







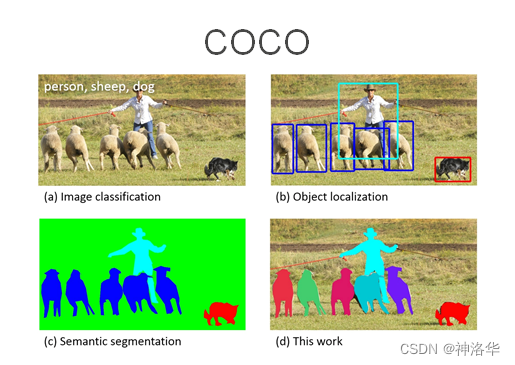
一、目标检测
1.1 目标检测简介
目标检测介绍
目标检测或目标识别(object recognition)是计算机视觉领域中最基础且最具挑战性的任务之一,其包含物体分类和定位。为实例分割、图像捕获、视频跟踪等任务提供了强有力的特征分类基础。
目标检测模型
深度学习目标检测方法分为分为Anchor-Based(锚框法)和Anchor-Free(无锚框)两大类,根据有无区域提案阶段划分为双阶段模型和单阶段检测模型。

- 双阶段模型:区域检测模型将目标检测任务分为区域提案生成、特征提取和分类预测三个阶段。在区域提案生成阶段,检测模型利用搜索算法如选择性搜索(SelectiveSearch,SS)、EdgeBoxes、区 域 提 案 网 络(Region Proposal Network,RPN) 等在图像中搜寻可能包含物体的区域。在特征提取阶段,模型利用深度卷积网络提取区域提案中的目标特征。在分类预测阶段,模型从预定义的类别标签对区域提案进行分类和边框信息预测。
- 单阶段模型:单阶段检测模型联合区域提案和分类预测,输入整张图像到卷积神经网络中提取特征,最后直接输出目标类别和边框位置信息。这类代表性的方法有:YOLO、SSD和CenterNet等。


目标检测数据集
目前主流的通用目标检测数据集有PASCAL VOC、ImageNet、MS COCO、Open Images和Objects365。
目标检测评价指标
当前用于评估检测模型的性能指标主要有帧率每秒(Frames Per Second,FPS)、准确率(accuracy)、精确率(precision)、召回率(recall)、平均精度(Average Precision,AP)、平均 精度均值(mean Average Precision,mAP)等。
-
FPS即每秒识别图像的数量,用于评估目标检测模型的检测速度;
-
P-R曲线:以Recall、Precision为横纵坐标的曲线
如下图所示,当检测框和标注框的IoU>设定阈值(比如0.3)时,可以认为这个检测框正确检测出物体。IoU>=阈值的检测框的数量就是TP。

-
AP(Average Precision):对不同召回率点上的精确率进行平均,在PR曲线图上表现为某一类别的 PR 曲线下的面积;
-
mAP(mean Average Precision):所有类别AP的均值
目标检测研究方向
目标检测方法可分为检测部件、数据增强、优化方法和学习策略四个方面 。其中检测部件包含基准模型和基准网络;数据增强包含几何变换、光学变换等;优化方法包含特征图、上下文模型、边框优化、区域提案方法、类别不平衡和训练策略六个方面,学习策略涵盖监督学习、弱监督学习和无监督学习。

边界框(bounding box)
- 图片分类一般默认图片中只有一个主体,而目标检测任务中,图片通常含有多个主体。不仅想知道它们的类别,还想得到它们在图像中的具体位置。
- 在目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置。边界框是矩形的,表示方式有三种:
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
- (中心x,中心y,宽,高)
- 目标检测数据集的常见表示:每一行表示一个物体,对于每一个物体而言,用“图片文件名,物体类别,边缘框”表示,由于边缘框用4个数值表示,因此对于每一行的那一个物体而言,需要用6个数值表示。
- 目标检测领域常用数据集:COCO(80类物体,330K图片,所有图片共标注1.5M物体)
下面加载本节将使用的示例图像。可以看到图像左边是一只狗,右边是一只猫。 它们是这张图像里的两个主要目标。
%matplotlib inline
import torch
from d2l import torch as d2l
