






引言
序列转录模型,一般需要依赖于复杂的循环或者卷积神经网络,架构一般为encoder(编码器)和decoder(解码器),这篇论文提出了一个具有简单架构的模型:Transformer(中文译为“变形金刚”),是第一个仅仅使用自注意力机制(self-attention)做序列转录的模型,而没有用到之前的循环或者卷积。作者使用该模型做了两个机器翻译的小实验,并行度更好且可以用更少的时间来训练。而且作者认为transformer还可以扩展到大型的输入输出模式上面,比如图片、语音和视频处理等等。(可见作者是看准了大方向的)
这篇博文,就让我们一起逐层剖析transformer的架构!
1.Encoder和Decoder
在序列转录模型中,比较好的一个架构就是encoder-decoder架构。
Encoder(编码器):将一个长为n的序列(x1,x2,x3...xn)转换为z=(z1,z2,z3...zn)这样的向量表示,比如,如果(x1,x2,x3...xn)是一个句子,xt(t>=1&&t<=n)代表一个词,则zt就代表该词的向量。
Decoder(解码器):拿到encoder的输出,生成一个长为m的序列(y1,y2,y3...ym),(这里值得注意的是encoder中的n和decoder中的m不一定相等,比如英文句子翻译成中文句子,两个句子很有可能不一样长。)对于解码器,它的输出方式就比较有意思了,它一次只生成一个词,且采用自回归(auto-regressive)的一种方式生成,即过去时刻的输出作为当前时刻的输入,比如decoder如果要生成yt(t>=1&&t<=m)的话,需要把之前y1到y(t-1)全部拿到。
2.Transformer的架构图
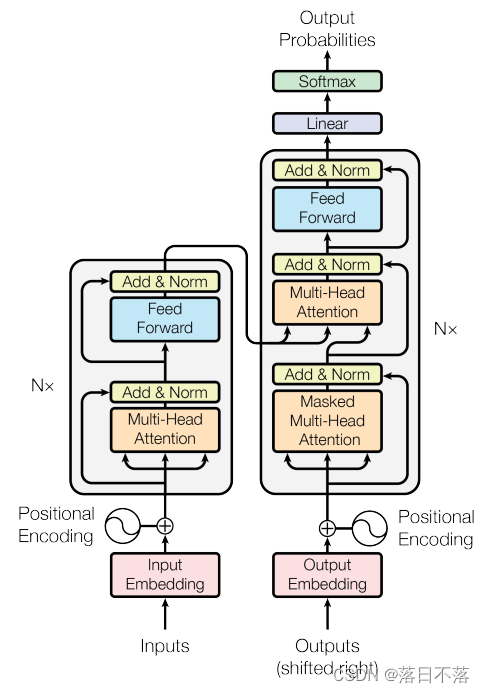
每一层在之后会讲解,可以先看架构图知道一个大概即可。
3.Transformer中的encoder和decoder
先来说说LayerNorm这个操作,我们可以通过和BatchNorm做对比来解释一下:BatchNorm所做的事情是对于在一个batch中的所有样本的某一个特征做normalization,而LayerNorm所做的是将一个样本的所有特征进行normalization。
Encoder:6个堆叠,每一个encoder中有两个子层(sub-layer),第一个子层是多头注意力机制层,第二个子层是一个前馈神经网络层(说白了就是MLP,simple~),对于每一个子层用到了残差连接,为了适应残差,在每一层输出的维度都是512维。
即:![]()
Decoder:6个堆叠,每一个decoder中有三个子层(sub-layer),第一个子层是掩码的多头注意力机制层,后两层和encoder的两个子层一致。针对于这个Masked层,之所以是掩码,是因为我们希望比如预测yt的时候只看到y1到y(t-1),而不要看到yt之后的词。
4.注意力机制
注意力机制这个问题比较抽象,参与运算的有三个向量:query(请求),key(键)和value(值),它的输出计算为value的加权和,每一个value的权重是通过query和key进行相似度计算得来的,如果一个query和某一个key的相似度较高,那么这个key所对应的value的权重就会大一点。
在这里,我觉得看下面这个视频可以帮助大家更深入的理解Attention机制:
注意力机制的本质|Self-Attention|Transformer|QKV矩阵_哔哩哔哩_bilibili
以下是一个小demo,大家可以跑一下,看看输出是否合理:
import numpy as np
import math
def softmax(x):
c = np.max(x)
return np.exp(x - c)/np.sum(np.exp(x - c))
q = np.array([[57, 83]])
k = np.array([[51, 56, 58], [70, 82, 88]])
v = np.array([[40, 155], [43, 159], [48, 162]])
print(np.dot(softmax(np.dot(q,k)),v))在Transformer中,使用到的注意力计算方法为缩放点积注意力(Scaled Dot-Product Attention),让query和key做内积运算来计算相似度,内积越大,相似度越高,对应权值就越高,之所以除以根号dk,是为了缓解梯度消失的问题。我们可以使用矩阵的乘法,提高并行度,从而提高运算效率,公式为:
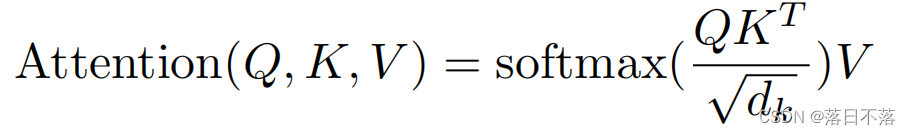
流程图为:
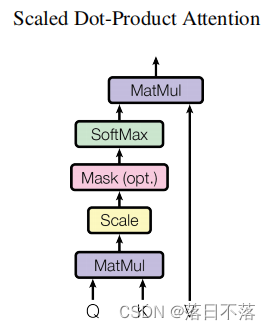
4.1自注意力机制(Self-Attention):
对于自注意力机制,Q、K、V其实是同一个矩阵,你的输出其实就是输入的加权和,权重来自于你本身和其他各个向量的相似度。
4.2多头注意力机制(Multi-Head Attention):


