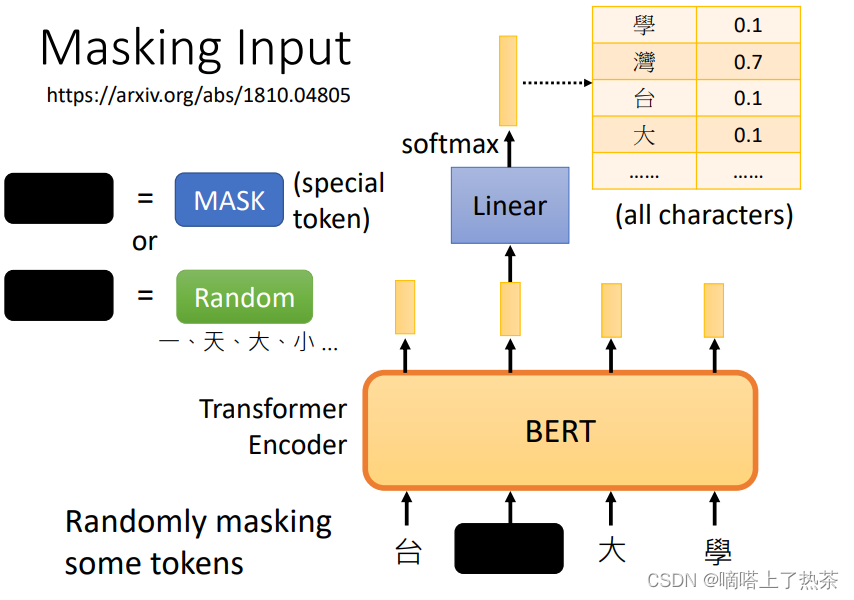
4.1 Masking Input(填空题)
现在详细说一下BERT,BERT的参数量很多。BERT的架构可以简单地看成跟Transformer中的Encoder的架构是相同的,其实现的功能都是接受一排向量,并输出一排向量(对等长度的)。而BERT特别的地方在于它对于接受的一排输入的向量(通常是文字或者语音等)会随机选择某些向量进行“遮挡”(mask),而进行遮挡的方式又分为两种:
- 是将该文字用一个特殊的字符来进行替代
- 是将该文字用一个随机的文字来进行替代
而这两种方法的选择也是随机的,因此就是随机选择一些文字再随机选择mask的方案来进行遮挡。然后就让BERT来读入这一排向量并输出一排向量,那么训练过程就是将刚才遮挡的向量其对应的输出向量,经过一个线性变换(复杂点也可以,看自己)模型(乘以一个矩阵)再经过softmax模块得到一个分布,包含该向量取到所有文字的所有概率(one-hot-vector),就拿答案的文字对应的one-hot-vector来与output的概率分布(向量)最小化交叉熵,从而来训练BERT和这个线性变换模块,总体可以看下图。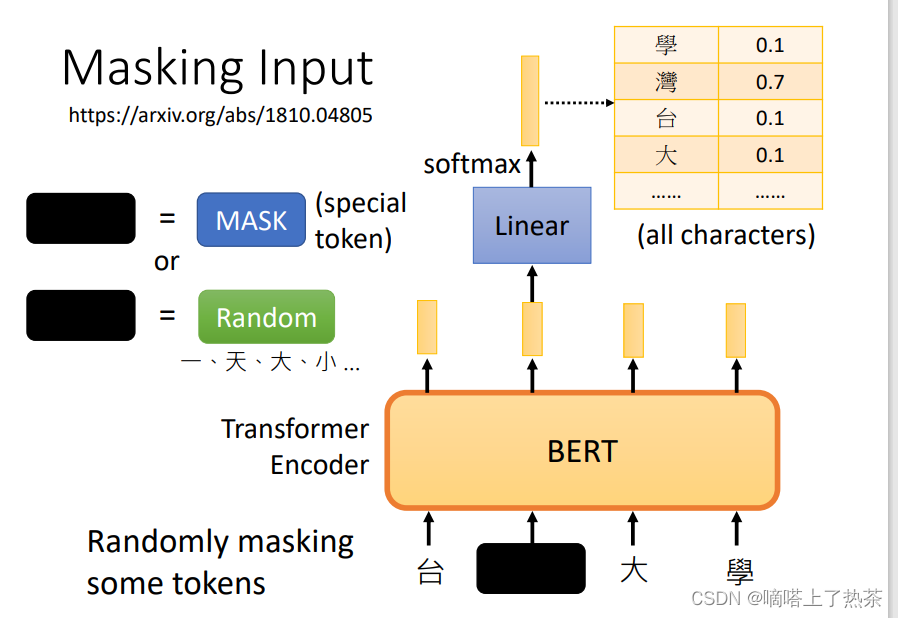
4.2 Next Sentence Prediction(判断题)
预测两个句子是不是应该被接在一起
