






本篇文章的主要内容:我会详细介绍自己使用Pytorch中的API搭建第一个神经网络并且使用GPU训练和验证的过程和感受,这个神经网络是一个基于CIFAR10数据集的图片分类的网络(10分类)。我想这不仅是对我学习知识的一个复习,更希望对刚刚入门深度学习的人有一定的启发。
我想,当你想针对于一个任务去搭建模型的时候你需要明确以下步骤(就我这次demo来说):
1.你要明确这个模型的任务是什么(比如这个网络的任务就是图片分类,这里有一个小技巧,一般分类任务在我看来是比较简单的,因为最后几步的操作处理一般都是一个Flatten层,一个Linear层,该Linear层的output_size一般都是分类的类别,最后做一个Softmax处理得出概率最大的类别)
2.设计完成该任务的网络模型,该任务的模型如下:
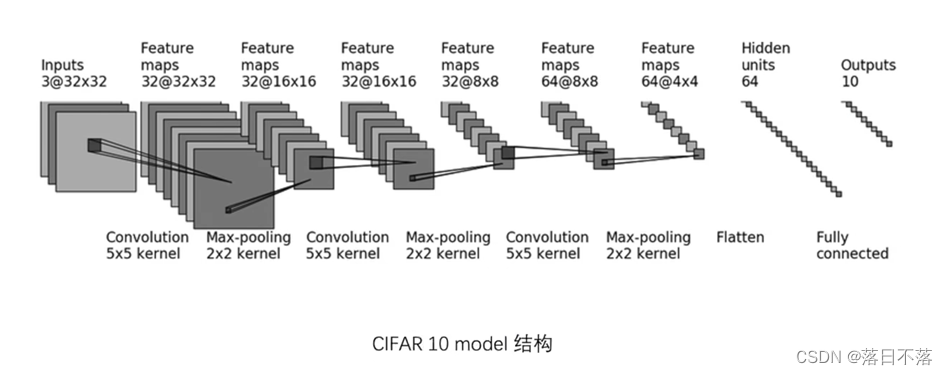
3.根据所设计的模型进行模型搭建,一般模型都要继承nn.Module类,因为这个类里面有很多网络模型的基本属性以及一个大框架(也可以理解为容器),然后需要重载init方法和forward方法,之后就是需要对Pytorch里面的API有一定的了解,比如该网络用到了卷积层、池化层、拉伸层和全连接层,以及每一层的参数是代表着什么,就比如第一个卷积层Conv2d(3,32,5,padding=2),表示该卷积层的输入通道数是3,输出通道数是32,滤波器(卷积核)的大小是5,边缘填充是2......(其他层还是需要大家自己去探索和学习),然后就是把每一层放入Sequential来存储,好处就是Sequential是一个维护好的有序字典,使用它的好处就是在重载forward的时候不用一个一个层的前向传播了,直接x = self.model1(x)一句话就把整个网络推理了一遍,这就是Sequential的强大。这样,综上,一个网络模型就搭建成功了。直接附上源码:
class MyFirstModel(nn.Module):
def __init__(self):
super(MyFirstModel, self).__init__()
self.model = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model(x)
return x4.准备数据集,数据集分为训练数据集和测试数据集,在这里我们直接使用torchvision.datasets中的CIFAR10数据集,可以通过len(train_data)、len(test_data)来看一看训练集和测试集的大小(训练集有50000张,测试集有10000张)。这里,我们获取数据集的时候需要两个步骤,首先是先拿到数据集,然后使用DataLoader类将数据集加载出来并规定batch_size的大小(也可以说成是mini-batch),源码如下:(注意拿数据集的时候要规定数据集下载的路径,是不是训练集,以及把数据转化为tensor数据类型)
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)5.有了模型和数据集,我们就需要确定一些必要的超参数和训练网络所使用的工具了,这里的工具一般有三个,一个是你要实例化这个网路模型,一个是你使用什么损失函数来计算output和targets之间的误差,另外一个就是你使用什么优化器来通过误差反向传播得到参数的梯度从而对参数更新,该任务使用交叉熵函数作为损失函数,使用随机梯度下降法来作为优化器,代码如下:
model = MyFirstModel()
loss_fn = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=0.05)
对于一些超参数,我们一般首先会设置epoch,它表示我要训练几轮(一轮训练代表把整个训练集都用了一遍),然后设置学习率learning_rate,它表示每一次梯度更新的幅度,不能太大也不能太小,源码如下:
learning_rate = 0.05
epoch = 106.接下来就到了我们最重要的一步,也是最核心的一步,就是对网络模型进行一轮一轮的训练,在每一轮训练过后,对测试集的这10000张图片进行一个准确率的统计,来看一看我们每一轮的训练有没有效果(这里说明一下第几次训练代表一个batch中的数据已经用完了,算作一次)。