# 下面加载本节将使用的示例图像。可以看到图像左边是一只狗,右边是一只猫。 它们是这张图像里的两个主要目标。
d2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img);
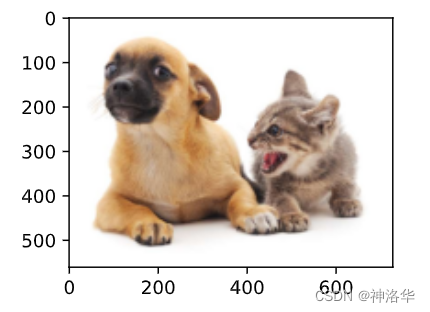
我们将根据坐标信息[定义图像中狗和猫的边界框]。 图像中坐标的原点是图像的左上角,向右的方向为 𝑥 轴的正方向,向下的方向为 𝑦 轴的正方向
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
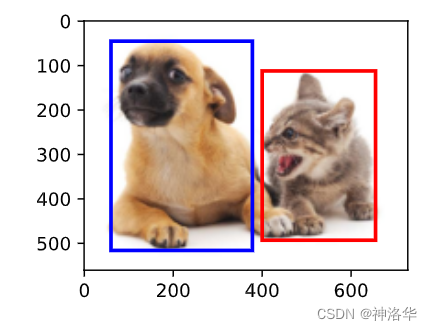
我们可以[将边界框在图中画出],以检查其是否准确。 画之前,我们定义一个辅助函数bbox_to_rect。 它将边界框表示成matplotlib的边界框格式。
#@save
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
在图像上添加边界框之后,我们可以看到两个物体的主要轮廓基本上在两个框内。
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));
我们还可以在两种常用的边界框表示(中间,宽度,高度)和(左上,右下)坐标之间进行转换。
#@save
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
#@save
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
1.2 目标检测数据集
目标检测领域没有像MNIST和Fashion-MNIST那样的小数据集。 为了快速测试目标检测模型,我们收集并标记了一个小型数据集。 首先,我们拍摄了一组香蕉的照片,并生成了1000张不同角度和大小的香蕉图像。 然后,我们在一些背景图片的随机位置上放一张香蕉的图像。 最后,我们在图片上为这些香蕉标记了边界框。
- 下载数据集
- 包含所有图像和CSV标签文件的香蕉检测数据集可以直接从互联网下载。
%matplotlib inline
import os
import pandas as pd
from mxnet import gluon, image, np, npx
from d2l import mxnet as d2l
npx.set_np()
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
- 读取数据集
- 通过
read_data_bananas函数,我们读取香蕉检测数据集。 该数据集包括一个的CSV文件,内含目标类别标签和位于左上角和右下角的真实边界框坐标。
#@save
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
#将所有图片读到内存(数据集比较小)
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
#返回图片和标签tensor。/256是除以高宽(图片是256*256),得到一个0-1的数
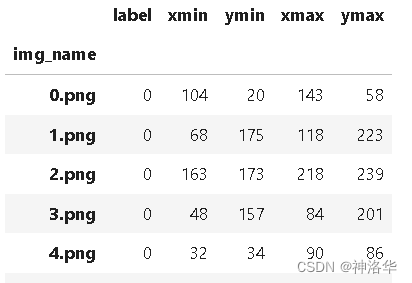
label.csv格式如下:

读出来csv_data数据集格式如下:
- 通过使用
read_data_bananas函数读取图像和标签,以下BananasDataset类别将允许我们创建一个自定义Dataset实例来加载香蕉检测数据集。
#@save
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
#下面一行是打印训练测试集各读了多少样本
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
- 最后,我们定义
load_data_bananas函数,来为训练集和测试集返回两个数据加载器实例。对于测试集,无须按随机顺序读取它。
