







nltk是一个强大的自然语言处理库,提供了丰富的工具和资源,用于文本处理、分词、词性标注、句法分析和情感分析等任务。广泛应用于学术研究、教学和工业项目,帮助开发者高效处理和分析自然语言数据。
项目地址:https://github.com/nltk/nltk
目录
一、在华为云环境部署NLTK的优点
在使用 nltk 时,由于网络限制原因,直接调用 nltk.download() 方法会遇到错误,导致下载失败:
[nltk_data] Error loading averaged_perceptron_tagger: <urlopen error
[nltk_data] [Errno 11004] getaddrinfo failed> 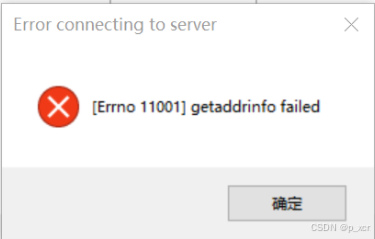
为了绕过这个问题,用户需要手动下载 nltk_data 的依赖包,解压并重命名,然后查找 nltk 的搜索路径,将依赖包复制到相应的路径中。这一过程较为繁琐,且不能随意更改下载路径,增加了使用的复杂性。
相比之下,在华为云上运行 nltk 可以避免这些问题。华为云提供了稳定的网络环境和优化的下载通道,可以直接成功下载 nltk 的依赖包,无需手动干预。这大大简化了开发和部署流程,提高了工作效率。
此外nltk 是一个主要用于教学和研究的自然语言处理库,它的设计初衷是为了提供简单易用的功能接口,而不是为了高性能计算。因此,它主要依赖于 CPU 来执行各种文本处理任务,不支持在GPU或NPU等专用硬件上运行。鲲鹏处理器具有高核心数和高效的并行计算能力,可以更好地利用多核优势来加速文本分词、词性标注、命名实体识别等自然语言处理任务,能够显著提高任务处理速度和效率。
二、创建华为云ECS弹性云服务器
(如果已有环境可跳过这一步骤)
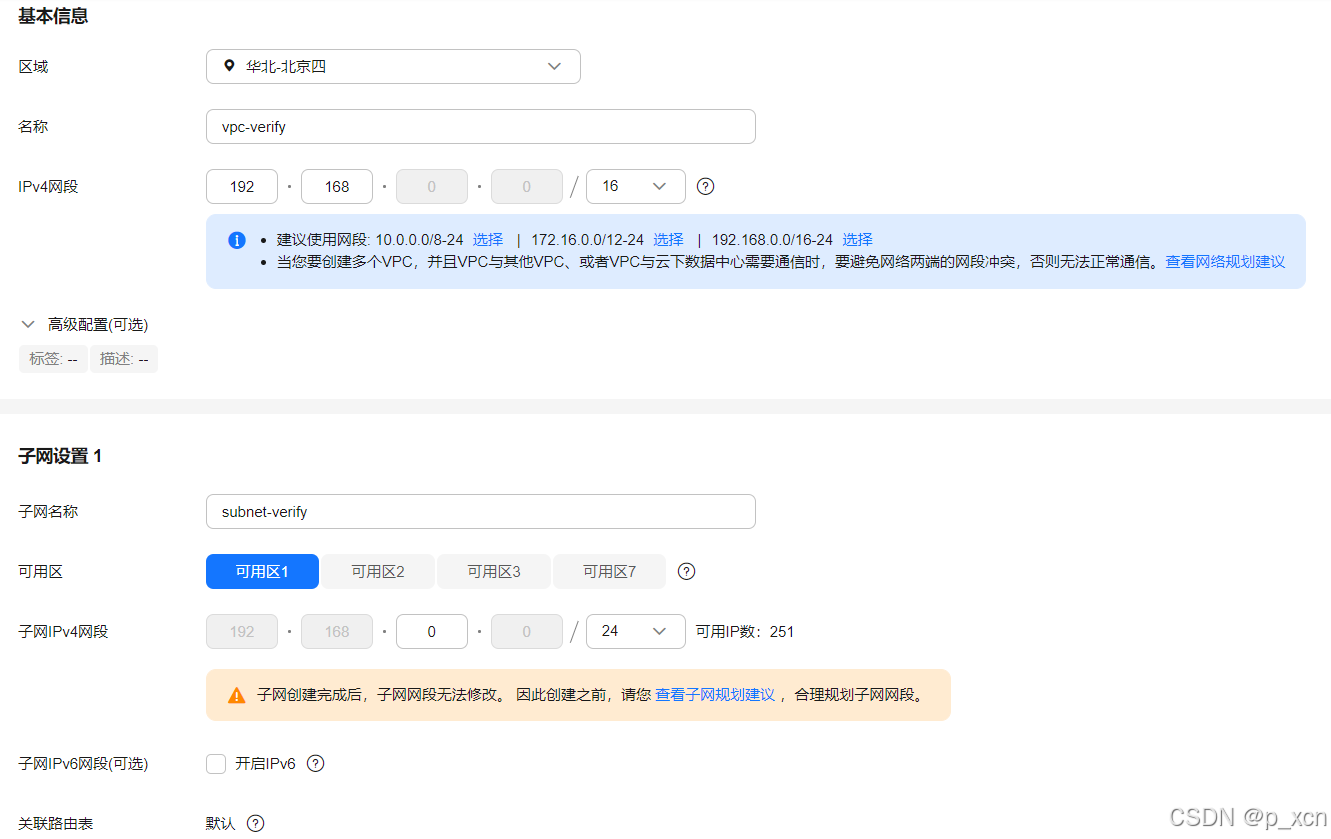