- 先对两个句子进行处理,在第一个句子的前面加上一个特殊的成为CLS的向量,再在两个句子的中间加上一个特殊的SEP的向量作为分隔,因此就拼成了一个较长的向量集
- 将该长向量集输入到BERT之中,那么就会输出相同数目的向量
- 只关注CLS对应的输出向量,因此将该向量同样经过一个线性变换模块,并让这个线性变换模块的输出可以用来做一个二分类问题,就是yes或者no,代表这两个句子是不是应该拼在一起,大体流程如下图。
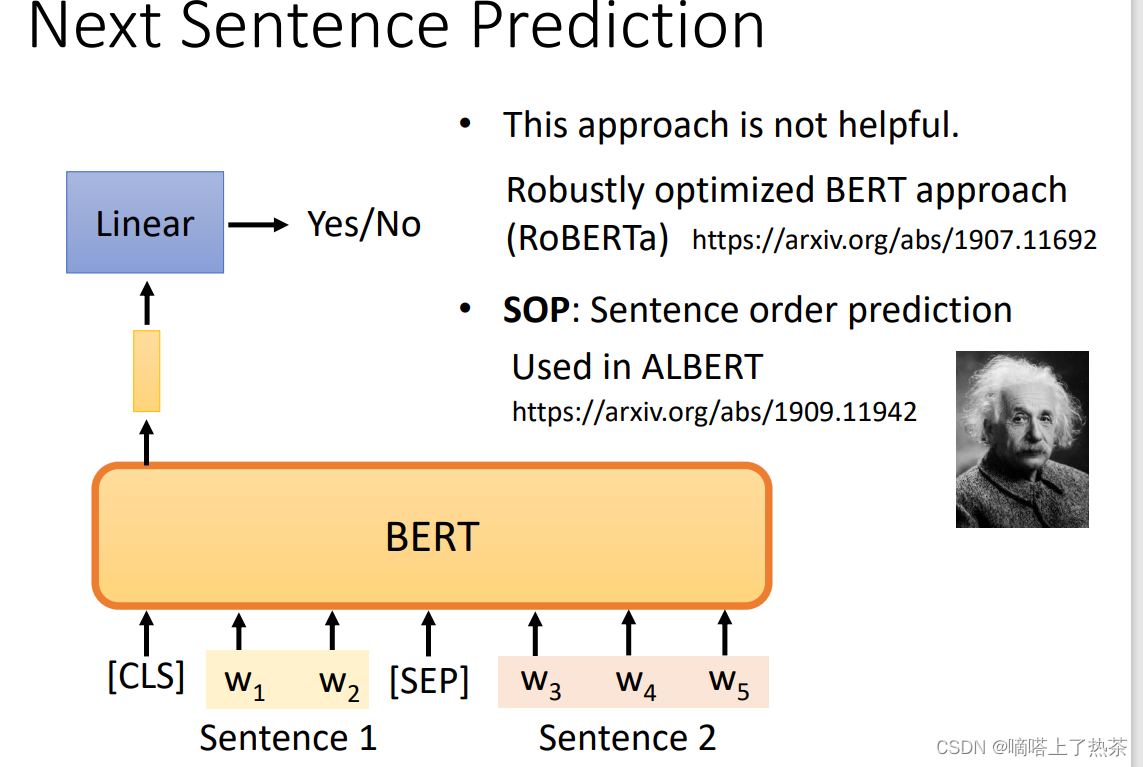
后来研究发现,对于BERT要做的任务来说,Next Sentence Prediction 并没有真正的帮助。它帮助不大可能的原因之一是,Next Sentence Prediction 太简单了,是一项容易的任务。
还有一种类似于Next Sentence Prediction 的方法,它看起来更有用,它被称为Sentence order prediction,简称SOP。
这个方法的主要思想是,我们最初挑选的两个句子可能是相连的。可能有两种可能性:要么句子1在句子2后面相连,要么句子2在句子1后面相连。有两种可能性,我们问BERT是哪一种。
也许因为这个任务更难,它似乎更有效。它被用在一个叫ALBERT的模型中,这是BERT的高级版本。
4.3 GLUE数据集
