






本篇博客,主要是记录自己在使用YOLO系列模型来训练自己的数据集时,遇到的标注格式转换问题与解决方案。本博客采用图文方式详细讲解并提供代码供大家使用讨论。
在转换过程中,遇到了很多问题,也一一进行了解决。
gitee源代码与文件目录示例:https://gitee.com/ming-ming-0201/voc2-yolo
train: voc的图片
train_xmls :voc的xml标注
voc2yolo.py: 将voc转成yolo
voc可视化:可视化xml标注
yolo划分: 将转换后的yolo划分为训练集与验证集
yolo可视化: 可视化yolo标注

1.VOC标注文件
我的VOC数据集有两个文件夹
train:存放的图片
train_xmls:存放的XML标注
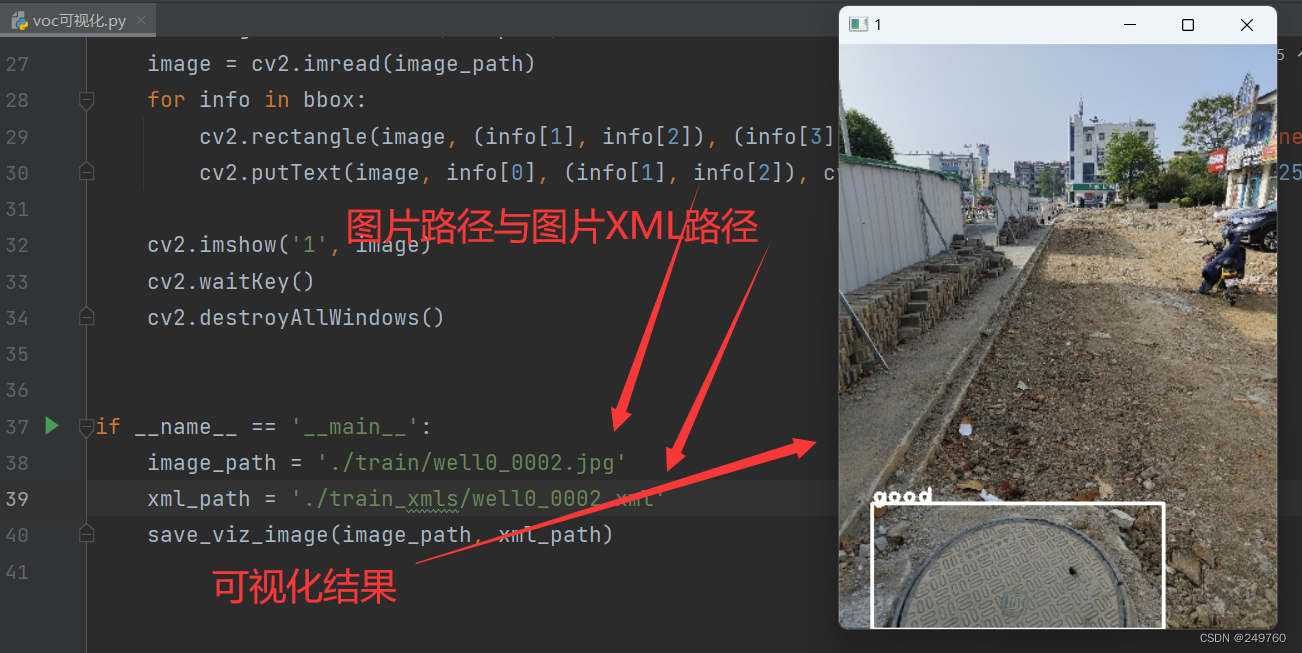
2.VOC可视化
import os
import cv2
import re
pattens = ['name', 'xmin', 'ymin', 'xmax', 'ymax']
def get_annotations(xml_path):
bbox = []
with open(xml_path, 'r') as f:
text = f.read().replace('\n', 'return')
p1 = re.compile(r'(?<=<object>)(.*?)(?=</object>)')
result = p1.findall(text)
for obj in result:
tmp = []
for patten in pattens:
p = re.compile(r'(?<=<{}>)(.*?)(?=</{}>)'.format(patten, patten))
if patten == 'name':
tmp.append(p.findall(obj)[0])
else:
tmp.append(int(float(p.findall(obj)[0])))
bbox.append(tmp)
return bbox
def save_viz_image(image_path, xml_path):
bbox = get_annotations(xml_path)
image = cv2.imread(image_path)
for info in bbox:
cv2.rectangle(image, (info[1], info[2]), (info[3], info[4]), (255, 255, 255), thickness=2)
