






文章相关信息:
论文地址:[2301.05709] Self-Supervised Image-to-Point Distillation via Semantically Tolerant Contrastive Loss
解决的问题:
1.自我结构相似性导致的语义结构混乱
这个简单的理解是:外观相似的汽车A和B,在对比学习中,可能汽车A的图像特征和汽车B的点云特征会被认为是负样本对,于是算法强制让这两个汽车在特征空间中远离,导致模型无法形成汽车类整体的语义聚合。
这里补充一下全局对比,即模型会把同一批次(batch)里的所有样本都拿来与图像特征对比,仅一个正样本,其余全负样本。
2.类别不平衡导致的学习偏差
解决的方法:
1.语义容忍对比学习机制:引入语义距离,使得对比学习能够区分“语义相近但不相同”的样本,保持局部语义一致性。(同类不同实例减少惩罚力度)
2.类平衡相似性建模策略:通过语义相似性聚合机制显示缓解类别不平衡问题,提高少数类特征的学习质量。
方法解析:
1.原理图如下:
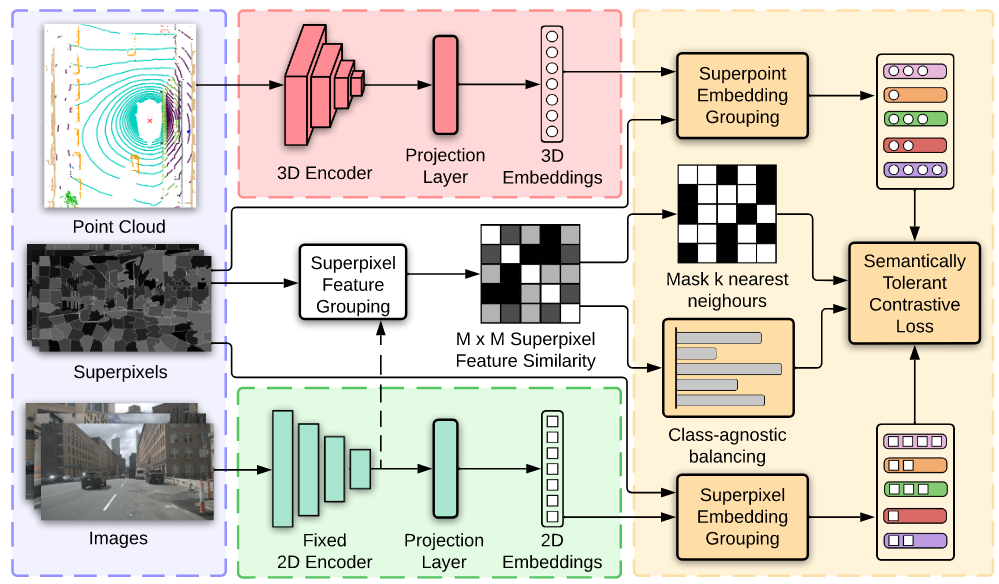
整体框架介绍:LiDAR 和相机数据先被编码为 3D/2D 嵌入,投影到同一嵌入空间;再通过 “超像素分组 + 相似度计算”,为对比损失提供语义感知的样本关系(哪些超像素应相似、哪些应区分);最终通过定制的对比损失,实现跨模态(图像→点云)的自监督特征蒸馏。
2.背景知识:
①SLIC无监督分割算法将图像的每个像素进行分割
②超点和超像素的对应
③点云和图像编码后投影到统一的空间以比较相似度
④超点和超像素进行分组与平均池化,其中Q是超点嵌入,K是超像素嵌入
⑤超像素驱动对比损失,即相似度计算以拉近正样本的距离,推远负样本的距离。
3.语义容忍对比损失:
①基于相似度的损失
解决语义相似超点与超像素嵌入被错误对比的问题,利用特征空间中超像素间的相似度 重新加权语义相似负样本的贡献。该损失公式为:

关键的理解:权重αij是超像素的相似度,相似度高的负样本梯度贡献小,反之大。
②基于最近邻的梯度修正
如果大部分超像素都非常相似则可能导致负样本贡献太少,学不到有效的表示。
因此这里对于负样本的相似度会进行排序,排除K个最相似的负样本,以保持学习的有效性。

4.解决类别不平衡:
用超像素间相似度 αij → 计算每个 anchor 的总相似度 vi → 归一化 → 1 - vi → 得到权重 wi→总体的归一化得到w
语义容忍 + 类别平衡的对比损失:
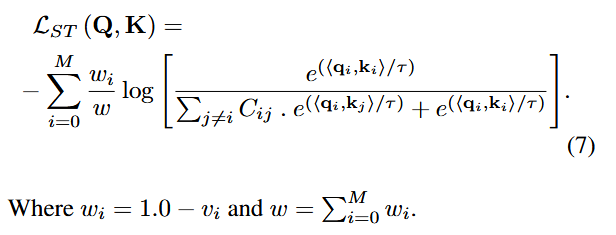
公式的理解:对每个anchor超点计算对比损失,i一直移动,让不同的anchor做为基准。wi是每个样本的权重,w的所有样本归一化的权重,以此让稀有类别的损失占比更大。
总结:这个任务应用于分割,效果一定程度上也依赖于预训练的教师模型和无监督的弱分割算法。

















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