最有名的测试语言模型好坏的任务集是GLUE,它里面总共有9个任务,一般看语言模型在这9个任务集上的平均表现,下图是九个任务集。

4.4 How to use BERT
BERT在Pre-train产生后,经过fine-tune就可以做多种多样的任务。而BERT的真正任务是Downstream Tasks,它的前提是需要一些带有标记的数据。下面介绍使用BERT的几个小案例
case1:情感分析
model是接受一个向量,输出一个分类,例如做句子的情感分析,对一个句子判断它是积极的还是消极的。那么如何用BERT来解决这个问题呢,具体的流程如下:
- 在句子对应的一排向量之前再加上CLS这个特殊字符所对应的向量,然后将这一整排向量放入BERT之中
- 关注CLS对应的输出向量,将该向量经过一个线性变换(乘上一个矩阵)后再经过一个softmax,输出一个向量来表示分类的结果,表示是积极的还是消极的
而重要的地方在于线性变换模块的参数是随机初始化的,而BERT中的参数是之前就pre-train model的参数,这样会比随机初始化的BERT更加高效。而这也代表我们需要很多句子情感分析的样本和标签来让我们可以通过梯度下降来训练线性变换模块和BERT的参数,如下图。
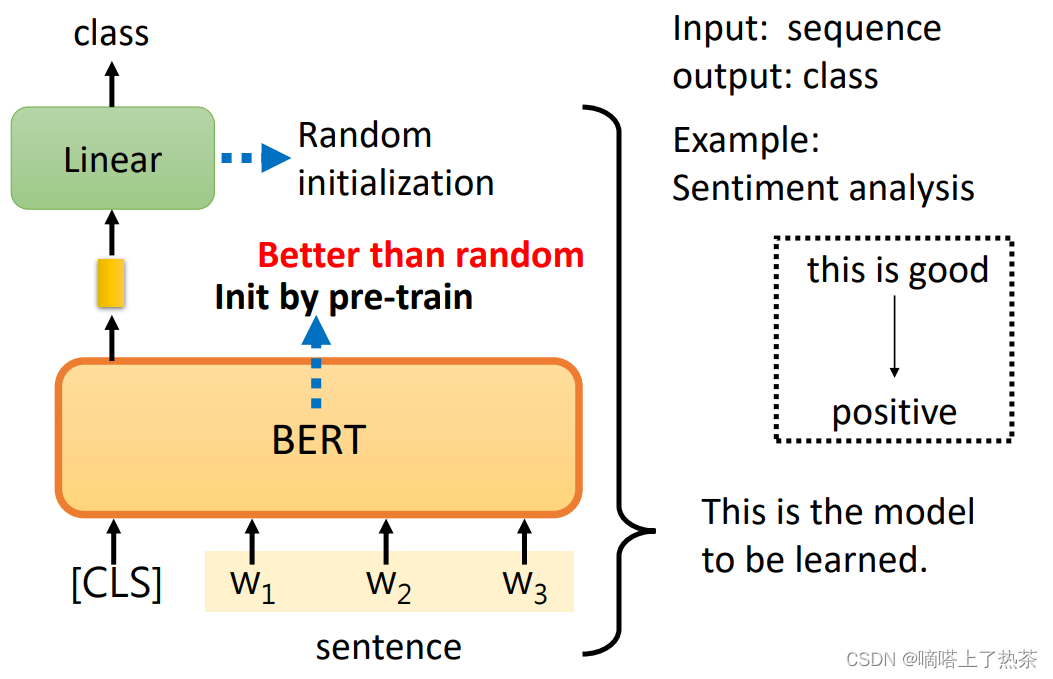
case2: 词性标注
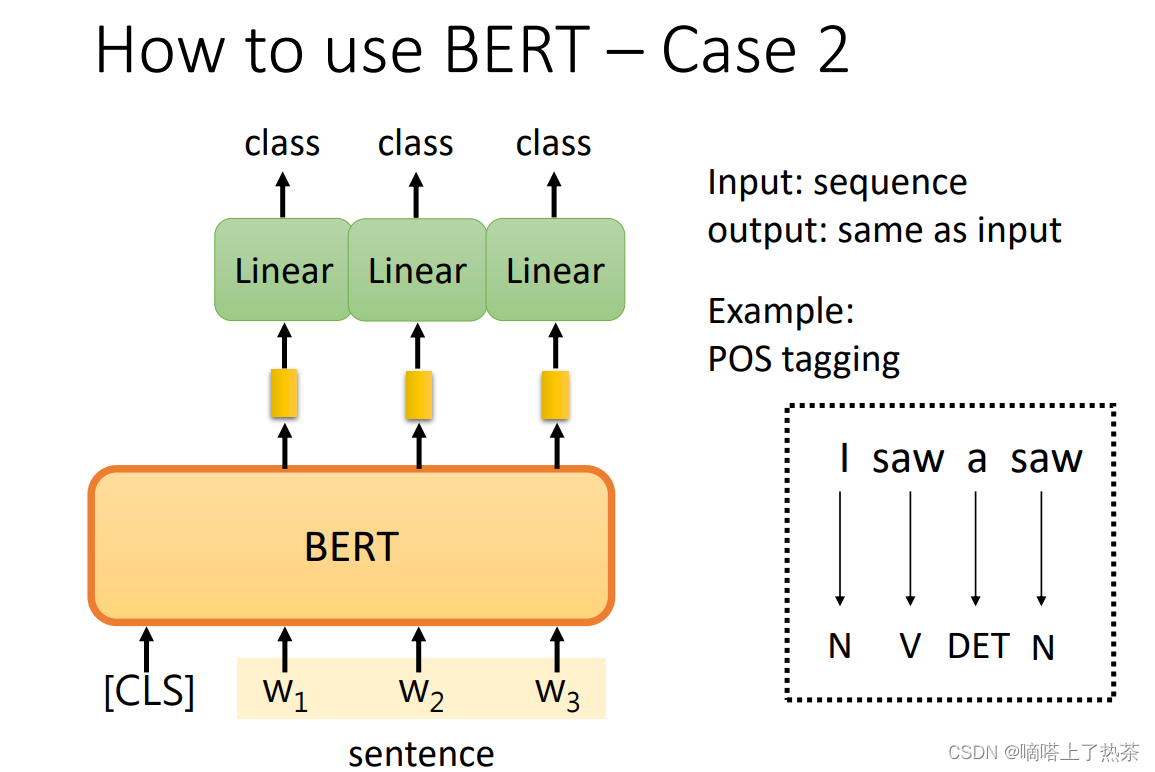
