






一.实验目的
利用强化学习算法,实现机器人走迷宫,编写程序。要求在一个自定义m行n列,自定义设置障碍,自定义设置起点和终点的网格中寻找一条最优路径,并实现程序的可视化。
二.实验环境
MATLAB2016
三.实验思路
1.实现可视化
为了实现程序的可视化,可以利用MATLAB的作图功能,用其中的一些函数画网格,主要利用了meshgrid和plot。画完网格之后,把状态数写进网格中,比如1表示状态一,本实验定义左下角为状态1,右上角为最大的状态数。例如:
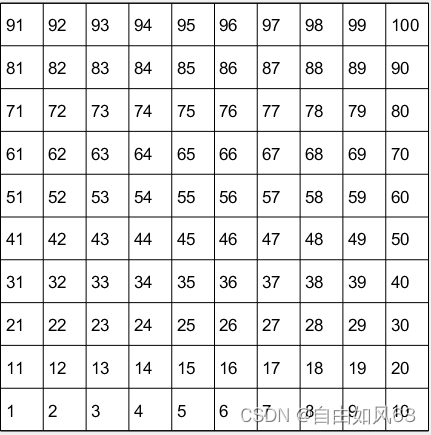
最后,给设置障碍的格子填充颜色为黑色,把最终求得的最优路径用蓝色展示出来,这样就实现了程序可视化。主要用到fill函数
2.强化学习算法
本次实验采用Q-learning算法。
应用MATLAB中特有的矩阵功能,将决策Reward,Q(s,a)以及状态转换表S存入矩阵中。动作决策一共有四个,分别是左移,上移,右移,下移。本次实验中,每一次动作决策完成后,会百分百到达下一个格子(若移动方向没有格子则停留在原位置)。一个m行n列的网格一共有total=m×n个格子,也就是有total个状态。我们把决策Reward设置一个为total行4列的矩阵,每一行代表一个状态,第一列代表左移的回报,第二列代表上移的回报,第三列代表右移的回报,第四列代表下移的回报。而对于回报,我们定义为,若移动到障碍里,回报为-1000,待在原位置回报为-1000,落入正常格子回报为-1。根据这个思路,Q和S都设置为total行4列的矩阵。状态转换表S中第一行第一列就表示状态一左移后的状态,Q表第一行第一列就表示状态一做左移这个动作的Q。
这样,在设置完障碍后就可以对这三个矩阵初始化,其中Q初始化全为0

最后根据Q-learning算法流程,利用e-greedy策略一次次迭代,实现Q-learning算法学习,
本次实验规定有1%的概率随机探索
四.实例验证
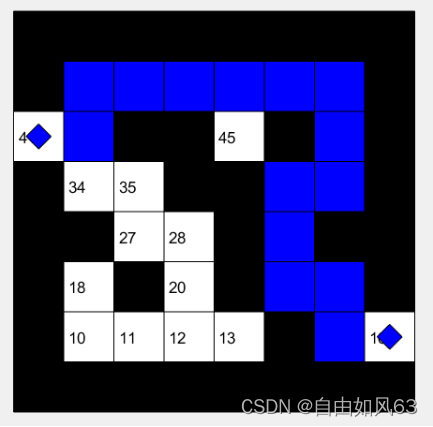
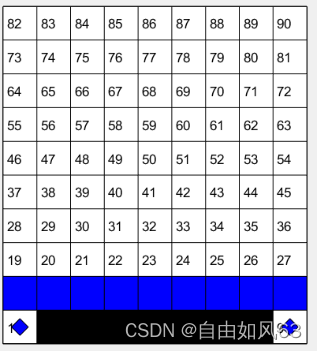
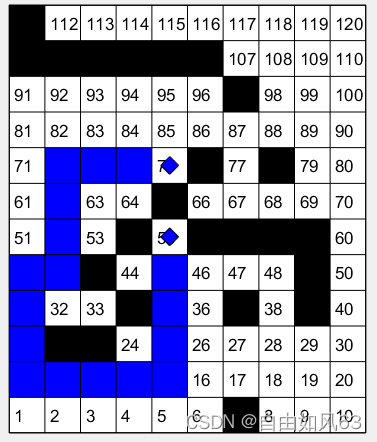
实验中黑色为障碍,蓝色为路径,未填满的小蓝方块为起点和终点
代码全部为原创,有不足的地方,欢迎指正
主函数程序如下:
close all;
clear
m=input('请输入您想创建的网格的行数:');
n=input('列数:');
total=m*n;
gezi=ones(total,1);
zuotu(m,n);
a=1;
while a~=0
a=input('请输入您想设置的障碍的标号(没有则输入0):');
if(a==0)break;
end
zhizhang(a,m,n);
gezi(a)=1000;
end
%********************************
for i=1:total
if mod(i,n)==1
R(i,1)=-1000;
else
j=i-1;
R(i,1)=-gezi(j);
end
if total-i<n
R(i,2)=-1000;
else
j=i+n;
R(i,2)=-gezi(j);
end
if mod(i,n)==0
R(i,3)=-1000;
else
j=i+1;
R(i,3)=-gezi(j);
end
if i<=n
R(i,4)=-1000;
else
j=i-n;
R(i,4)=-gezi(j);
end
end
%******************************
S=zeros(total,4);
for i=1:total
if mod(i,n)==1
S(i,1)=i;
else
S(i,1)=i-1;
end
if total-i<n
S(i,2)=i;
else
S(i,2)=i+n;
end
if mod(i,n)==0
S(i,3)=i;
else
S(i,3)=i+1;
end
if i<=n
S(i,4)=i;
else
S(i,4)=i-n;
end
end
%***********************
qidian=input('输入起始标号:');
zhongdian=input('输入终点标号:');
Q=zeros(total,4);
gamma = 0.9;
alpha = 0.9;
cnt = 0;
epoch = 10000;
done = false;
action = 0;
state = 0;
rt = 0;
road = [qidian];
while cnt<epoch
state = qidian;
done = false;
while ~done
%e-greedy策略,确保不会一直按照已知的路走,有1%概率探索未知的方法
if rand()<0.99
[rt,action] = max(Q(state,:));
verify = find(Q(state,:) == rt);
%当已知的路径有多条时随机选择一条
if length(verify) >1
action = verify(randi([1,length(verify)]));
end
else
%随机去探索
action = randi([1,4]);
end
nextstate = S(state,action);
Q(state,action) = Q(state,action) + alpha*(R(state,action)+gamma*max(Q(nextstate,:))-Q(state,action));
state = S(state,action);
road(end+1) = state;
jieshu=find(gezi==1000);
if any(state==jieshu(:))||state==zhongdian
done = true;
end
end
cnt = cnt + 1;
disp(road);
if cnt==9999
long=length(road);
qizhong(road(1),m,n);
qizhong(road(long),m,n);
for i=2:long-1
zhidian(road(i),m,n);
pause(0.3);
end
end
road = [qidian];
end














 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