1、创建虚拟私有云VPC
打开华为云官网:共建智能世界云底座-华为云
在控制台点开左上角搜索到虚拟私有云VPC,点击创建虚拟私有云。
配置概要:
区域:华北-北京四
名称:自定义
IPv4网段:选择192.168.0.0/16
子网名称:自定义
可用区:可用区1
其他设为默认。
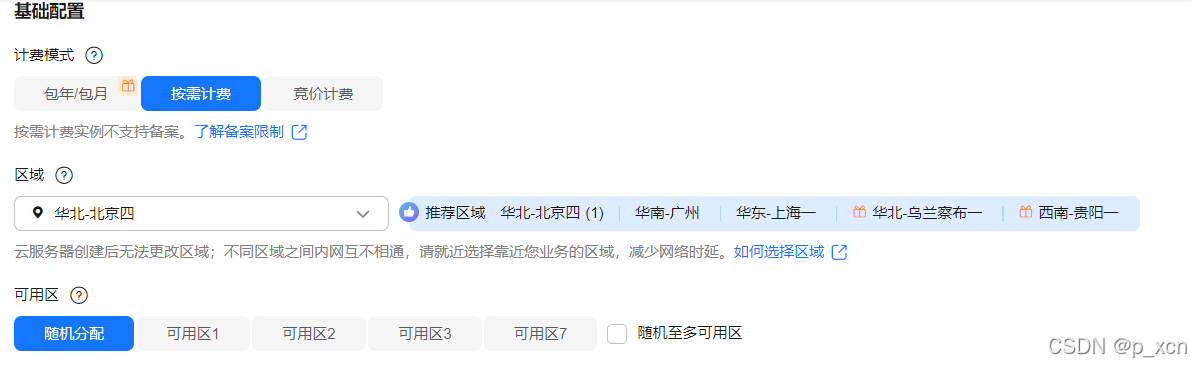
2、购买华为云弹性云服务器ECS
在控制台点开左上角搜索弹性云服务器ECS,点击购买弹性云服务器。
配置概要
基础配置
计费模式: 按需计费
区域/可用区: 华北-北京四 | 随机分配
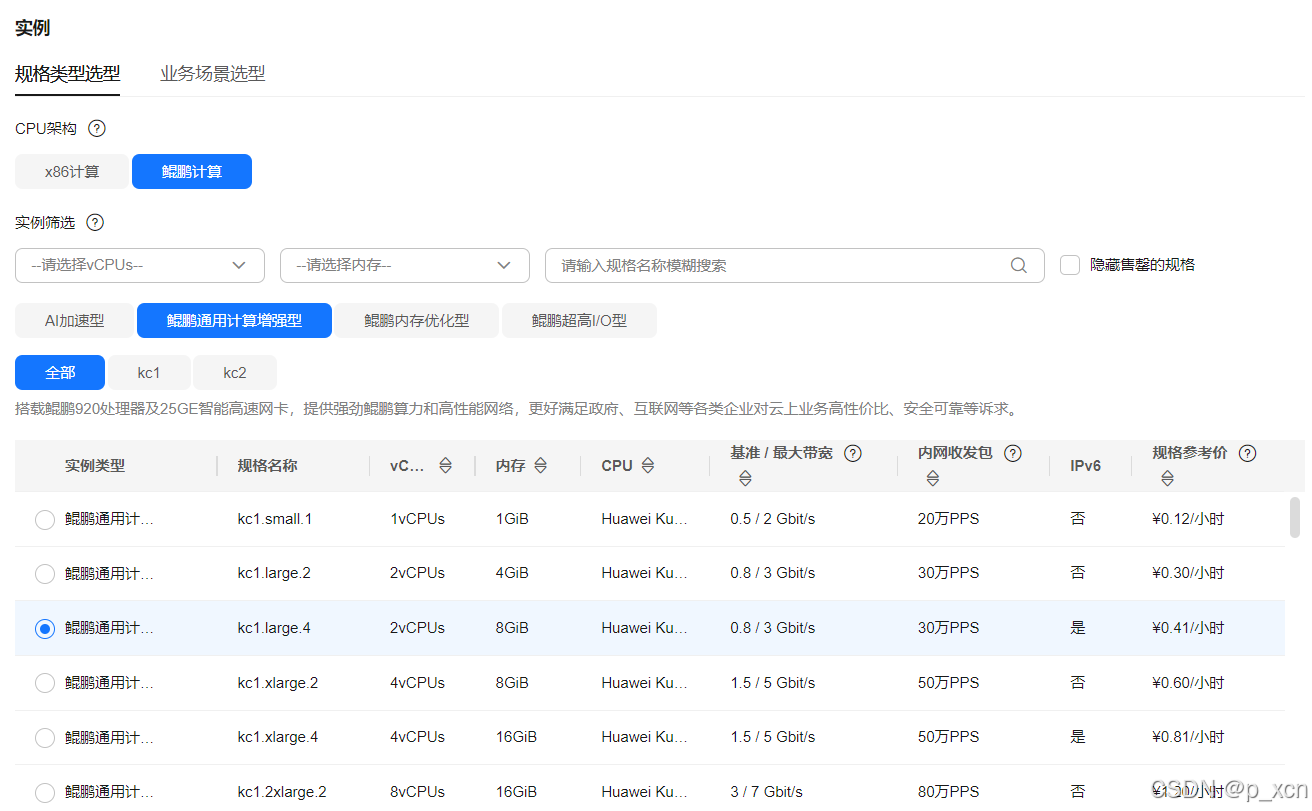
实例
规格: 鲲鹏通用计算增强型 | kc1.large.4 | 2vCPUs | 8GiB
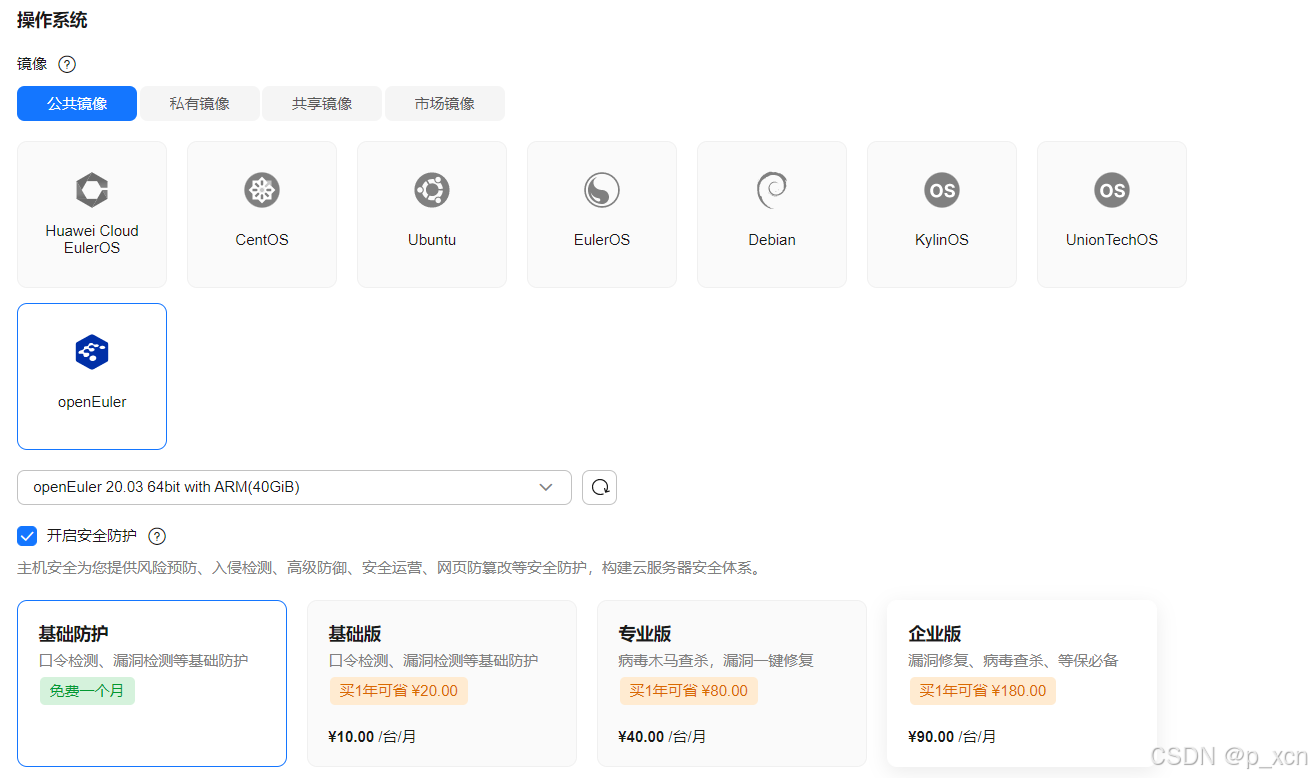
操作系统