cv2.putText(image, info[0], (info[1], info[2]), cv2.FONT_HERSHEY_PLAIN, 1.2, (255, 255, 255), 2)
cv2.imshow('1', image)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == '__main__':
image_path = './train/well0_0002.jpg' # 图片路径
xml_path = './train_xmls/well0_0002.xml' # 图片对应的XML路径
save_viz_image(image_path, xml_path)
3.VOC转YOLO
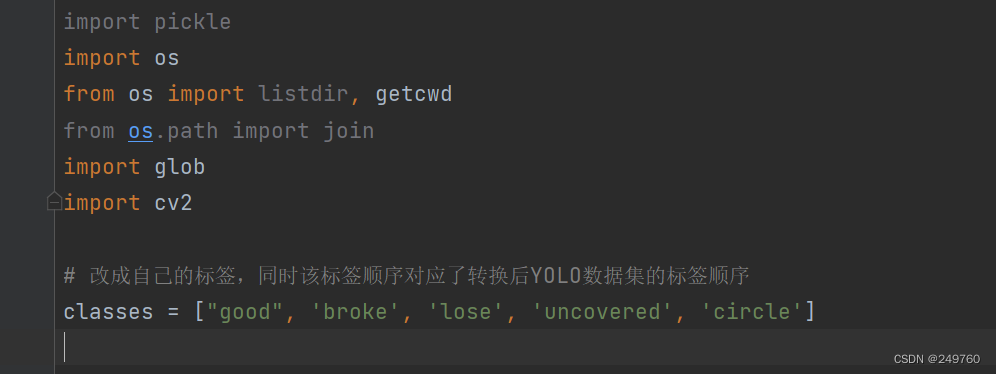
需要修改的地方,一共有 4 处,这里需要仔细去检查是否对应
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
import cv2
# 改成自己的标签,同时该标签顺序对应了转换后YOLO数据集的标签顺序
classes = ["good", 'broke', 'lose', 'uncovered', 'circle']
def convert(size, box):
dw = 1.0 / (size[0] + 1)
dh = 1.0 / (size[1] + 1)
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_name,img_path,xml_path,yolo_path):
in_file = open(xml_path + image_name[:-3] + 'xml') # xml存放路径
out_file = open(yolo_path + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
f = open(xml_path + image_name[:-3] + 'xml') # xml存放路径
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
img = cv2.imread(os.path.join(img_path,image_name)) # 图片存放路径
w = img.shape[1]
h = img.shape[0]
