







一、 数据集介绍
pima_data.csv 数据集是经典的皮马印第安人糖尿病预测数据集(Pima Indians Diabetes Dataset),该数据集最初由美国国立糖尿病、消化系统疾病和肾脏疾病研究所(NIDDK)收集,用于研究皮马印第安人中的糖尿病患病情况。数据集包含以下 8 个特征(自变量) 和 1 个标签(因变量),共 9 列。
| 序号 | 特征名称 | 特征名称 | 说明 |
|---|---|---|---|
| 1 | preg | 怀孕次数 | 过去怀孕的次数 |
| 2 | plas | 血浆葡萄糖浓度 | 口服葡萄糖耐量试验中 2 小时的血浆葡萄糖浓度(mg/dL) |
| 3 | pres | 舒张压 | 血压(mm Hg) |
| 4 | skin | 三头肌皮肤褶皱厚度 | 三头肌皮肤褶皱厚度(mm),反映体脂率 |
| 5 | test | 血清胰岛素 | 2 小时血清胰岛素水平(μU/mL),数值越高可能胰岛素抵抗越严重 |
| 6 | mass | 体重指数(BMI) | 体重(kg)/(身高(m))^2 |
| 7 | pedi | 糖尿病家族史系数 | 糖尿病家族史的遗传易感性指标(基于亲代糖尿病史计算的权重值) |
| 8 | age | 年龄 | 年龄(岁) |
| 9 | class | 糖尿病诊断结果 | 标签 |
二、四种不同特征选择方法对比
| 特征选择方法 | 原理 | 特点 | 适用场景 | 结果示例 |
|---|---|---|---|---|
| 递归特征消除(RFE) | 递归地训练模型并消除最不重要的特征。依赖于基础模型的系数或特征重要性评分。 | - 依赖于基础模型(如逻辑回归、支持向量机等) - 适合线性模型,对非线性关系的捕捉能力较弱 - 结果可能因基础模型的选择而有所不同 | - 线性模型 - 特征数量较多,需要减少特征数量 | - 选择的特征:plas, mass, age- 未选择的特征: preg, pres, skin, test, pedi |
| 主成分分析(PCA) | 通过线性变换将原始特征转换为一组新的不相关特征(主成分),并保留尽可能多的方差信息。 | - 适用于高维数据 - 不依赖于目标变量,基于数据的方差进行降维 - 结果是数据在主成分空间的投影 | - 高维数据降维 - 数据预处理 | - 主成分1:[0.276, 0.397, 0.387, 0.358, 0.993, 0.014, 0.005, -0.036]- 主成分2: [0.229, 0.244, 0.258, 0.271, 0.095, -0.047, -0.008, -0.140] |
| 卡方检验(Chi-Squared Test) | 评估特征与目标变量之间的独立性,通过计算卡方统计量来衡量特征的重要性。 | - 适用于分类问题,特别是当特征和目标变量都是分类变量时 - 对特征的分布和数据的稀疏性敏感 - 结果反映了特征与目标变量之间的统计相关性 | - 分类问题 - 特征和目标变量都是分类变量 | - 选择的特征:test, plas, mass, age- 卡方统计量值: [111.52, 1411.887, 127.669, 181.304] |
