







论文:https://arxiv.org/pdf/2410.23262(waymo,自认为该开启了通过大模型输出自动驾驶轨迹和各种任务的“大模型范式”)
参考资料:https://zhuanlan.zhihu.com/p/4667962901(该文章很深入,在梳理论文时有许多参考该文章思考的地方)
尽量让模型寻找隐空间里不易被人类捕捉到的规则
局限:
(1)不能将相机与LIDAR或radar融合,3D空间推理有限;(2)sensor simulation来促进其闭环评估;(3)相较于传统model要更大的计算能力
1.整体框架:
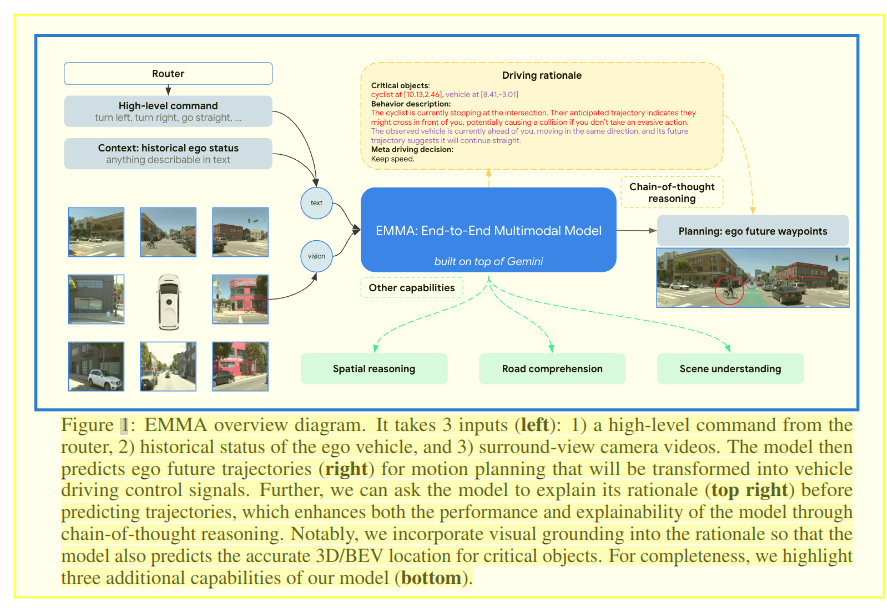
输入:(1)视觉(环视图像);(2)高维指令,如google地图的导航指令,"前方请在第二个匝道右转出匝道这种指令";(3)自车的历史轨迹等状态
输出:模型在预测轨迹之前解释其基本原理,通过思维链COT推理增强了模型的性能和可解释性。模型还预测关键对象的准确 3D/BEV 位置,如图中下面模型的三个附加功能
2.Method
![]()
O是T和V输入给G后的自然语言输出,接下里详细看下论文中这三个都表示什么:
(1)V:Surround-view camera videos提供复杂的环境信息
(2)T:分成Tintent和Tego
Tintent:高维的意图指令,如直行、左转、右转等
Tego:自车的历史轨迹,BEV下一系列的坐标点,坐标为纯文本形式。也可以扩展更高阶的速度和加速度
(3)O:用一系列在BEV空间下的轨迹点表示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