#@save
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size)
return train_iter, val_iter
- 让我们读取一个小批量,并打印其中的图像和标签的形状。 图像的小批量batch[0]的形状为(批量大小、通道数、高度、宽度)这与我们之前图像分类任务中的相同。 标签的小批量batch[1]的形状为(批量大小,m,5),其中m是数据集的任何图像中边界框可能出现的最大数量。
- 通常来说,图像可能拥有不同数量的主体,则有不同数据的边界框,这样会造成每个批量标签不一样。所以限制每张图片主体最多有m个。
- 对于不到m个主体的图像将被非法边界框填充。这样,每个边界框的标签将被长度为5的数组表示, 即[𝑙𝑎𝑏𝑒𝑙,𝑥𝑚𝑖𝑛,𝑦𝑚𝑖𝑛,𝑥𝑚𝑎𝑥,𝑦𝑚𝑎𝑥] (坐标值域在0到1之间)。这样每个批次物体数量一样。 对于香蕉数据集而言,由于每张图像上只有一个边界框,因此 𝑚=1 。
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape
(torch.Size([32, 3, 256, 256]), torch.Size([32, 1, 5]))
让我们展⽰10幅带有真实边界框的图像。我们可以看到在所有这些图像中⾹蕉的旋转⻆度、⼤⼩和位置都有所不同。当然,这只是⼀个简单的⼈⼯数据集,实践中真实世界的数据集通常要复杂得多。
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])

3. 小结
- 我们收集的香蕉检测数据集可用于演示目标检测模型。
- 用于目标检测的数据加载与图像分类的数据加载类似。但是,在目标检测中,标签还包含真实边界框的信息,它不出现在图像分类中。
1.3 锚框
1.3.1 生成锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。主流算法为锚框。即:
- 读取图片,和图片已经标记好的边缘框
- 根据图片生成大量锚框,每个锚框是一个训练样本
- 预测每个锚框是否包含目标物体
- 如果是,则预测从锚框到实际边界框的偏移量
1.3.2 锚框的交并比
交并比(IoU):对于两个边界框,我们通常将它们的杰卡德系数(Jaccard 系数)称为交并比。给定集A和B:
J
(
A
,
B
)
=
∣
A
∩
B
∣
∣
A
∪
B
∣
.
J(\mathcal{A},\mathcal{B}) = \frac{\left|\mathcal{A} \cap \mathcal{B}\right|}{\left| \mathcal{A} \cup \mathcal{B}\right|}.
J(A,B)=∣A∪B∣∣A∩B∣.
交并比的取值范围在0和1之间。0 表示不重叠,1 表示完全相同。
接下来我们会对一张图片生成大量锚框,然后对这些锚框进行标记,即:
- 每个锚框是一个训练样本(要么固定生成,要么根据图片生成)
- 对锚框标记,要么标成背景,要么关联上一个真实的边界框。
- 生成的大量锚框都是负样本。
1.3.3标号锚框的常见算法
如下图,矩阵的列表示标记好的四个真实边界框 A 1 A_1 A1、 A 2 A_2 A2、 A 3 A_3 A3、 A 4 A_4 A4,行表示生成好的锚框 B 1 B_1 B1—- B 9 B_9 B9。这样我们计算每个边界框和锚框的交并比值,填在矩阵中。
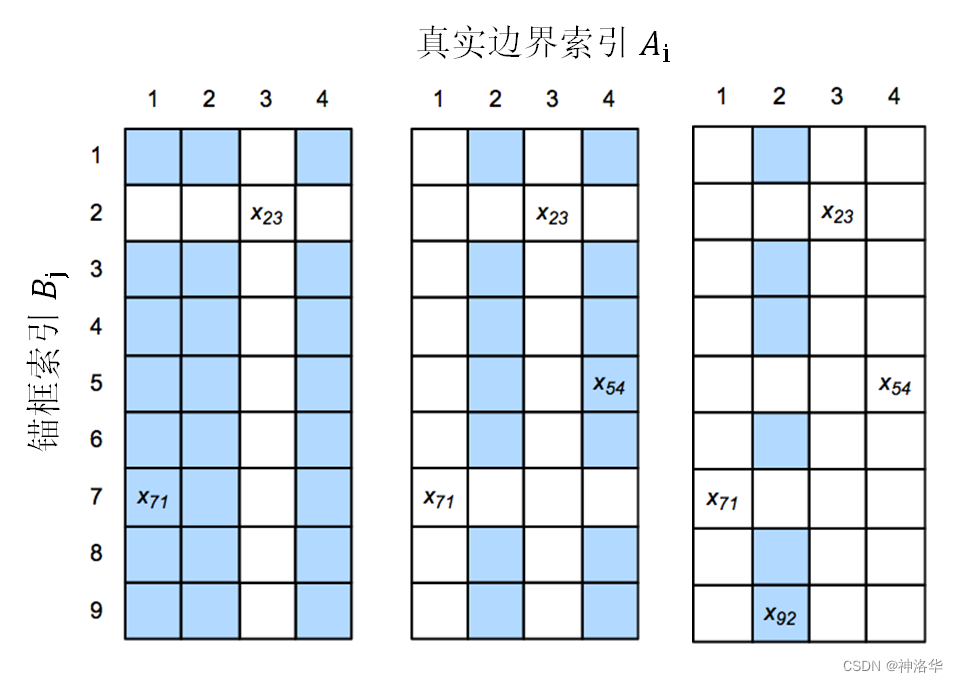
- 假设矩阵 X 中最大值为 x 23 x_{23} x23,我们将分配真实边界框 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_3 给锚框 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_2(重合度最高)。