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
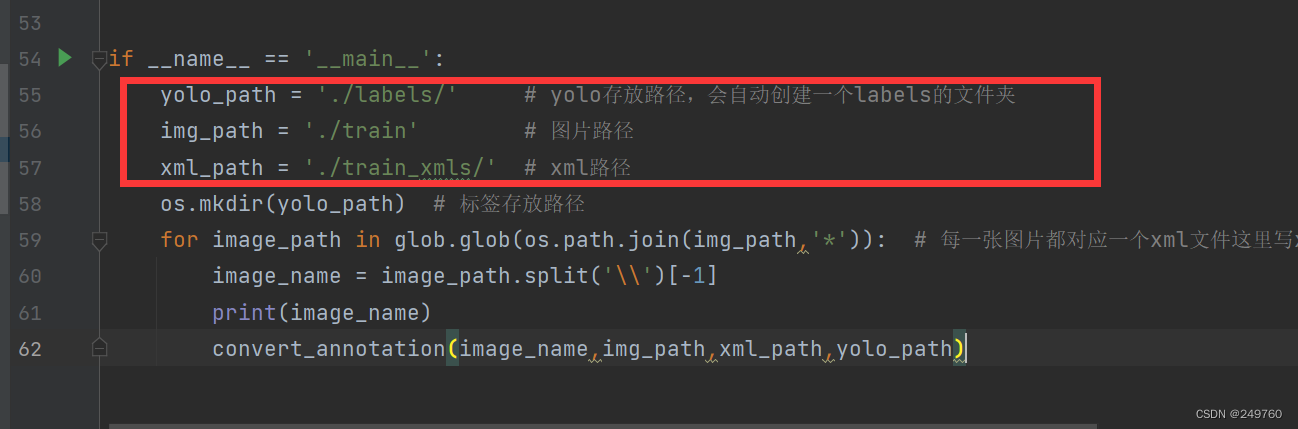
if __name__ == '__main__':
yolo_path = './labels/' # yolo存放路径,会自动创建一个labels的文件夹
img_path = './train' # 图片路径
xml_path = './train_xmls/' # xml路径
os.mkdir(yolo_path) # 标签存放路径
for image_path in glob.glob(os.path.join(img_path,'*')): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径 修改5
image_name = image_path.split('\\')[-1]
print(image_name)
convert_annotation(image_name,img_path,xml_path,yolo_path)
4.YOLO可视化
import os
import numpy as np
import cv2
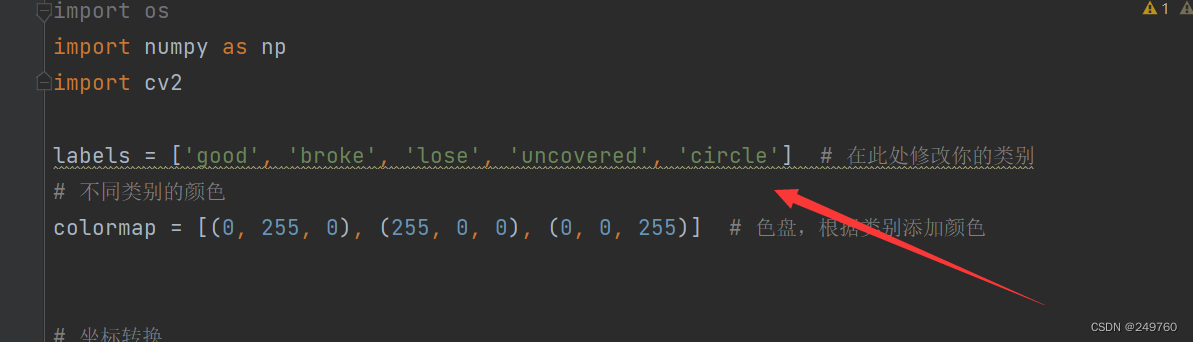
labels = ['good', 'broke', 'lose', 'uncovered', 'circle'] # 在此处修改你的类别
# 不同类别的颜色
colormap = [(0, 255, 0), (255, 0, 0), (0, 0, 255)] # 色盘,根据类别添加颜色
# 坐标转换
def xywh2xyxy(x, w1, h1, img):
label, x, y, w, h = x
# print("原图宽高:\nw1={}\nh1={}".format(w1, h1))
# 边界框反归一化
x_t = x * w1
y_t = y * h1
w_t = w * w1
h_t = h * h1
# print("反归一化后输出:\n第一个:{}\t第二个:{}\t第三个:{}\t第四个:{}\t\n\n".format(x_t, y_t, w_t, h_t))
# 计算坐标
top_left_x = x_t - w_t / 2
top_left_y = y_t - h_t / 2
bottom_right_x = x_t + w_t / 2
bottom_right_y = y_t + h_t / 2
