







前言
昨天师弟问我应该如何理解PCA,然后我又重新整理一下,也和大家聊一下主成分分析,英文 Principal Component Analysis,简称 PCA。其实它就是一个实用的工具,专门用来处理那种“特征太多”的数据。简单来说,PCA 能帮我们把复杂的数据“压缩”成更简单的东西,同时尽量不丢掉重要的信息。
比如说,你在研究房子数据,有一堆特征:面积、房间数、楼层、距离市中心的公里数、价格……光看这些就头晕了吧?PCA 就能把这些乱七八糟的特征“浓缩”成几个关键指标,让你一看就明白数据在讲啥。
这篇文章会用大白话把 PCA 讲清楚:它是什么、怎么来的、怎么用。会说一些具体的例子直观说明。后续也会持续更新其他算法,可以关注一下~
1. PCA 是什么?
主成分分析(PCA)是一种无监督学习方法,旨在通过线性变换将原始的高维数据映射到一个低维空间,同时尽可能保留数据的方差(即信息量)。简单来说,PCA 的目标是找到一组新的坐标轴(称为主成分),这些坐标轴能够捕捉数据中最大的变异性,并用更少的维度来近似表示原始数据。
关键名词:
- 维度:就是数据的“特征数量”。比如,房子的面积、房间数是 2 个维度,加个价格就变成 3 维。
- 降维:把维度变少。比如,原来有 10 个特征,降维后只剩 2 个。
- 主成分:PCA 找到的“新坐标轴”。这些新坐标轴是原来特征的某种组合,能抓住数据里最大的变化。
- 比如:如果数据是一堆散乱的点,主成分就像是你找到的最粗的那根“趋势线”,能概括大部分点的走向。
- 方差:数据的“散乱程度”。方差越大,说明数据点越分散,越能体现差异。