| 极端随机树(ExtraTreesClassifier) | 构建多个决策树来评估特征的重要性,基于决策树的不纯度减少量计算特征重要性。 | - 适用于非线性关系,能够捕捉复杂的特征交互 - 特征重要性是基于决策树的不纯度减少量计算的 - 结果反映了特征在模型中的平均重要性 | - 非线性关系 - 特征交互 | - 选择的特征:plas, mass, age, pedi- 特征重要性值: [0.109, 0.222, 0.149, 0.144, 0.119, 0.099, 0.080, 0.077] |
| SelectKBest with Chi-Squared | 使用卡方检验选择与目标变量相关性最强的前K个特征。 | - 适用于分类问题,特别是当特征和目标变量都是分类变量时 - 对特征的分布和数据的稀疏性敏感 - 结果反映了特征与目标变量之间的统计相关性 | - 分类问题 - 特征和目标变量都是分类变量 | - 选择的特征:test, plas, mass, age- 卡方统计量值: [111.52, 1411.887, 127.669, 181.304] |
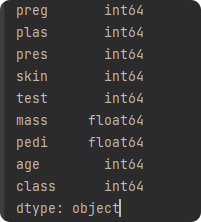
1.显示每列的数据类型
from pandas import read_csv
# 显示数据的行和列数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
print(data.dtypes)
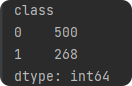
2.指定列进行分类分布统计
from pandas import read_csv
# 数据分类分布统计
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
print(data.groupby('class').size())
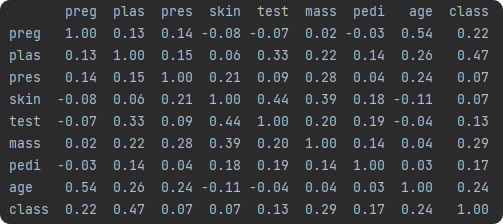
3.计算各列之间的皮尔逊相关系数矩阵和绘制相关系数矩阵的热力图(Heatmap)
from pandas import read_csv
from pandas import set_option
# 显示数据的相关性
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 设置显示宽度
set_option('display.width', 100)
# 设置数据的精确度
set_option('display.float_format', '{:.2f}'.format)
print(data.corr(method='pearson'))
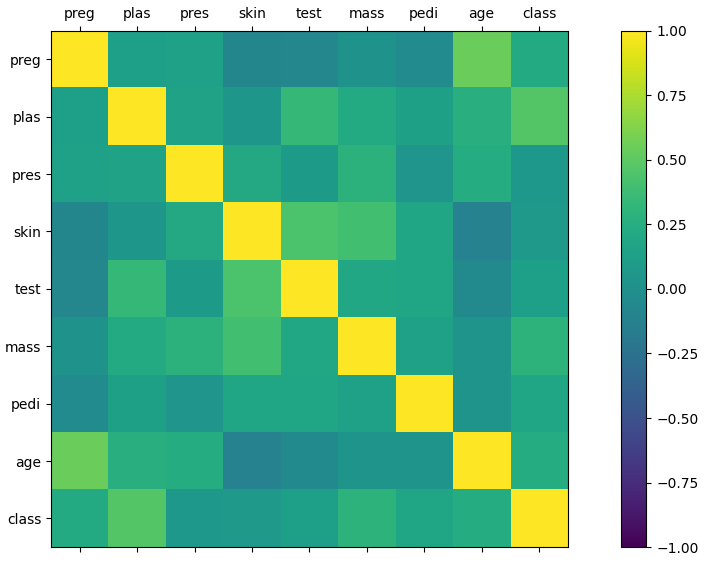
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = np.arange(0, 9, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
4.描述性统计信息和绘制各列特征的箱线图
描述性统计:每列的计数、均值、标准差、最小值、四分位数和最大值。
from pandas import read_csv