- 丢弃矩阵中第2行和第3列的所有元素,找出剩余阴影部分的最大元素 x 71 x_{71} x71,为锚框KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_7分配真实边界框 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_1 。
- 丢弃矩阵中第7行和第1列的所有元素,找出剩余阴影部分的最大元素 x 54 x_{54} x54,为锚框KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_5分配真实边界框 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_4 。
- 最后,丢弃矩阵中第5行和第4列的所有元素,找出剩余阴影部分的最大元素 x 92 x_{92} x92,为锚框KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_9分配真实边界框 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?_2 。
1.3.4 非极大值抑制NMS(non-maximum suppression)
由于实际中,每张图片会生成很多锚框,其中很多锚框其实是很相似的。所以其实可以把这些相似的锚框合并,删除多余的,保留剩下的锚框。NMS是其中一种合并锚框方法,步骤为:
- 选择所有非背景类锚框的最大预测值对应的锚框A(比如下图蓝色框dog=0.9,预测最相似)
- 删除所有和锚框A交并比大于某个值 θ \theta θ的锚框(删除绿色框和红色框)
- 重复以上过程,直到所有锚框要么被选中,要么被删除(选择紫色框,开始合并。紫色和蓝色不相似,所以上一轮没被删除)
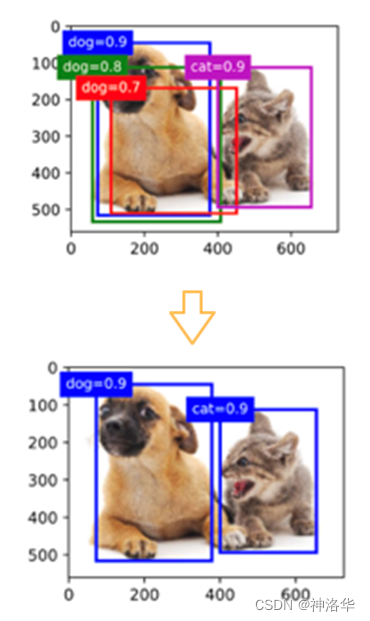
总结: - 一类目标检测方法基于锚框来预测
- 每个锚框是一个训练样本。在训练集中,我们需要给每个锚框两种类型的标签。一个是预测锚框中是否含有要检测的物体,另一个是锚框相对于边界框的偏移量。
- 预测时,我们可以使用非极大值抑制(NMS)来删除类似的预测边界框,从而简化输出。
二、 手写目标检测(锚框)
2.1 锚框算法
2.1.1 以每个像素为中心点生成锚框
各种目标检测算法,都会研究如何生成高质量的锚框。这里介绍一种简单的生成算法:以每个像素为中心点生成锚框。
假设输入图像的高度为
h
h
h,宽度为
w
w
w。我们以图像的每个像素为中心生成不同形状的锚框:缩放比为
s
∈
(
0
,
1
]
s\in (0, 1]
s∈(0,1](即锚框占图片大小的比例),宽高比为
r
>
0
r > 0
r>0。那么锚框的宽度和高度分别是
w
s
r
ws\sqrt{r}
wsr和
h
s
/
r
hs/\sqrt{r}
hs/r。
缩放比scale取值
s
1
,
…
,
s
n
s_1,\ldots, s_n
s1,…,sn,宽高比aspect ratio取值
r
1
,
…
,
r
m
r_1,\ldots, r_m
r1,…,rm。当使用这些比例和长宽比的所有组合以每个像素为中心时,输入图像将总共有
w
h
n
m
whnm
whnm个锚框,计算复杂性很容易过高。在实践中,我们只考虑包含
s
1
s_1
s1或
r
1
r_1
r1的组合:(
s
1
s_1
s1、
r
1
r_1
r1是最合适的比例)
( s 1 , r 1 ) , ( s 1 , r 2 ) , … , ( s 1 , r m ) , ( s 2 , r 1 ) , ( s 3 , r 1 ) , … , ( s n , r 1 ) . (s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1). (s1,r1),(s1,r2),…,(s1,rm),(s2,r1),(s3,r1),…,(sn,r1).