输入一个序列,然后输出另一个序列,而输入和输出的长度是一样的。在Self-Attention的时候也举了类似的例子, 例如POS tagging,也就是词性标记的问题。所谓的词性标记,就是你给机器一个句子,它必须告诉你这个句子中每个词的词性,即使这个词是相同的,也可能有不同的词性。
你只需向BERT输入一个句子。之后,对于这个句子中的每一个标记,它是一个中文单词,有一个代表这个单词的相应向量。然后,这些向量会依次通过Linear transform和Softmax层。最后,网络会预测给定单词所属的类别,例如,它的词性,如下图。
case3:自然语言推断
在该任务中,输入是两个句子,输出是一个分类,例如自然语言推断问题,输入是一个假设和一个推论,而输出就是这个假设和推论之间是否是冲突的,或者是相关的,或者是没有关系的,如下图。
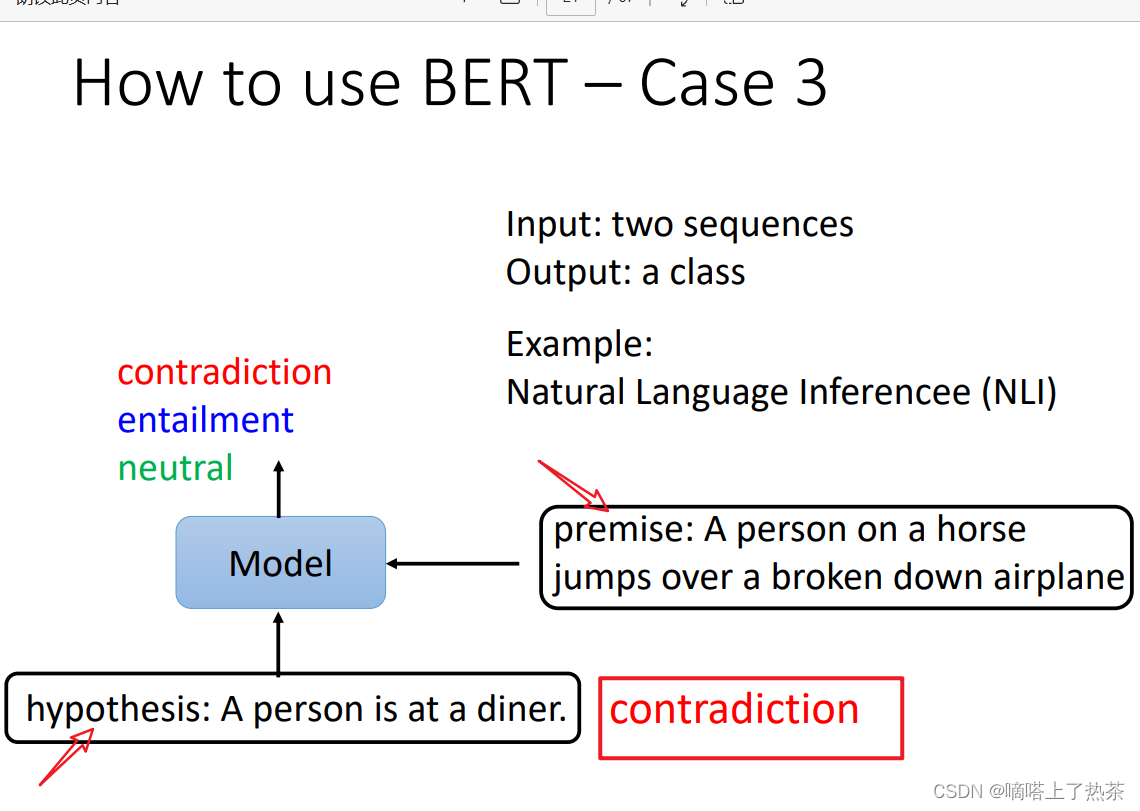
具体来说,还是将其当作分类问题,看下图。

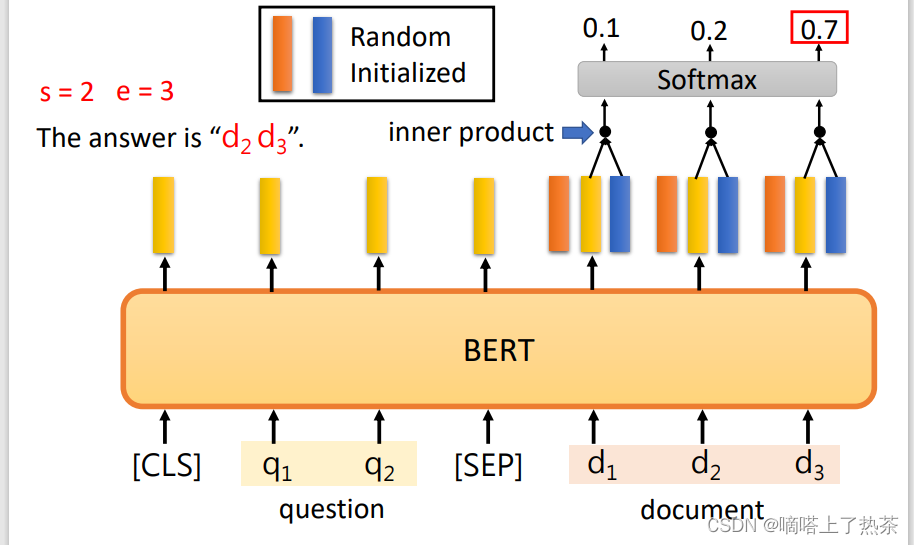
case4:QA问题(基于信息抽取的问答)
输入一篇文章和一个问题,输出问题的答案。(答案一定是出现在文章里的某个片段)输出是两个整数,代表了答案在文章中的起始位置和结束位置。

具体来说,是使用两个向量,与pre-train model所得到的向量进行inner product,得到概率分布,选出最大的概率位置当做起始位置。