- 比如:如果所有学生的数学成绩都是 80 分,方差就很小;如果有人 100 分,有人 20 分,方差就很大。
2. PCA 的原理
我们一步步拆开,用例子讲明白它的原理。现假设我们有学生成绩的数据,来看看 PCA 怎么操作。
2.1 数据定义
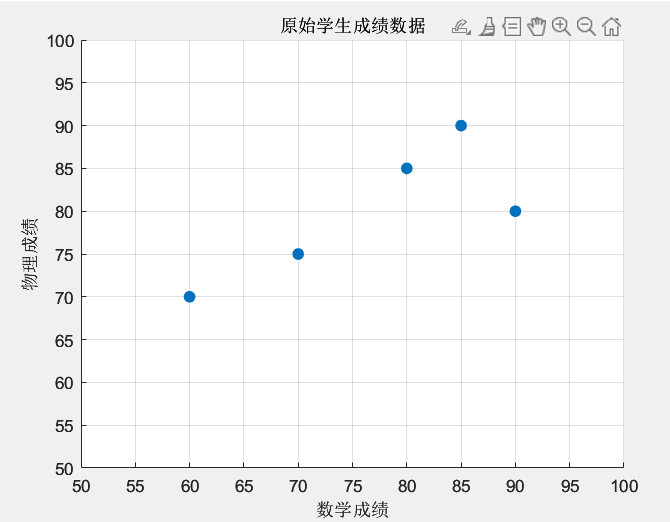
我们有 5 个学生的数学和物理成绩:
| 学生 | 数学成绩 | 物理成绩 |
| A | 80 | 85 |
| B | 90 | 80 |
| C | 70 | 75 |
| D | 60 | 70 |
| E | 85 | 90 |
把这些点画在图上(横轴是数学,纵轴是物理),你会发现它们差不多沿着一条斜线分布。因为数学和物理成绩通常相关:数学好的,物理一般也不差。PCA 的目标就是找到这条“斜线”,然后用它来简化数据。
2.2 PCA 计算步骤
步骤 1:数据中心化
首先,我们需要将数据中心化,即让每个特征的均值变为 0。
- 计算均值:
- 数学均值:(80 + 90 + 70 + 60 + 85) ÷ 5 = 77
- 物理均值:(85 + 80 + 75 + 70 + 90) ÷ 5 = 80
- 中心化后的数据(原始值减去均值):
- 数学:80-77=3, 90-77=13, 70-77=-7, 60-77=-17, 85-77=8
- 物理:85-80=5, 80-80=0, 75-80=-5, 70-80=-10, 90-80=10
中心化后数据表格:
| 学生 | 数学(中心化) | 物理(中心化) |
| A | 3 | 5 |
| B | 13 | 0 |
| C | -7 | -5 |