也就是说,以同一像素为中心的锚框的数量是 n + m − 1 n+m-1 n+m−1。对于整个输入图像,我们将共生成 w h ( n + m − 1 ) wh(n+m-1) wh(n+m−1)个锚框。
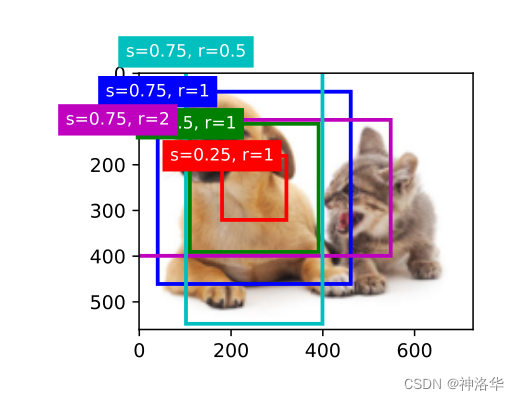
上图中, s 1 s_1 s1、 r 1 r_1 r1是最合适的缩放比和高宽比。比如下面代码中选取锚框的sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5]。 s 1 = 0.75 s_1=0.75 s1=0.75、 r 1 = 1 r_1=1 r1=1是最合适的取值,是一定要选的。
上述生成锚框的方法在下面的multibox_prior函数中实现。 我们指定输入图像、尺寸列表和宽高比列表,然后此函数将返回所有的锚框。
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # 精简输出精度
#@save
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape
561 728#读取的图片大小
torch.Size([1, 2042040, 4])#(批量大小,锚框的数量,锚框坐标)
将锚框变量Y的形状更改为(h,w,锚框的数量,4),然后访问以(250,250)为中心的第1个锚框。它有四个元素(xmin,ymin,xmax,ymax),且坐标都分别除以了图像的宽度和高度,所得的值介于0和1之间。
boxes = Y.reshape(h, w, 5, 4)#锚框数量=len(sizes)+len(ratios)-1=5
boxes[250, 250, 0, :]
tensor([0.06, 0.07, 0.63, 0.82])
为了显示以图像中以某个像素为中心的所有锚框,我们定义了下面的show_bboxes函数来在图像上绘制多个边界框。
#@save
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
变量boxes中x轴和y轴的坐标值已分别除以图像的宽度和高度。 绘制锚框时,我们需要恢复它们原始的坐标值。 因此,我们在下面定义了变量bbox_scale。 现在,我们可以绘制出图像中所有以(250,250)为中心的锚框了
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
#坐标是(xmin,ymin,xmax,ymax)除以了w、h。所以反过来乘以(w,h,w,h)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])
2.1.2 计算交并比
给定两个锚框或边界框的列表,以下box_iou函数将在这两个列表中计算它们成对的交并比。
#@save
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
#计算box面积
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量), areas2:(boxes2的数量)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
2.1.3 在训练数据中标注锚框
assign_anchor_to_bbox:将真实边界框分配给锚框
在训练集中,我们将每个锚框视为⼀个训练样本。为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签。预测时,我们为每个图像生成多个锚框,预测所有锚框的类别和偏移量,最后只输出符合特定条件的预测边界框。
定义assign_anchor_to_bbox函数,将真实边界框分配给锚框(参考上面标号锚框的常见算法):
#@save
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框
ground_truth:边界框 ,anchors:锚框
iou_threshold=0.5表示某个锚框和任何其它锚框小于0.5,就把它删掉"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 计算所有锚框和边界框的IoU。位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = box_iou(anchors, ground_truth)
# 对于每个锚框,分配的真实边界框的张量
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# 根据阈值,决定是否分配真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= 0.5).reshape(-1)
box_j = indices[max_ious >= 0.5]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
#每次找出最大的IoU
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
#删除行和列
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
offset_boxes:标记偏移量
假设一个锚框A被分配了一个真实边界框B。那么,锚框A的类别将被标记为与B相同。另外,锚框A的偏移量将根据B和A中心坐标的相对位置以及这两个框的相对位置进行标记(如果是两个框的四个坐标直接相减算偏移,后续不好预测)。给定框A和B,中心坐标分别为
(
x
a
,
y
a
)
(x_a ,y_a )
(xa,ya)和
(
x
b
,
y
b
)
(x_b ,y_b )
(xb,yb),宽度分别为
