







机器学习笔记第六章
过拟合和欠拟合
模型的泛化能力
泛化能力:由此及彼的能力。
测试数据集的意义:
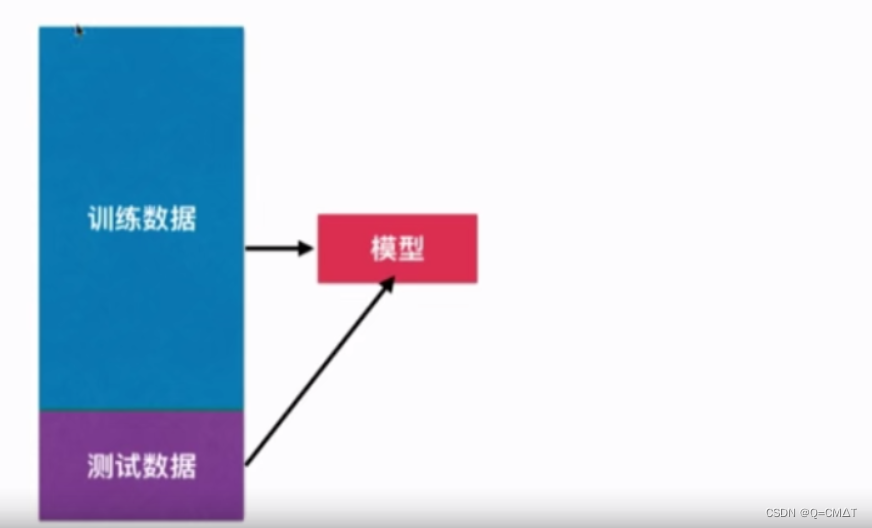
实验模型的复杂度,模型的degree越高,模型的复杂度越大
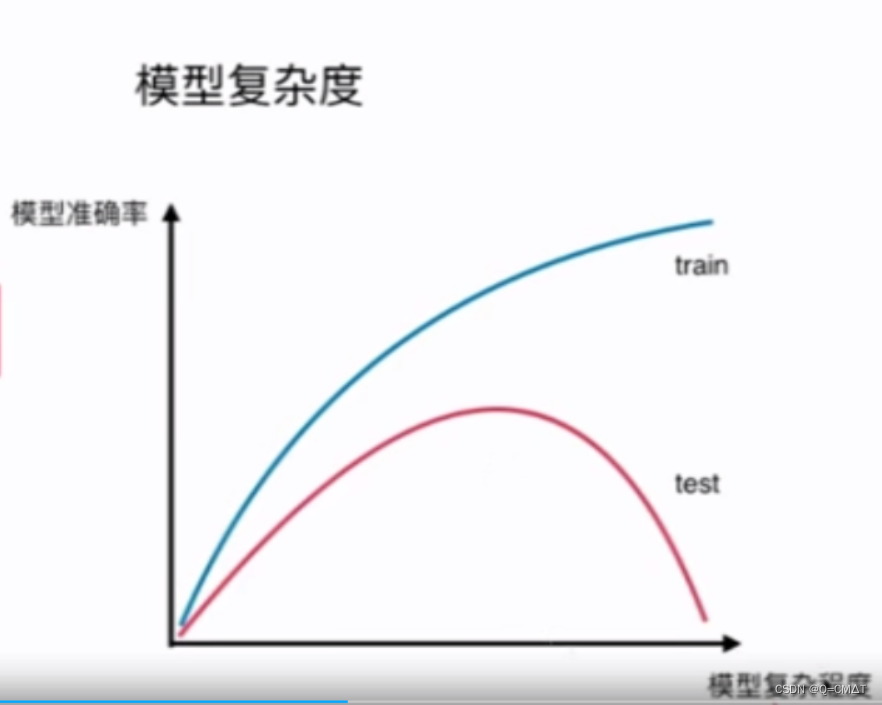
欠拟合(underfitting):
算法训练的模型不能完整的表述数据之间的关系
过拟合(overfitting):
算法所训练的模型过多的表达了数据之间的噪音关系
