







《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》2025年1月发表,来自浙江大学、上海AI实验室、慕尼黑工大、同济大学和中科大的论文。
尽管自动驾驶技术取得了显著进步,但由于推理能力有限,数据驱动的方法仍然难以应对复杂的场景。与此同时,随着视觉语言模型的普及,知识驱动的自动驾驶系统也得到了长足的发展。本文提出了LeapVAD,这是一种基于认知感知和双过程思维的新方法。此方法实现了一种人类注意力机制,以识别和关注影响驾驶决策的关键交通因素。通过包括外观、运动模式和相关风险在内的综合属性来表征这些对象,LeapVAD实现了更有效的环境表示并简化了决策过程。此外,LeapVAD整合了一个创新的双过程决策模块,模拟了人类驾驶学习过程。该系统由一个通过逻辑推理积累驾驶经验的分析过程(系统II)和一个通过微调和少量学习完善这些知识的启发式过程(系统I)组成。LeapVAD还包括反射机制和不断增长的记忆库,使其能够从过去的错误中学习,并在闭环环境中不断提高其性能。为了提高效率,我们开发了一个场景编码器网络,该网络生成紧凑的场景表示,用于快速检索相关的驾驶体验。对CARLA和DriveArena这两款领先的自动驾驶模拟器进行的广泛评估表明,尽管训练数据有限,但LeapVAD的性能优于仅使用摄像头的方法。全面的消融研究进一步强调了其在持续学习和领域适应方面的有效性。
1. 研究背景与动机
-
问题定义:现有自动驾驶技术中,数据驱动方法依赖大量标注数据且缺乏复杂场景下的推理能力,而知识驱动方法(如基于视觉语言模型VLM)虽具备一定推理能力,但评估方法多为开环测试,无法反映动态交互环境。
-
核心挑战:如何构建一个能够持续学习、模仿人类认知过程的自动驾驶系统,以应对复杂场景和长尾问题。
-
创新点:提出LeapVAD框架,融合认知感知(人类注意力机制)与双过程思维(分析过程System-II + 启发式过程System-I),结合记忆库和反射机制,实现闭环环境下的持续优化。
2. 方法论
框架组成
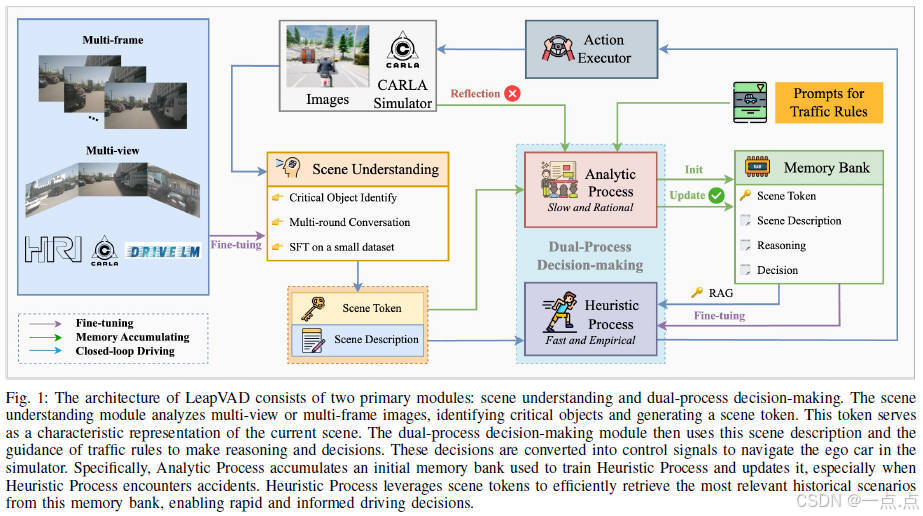
-
场景理解模块:
-
视觉语言模型(VLM):通过监督微调(SFT)生成关键交通对象的语义、空间、运动属性及行为推理描述(如车辆类别、位置、速度、风险等级)。
-
多帧输入:支持多视角和多帧数据,捕捉动态属性(如速度趋势、运动方向)。
-
数据结构:采用“总结-细化”格式,提升场景描述的全面性。
-
-
场景编码器:
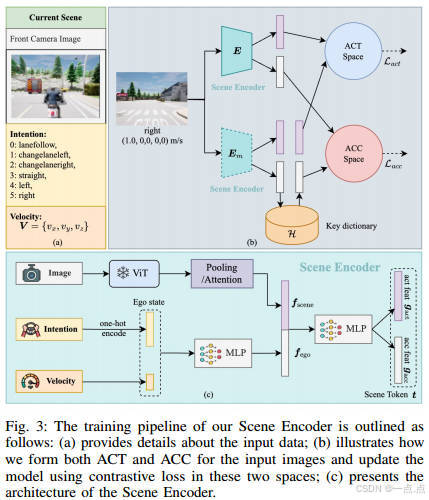
-
目标:生成紧凑的场景标记(Scene Token),用于快速检索相似历史场景。
-
对比学习框架:在动作空间(ACT,转向控制)和加速度空间(ACC,制动控制)中,通过对比学习优化特征表示。
-
动量编码器:通过动量更新策略(MoCo风格)维护历史特征字典,支持大规模负样本对比。
-
-
双过程决策模块:
-
分析过程(System-II):
-
基于LLM的逻辑推理,生成高质量驾驶决策(如变道、减速)。