from pandas import set_option
# 描述性统计
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 设置显示宽度
set_option('display.width', 100)
# 设置数据的精确度
set_option('display.float_format', lambda x: '%.4f' % x)
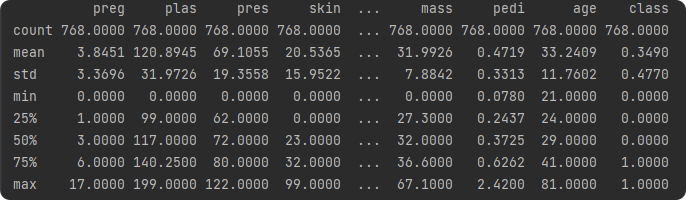
print(data.describe())
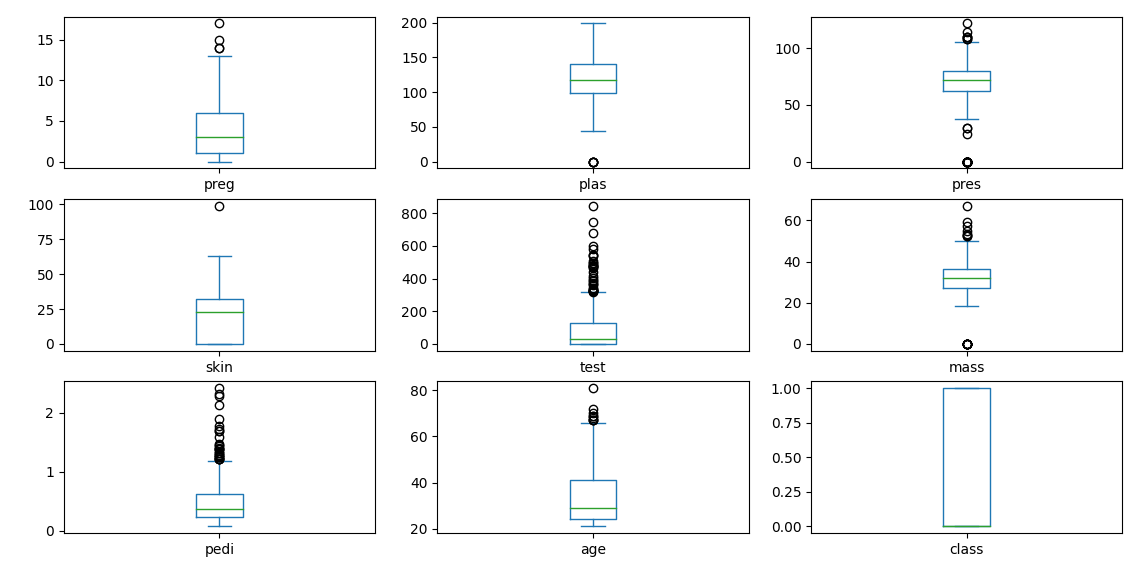
- 中位数:箱体中的横线。
- 四分位数:箱体的上下边界。
- 异常值:箱体外的点,通常用圆圈表示。
- 最大值和最小值:箱体外的线段。
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False)
plt.show()
5.显示数据最初10行
from pandas import read_csv
# 显示数据最初10行
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
peek = data.head(10)
print(peek)
6.计算数据各列的偏度(Skewness)和各特征的分布情况图
(1)偏度
- 衡量数据分布对称性的一个统计量。它描述了数据分布的不对称程度。
- 偏度为0:表示数据分布是对称的,即数据在均值两侧的分布是镜像对称的。
- 偏度大于0:表示数据分布右偏(正偏),即数据的长尾在右侧。这意味着大部分数据集中在左侧,少数极端值在右侧。
- 偏度小于0:表示数据分布左偏(负偏),即数据的长尾在左侧。这意味着大部分数据集中在右侧,少数极端值在左侧。
from pandas import read_csv
import matplotlib.pyplot as plt
# 计算数据的高斯偏离
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
print(data.skew())
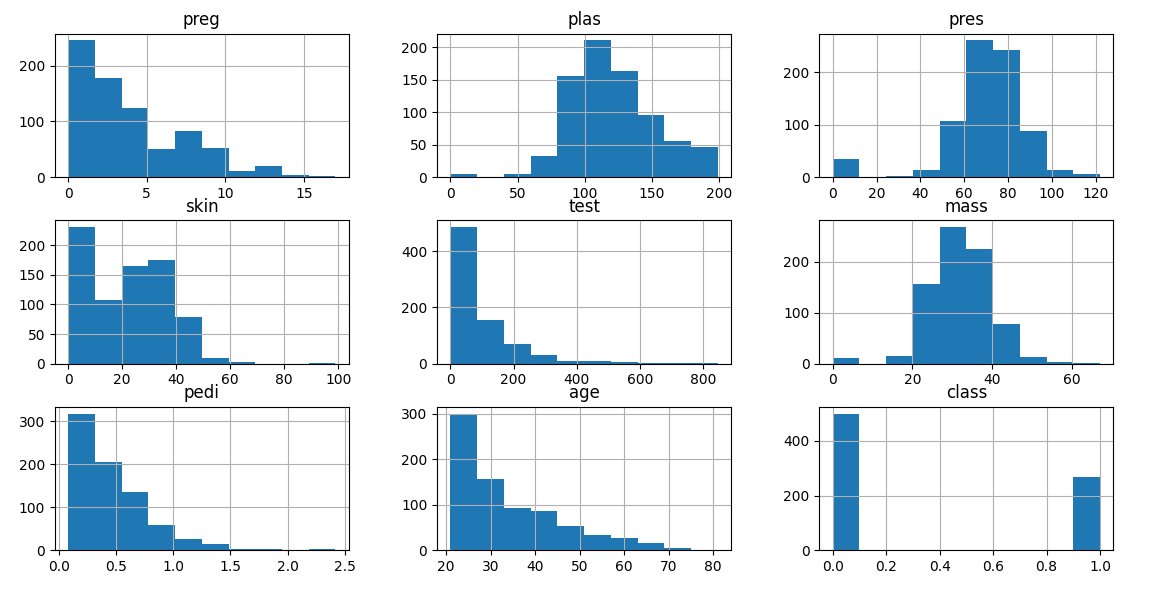
data.hist()
plt.suptitle('各特征分布直方图')
plt.show()
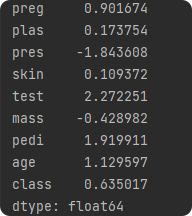
比如:
test:2.272251
数据右偏,且偏度较大,表示大部分数据集中在较低的值,少数极端值在右侧。
class:0.635017
数据右偏,表示大多数数据集中在较低的值,少数数据有较高的值
(2)展示各特征的分布情况
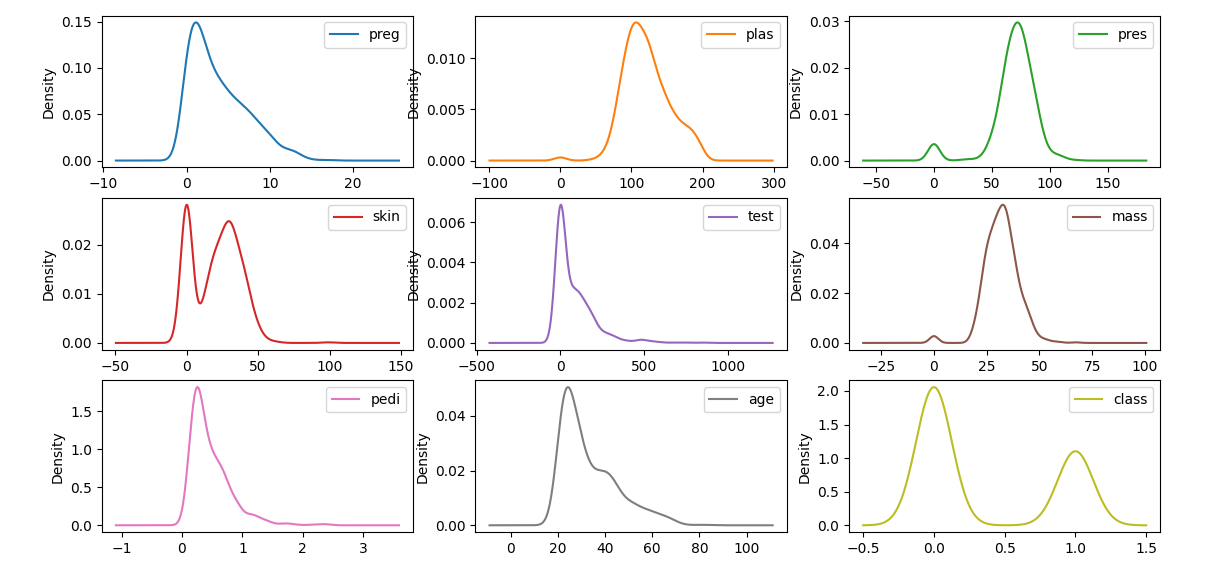
7.各列的概率密度函数(Probability Density Function, PDF)图。
-
概率密度函数图是一种用于显示数据分布的图形,可以直观地展示数据的概率分布情况。
-
数据分布分析:
- 通过概率密度函数图,可以快速发现数据是否接近正态分布、是否存在多峰等特性。如果曲线左右对称,表示数据分布是对称的。例如,正态分布(高斯分布)是对称的。