镜像: openEuler 20.03 64bit with ARM
主机安全: 已开启基础防护免费一个月
存储与备份
系统盘: 通用型SSD, 40GiB
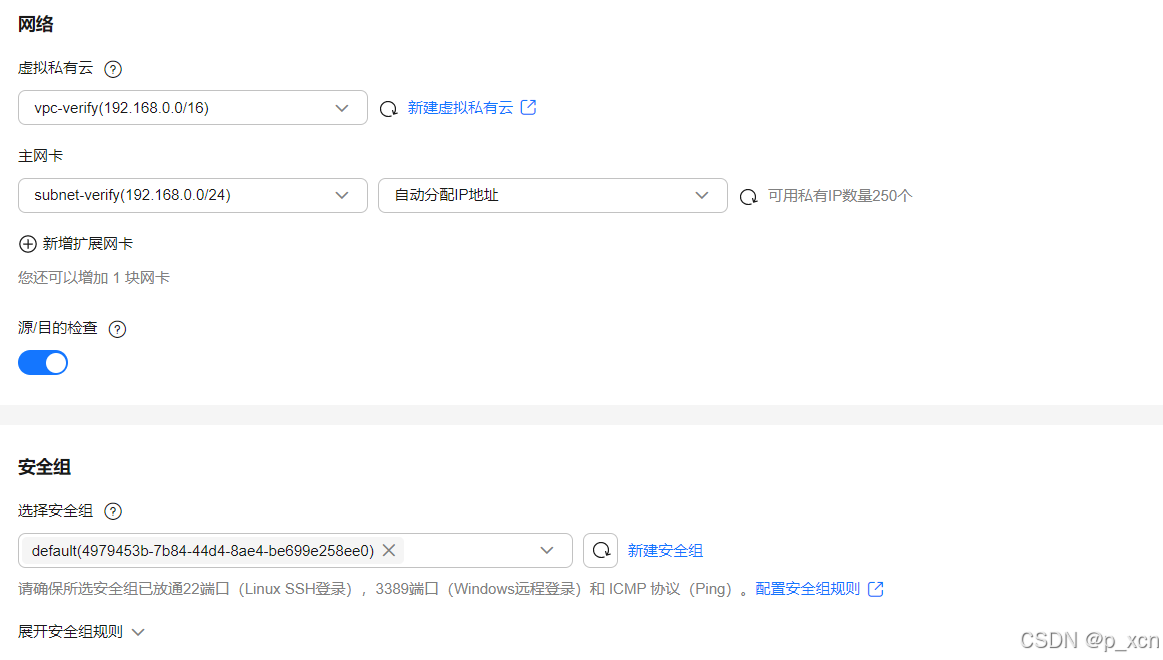
网络
虚拟私有云: 上一步创建的VPC(192.168.0.0/16)
主网卡: 上一步创建的VPC(192.168.0.0/24)
源/目的检查: 开启
安全组
default
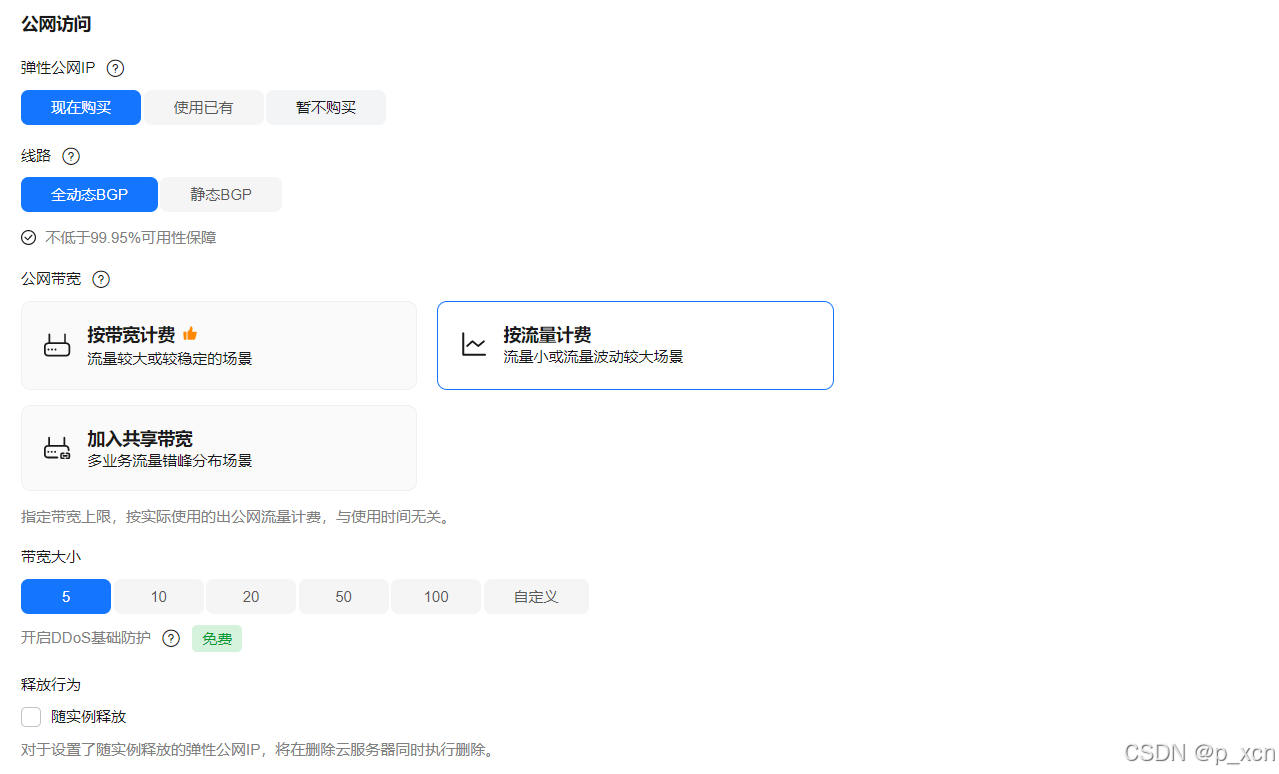
公网访问
弹性公网IP: 全动态BGP | 按流量计费 | 10 Mbit/s
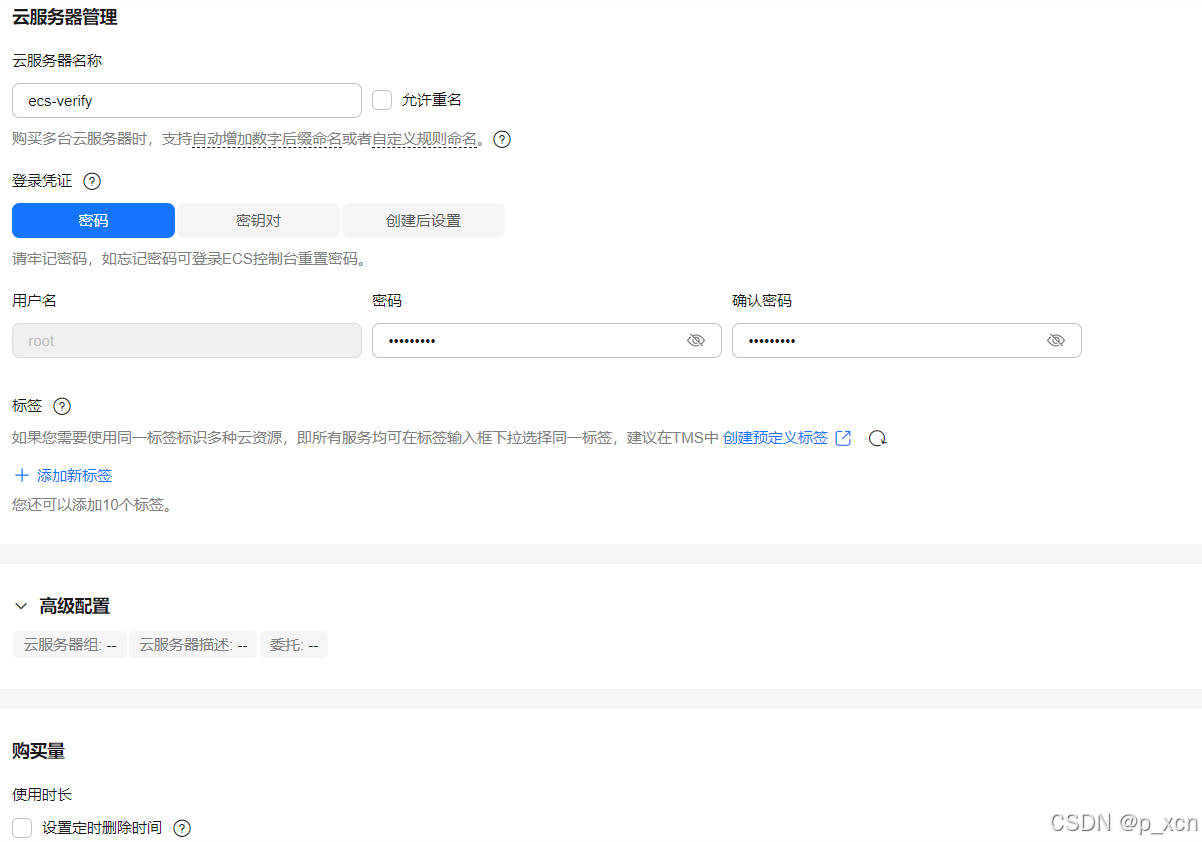
云服务器管理
云服务器名称: 自定义
登录凭证: 密码
标签: --
购买量
定时删除时间: --
购买数量: 1
ECS状态为运行中则为创建成功。点击右侧远程登录。