-
通过闭环实验积累经验至记忆库,支持知识迁移。
-
反射机制:事故发生时,分析历史帧数据(描述、决策、推理),识别错误原因并生成修正策略,更新记忆库。
-
-
启发式过程(System-I):
-
基于轻量级LLM(如Qwen-1.8B),利用记忆库中的经验进行快速决策。
-
少样本提示(Few-shot Prompting):通过检索相似场景的样本,减少幻觉(Hallucination)并提升泛化能力。
-
-
-
控制器:
-
元动作生成:输出高层指令(如“加速AC”“左变道LCL”)。
-
PID控制:通过轨迹规划和跟踪,将元动作转化为底层控制信号(转向、油门、刹车)。
-
3. 实验与验证
实验平台
-
CARLA:Town05短途与长途基准测试,评估驾驶分数(DS)、路线完成率(RC)、违规分数(IS)。
-
DriveArena:高保真仿真环境,验证跨域泛化能力。
主要结果
-
CARLA性能:
-
Town05短途:LeapVAD以仅1/73的数据量(41K vs. 3M)达到接近SOTA(94.95 vs. 88.19 DS),较前作LeapAD提升5.3%。
-
Town05长途:DS提升42.6%,显著优于纯视觉方法。
-
-
DriveArena性能:
-
记忆库(CARLA训练)跨域迁移有效,ADS(驾驶分数)达45.52%,优于端到端方法(如VAD、UniAD)。
-
消融实验
-
VLM选择:Qwen-VL-7B在场景理解和推理能力上优于LLaVA和InternVL2。
-
场景标记设计:“池化+状态”方案(Precision@1达87.52%)优于文本嵌入(OpenAI Embedding)。
-
记忆库容量:容量越大(如4096),性能提升越显著。
-
少样本提示:3-shot设置效果最佳,较零样本提升显著。
4. 创新与贡献
-
双过程思维:模仿人类驾驶学习过程(新手→专家),结合逻辑推理(System-II)与快速反应(System-I)。
-
高效场景表示:通过对比学习生成场景标记,提升检索效率与决策一致性。
-
持续学习机制:反射机制与动态记忆库实现闭环优化,支持跨域知识迁移(如CARLA→DriveArena)。
-
数据效率:仅需少量标注数据(41K)即可达到SOTA性能,显著降低数据依赖。
5. 局限与未来方向
-
实时性:分析过程(System-II)依赖大模型推理,可能影响实时性,需进一步优化轻量化。
-
复杂场景泛化:极端天气、密集交通等场景的泛化能力需验证。
-
硬件部署:当前实验基于仿真环境,实际车载部署的算力与延迟问题待解决。
6. 结论
LeapVAD通过融合认知感知与双过程思维,构建了一个高效、可解释的自动驾驶框架。其核心创新在于模仿人类驾驶的持续学习机制,结合场景编码与记忆库技术,显著提升了复杂场景下的决策鲁棒性和数据效率。实验证明该方法在仿真环境中具有优越性能,为知识驱动自动驾驶提供了新的研究方向。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









