







 本文讨论了如何利用注意力机制解决3D人体姿态估计中的挑战,包括从单目视频中获取精确姿势、处理运动一致性以及克服传统方法的局限性。介绍了几种创新的注意力模型如TemporalAttention、KernelAttention和HSTFormer,展示了在提升3D姿态预测准确性方面的贡献。
本文讨论了如何利用注意力机制解决3D人体姿态估计中的挑战,包括从单目视频中获取精确姿势、处理运动一致性以及克服传统方法的局限性。介绍了几种创新的注意力模型如TemporalAttention、KernelAttention和HSTFormer,展示了在提升3D姿态预测准确性方面的贡献。
12.Attention Mechanism Exploits Temporal Contexts: Real-time 3D Human Pose Reconstruction(CVPR 2020)
想解决的问题:
①传统方法通常在高度受控的环境下使用专用设备,例如多视图捕获、标记系统和多模态传感,这需要费力的设置过程,限制了它们的实际用途。这些工作的重点是从任意单目视频中进行三维姿态估计,由于人体动态的高维可变性和非线性,这些工作极具挑战性。端到端的学习过程减少了使用定制特征或空间约束的需要,从而最大限度地减少了特征错误,例如重复计算图像证据。
②虽然关于 3D 姿态预测的大量强大的深度模型正在出现(从卷积神经网络 (CNN) 到生成对抗网络 (GAN)),这些方法中的许多方法都专注于单个图像推断,这倾向于抖动运动或不精确的身体配置。为了解决这个问题,需要考虑时间信息以获得更好的运动一致性。
解决方法:
①在这项工作中,我们的目标是利用注意力模型进一步提高现有深度网络的准确性,同时保持视频中的自然时间连贯性。
贡献:
①开发一种系统方法,用于设计和训练基于注意力的模型,用于三个级别的姿势估计:2D 关节注意力、3D 到 2D 投影注意力和 3D 姿势注意力。
②通过扩张卷积的多尺度结构学习大时间感受野中的隐式依赖关系。
③设计集成基于注意力的模型和膨胀卷积结构的系统架构,以增强 3D 姿势推断,以促进性能驱动的动画应用。
网络框架:
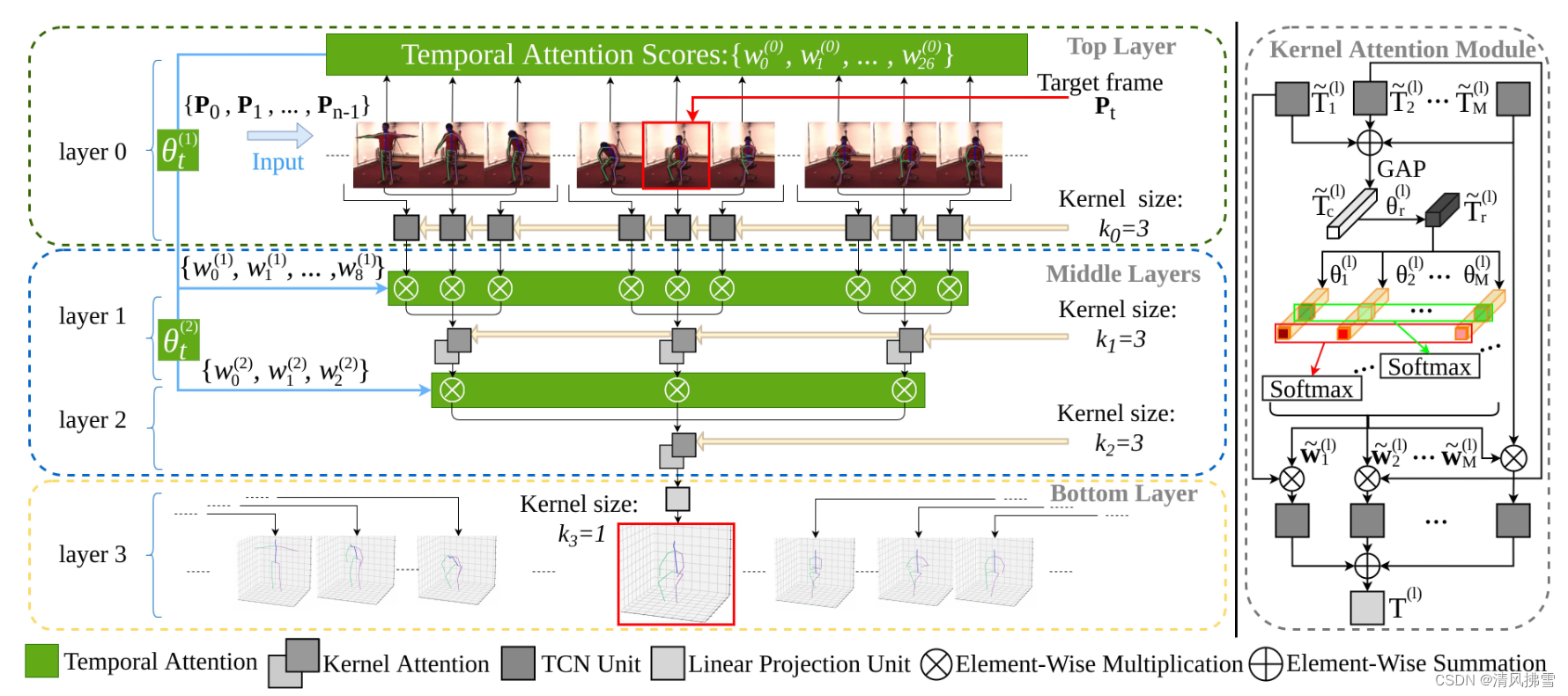
Temporal Attention:给输出的张量提供贡献度量,每一个attention模块产生一组标量,权衡层内不同张量的重要性,根据经验,我们通过简单地计算标准化互相关(ncc)来获得理想的结果,该标准化互相关测量 Pi 和 Pt 在 2D 关节位置上的正余弦相似度: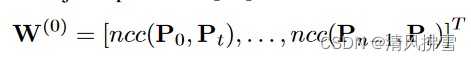 ,输出 W(0) 被转发到注意力矩阵 θt(l) 以为后续层生成张量权重。
,输出 W(0) 被转发到注意力矩阵 θt(l) 以为后续层生成张量权重。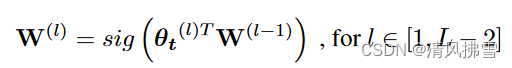
Kernel Attention:类似于时序注意力一样,在每一层的kernel注意力模块设计一个通道权重分配w(l),上图右半部分描述了如何通过权重调整更新tensor T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