推荐使用CloudShell登录。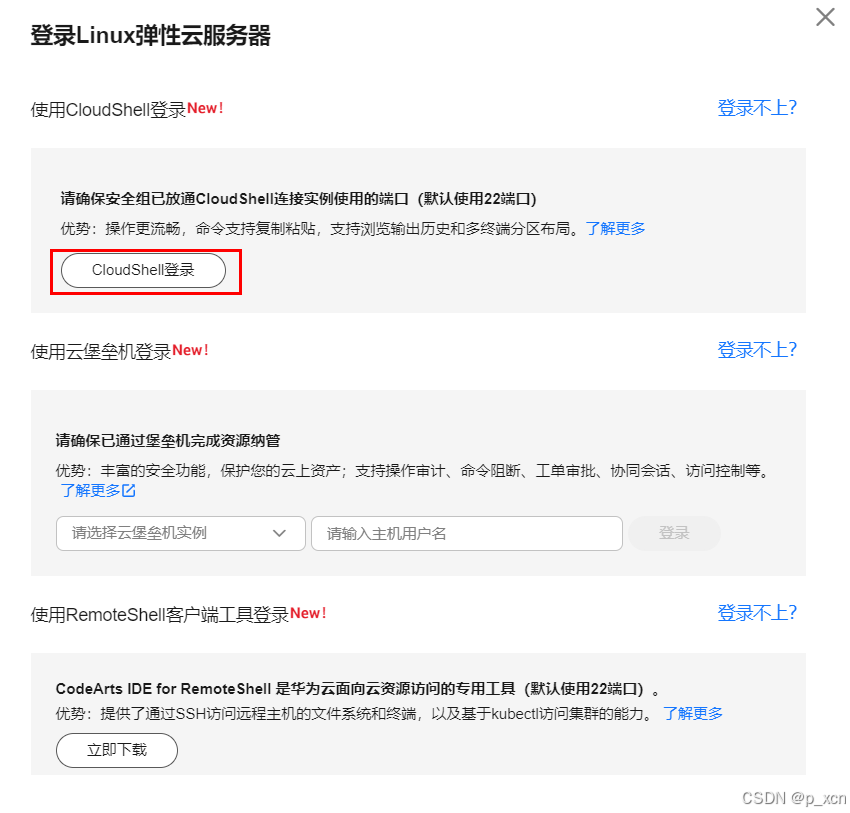 登录页面能看到公网和私网IP。输入创建ECS时设置的密码点击登录。
登录页面能看到公网和私网IP。输入创建ECS时设置的密码点击登录。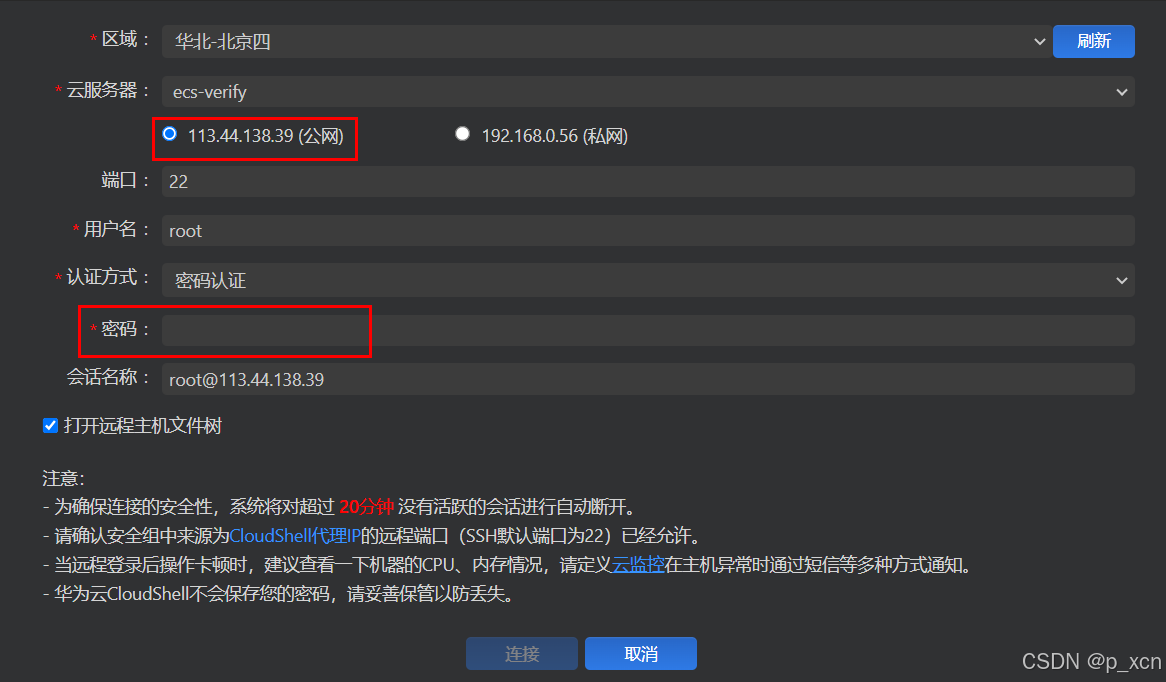 进入页面登录成功。
进入页面登录成功。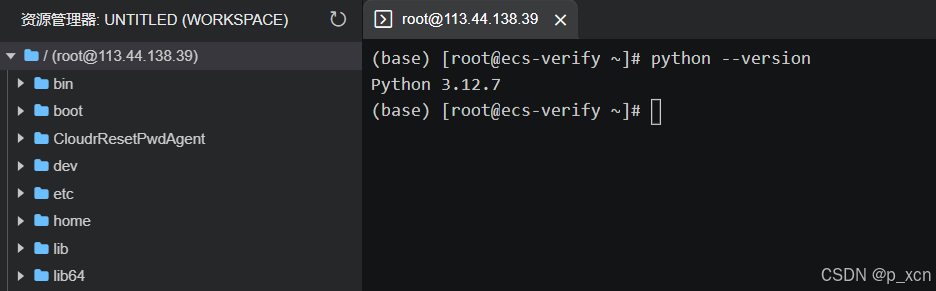
三、华为云ECS环境下运行代码
1.搭建python环境
conda创建python3.9环境。
conda create --name nltk python=3.9
conda activate nltk从 GitHub 拉取代码。
git clone https://github.com/nltk/nltk
cd nltk安装依赖。
pip install -r requirements-ci.txt2.使用nltk进行分词和词性标注
新建run-pos.py文件,下载所需资源包,并进行分词和词性标注。
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk.downloader import Downloader
import os
# 设置 NLTK 数据路径
data_path = './nltk_data'
os.makedirs(data_path, exist_ok=True)
nltk.data.path.append(data_path)
# 下载所需的资源包
if not os.path.exists(os.path.join(data_path, 'tokenizers', 'punkt_tab')):
# 创建 Downloader 对象,并指定下载目录
downloader = Downloader(download_dir=data_path)
# 下载 punkt_tab 资源包
downloader.download('punkt_tab')
if not os.path.exists(os.path.join(data_path, 'taggers', 'averaged_perceptron_tagger_eng')):
# 创建 Downloader 对象,并指定下载目录
downloader = Downloader(download_dir=data_path)
# 下载 averaged_perceptron_tagger_eng 资源包
downloader.download('averaged_perceptron_tagger_eng')
print("start_pos")
# 示例文本
text = "I really like the new design of your website!"