找起始位置,如下图。

找结束位置,如下图。
4.5 Multi-lingual BERT
这个模型也就是用很多种语言来训练一个模型,有一个实验室表现了BERT的神奇之处,也就是用了104种语言Pre-trainBERT,也就是教BERT做填空题,然后再用英文的问答资料来教BERT做英文的问答题,再在测试集中用中文的问答题来测试BERT,它的结果如下,可以达到这个正确率真的很令人吃惊!
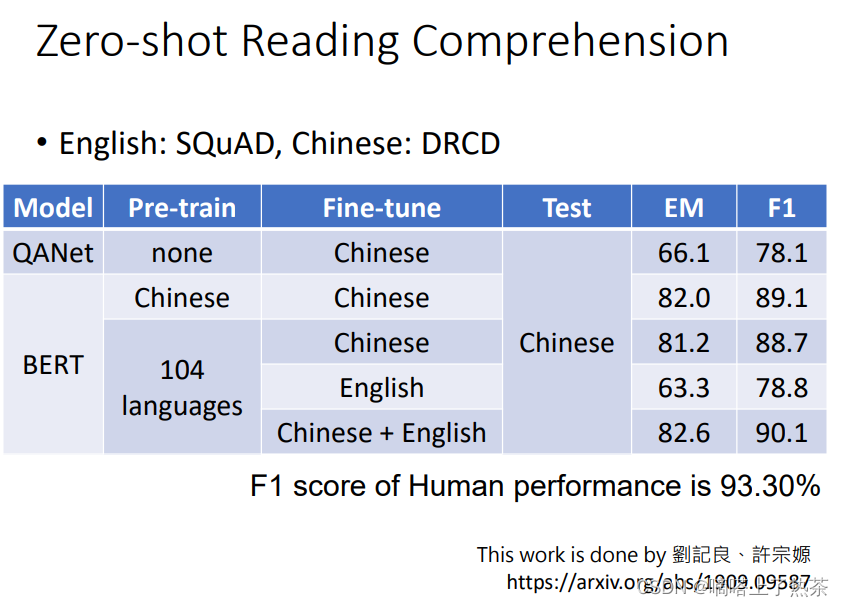
为何,能用英文做中文呢?猜测是中英文的输出的向量(embedding)比较接近,机器在学习大量语言后会自动学习这件事,就是学懂了中英文的语义。
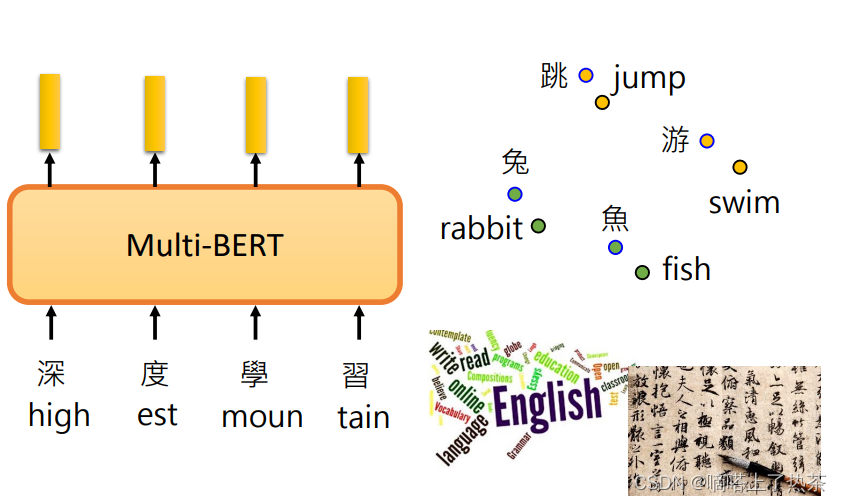
现在发现有一件神奇的事情是将中文的embedding与英文的embedding做差后,加上给Multi-lingual BERT输入英文训练后得到的向量后,就会变成中文的句子。因此给机器英文的问题,它就可以回复给你中文的答案。这证实了猜想,中英文的embedding确实是有关系的。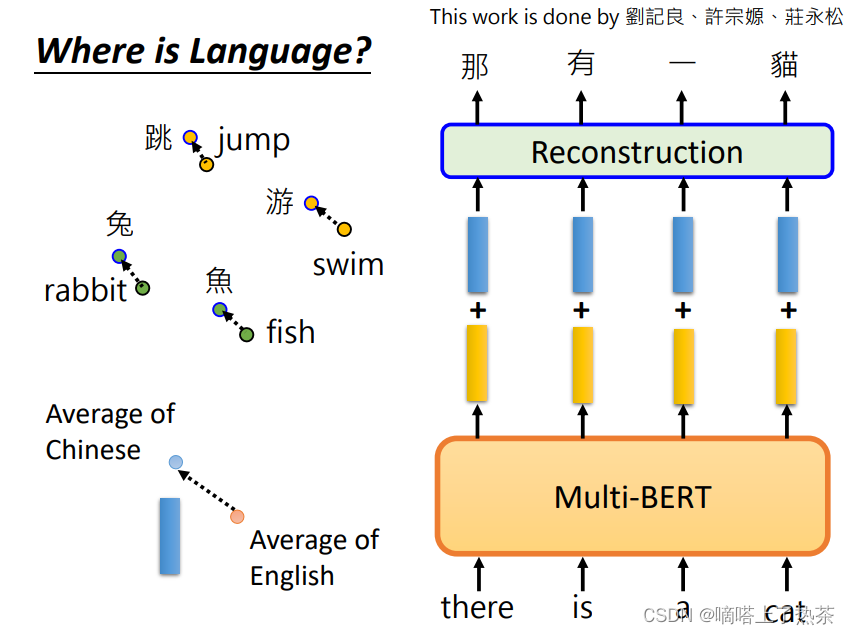
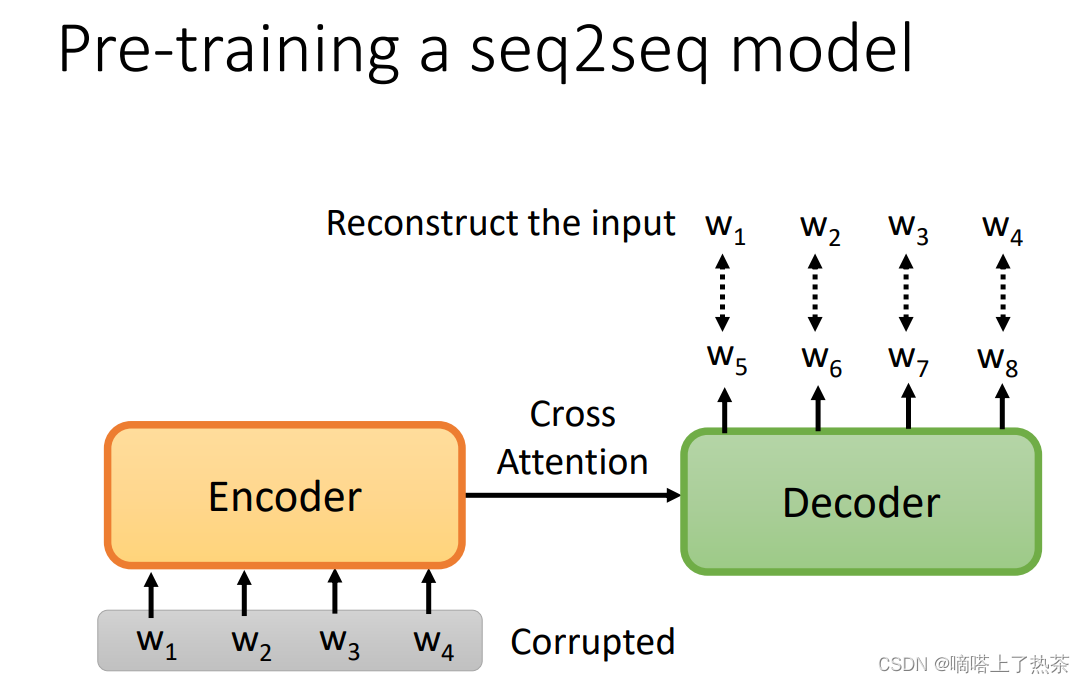
