







 本文详细介绍了如何从官网下载yolov5源代码,使用PyCharm打开并配置,通过labelimg进行标注,转换xml到txt格式,创建mydata文件夹,划分训练集、验证集和测试集,以及调整coco128.yaml文件,最后执行train.py进行模型训练的过程。
本文详细介绍了如何从官网下载yolov5源代码,使用PyCharm打开并配置,通过labelimg进行标注,转换xml到txt格式,创建mydata文件夹,划分训练集、验证集和测试集,以及调整coco128.yaml文件,最后执行train.py进行模型训练的过程。
本文将介绍yolov5模型训练的整个过程。
二:yolov5训练
1.官网下载源代码:https://github.com/ultralytics/yolov5
2.使用pycharm打开解压后的yolov5文件夹
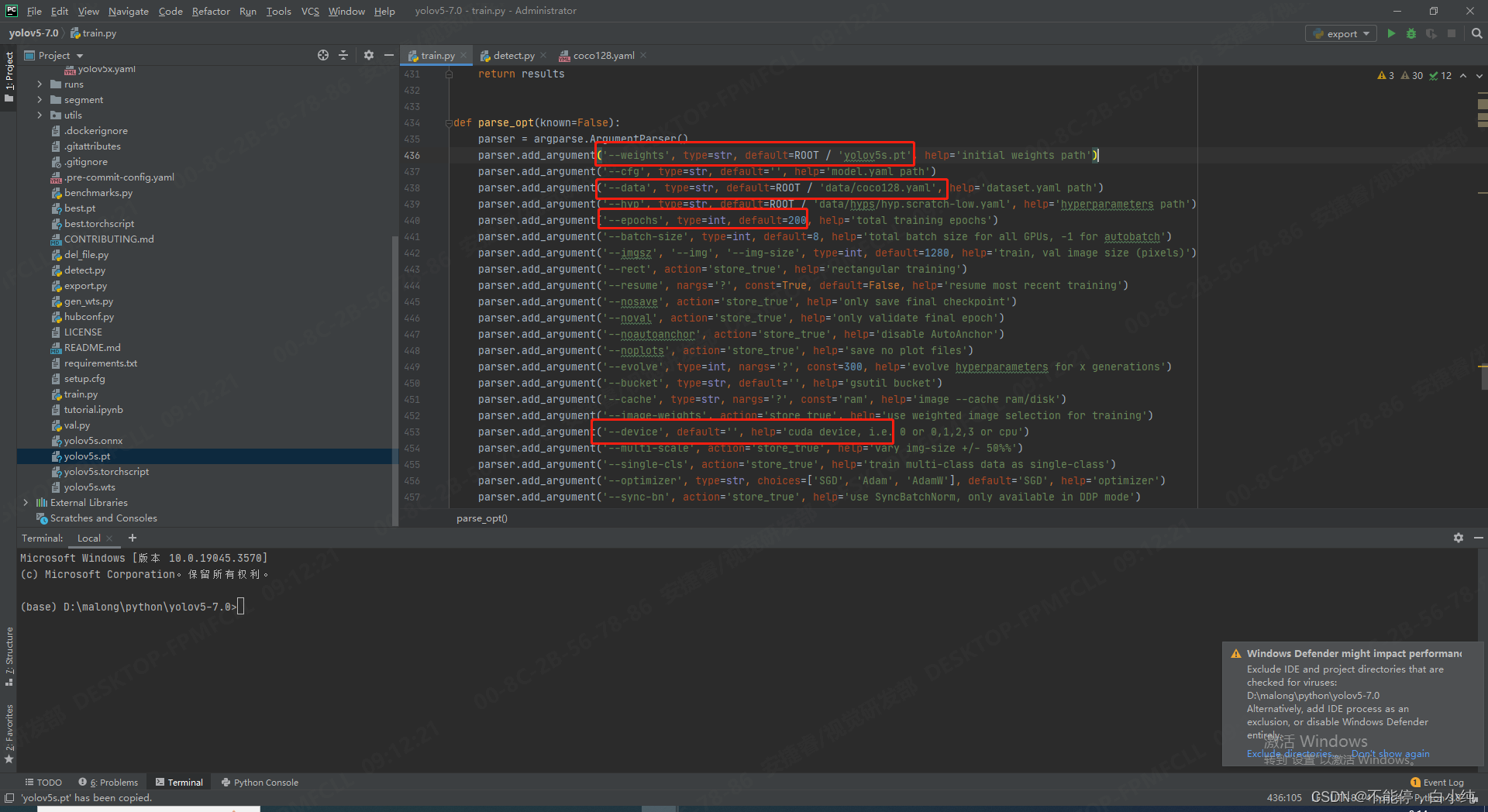
3.打开主文件夹目录下的train.py文件,对参数进行修改
4.使用labelimg进行标注,建议标签名不要用中文。
标注完得到xml文件后,使用脚本进行转化文件格式为txt。
修改xml_path的文件路径(换成自己的),再运行以下代码 。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["0", "1", "2", "3"] # 类别
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
# print(cls)
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
5.创建文件夹mydata,将对应xml、img/bmp、txt文件分别存入对应文件夹中。
6.在mydata文件夹路径下创建split.py文件,使用以下代码对txt以及img/bmp文件进行训练集、验证集、测试集划分,修改 img_path、label_path为自己的文件路径。
'''
Descripttion: split_img.py
version: 1.0
Author: UniDome
Date: 2022-04-20 16:28:45
LastEditors: UniDome
LastEditTime: 2022-04-20 16:39:56
'''
import os, shutil, random
from tqdm import tqdm
def split_img(img_path, label_path, split_list):
try : # 创建数据集文件夹
Data = '../datasets'
os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
os.makedirs(test_img_dir)
os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.txt'
return os.path.join(label_path, label)
def main():
img_path = r'D:\malong\python\yolov5-7.0\mydata\images'
label_path = r'D:\malong\python\yolov5-7.0\mydata\labels'
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
if __name__ == '__main__':
main()
7.前文第三点所说的coco128.yaml文件,修改为自己需要的数据集格式。
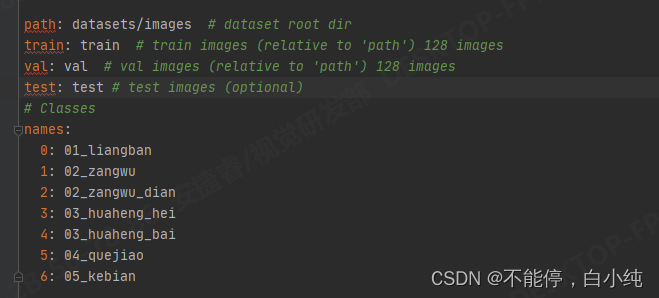
8.设置好之后运行train.py文件,出现以下界面则训练成功,等待完成训练即可。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