-
异常值检测:
- 概率密度函数图可以帮助你识别数据中的异常值或极端值,这些值可能需要进一步处理或分析。在概率密度函数图中,异常值通常表现为曲线尾部的突起或离群点。
-
模型假设检验:
- 许多统计模型假设数据是正态分布的。概率密度函数图可以帮助你评估数据是否符合这一假设。
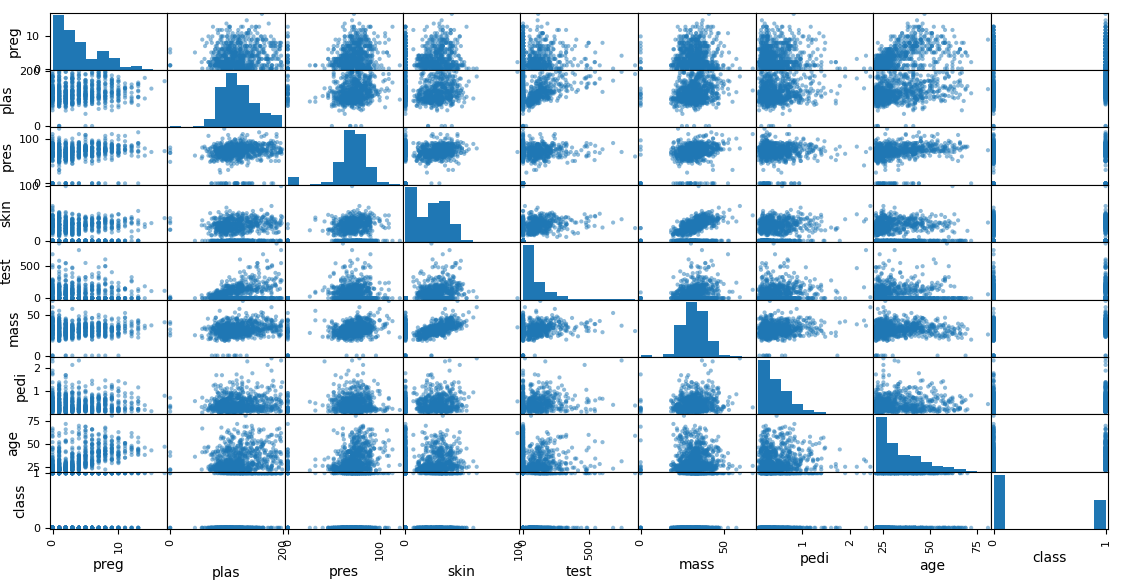
8.绘制各列之间的散点图矩阵(Scatter Plot Matrix)
- 散点图矩阵是一种用于展示多变量数据之间关系的图形,可以直观地观察各列数据之间的相关性。特别是线性关系和非线性关系,可以发现哪些变量之间存在强相关性或弱相关性。对角线上的直方图可以展示每列数据的分布情况,帮助你了解数据的集中趋势和离散程度。
from pandas import read_csv
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
scatter_matrix(data)
plt.show()
9.归一化(Normalization)范围(0到1)
- 提高模型性能:
- 许多机器学习算法(如梯度下降、支持向量机等)对特征的尺度敏感。归一化可以确保所有特征在相同的尺度上,从而提高模型的训练速度和准确性。
- 避免特征主导:
- 如果某些特征的数值范围远大于其他特征,这些特征可能会在模型训练中占据主导地位,影响模型的性能。归一化可以避免这种情况。
- 标准化数据:
- 归一化可以将数据标准化到一个统一的范围,便于不同数据集之间的比较和分析。
# 调整数据尺度(0..)
from pandas import read_csv
from numpy import set_printoptions
from sklearn.preprocessing import MinMaxScaler
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
scaler = MinMaxScaler(feature_range=(0, 1))
# 数据转换
rescaledX = scaler.fit_transform(X)
# 设定数据的打印格式
set_printoptions(precision=3)
print(rescaledX)
10.标准化(Standardization)或Z分数标准化(Z-score normalization)
# 正态化数据
from pandas import read_csv
from numpy import set_printoptions
from sklearn.preprocessing import StandardScaler
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
scaler = StandardScaler().fit(X)
# 数据转换
rescaledX = scaler.transform(X)
# 设定数据的打印格式
set_printoptions(precision=3)
print(rescaledX)
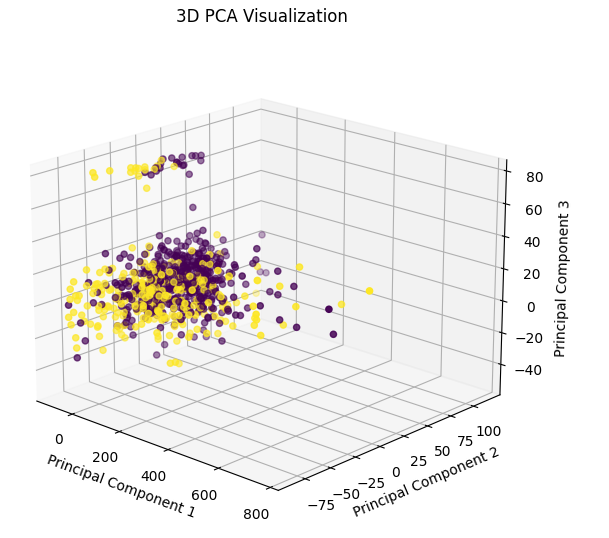
