







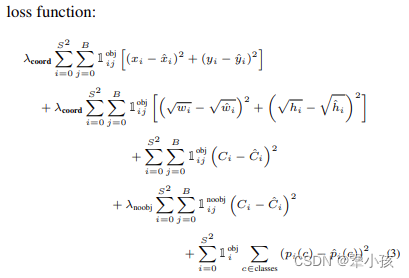
前言:
我是小白,刚能手搓分类模型,现在准备手搓检测模型。
于是我瞄上了最简单的一个yolov1
paper:https://arxiv.org/pdf/1506.02640.pdf
建议先了解yolov输出数据的构成:(7*7*30)
7为分割的格子数量,30为 2(anchor数量)*5(xywh+置信度) + 20(该论文中的类别数量) )
内容:
由图可得,一下内容图中公式对应
损失值=格子内有目标的xy的损失值
+格子内有目标的wh的损失值
+格子内有目标的置信度的损失值
+格子内没有目标的置信度的损失值(由于没有目标,只进行conf的计算)
+格子内有目标的类别的损失值
代码 :
class yoloLoss(nn.Module):
def __init__(self,S,B,l_coord,l_noobj):
super(yoloLoss,self).__init__()
self.S = S
self.B = B
self.l_coord = l_coord
self.l_noobj = l_noobj
self.grid_nums=7
def compute_iou(self, box1, box2):
'''Compute the intersection over union of two set of boxes, each box is [x1,y1,x2,y2].
Args:
box1: (tensor) bounding boxes, sized [N,4].
box2: (tensor) bounding boxes, sized [M,4].
Return:
(tensor) iou, sized [N,M].
'''
N = box1.size(0)
M = box2.size(0)
lt = torch.max(
box1[:,:2].unsqueeze(1).expand(N,M,2), # [N,2] -> [N,1,2] -> [N,M,2]
box2[:,:2].unsqueeze(0).expand(N,M,2), # [M,2] -> [1,M,2] -> [N,M,2]
)
rb = torch.min(
box1[:,2:].unsqueeze(1).expand(N,M,2), # [N,2] -> [N,1,2] -> [N,M,2]
box2[:,2:].unsqueeze(0).expand(N,M,2), # [M,2] -> [1,M,2] -> [N,M,2]
)
wh = rb - lt # [N,M,2]
wh[wh<0] = 0 # clip at 0
inter = wh[:,:,0] * wh[:,:,1] # [N,M]
area1 = (box1[:,2]-box1[:,0]) * (box1[:,3]-box1[:,1]) # [N,]
area2 = (box2[:,2]-box2[:,0]) * (box2[:,3]-box2[:,1]) # [M,]
area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M]
iou = inter / (area1 + area2 - inter)
return iou
def forward(self,pred_tensor,target_tensor):
'''
pred_tensor: (tensor) size(batchsize,S,S,Bx5+20=30) [x,y,w,h,c]
target_tensor: (tensor) size(batchsize,S,S,30)
'''
#batchsize
N = pred_tensor.size()[0]
#anchor mask
coo_mask = target_tensor[:,:,:,4] > 0
noo_mask = target_tensor[:,:,:,4] == 0
#(b,7,7,1) to (b,7,7,30) 1复制为30个
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor)
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)
#拓展为二维数据(b,7,7,30) (b*7*7,30)
coo_pred = pred_tensor[coo_mask].view(-1,30)
box_pred = coo_pred[:,:10].contiguous().view(-1,5) #box[x1,y1,w1,h1,c1]
class_pred = coo_pred[:,10:] #[x2,y2,w2,h2,c2]
coo_target = target_tensor[coo_mask].view(-1,30)
box_target = coo_target[:,:10].contiguous().view(-1,5)
class_target = coo_target[:,10:]
# compute not contain obj loss
#计算没有目标的损失值,只需要计算置信度损失
noo_pred = pred_tensor[noo_mask].view(-1,30)
noo_target = target_tensor[noo_mask].view(-1,30)
noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size())
noo_pred_mask.zero_()
noo_pred_mask[:,4]=1;noo_pred_mask[:,9]=1
noo_pred_c = noo_pred[noo_pred_mask]
noo_target_c = noo_target[noo_pred_mask]
nooobj_loss = F.mse_loss(noo_pred_c,noo_target_c,size_average=False)
#compute contain obj loss
#计算有目标的情况下的损失值
coo_response_mask = torch.cuda.ByteTensor(box_target.size())
coo_response_mask.zero_()
coo_not_response_mask = torch.cuda.ByteTensor(box_target.size())
coo_not_response_mask.zero_()
box_target_iou = torch.zeros(box_target.size()).cuda()
#iou计算得到最符合的roi
for i in range(0,box_target.size()[0],2):
box1 = box_pred[i:i+2]
box1_xyxy = Variable(torch.FloatTensor(box1.size()))
box1_xyxy[:,:2] = box1[:,:2]/self.grid_nums -0.5*box1[:,2:4]
box1_xyxy[:,2:4] = box1[:,:2]/self.grid_nums +0.5*box1[:,2:4]
box2 = box_target[i].view(-1,5)
box2_xyxy = Variable(torch.FloatTensor(box2.size()))
box2_xyxy[:,:2] = box2[:,:2]/self.grid_nums -0.5*box2[:,2:4]
box2_xyxy[:,2:4] = box2[:,:2]/self.grid_nums +0.5*box2[:,2:4]
iou = self.compute_iou(box1_xyxy[:,:4],box2_xyxy[:,:4]) #[2,1]
max_iou,max_index = iou.max(0)
max_index = max_index.data.cuda()
coo_response_mask[i+max_index]=1
coo_not_response_mask[i+1-max_index]=1
box_target_iou[i+max_index,torch.LongTensor([4]).cuda()] = (max_iou).data.cuda()
box_target_iou = Variable(box_target_iou).cuda()
box_pred_response = box_pred[coo_response_mask].view(-1,5)
box_target_response_iou = box_target_iou[coo_response_mask].view(-1,5)
box_target_response = box_target[coo_response_mask].view(-1,5)
contain_loss = F.mse_loss(box_pred_response[:,4],box_target_response_iou[:,4],size_average=False)
loc_loss = F.mse_loss(box_pred_response[:,:2],box_target_response[:,:2],size_average=False) + F.mse_loss(torch.sqrt(box_pred_response[:,2:4]),torch.sqrt(box_target_response[:,2:4]),size_average=False)
box_pred_not_response = box_pred[coo_not_response_mask].view(-1,5)
box_target_not_response = box_target[coo_not_response_mask].view(-1,5)
box_target_not_response[:,4]= 0
not_contain_loss = F.mse_loss(box_pred_not_response[:,4], box_target_not_response[:,4],size_average=False)
class_loss = F.mse_loss(class_pred,class_target,size_average=False)
return (self.l_coord*loc_loss + 2*contain_loss + not_contain_loss + self.l_noobj*nooobj_loss + class_loss)/N















 3441
3441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