可视化看到模型的欠拟合和过拟合
学习曲线:随着训练样本的逐渐增多,算法训练出的模型的表现能力。
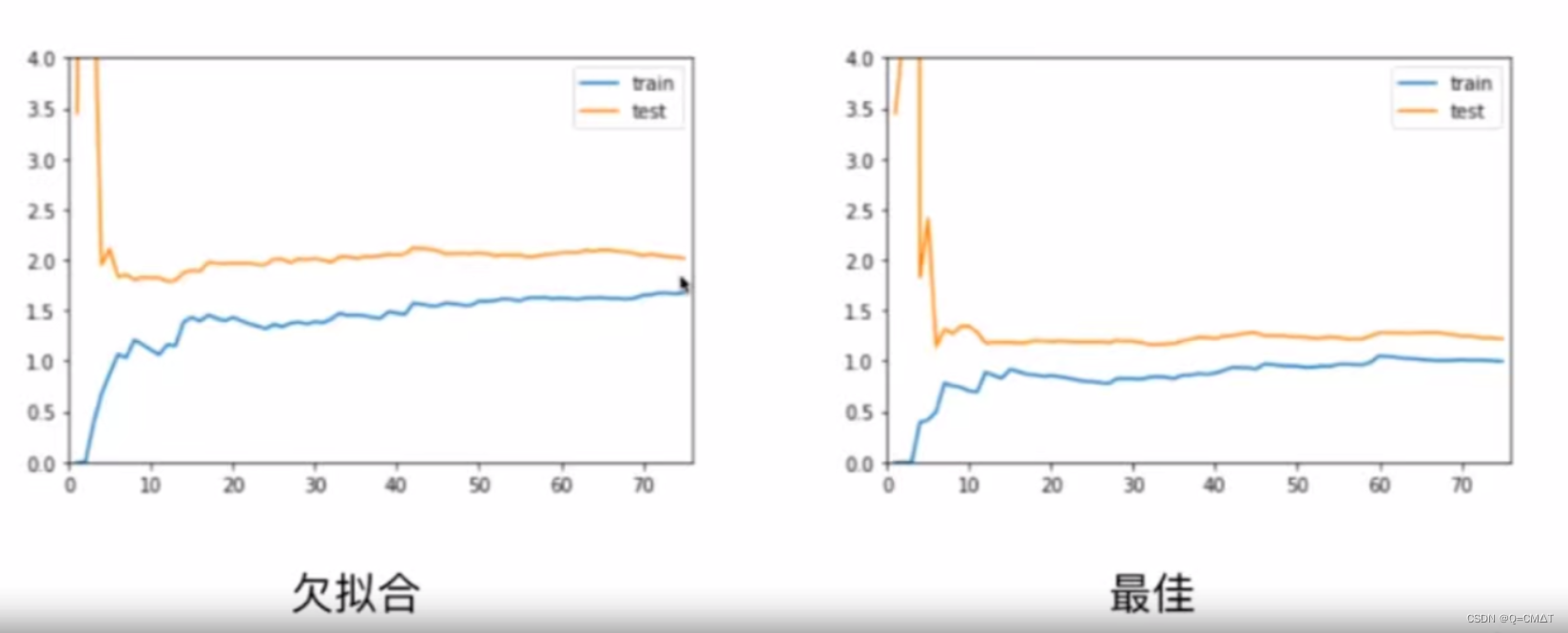
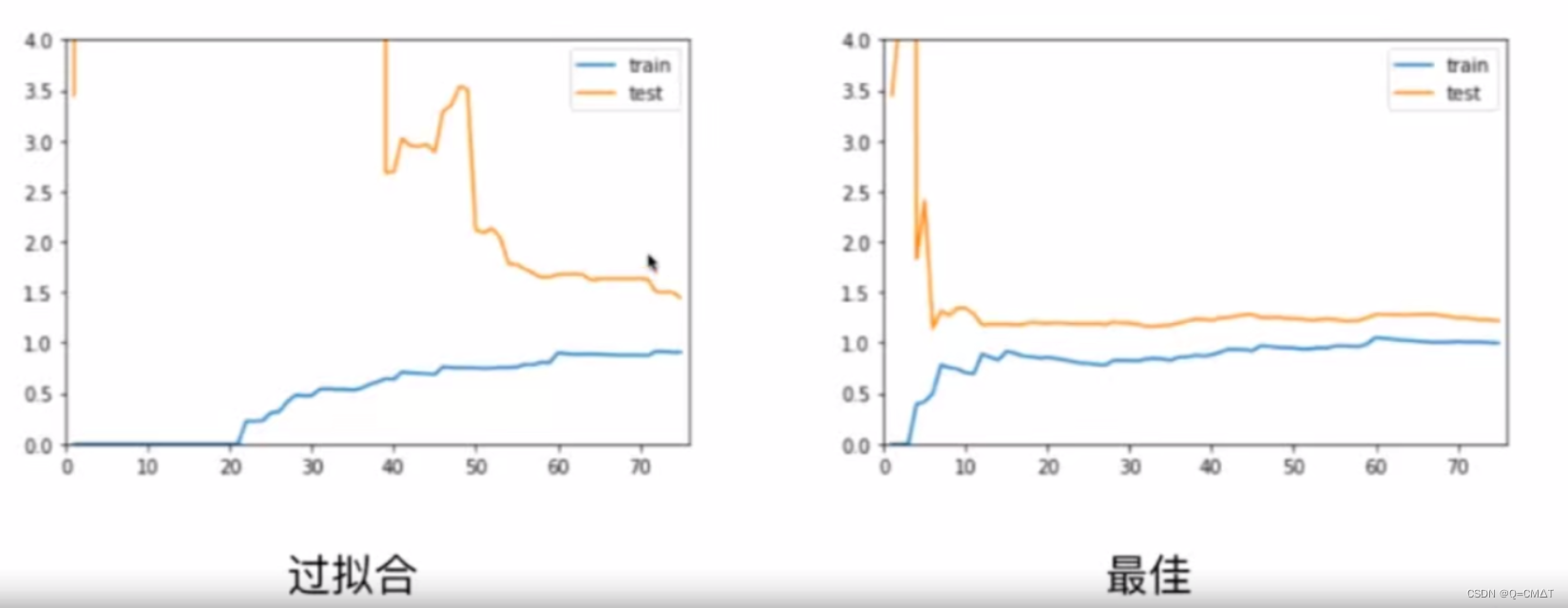
测试数据集的意义
过拟合的情况,进行调整参数,超参数来进行调整情况。
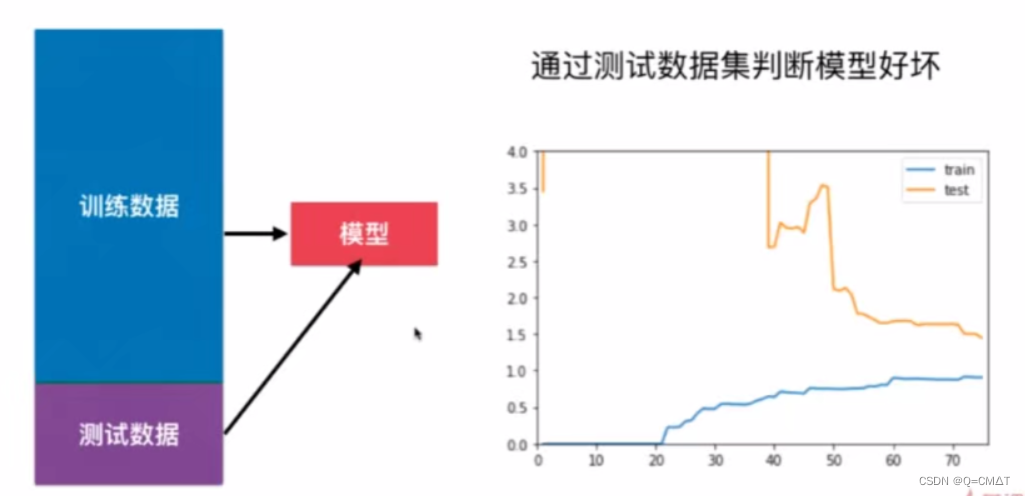
围绕着测试数据集打转,测试数据集是已经知道的,针对特定的测试数据集过拟合
解决办法:

增加一个验证数据集