| D | -17 | -10 |
| E | 8 | 10 |
步骤 2:计算协方差矩阵
这是PCA的核心之一,协方差矩阵反映了特征自身的方差和特征之间的相关性。(这里不再给出具体公式,直接计算更直观)
- 协方差矩阵:
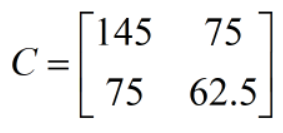
步骤 3:特征值分解
这是PCA的核心之一,我们需要对协方差矩阵进行特征值分解,得到主成分的方向(特征向量)和重要性(特征值)。这里直接给出计算结果(实际计算涉及求解二次方程,略去细节):
- 特征值:
λ1≈189.345
λ2≈18.15
- 特征向量:
v1≈[-0.860, -0.50896](对应 λ1)
v2≈[-0.860,0.50896](对应 λ2)
步骤4:排序、选择主成分
按特征值从大到小排序,λ1≈189.345最大,说明v1≈[-0.860, 0.50896]是第一个主成分,捕捉了数据中最大的变化,也就是数据分布中最显著的变化方向。第二个主成分与第一个主成分正交(相互垂直),且在正交约束下方差次大的方向。后续主成分:依此类推,每个主成分都与前面的主成分正交,并按特征值大小递减排列。
步骤5:投影数据
将中心化后的数据投影到第一个主成分1上,得到降维后的结果。
投影公式:Z=数学中心化值×0.894+物理中心化值×0.447
计算每个学生:
A:3×(-0.860)+5×(-0.50896)≈-5.127
B:13×(-0.860)+0×(-0.50896)≈-11.190
C:-7×(-0.860)+(-5)×(-0.50896)≈8.570
D:-17×(-0.860)+(-10)×(-0.50896)≈19.72
