







机器学习笔记第一章
机器学习:让机器去学习
什么是机器学习:(垃圾邮件分辨例子)
图像识别:分辨这个图像是什么,(二分类问题、人脸识别、数字识别、)
MNIST数据集
机器学习算法:KNN、线性回归、多项式回归、逻辑回归、模型正则化、PCA、SVM、决策树、随机森林、集成学习、模型选择、模型调整。
介绍如何使用算法
-如何评价算法的好坏
-如何解决过拟合和欠拟合
-如何调节算法的参数
-如何验证算法的正确性
scikit-learn机器学习库使用
技术栈:
语言:python3
框架:scikit-learn
其他:numpy,matplotlib
IDE: Jupyter Notebook
深蓝计算机:查找资料
梯度下降法的搜索策略
数据:鸢尾花数据集:https://en.wikipedia.org/wiki/lris_flower_data_set
矩阵:多少行说明有多少个样本,多少列说明有多少特征(属性)
最后一列,成为标记
大写字母表示矩阵,小写字母表示向量
特征空间
分类任务本质就是在特征空间切分
机器学习的基本任务
-分类任务
猫狗分类、数字分类:MNIST数据集
二分类任务
-判断猫狗
-判断邮件是否是垃圾邮件
-判断发放给客户信用卡是否有风险
-判断病患良性恶性肿瘤
-判断某支股票的涨跌
多分类任务
-数字识别
-图像识别
-判断发给客户信用卡的风险评级
-自动玩游戏的人工智能
多标签分类
-回归任务
结果是一个连续数字的值,而非一个类别
-房屋价格
-市场分析
-学生的成绩
-股票价格
一般情况下,回归任务可以简化为分类问题
机器学习的分类
机器学习可以分为:监督学习、非监督学习、半监督学习、增强学习
监督学习:
给机器的训练数据拥有“标记”或者“答案”的
例如:
-图像已经拥有了标定信息
-积累了一定的信息来进行训练
需要学习的关于监督学习的算法
-k近邻
-线性回归和多项式回归
-逻辑回归
-SVM
-决策树和随机森林
非监督学习:
给机器的训练数据没有任何“标记”或者“答案”
对没有“标记”的数据进行分类,叫做聚类分析
非监督学习的意义:
对数据进行降维处理
-特征提取:信用卡的信用评级和人的胖瘦无关?
-特征压缩:PCA (尽量少的损失特征的情况下,将高维的特征压缩成低维的特征)
-降维处理的意义:方便可视化
-异常检测
半监督学习:
一部分数据有“标记”或者“答案”,另一部分数据没有
生活中更常见:各种原因产生的标记缺失
通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测
增强学习:
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
机器学习的其他分类
批量学习:
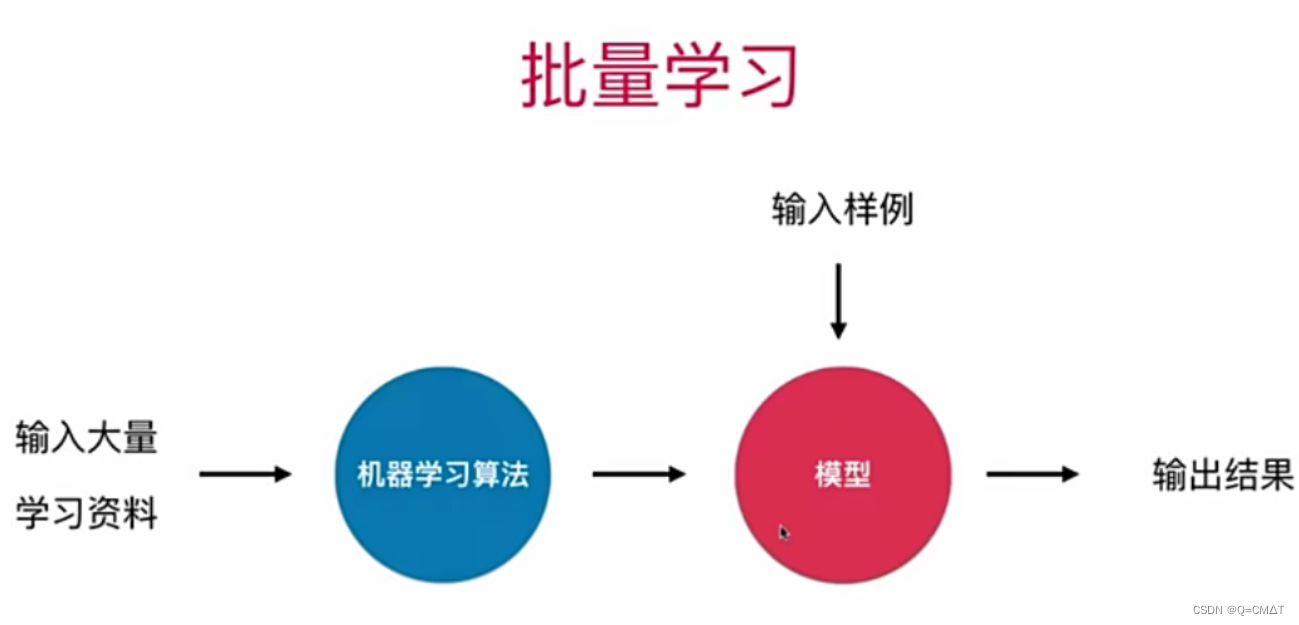
优点:简单
问题:如何适应环境的变化?
