






LLama2原始权重转Hugging Face权重
由于使用的底座模型是llama,官方公布的是PyTorch版本,为了方便后续使用,需转换为HuggingFace格式 .pth->.bin
环境准备
本文实验conda环境为test_llm
pytorch1.13.1
cuda116
python3.8下载transformers到本地 并安装(要安装对应版本的,要不然会报错RuntimeError: shape '[32, 2, 2, 4096]' is invalid for input of size 16777216)
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout v4.28.1
pip install -e .
#要安装一些包
pip install sentencepiece==0.1.97 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install peft==0.3.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip uninstall tokenizers
pip install tokenizers==0.13.3 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install protobuf==3.20.2
下载llama
1.从GitHub克隆LLama项目到本地
git clone https://github.com/meta-llama/llama
2.下载模型权重
先登录到网址填写申请llama的信息,建议国家写美国

然后在你留下的邮箱中会收到一个URL,在接下来会用到
进入克隆下来的LLama项目目录,执行download.sh脚本来下载模型权重。我们全篇文章都以7B模型为例
cd llama
./download.sh
显示:
 输入邮箱
输入邮箱
![]()
输入你想下载的模型 7B
共下载了一个文件夹llama-2-7b和一个tokenizer.model文件
将下载下来的模型文件夹llama-2-7b重命名为7B
llama提供了7b、13b、30b、65b四种不同规模的模型,因此要使用第一代LLama的转换脚本convert_llama_weights_to_hf.py,我们需要将下载的模型名称改为这些名称,以便脚本能正确识别。例如,我使用了7b-chat模型,那么我就需要将7b-chat文件夹改名为7B。总的来说就是模型是7b-chat或7b则需要改名7B ,13b-chat或13b则需要改名13B
3.使用transformers包中的py文件执行权重转换,创建脚本convert_llama_weights_to_hf.sh如下
python transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir path_to_your_llama \
--model_size 7B \
--output_dir path_to_your_hf_model_output
path_to_your_llama为整个LLama项目的路径(也就是7B上一级目录) ,而不是刚刚下载到项目文件夹中的模型文件夹路径。- path_to_your_hf_model_output随便自定义一个输出目录就行
转换完成后,你可以在output_dir也就是huggingface格式模型输出文件夹中找到以下文件:
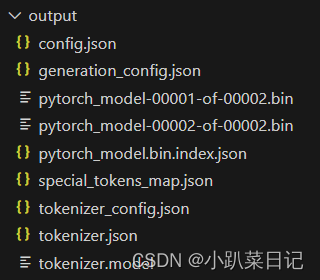
拉取Chinese-LLaMA-Alpaca项目
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
cd Chinese-LLaMA-Alpaca
mkdir model
然后将llama移动到model文件夹下面
合并模型
下载lora权重
由于原始llama模型对中文的支持不是很优秀,所以需合并一个chinese-llama-plus-lora-7b模型和chinese-alpaca-plus-lora-7b模型
(Chinese-LLaMA在原版LLaMA的基础上进行了扩充中文词表+增量预训练:扩充中文词表并使用了大规模中文语料数据进行增量预训练(因为采用了LoRA技巧,其本质还是高效参数微调),更好地理解新的语义和语境,进一步提升了中文基础语义理解能力。然后,Chinese-Alpaca模型进一步使用了中文指令数据进行指令精调(依旧采用了LoRA技巧),显著提升了模型对指令的理解和执行能力。官方链接:Chinese-LLaMA-Alpaca)