w
a
w_a
wa 和
w
b
w_b
wb ,长度分别为
h
a
h_a
ha和
h
b
h_b
hb 。我们可以将A的偏移量标记为:
(
x
b
−
x
a
w
a
−
μ
x
σ
x
,
y
b
−
y
a
h
a
−
μ
y
σ
y
,
log
w
b
w
a
−
μ
w
σ
w
,
log
h
b
h
a
−
μ
h
σ
h
)
,
\left( \frac{ \frac{x_b - x_a}{w_a} - \mu_x }{\sigma_x}, \frac{ \frac{y_b - y_a}{h_a} - \mu_y }{\sigma_y}, \frac{ \log \frac{w_b}{w_a} - \mu_w }{\sigma_w}, \frac{ \log \frac{h_b}{h_a} - \mu_h }{\sigma_h}\right),
(σxwaxb−xa−μx,σyhayb−ya−μy,σwlogwawb−μw,σhloghahb−μh),
其中常量的默认值为 μ x = μ y = μ w = μ h = 0 , σ x = σ y = 0.1 \mu_x = \mu_y = \mu_w = \mu_h = 0, \sigma_x=\sigma_y=0.1 μx=μy=μw=μh=0,σx=σy=0.1 , σ w = σ h = 0.2 \sigma_w=\sigma_h=0.2 σw=σh=0.2。这样做使数值分的比较开,均值方差都比较好做预测。
下面的 offset_boxes 函数中可以实现这种转换。
#@save
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
multibox_target:标记类别和偏移量
如果一个锚框没有被分配真实边界框,我们只需将锚框的类别标记为“背景”(background)。 背景类别的锚框通常被称为“负类”锚框,其余的被称为“正类”锚框。 我们使用以下multibox_target函数,来标记锚框的类别和偏移量(anchors参数)。 此函数将背景类别的索引设置为零,然后将新类别的整数索引递增一:
#@save
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
# 将类标签和分配的边界框坐标初始化为零
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# 使用真实边界框来标记锚框的类别。
# 如果一个锚框没有被分配,我们标记其为背景(值为零)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# 偏移量转换
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
#锚框对应真实边界框的偏移量offset,bbox_mask=0表示锚框是背景框,不需要预测类别;
#bbox_mask=1表示锚框对应一个真实边缘框。class_labels 表示锚框对应的类别
2.2 举例测试
代码见https://zh-v2.d2l.ai/chapter_computer-vision/anchor.html
2.2.1 生成锚框,并用multibox_target标记锚框类别和偏移量
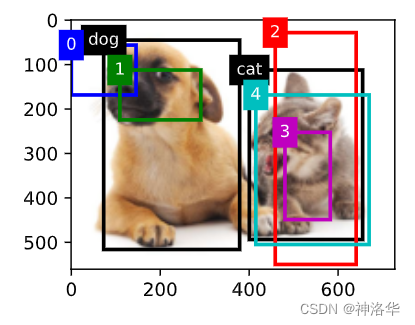
如下图,我们已经为加载图像中的狗和猫定义了真实边界框(黑色)。第一个元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的 (𝑥,𝑦) 轴坐标(范围介于0和1之间)。 我们还构建了五个锚框 A 0 , … , A 4 A_0, \ldots, A_4 A0,…,A4。然后我们在图像中绘制这些真实边界框和锚框。
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4']);
我们可以使用上面定义的multibox_target函数,根据狗和猫的真实边界框,标注这些锚框的分类和偏移量(背景、狗和猫的类索引分别为0、1和2)。另外我们为锚框和真实边界框样本添加一个维度(批量大小):
#unsqueeze表示增加一个维度
labels = multibox_target(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))
print(labels[0])
print(labels[1])
print(labels[2])
- 上面
multibox_target函数最后return (bbox_offset, bbox_mask, class_labels) - labels[0]包含了为每个锚框标记的四个偏移值。 请注意,负类锚框的偏移量被标记为零
- labels[1]是掩码(mask)变量,形状为(批量大小,锚框数的四倍)。 掩码变量中的元素与每个锚框的4个偏移量一一对应。 由于我们不关心对背景的检测,负类的偏移量不应影响目标函数。 通过元素乘法,掩码变量中的零将在计算目标函数之前过滤掉负类偏移量
- labels[2]表示锚框被标记的类别
#背景类偏移为0
tensor([[-0.00e+00, -0.00e+00, -0.00e+00, -0.00e+00, 1.40e+00, 1.00e+01,
2.59e+00, 7.18e+00, -1.20e+00, 2.69e-01, 1.68e+00, -1.57e+00,
-0.00e+00, -0.00e+00, -0.00e+00, -0.00e+00, -5.71e-01, -1.00e+00,
4.17e-06, 6.26e-01]])
tensor([[0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 1., 1.,
1., 1.]])