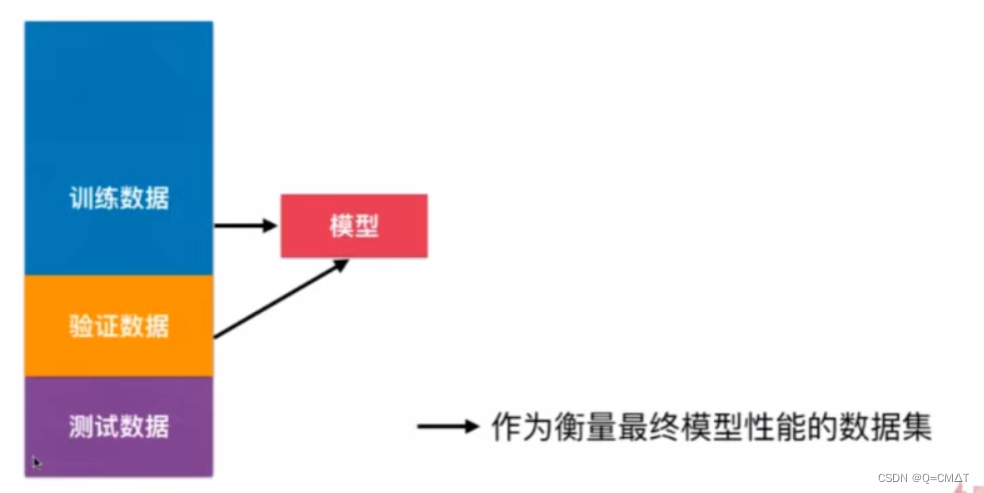
测试数据集不参与模型的训练。相当于是在模拟真正的测试。
验证数据集用来调整超参数来进行使用的。
validation_data 验证数据集
交叉验证 Cross Validation
训练数据分成多份
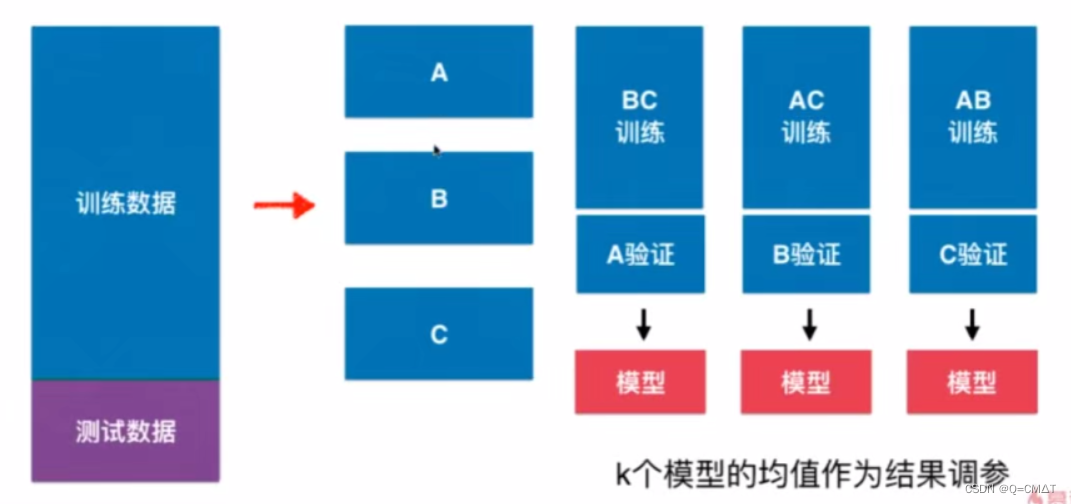
k-folds 交叉验证
把训练数据集分成k份,称为 k-folds cross validation
缺点,每次训练k个模型,相当于整体性能慢了k倍
留一法 LOO-CV