5.Pre-training a seq2seq model
如下图所示,对Encoder输入的句子进行Corrupted,希望Decoder的输出与被Corrupted前输入的句子越接近越好。
对输入的句子Corrupted的方法有很多种,把部分词语盖住、删除部分词语、打乱句子顺序、翻转整个句子、以及多种方法同时使用,如下图所示。
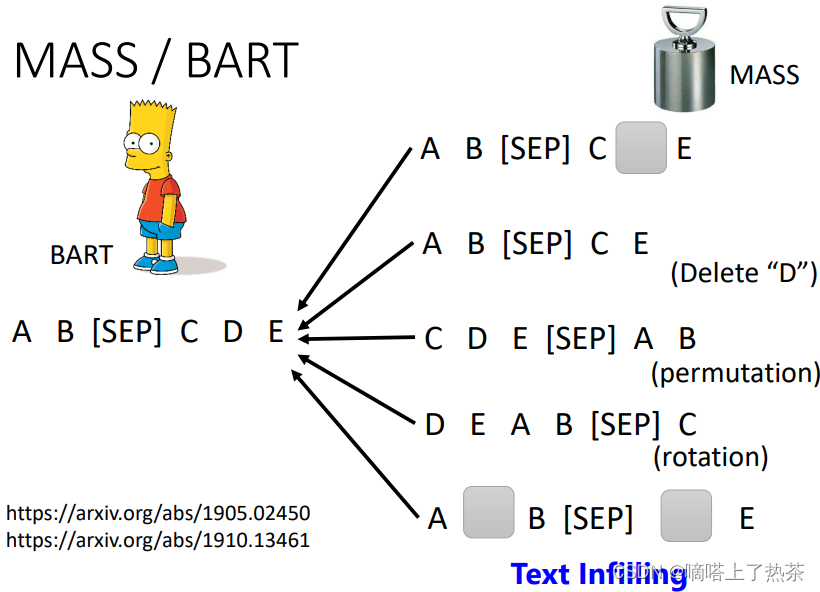
6.UniLM
这是一个神奇的model,这个可以当encoder,可以当decoder,也可以当SeqtoSeq,只需要调整中间的注意力机制,encoder使用没有限制的自注意力机制,decoder使用的是有限制的自注意力机制(只看左边),SeqtoSeq的左边使用没有限制的自注意力机制,右边使用有限制的自注意力机制(只看左边)。
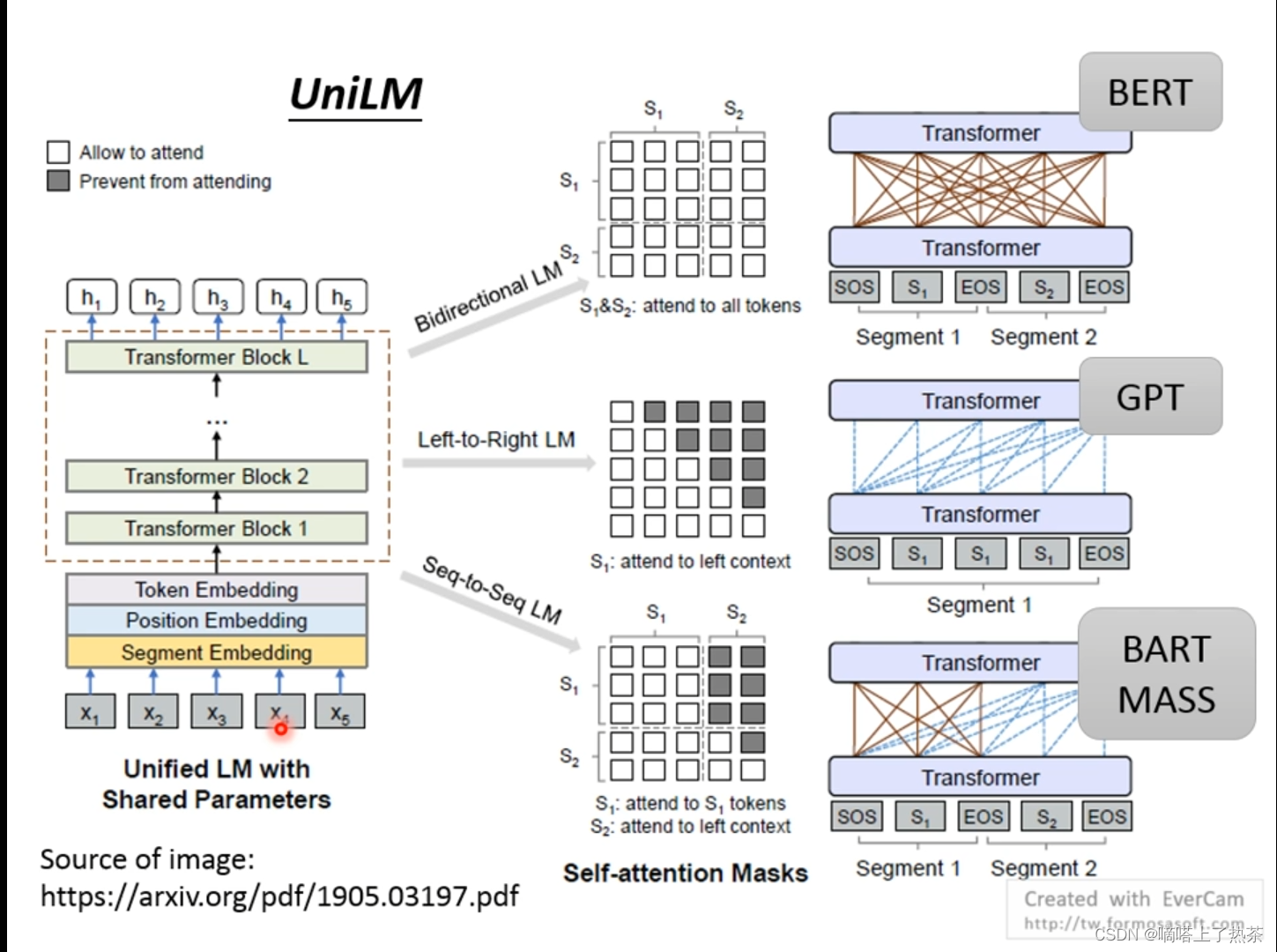
7.GPT-3
GPT是一个训练好的model,在解决问题时不用再调参数,直接就用来解决问题,按所给案例的多少分为下图的三类。

结果表明GPT的正确率比较低,随着参数量的增多,准确率也提高。
8.线性回归的例子
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#y=2x+0
# 输入数据
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 前向传播,model函数