tensor([[0, 1, 2, 0, 2]])
具体的,让我们根据图像中的锚框和真实边界框的位置来分析下面返回的类别标签。
- 首先,在所有的锚框和真实边界框配对中,锚框 A 4 A_4 A4与猫的真实边界框的IoU是最大的。因此, A 4 A_4 A4的类别被标记为猫。
- 去除包含 A 4 A_4 A4或猫的真实边界框的配对,在剩下的配对中,锚框 A 1 A_1 A1和狗的真实边界框有最大的IoU。因此, A 1 A_1 A1的类别被标记为狗。
- 接下来,我们需要遍历剩下的三个未标记的锚框: A 0 A_0 A0、 A 2 A_2 A2和 A 3 A_3 A3。
对于 A 0 A_0 A0,与它拥有最大IoU的真实边界框的类别是狗,但IoU低于预定义的阈值(0.5),因此该类别被标记为背景;
对于 A 2 A_2 A2,与它拥有最大IoU的真实边界框的类别是猫,IoU超过阈值,所以类别被标记为猫;
对于 A 3 A_3 A3,与它拥有最大IoU的真实边界框的类别是猫,但值低于阈值,因此该类别被标记为背景。
2.2.2 offset_inverse函数预测边界框坐标
在前面,我们用multibox_target函数为锚框一一预测类别和偏移量。 预测时,根据其中某个带有预测偏移量的锚框而生成一个“预测好的边界框”。
下面的offset_inverse函数, 将锚框和偏移量预测作为输入,并应用逆偏移变换来返回预测的边界框坐标:
#@save
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox
2.2.3 使用非极大值抑制nms预测边界框
在前面我们讲过,以每个像素为中心点生成锚框时会产生大量的锚框,许多锚框非常相似,使用NMS方法可以合并属于同一目标的类似的预测边界框。其原理为:
对于一个预测边界框
B
B
B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为
p
p
p,则该概率所对应的类别
B
B
B即为预测的类别。具体来说,我们将
p
p
p称为预测边界框
B
B
B的置信度(confidence)。
在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表
L
L
L。然后我们通过以下步骤操作排序列表
L
L
L:
- 从 L L L中选取置信度最高的预测边界框 B 1 B_1 B1作为基准,然后将所有与 B 1 B_1 B1的IoU超过预定阈值 ϵ \epsilon ϵ的非基准预测边界框从 L L L中移除。这时, L L L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
- 从 L L L中选取置信度第二高的预测边界框 B 2 B_2 B2作为又一个基准,然后将所有与 B 2 B_2 B2的IoU大于 ϵ \epsilon ϵ的非基准预测边界框从 L L L中移除。
- 重复上述过程,直到 L L L中的所有预测边界框都曾被用作基准。此时, L L L中任意一对预测边界框的IoU都小于阈值 ϵ \epsilon ϵ;因此,没有一对边界框过于相似。
- 输出列表 L L L中的所有预测边界框。
定义nms函数按降序对置信度进行排序并返回其索引:
#@save
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)#按照scores进行置信度排序
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
定义以下multibox_detection函数来将nms应用于预测边界框:
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):#对所有样本,拿出预测值做nms
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
2.2.4 举例测试
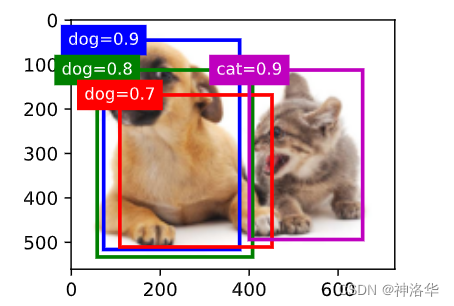
现在让我们将上述算法应用到一个带有四个锚框的具体示例中。 为简单起见,我们假设预测的偏移量都是零,这意味着预测的边界框即是锚框。 对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