# 分词
tokens = word_tokenize(text)
# 词性标注
pos_tags = pos_tag(tokens)
print("Tokenized and Tagged Text:", pos_tags)
3.使用gradio构建Web应用界面
查看弹性公网IP和设置开放端口流程参考:查看华为云ECS弹性公网IP和设置开放端口-CSDN博客
后续需使用弹性公网IP+开放端口访问Web应用界面, 这里为http://113.44.138.39:7862/。
安装gradio库。
pip install gradio新建gradio_show.py,
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk.downloader import Downloader
import os
import gradio as gr
# 设置 NLTK 数据路径
data_path = './nltk_data'
os.makedirs(data_path, exist_ok=True)
nltk.data.path.append(data_path)
# 下载所需的资源包
if not os.path.exists(os.path.join(data_path, 'tokenizers', 'punkt_tab')):
downloader = Downloader(download_dir=data_path)
downloader.download('punkt_tab')
if not os.path.exists(os.path.join(data_path, 'taggers', 'averaged_perceptron_tagger_eng')):
downloader = Downloader(download_dir=data_path)
downloader.download('averaged_perceptron_tagger_eng')
def process_text(input_text):
# 分词
tokens = word_tokenize(input_text)
# 词性标注
pos_tags = pos_tag(tokens)
# 格式化输出
tagged_text = " ".join([f"{word}/{tag}" for word, tag in pos_tags])
return tagged_text
# 创建 Gradio 接口
iface = gr.Interface(
fn=process_text,
inputs="text",
outputs="text",
examples=["This is an example sentence."],
title="NLTK 分词和词性标注",
description="输入一段英文文本,返回分词和词性标注的结果。"
)
# 启动 Gradio 应用
iface.launch(server_name="0.0.0.0", server_port=7862)nohup 运行gradio_show.py,并在浏览器转到http://113.44.138.39:7862/打开服务页面,可以输入英文得到分词和词性标注结果: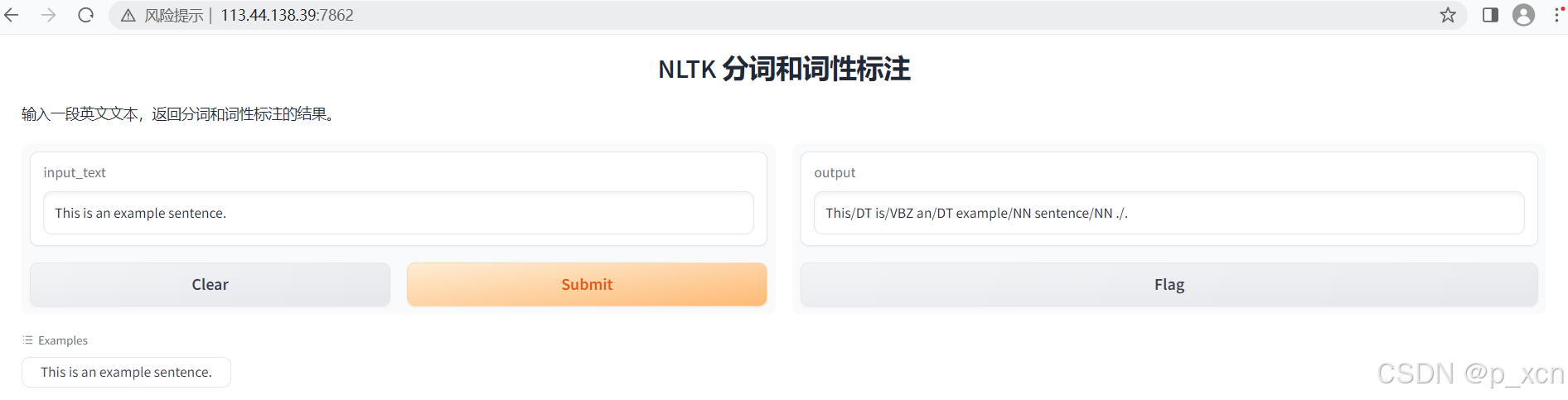

















 2789
2789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