# 绘制矩形框,使用与类别相关的颜色
#class_color = colormap[int(label)]
class_color = colormap[int(1)]
cv2.rectangle(img, (int(top_left_x), int(top_left_y)), (int(bottom_right_x), int(bottom_right_y)), class_color, 2)
# 在矩形框上方添加类别信息
class_name = labels[int(label)]
text = f"{class_name}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.5
font_thickness = 1
text_size, _ = cv2.getTextSize(text, font, font_scale, font_thickness)
text_x = int(top_left_x)
text_y = int(top_left_y) - 5 # 调整文本位置
cv2.putText(img, text, (text_x, text_y), font, font_scale, class_color, font_thickness)
return img
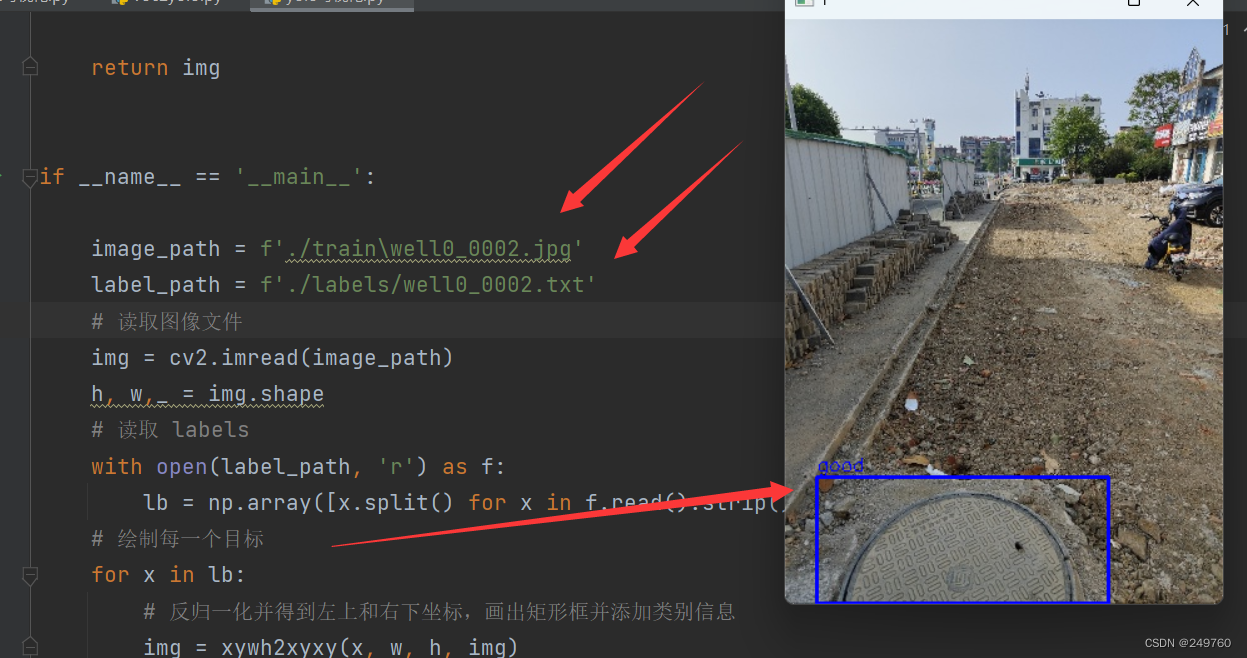
if __name__ == '__main__':
image_path = f'./train\well0_0002.jpg'
label_path = f'./labels/well0_0002.txt'
# 读取图像文件
img = cv2.imread(image_path)
h, w,_ = img.shape
# 读取 labels
with open(label_path, 'r') as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32)
# 绘制每一个目标
for x in lb:
# 反归一化并得到左上和右下坐标,画出矩形框并添加类别信息
img = xywh2xyxy(x, w, h, img)
cv2.imshow('1', img)
cv2.waitKey()
cv2.destroyAllWindows()
5.YOLO数据集划分
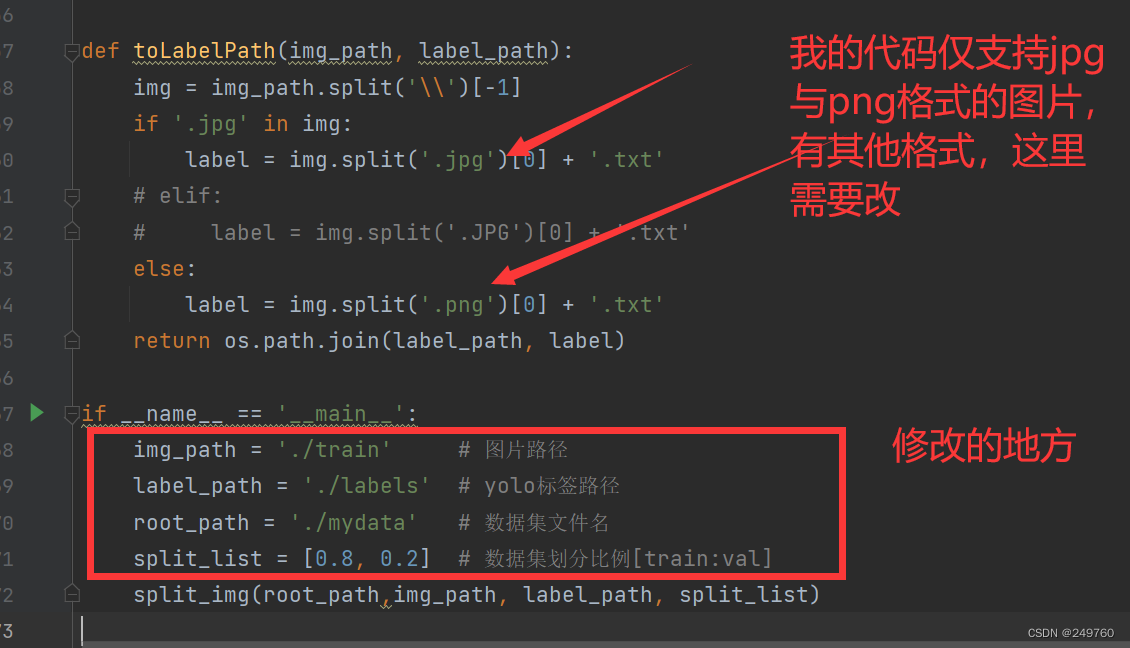
说明:由于我的数据集图片包含jpg和png格式,所以代码是这样的,如果大家有这两种格式之外的图片格式,可以在下图箭头的位置,增加代码以兼容。