把训练数据集分成m份,称为留一法
完全不受随机的影响,最接近模型真正的性能指标
缺点:计算量巨大
偏差方差权衡 Bias Variance Trade off
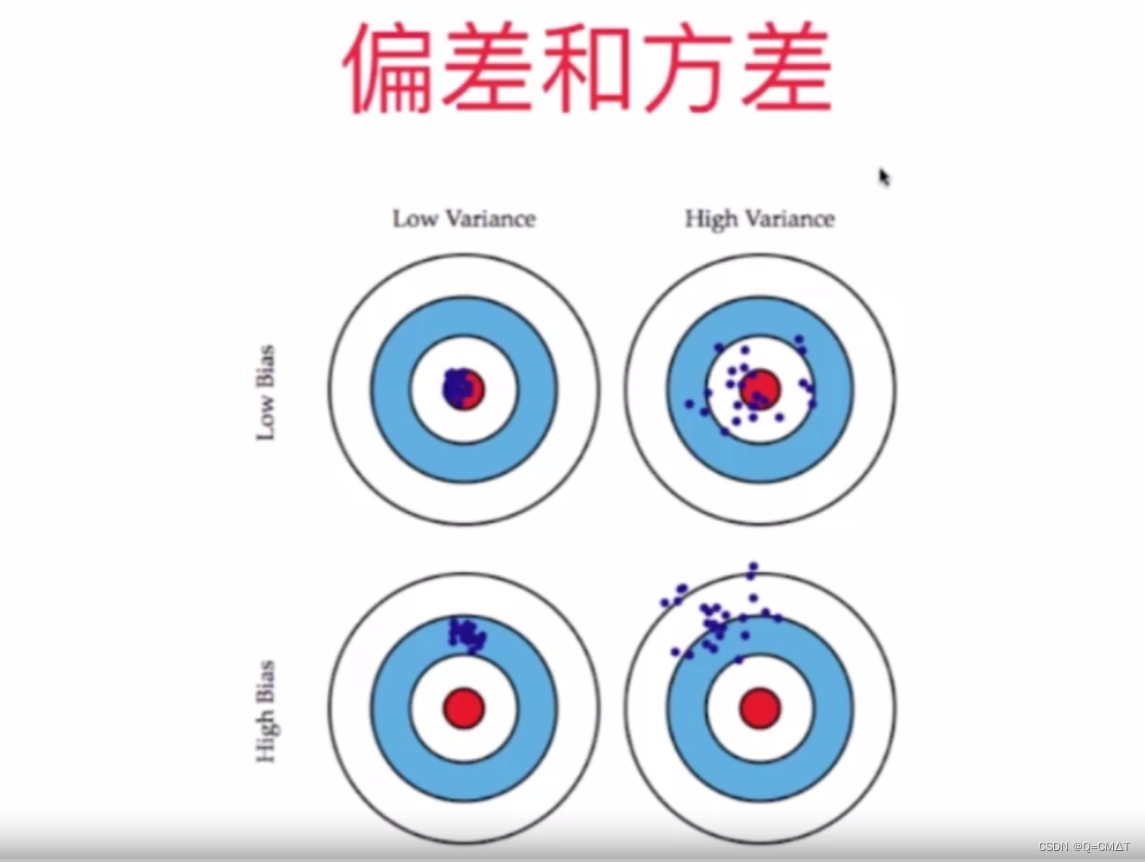
模型误差
模型误差: 偏差(Bias)+方差(Variance)+不可避免的误差
偏差:
导致原因:对问题本身的假设不正确,eg:欠拟合的例子
方差:
数据的一点点扰动都会较大地影响模型。
导致原因:使用的模型太复杂,rg:过拟合


k越小,说明模型越复杂。