11.主成分分析(PCA)特征降维、特征选择和3D可视化
- PCA是一种常用的降维技术,通过将原始特征转换为一组新的不相关特征(主成分),并保留尽可能多的方差信息。每个主成分的方差解释率,表示每个主成分在总方差中所占的比例。
- 降维
PCA可以将高维数据降维到低维空间,减少数据的复杂性,提高模型的训练速度和性能。 - 特征选择
PCA可以帮助选择最重要的特征,去除冗余信息,提高模型的泛化能力。 - 数据可视化
降维后的数据可以更容易地进行可视化,帮助理解数据的结构和分布。 - 去除噪声
PCA可以去除数据中的噪声,保留主要的方差信息,提高数据的质量。
from pandas import read_csv
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
# 特征选定
pca = PCA(n_components=3)
fit = pca.fit(X)
X_pca = pca.transform(X)
# 打印解释方差和主成分
print("解释方差:%s" % fit.explained_variance_ratio_)
print("主成分:\n%s" % fit.components_)
# 3D可视化
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 绘制3D散点图
ax.scatter(X_pca[:, 0], X_pca[:, 1], X_pca[:, 2], c=Y, cmap='viridis')
# 设置标签
ax.set_xlabel('Principal Component 1')
ax.set_ylabel('Principal Component 2')
ax.set_zlabel('Principal Component 3')
# 显示图形
plt.title('3D PCA Visualization')
plt.show()
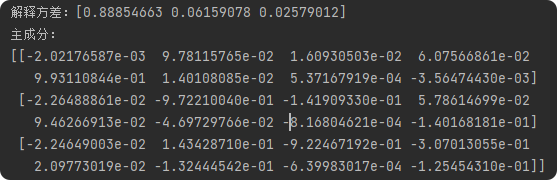
第一行:表示第一个主成分(PC1)的系数。例如,9.93110844e-01是特征test在PC1中的权重,表示test对PC1的贡献最大。
第二行:表示第二个主成分(PC2)的系数。例如,-9.72210040e-01是特征plas在PC2中的权重,表示plas对PC2的贡献最大,且方向为负。
第三行:表示第三个主成分(PC3)的系数。例如,-9.22467192e-01是特征pres在PC3中的权重,表示pres对PC3的贡献最大,且方向为负。
12.递归特征消除(Recursive Feature Elimination, RFE)特征选择
- 通过递归地训练模型并消除最不重要的特征来选择最重要的特征。RFE的核心思想是通过逐步减少特征集的大小来提高模型的性能和解释性。
具体步骤:- 1)初始化模型:选择一个基础模型,如LogisticRegression或SVC。指定要保留的特征数量n_features_to_select。
- 2)训练模型:使用所有特征训练基础模型。计算每个特征的重要性。
- 3)消除特征:消除最不重要的特征(通常是通过选择最小的特征重要性值)。更新特征集合。