我这里 训练:验证是8:2
import os
import shutil
import random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集 (8:2)
"""
def split_img(root_path,img_path, label_path, split_list):
try: # 创建数据集文件夹
Data = root_path
os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
except:
print('文件目录已存在')
train, val = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = all_img_path
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
if '.jpg' in img:
label = img.split('.jpg')[0] + '.txt'
# elif:
# label = img.split('.JPG')[0] + '.txt'
else:
label = img.split('.png')[0] + '.txt'
return os.path.join(label_path, label)
if __name__ == '__main__':
img_path = './train' # 图片路径
label_path = './labels' # yolo标签路径
root_path = './mydata' # 数据集文件名
split_list = [0.8, 0.2] # 数据集划分比例[train:val]
split_img(root_path,img_path, label_path, split_list)
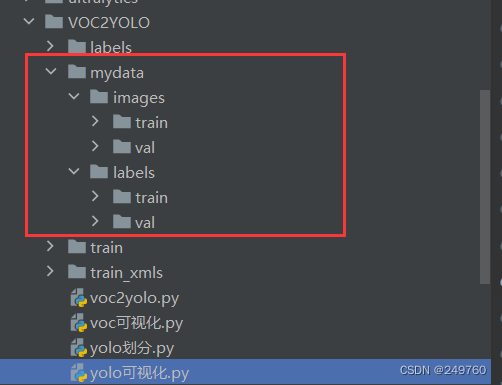
6.最终结果
结语
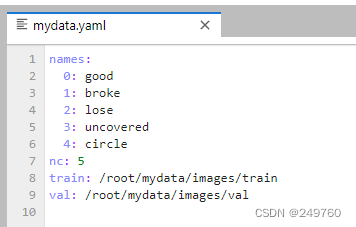
最终自己使用YOLOv8进行了训练,还需要自行构建yaml文件
需要注意的是,这个标签顺序必须和自己构建数据集时的标签顺序一致














 5937
5937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