偏差和方差通常是相互矛盾的。
降低偏差,会提高方差。
降低方差,会提高偏差。
方差:模型的泛化能力很差,overfitting,学习了过多的噪音
通常解决高方差的手段:
- 降低模型的复杂度
- 减少数据维度;降噪
- 增加样本数(深度学习,样本数量要足够大,神经网络)
- 使用验证集
- 模型的正则化
模型泛化与岭回归
模型正则化 (Regularization):限制参数的大小

岭回归(Ridge Regression)
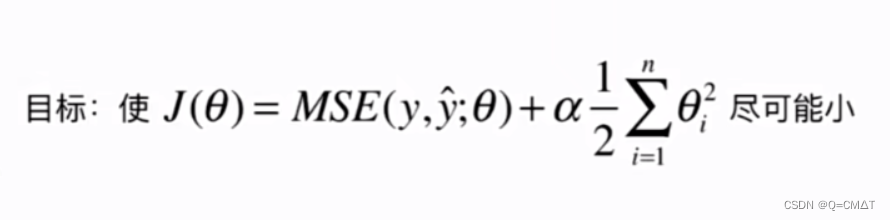
LASSO Regularization
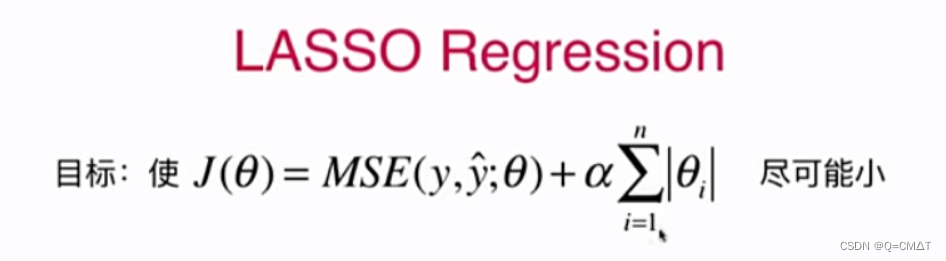
LASSO(Least Shrinkage and Selection Operator Regression)
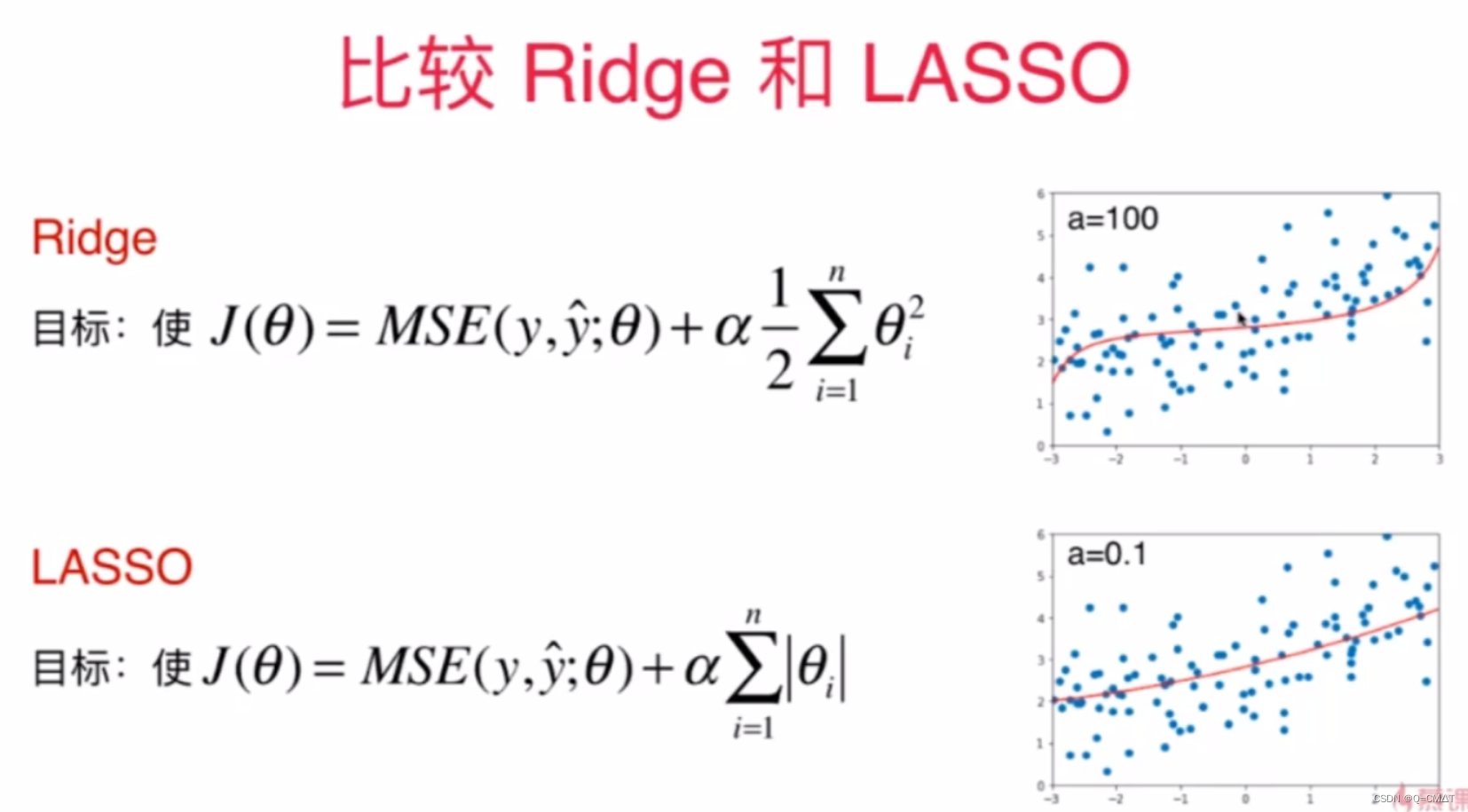

因为某些theta为0了,就可以用来进行特征的选择,相当于挑选一部分的特征进行计算。

L1、L2 和弹性网络
Lp范数
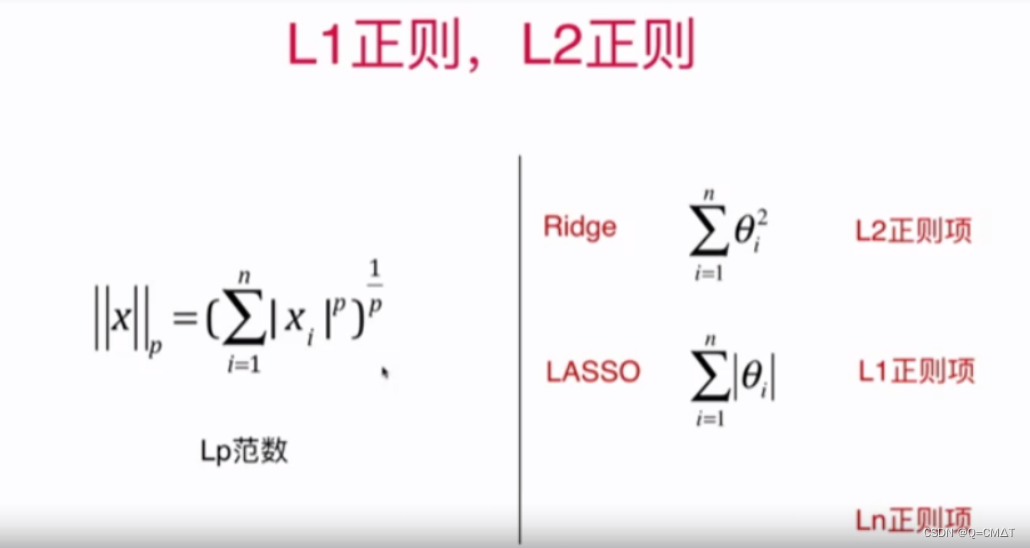
L0正则
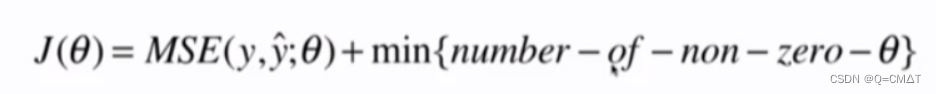
因为L0正则的优化是一个NP难的问题,所以通常不使用L0,而用L1来取代
弹性网 Elastic Net
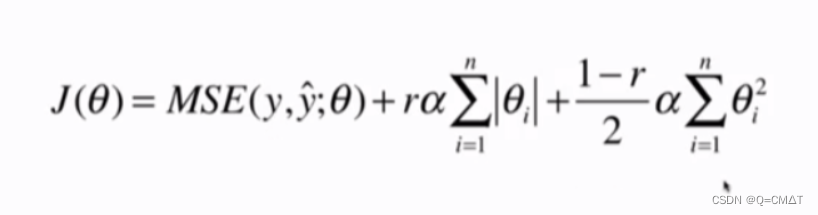
引入了 L1正则项和 L2正则项,同时结合了岭回归和LASSO的方式














 4059
4059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