def forward(x):
return x * w + b
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred-y)
w_list = [] # 用于存储不同的w值
b_list = [] # 用于存储不同的b值
mse_list = [] # 用于存储对应的MSE值
# 循环遍历不同的w和b取值
for w in np.arange(0.0, 4.1, 0.1):
for b in np.arange(0.0, 2.0, 0.1):
print('w={}, b={}'.format(w, b))
l_sum = 0
# 计算每个样本的损失值
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
mse = l_sum / 3 # 计算均方误差
print('MSE={}'.format(mse))
w_list.append(w)
b_list.append(b)
mse_list.append(mse)
# 创建一个三维图形对象
fig = plt.figure()
ax = fig.add_subplot(111, projection='loss')
# 绘制三维散点图
ax.scatter(w_list, b_list, mse_list)
# 设置坐标轴标签
ax.set_xlabel('W')
ax.set_ylabel('B')
ax.set_zlabel('Loss')
# 显示图形
plt.show()
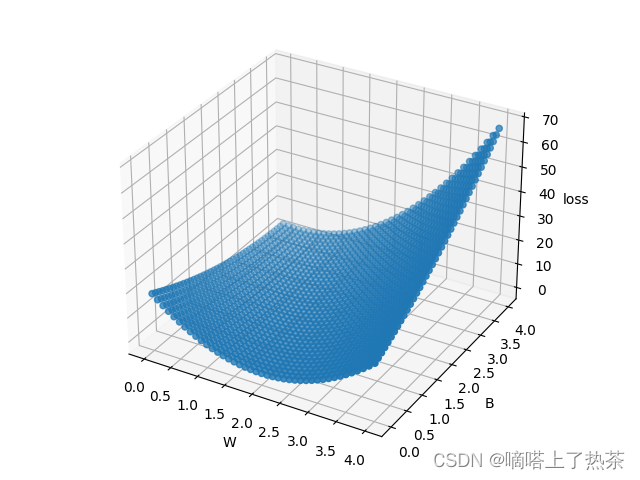
loss和w,b的关系如下图所示。
总结
本周学习了自监督学习的一些知识,了解了BERT的架构,还有一些别的pre-train model,pre-train model为各式各样的任务提供了方便,训练一个pre-train model可以用于多个下游任务。也了解到了GPT-3的大力出奇迹,使用参数多真的会有奇迹产生,还写了一些代码,慢慢入门pytroch这个库。
本周报参考以下博客:
https://blog.csdn.net/weixin_43992003/article/details/119298317
https://blog.csdn.net/weixin_51545953/article/details/128469678
https://blog.csdn.net/StarandTiAmo/article/details/126918207














 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