E:8×(-0.860)+10×(-0.50896)≈-11.9759
降维后数据:
| 学生 | 主成分值 |
| A | -5.127 |
| B | -11.190 |
| C | 8.570 |
| D | 19.72 |
| E | -11.9759 |
PCA后可以看到第一主成分红色箭头表明了数据的主要变化趋势,绿色箭头表示第二主成分方向。
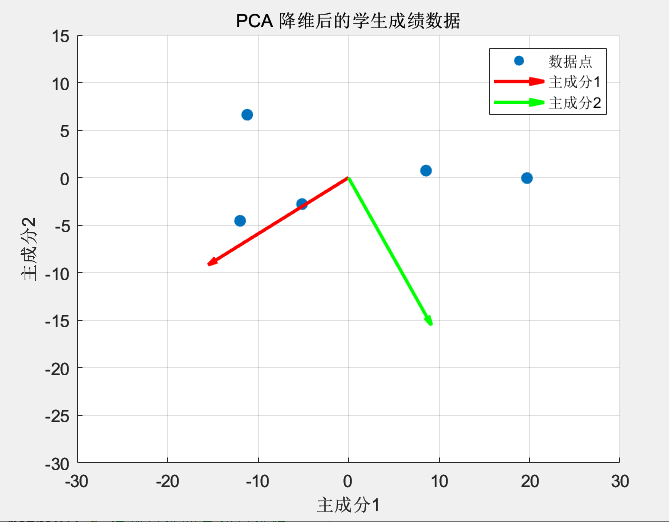
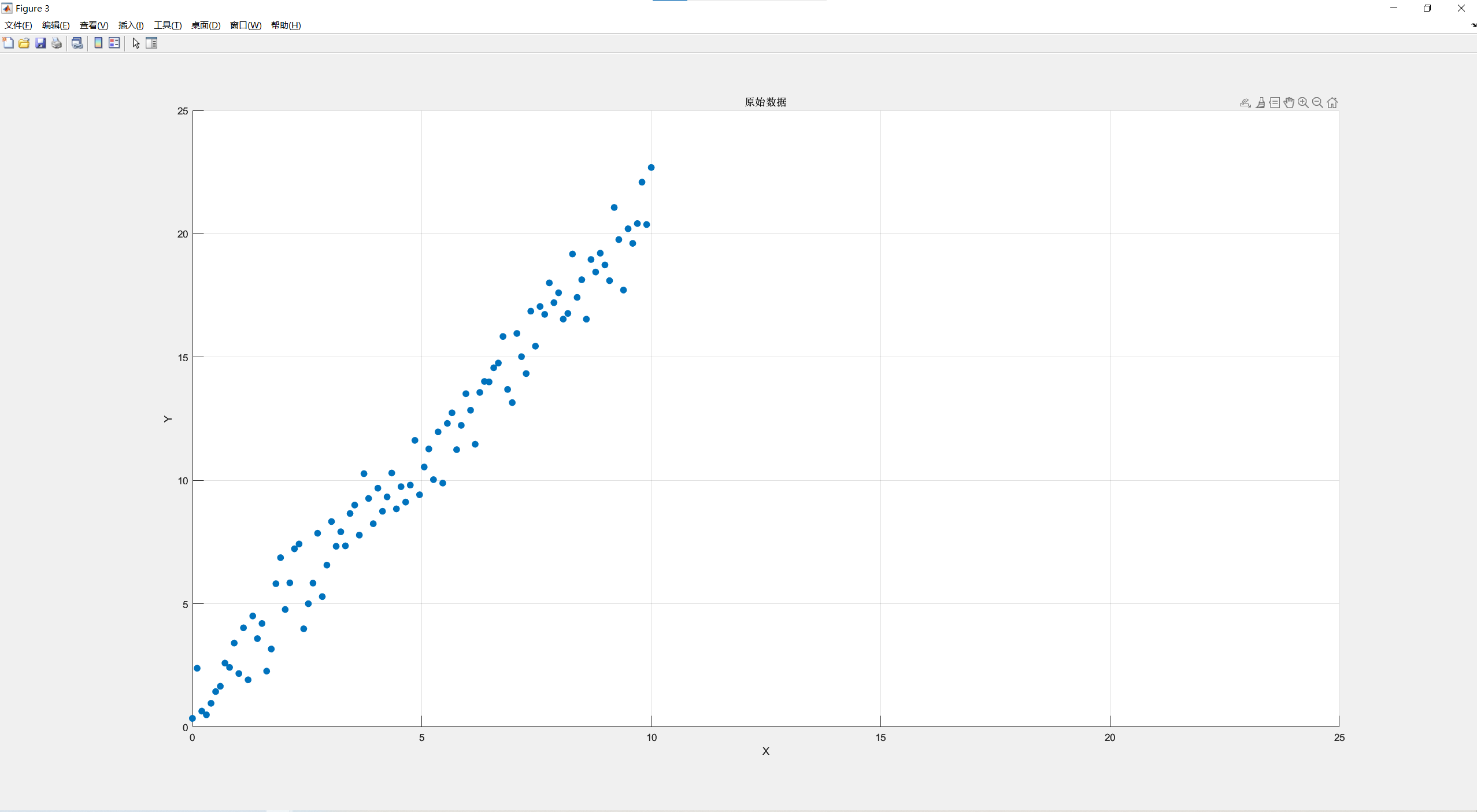
举的例子数据有点少,可能不太明显看出来,然后使用生成了100个大致符合y=2x+1分布的点,可以明显看出来红色箭头表明了其变化方向,如下(程序附后):
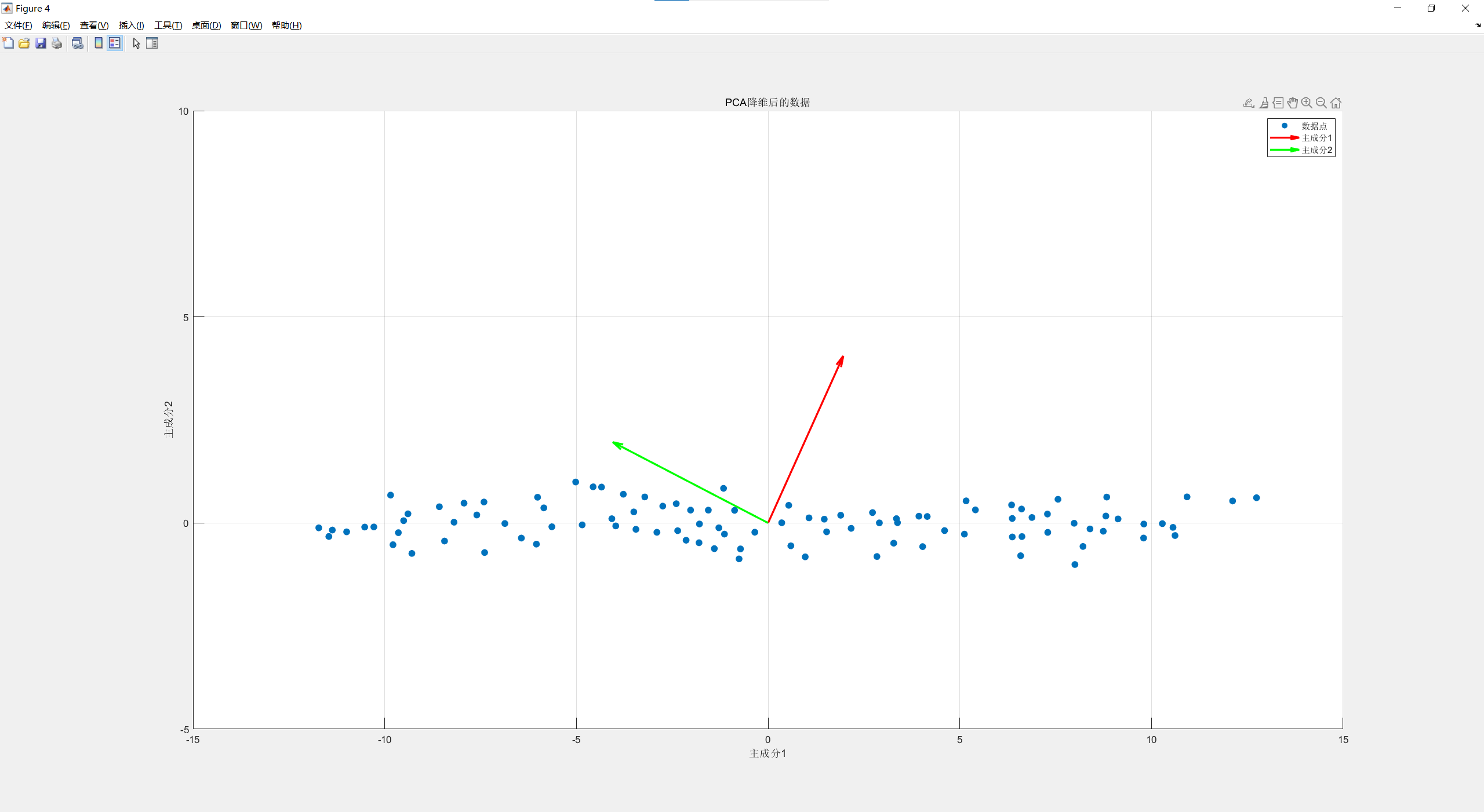
3. 几个问题
3.1 为什么要计算协方差矩阵?
协方差矩阵是 PCA 的基础,它用于描述数据集中变量之间的关系。具体来说:
- 定义:协方差矩阵是一个对称矩阵,对角线上的元素表示每个变量的方差,非对角线上的元素表示变量之间的协方差(即变量之间的线性相关性)。
- 作用:PCA 的目标是找到一组新的坐标轴(称为主成分),使得数据在这些轴上的投影方差最大化,同时这些轴相互正交(不相关)。协方差矩阵正好量化了数据中的变异性和变量间的相关性,为找到这样的轴提供了基础。
- 意义:通过协方差矩阵,我们可以了解哪些变量变化较大,哪些变量之间存在较强的关联,从而为后续的主成分提取奠定基础。
简单来说,计算协方差矩阵是为了捕捉数据的变异性和结构信息。
3.2 为什么要进行特征值分解?