- 4)重复训练:使用更新后的特征集合重新训练模型。重复上述步骤,直到保留的特征数量达到指定的数量。
- 5)输出结果:最终保留的特征集合。每个特征的排名(ranking_)。每个特征是否被选中(support_)。
from pandas import read_csv
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
# 特征选定
model = LogisticRegression( max_iter=1000)
rfe = RFE(estimator=model, n_features_to_select=3) # 使用关键字参数
fit = rfe.fit(X, Y)
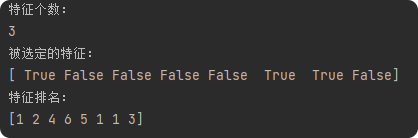
print("特征个数:")
print(fit.n_features_)
print("被选定的特征:")
print(fit.support_)
print("特征排名:")
print(fit.ranking_)
13.极端决策树分类器计算各特征的重要性
- 特征选择:通过计算特征的重要性,可以识别出对模型预测能力贡献最大的特征,从而选择最重要的特征用于建模。这有助于减少特征数量,提高模型的训练速度和性能。
- 模型解释:特征重要性可以帮助解释模型的决策过程,了解哪些特征对模型的预测结果影响最大。
- 数据理解:特征重要性可以帮助你更好地理解数据中的特征,发现数据中的模式和关系。
# 通过决策树计算特征的重要性
from pandas import read_csv
from sklearn.ensemble import ExtraTreesClassifier
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
# 特征选定
model = ExtraTreesClassifier()
fit = model.fit(X, Y)
print(fit.feature_importances_)
14.卡方检验(Chi-Squared Test)选择最重要的特征
- 卡方检验是一种统计方法,用于评估特征与目标变量之间的独立性。通过卡方检验,可以选择与目标变量相关性最强的特征。使用卡方检验作为评分函数,指定选择4个最佳特征。每个特征的卡方统计量值,值越大表示该特征与目标变量的相关性越强。
# 通过卡方检验选定数据特征
from pandas import read_csv
from numpy import set_printoptions
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
# 特征选定
test = SelectKBest(score_func=chi2, k=4)
fit = test.fit(X, Y)
set_printoptions(precision=3)
print(fit.scores_)
features = fit.transform(X)
print(features)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