从huggface下载这两个模型 到model文件夹下
git lfs clone https://huggingface.co/hfl/chinese-llama-plus-lora-7b
git lfs clone https://huggingface.co/hfl/chinese-alpaca-plus-lora-7b在model文件夹下创建一个firstmergemodel文件夹
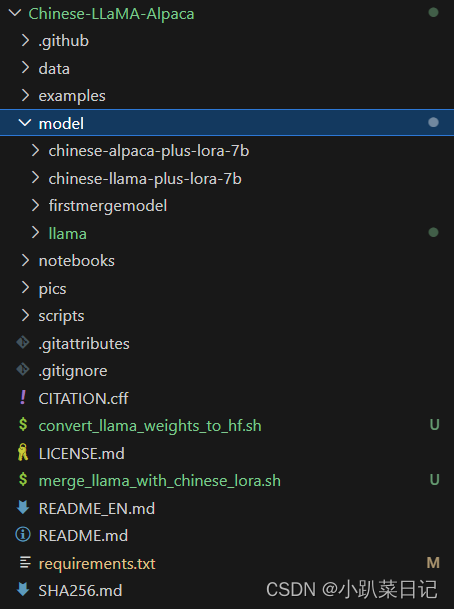
进入Chinese-LLaMA-Alpaca文件夹 cd Chinese-LLaMA-Alpaca
创建合并脚本merge_llama_with_chinese_lora.sh如下
python scripts/merge_llama_with_chinese_lora.py \
--base_model Chinese-LLaMA-Alpaca/model/llama/output/ \
--lora_model Chinese-LLaMA-Alpaca/model/chinese_llama_plus_lora_7b,Chinese-LLaMA-Alpaca/model//chinese_alpaca_plus_lora_7b \
--output_type huggingface \
--output_dir Chinese-LLaMA-Alpaca/model/firstmergemodels
- --base_model:存放HF格式的LLaMA模型权重和配置文件的目录
- --lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录,也可使用🤗Model Hub模型调用名称,提供两个lora_model的地址,用逗号分隔。⚠️ 两个LoRA模型的顺序很重要,不能颠倒。先写chinese-llama-plus-lora-7b然后写chinese-alpaca-plus-lora-7b
- --output_type: 指定输出格式,可为pth或huggingface。若不指定,默认为pth
- --output_dir:指定保存全量模型权重的目录,默认为./
进行二次预训练
二次预训练
准备数据集txt格式(最好是一问一答,llama预训练目前只支持txt格式)
mkdir Chinese-LLaMA-Alpaca/txt修改run_pt.sh文件
cd Chinese-LLaMA-Alpaca/scripts/training
vi run_pt.sh修改一些包的版本
pip install transformers==4.30.0
pip install pytest==7.4.3
pip install deepspeed==0.11.1 #否则训练到后期可能报错FileNotFoundError: [Errno 2] No such file or directory: '/home/bingxing2/ailab/scxlab0069/.local/lib/python3.9/site-packages/deepspeed/utils/zero_to_fp32.py'
pip install git+https://github.com/huggingface/peft.git@13e53fc # 否则训练后无法合并模型,会报错assert not torch.allclose(first_weight_old, first_weight)运行
sh run_pt.shrun_pt.sh文件如下:
#!/bin/bash
source activate test_llm
lr=2e-4
lora_rank=8
lora_alpha=32
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
### 对原版llama的hf文件与chinese_llama_plus_lora_7b及chinese_Alpaca_plus_lora_7b合并后结果
pretrained_model=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/model/firstmergemodel
### Chinese-Alpaca tokenizer所在的目录
chinese_tokenizer_path=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/model/chinese-alpaca-plus-lora-7b
### 预训练数据的目录,可包含多个以txt结尾的纯文本文件
dataset_dir=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/txt
### 指定一个存放数据缓存文件的目录
data_cache=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/cache/
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=50
### 模型输出的路径
output_dir=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/model/pt_output
### deepspeed配置文件
deepspeed_config_file=/home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/scripts/training/ds_zero2_no_offload.json
#--nnodes 1 --nproc_per_node 1
torchrun /home/bingxing2/ailab/group/ai4agr/wzf/LLM/models/Chinese-LLaMA-Alpaca/scripts/training/run_clm_pt_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--data_cache_dir ${data_cache} \
--validation_split_percentage 0.001 \
--per_device_train_batch_size ${per_device_train_batch_size} \
--per_device_eval_batch_size ${per_device_eval_batch_size} \
--do_train \
--seed $RANDOM \
--fp16 \
--num_train_epochs 1 \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--save_steps 200 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--block_size 512 \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--lora_rank ${lora_rank} \
--lora_alpha ${lora_alpha} \
--trainable ${lora_trainable} \
--modules_to_save ${modules_to_save} \
--lora_dropout ${lora_dropout} \
--torch_dtype float16 \
--gradient_checkpointing \
--ddp_find_unused_parameters False
文件整理
训练后的LoRA权重和配置存放于Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model,可用于后续的合并流程。