特征值分解是 PCA 的关键步骤,它将协方差矩阵分解为特征值和特征向量,用于确定主成分的方向和重要性。原因如下:
- 特征向量:特征向量表示数据变异性最大的方向,这些方向是新的坐标轴(主成分),且彼此正交。这种正交性确保了主成分之间没有相关性。
- 特征值:特征值表示每个特征向量方向上的方差大小。特征值越大,说明该方向捕捉的变异性越多。
- 目的:通过特征值分解,我们可以将原始数据投影到这些特征向量上,从而实现降维,同时尽可能保留数据的信息。
换句话说,特征值分解帮助我们找到数据中最重要的变异方向,并用这些方向重新表示数据。
3.3 为什么要对特征值进行排序?
对特征值排序是 PCA 的重要环节,其目的是确保主成分按重要性排列。原因如下:
- 重要性排序:特征值的大小反映了每个主成分捕捉的方差大小。较大的特征值对应于更重要的主成分,因为它们解释了数据中更多的变异性。
- 降维应用:通过将特征值从大到小排序,我们可以:
- 确保第一个主成分捕捉最大方差,第二个主成分捕捉次大方差,以此类推。
- 在降维时,只保留前几个主成分(即特征值最大的那些),从而减少数据维度,同时保留主要信息。
- 可视化:排序后,选择前两个或三个主成分,可以将高维数据投影到二维或三维空间,便于观察和分析。
因此,排序特征值是为了按重要性排列主成分,确保降维时优先保留数据中最有价值的部分。
3.4 PCA 能干啥?
①数据可视化
- 场景:你有 50 个特征的癌症基因数据,想看看样本分布。
- PCA 降到 2 维,画散点图,能看出正常和癌症样本的区别。
②去噪声
- 场景:一张模糊的人脸照片。
- PCA 保留主要成分(人脸轮廓),丢掉小方差的噪声,照片变清晰。
③特征压缩
- 场景:手写数字识别,28x28 像素 = 784 维。
- PCA 降到 50 维,模型训练更快,效果差不多。
④数据压缩
- 场景:视频每一帧 1920x1080 像素。
- PCA 压缩每帧,节省存储和传输空间。
等等...甚至还可以使用PCA 提取客户“购物倾向”(买了啥,多少次)主成分,帮超市分析顾客类型。
4. MATLAB程序
% 生成一个二维数据集
rng(1); % 设置随机种子以确保结果可重复
n = 100; % 样本数量
x = linspace(0, 10, n); % 生成x轴数据
y = 2 * x + 1 + randn(1, n); % y与x有线性关系,并加入噪声
data = [x; y]'; % 组合成n x 2的矩阵
% 绘制原始数据
figure;
scatter(data(:,1), data(:,2), 50, 'filled');
title('原始数据');
xlabel('X');
ylabel('Y');
xlim([0 25]); % 设置横坐标范围为 [0,25]
ylim([0 25]); % 设置纵坐标范围为 [0, 25
grid on;
% PCA步骤
% 1. 中心化数据
mean_data = mean(data); % 计算均值
centered_data = data - mean_data; % 数据减去均值
% 2. 计算协方差矩阵
cov_matrix = cov(centered_data);
% 3. 特征值分解
[eigen_vectors, eigen_values] = eig(cov_matrix);
% 4. 按特征值大小排序
[eigen_values, sort_idx] = sort(diag(eigen_values), 'descend');
eigen_vectors = eigen_vectors(:, sort_idx);
% 5. 选择主成分
principal_components = eigen_vectors; % 保留所有主成分(这里是2个)
% 6. 将数据投影到主成分上
projected_data = centered_data * principal_components;
% 绘制PCA结果
figure;
hold on;
scatter(projected_data(:,1), projected_data(:,2), 50, 'filled');
% 绘制主成分方向
scale = 5; % 缩放因子,用于可视化主成分向量
quiver(0, 0, principal_components(1,1)*scale, principal_components(2,1)*scale, 'r', 'LineWidth', 2);
quiver(0, 0, principal_components(1,2)*scale, principal_components(2,2)*scale, 'g', 'LineWidth', 2);
title('PCA降维后的数据');
xlabel('主成分1');
ylabel('主成分2');
legend('数据点', '主成分1', '主成分2');
xlim([-15 15]); % 设置横坐标范围为 [-15, 15]
ylim([-5 10]); % 设置纵坐标范围为 [-5, 10]
grid on;
hold off;
















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