详细说下一次训练的过程:首先,我们先取出数据imgs和对应的标签targets(都是按batch取的),然后让imgs走一遍前向传播,计算output和targets之间的loss,然后梯度清零(很重要,每一次训练前梯度都要清零!!!),将loss进行反向传播得到各个参数的梯度,之后使用优化器对每一个参数进行更新,一次训练结束。
当把训练集的数据全走一遍之后,一轮训练就结束了,我们可以使用测试集来看一看效果,步骤就是让测试集的imgs跑一遍推理,最后得到一个得分矩阵output,然后使用output.argmax(1)(这个函数的作用是取第一维的最大值索引,也就是每一行的最大值的索引)和targets中的数值比较,统计相同的个数(也就是分类正确的个数)。
在我们最后一轮训练过后,我们需要保存我们的模型,使用torch.save(模型,“路径”),这样,我们经过十轮的训练,就得到了一个训练好的模型。
for i in range(epoch):
print("----------------第{}轮训练开始-----------------".format(i+1))
for data in train_dataloader:
train_step += 1
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
#梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
#打印训练结果
if train_step % 100 == 0:
print("第{}次训练之后,loss:{}".format(train_step, loss.item()))
#定义测试正确的总个数
total_ac = 0
#开始验证
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = model(imgs)
total_ac += (output.argmax(1)==targets).sum()
print("第{}轮训练结束,测试集准确率为:{}".format(i+1, total_ac/len(test_data)))
#保存模型
if i == epoch-1:
print("最后一轮训练的模型已保存!!")
torch.save(model, "myfirstmodel.pth")7.最后一步,我们需要对我们训练的模型进行验证,方法就是我们可以去网上找一张狗的图片(CIFAR10数据集中有狗的分类),然后将模型加载出来,放在模型上跑一下,看一下输出是不是狗的那一类。
首先取测试图片时,我们需要注意,RGB三通道以及将其resize和reshape,源码如下:
image_path = "D:\\PythonProject\\鱼书手撕\\data\\dog.png"
image = Image.open(image_path)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
#print(image.shape)
image = torch.reshape(image, (1,3,32,32))之后就是将我们的模型加载出来,输出结果就可以了,代码如下:
myModel = torch.load("myfirstmodel.pth",map_location='cpu')
print(myModel(image).argmax(1))8.最后说一下这个模型我是在GPU上训练的,也可以在CPU上训练,我建议大家都去跑一跑,感受一下GPU训练和CPU训练的差距(还是很大的),如何在GPU上训练呢,直接设置一个device = torch.device("cuda"),写cuda就是使用GPU,写cpu就是使用CPU,然后在实例化模型、损失函数和数据集(训练和测试数据都要加)之后加一句.to(device)即可,代码如下:
device = torch.device("cuda")
model = MyFirstModel()
model = model.to(device)
loss_fn = CrossEntropyLoss()
loss_fn = loss_fn.to(device)
imgs = imgs.to(device)
targets = targets.to(device)深度学习最大的特点就是比较抽象,学习之路道阻且长,希望大家都可以耐下心来认真钻研和理解,共同进步!!















 1556
1556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