解决方案:定时重新批量学习
缺点:每次重新批量学习,运算量巨大。在某些环境下变化非常快的情况下,甚至是不肯能的。
在线学习:
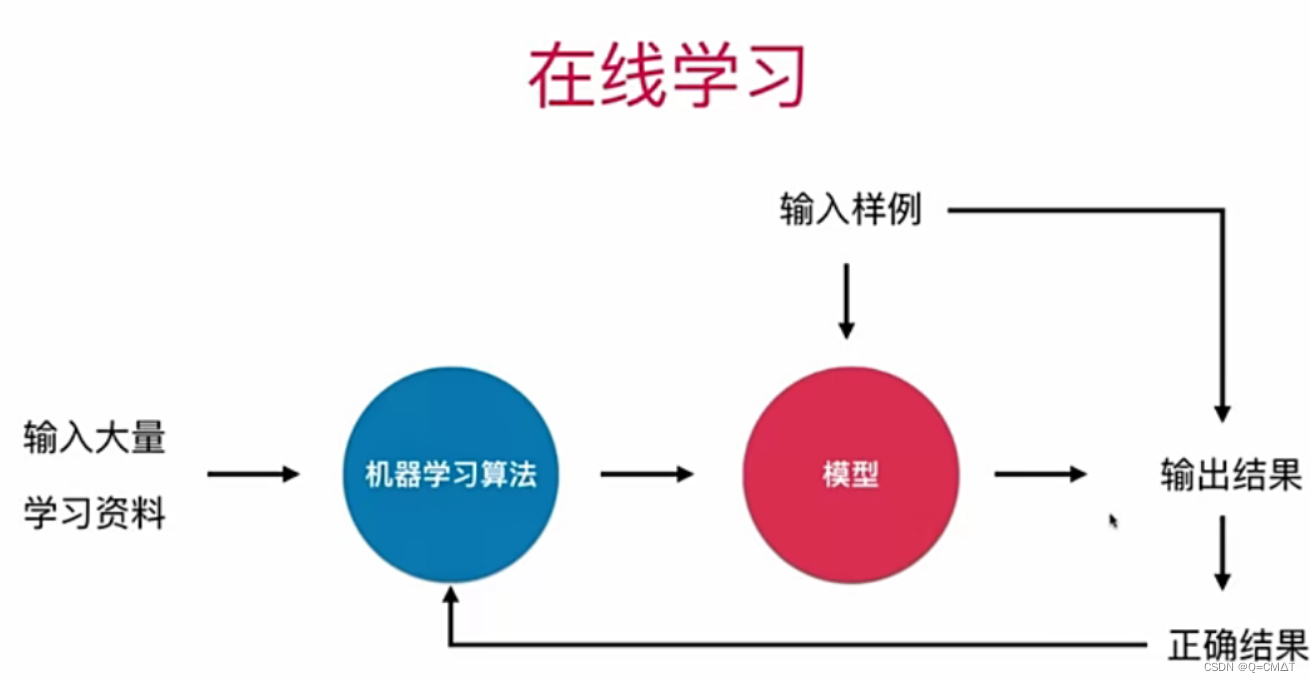
优点:及时反映新的环境变化
问题:新的数据带来不好的变化?
解决方案:需要加强对数据进行监控
其他:也适用于数据量巨大,完全无法批量学习的环境
参数学习:
特点:一旦学到了参数,就不再需要原有的数据集
非参数学习:
特点:不对模型进行过多的假设,非参数学习不等于没参数
和机器学习相关的“哲学”思考
数据即算法?
-数据确实非常重要
-数据驱动
-收集更多的数据
-提高数据质量
-提高数据的代表性
-研究更重要的特征
AlphaGo Zreo ---- Starting from scratch 所有的数据都是从零产生的
奥卡姆的剃刀
-简单的就是好的
-到底在机器学习领域,什么叫“简单”?
没有免费的午餐定理
-可以严格地数学推导出:任意两个算法,他们的期望性能是相同的!
-具体到某个特定问题,有些算法可能更好
-但没有一种算法,绝对比另一种算法好
-脱离具体问题,谈那个算法好坏是没有意义的
-在面对一个具体问题的时候,尝试使用多种算法进行对比试验,是必要的。
其他思考
-面对不确定的世界,怎么看待使用机器学习进行预测的结果?














 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