4.3掩码多头注意力机制(Masked Multi-Head Attention):
针对于Masked层,在计算上有一定的技巧,由于我们不想看到qt和kt之后的值,所以根据softmax的性质,我们只需要将qt和kt之后的值换成很大的复数,这样在经过softmax之后,这些项的概率基本为0,这样在算output的时候,我只用到了v1到v(t-1)的结果。
5.Embedding(词嵌入)和Positional Encoding(位置编码)
Embedding:在NLP领域,深度学习模型是不认字的,不能把字符直接输入进去,模型只认数字,不管是中文汉字还是英文字符,都需要先转成数字再输入到模型中去,这就是我们常说的“向量化”。不过我们的最终目标是向量化之后的数字可以完好地保持文本所包含的信息。这里将每一词转化为512维的向量。
Positional Encoding:首先,我们应该明白为什么要使用位置编码,因为我们在计算注意力的时候,我们是不去考虑每一个词的时序的,就比如有序的一句话我把里面的词全部打乱,那么乱序后的这句话所计算出的attention的值和原来有序的值是一样的,所以这时我们需要把时序信息加进来,具体规则如下:
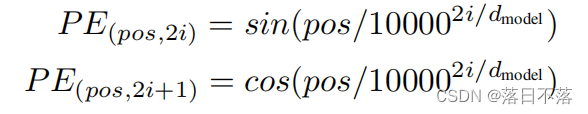
偶数位置用sin,奇数位置用cos。
以上就是Transformer的基本架构解析,这篇论文可以说是开创性的,论文花了大量笔墨去展示Transformer模型,对于模型中为什么使用某块架构,可能由于篇幅限制,解释仍欠佳,需要我们不断地去探索。另,附上本文创作的主要来源:















 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