确认Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model/adapter_config.json中的lora_alpha, r, modules_to_save, target_modules等参数与实际训练用的参数一致。
合并模型
cd /root/autodl-fs/Chinese-LLaMA-Alpaca/model
mkdir ptmerge_model
cd Chinese-LLaMA-Alpaca
python scripts/merge_llama_with_chinese_lora.py \
--base_model Chinese-LLaMA-Alpaca/model/firstmergemodel/ \
--lora_model Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model/ \
--output_type huggingface \
--output_dir Chinese-LLaMA-Alpaca/model/ptmerge_model/推理模型
命令行方式推理合并后的模型
进入Chinese-LLaMA-Alpaca文件夹 cd Chinese-LLaMA-Alpaca
python scripts/inference/inference_hf.py --base_model model/ptmerge_model --with_prompt --interactive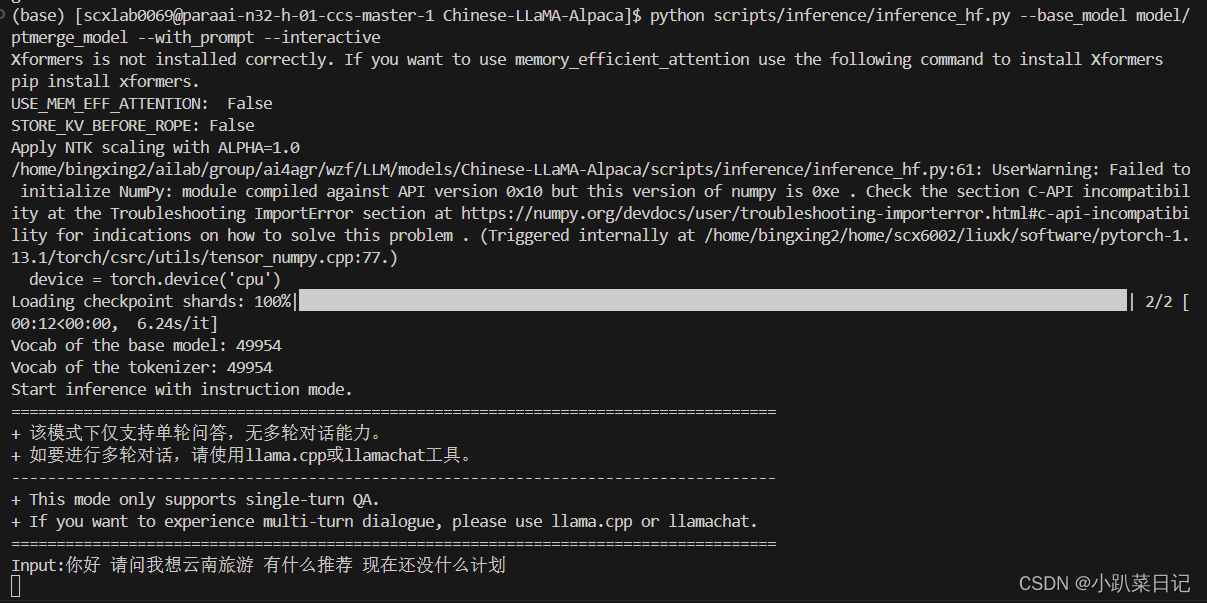
Web图形界面方式推理合并后的模型
进入Chinese-LLaMA-Alpaca文件夹 cd Chinese-LLaMA-Alpaca
python scripts/inference/gradio_demo.py --base_model model/ptmerge_model(下图是用Chinese-LLaMA-Alpaca/data/pt_sample_data.txt文件训练的,仅用作尝试)















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