在图像上绘制这些预测边界框和置信度:
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
调用multibox_detection函数来执行非极大值抑制,其中阈值设置为0.5。 请注意,我们在示例的张量输入中添加了维度。
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
output
tensor([[[ 0.00, 0.90, 0.10, 0.08, 0.52, 0.92],
[ 1.00, 0.90, 0.55, 0.20, 0.90, 0.88],
[-1.00, 0.80, 0.08, 0.20, 0.56, 0.95],
[-1.00, 0.70, 0.15, 0.30, 0.62, 0.91]]])
- 我们可以看到output形状是(批量大小,锚框的数量,6),6表示同一预测边界框的输出信息有6个元素。
- 第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了。 第二个元素是预测的边界框的置信度。 其余四个元素分别是预测边界框左上角和右下角的 (𝑥,𝑦) 轴坐标(范围介于0和1之间)
删除-1类别(背景)的预测边界框后,我们可以输出由非极大值抑制保存的最终预测边界框:
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
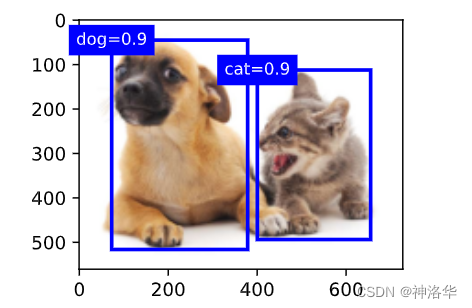
实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。 我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
2.3 小结
- 我们以图像的每个像素为中心生成不同形状的锚框。
- 交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。
- 在训练集中,我们需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真实相对于边界框的偏移量。
- 在预测期间,我们可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
本人理解的整个算法过程:
- 读取图片,和图片已经标记好的边缘框
- 使用
multibox_prior函数为每个图片生成大量锚框,每个锚框是一个训练样本 - 训练阶段:为每个锚框标记类别和偏移量。具体的:
- 使用
assign_anchor_to_bbox函数将最接近的真实边界框分配给锚框(3.3.3根据box_iou值进行计算) - 使用
multibox_target函数标记锚框的类别和对边界框的偏移量(4.1.3)。multibox_target举例见4.2.1.
- 使用
- 预测阶段:根据生成的锚框预测边缘框:
offset_inverse函数,反过来根据锚框的偏移量预测边界框坐标- 预测前,
multibox_detection函数根据nms算法去除相似的锚框和无效的锚框(背景框)
2.4.讨论
- 最大预测值指的是分类的置信度还是锚框预测的置信度?这两个置信度是混在一起预测吗?
只有分类有置信度,锚框预测是一个回归问题,没有置信度 - 每次做nms时,是针对相同类别(狗)做循环过滤去除,还是对所有类别(猫和狗)都做去除?
两种方法一般都支持,本节讲的是对所有类别(猫和狗)放在一起做去除(见4.2.3)。也可以在每一类里面做nms。 assign_anchor_to_bbox里面真实边缘框哪里来的?
真实边缘框是人工标注的,读取数据集的时候就会读入进来。锚框的生成是根据算法(以每个像素为中心点生成锚框)生成,且生成时不能看真实边缘框。预测时没有真实边缘框,是根据生成的锚框预测边缘框(offset_inverse函数预测边界框坐标,且预测前锚框经过nms去除太相似的)- 锚框的宽度和高度分别是
w
s
r
ws\sqrt{r}
wsr和
h
s
/
r
hs/\sqrt{r}
hs/r,这是怎么计算的
二者相除保证高宽比是r - 为啥要给每个像素都做锚框,可以合并像素吗?
这是为了保证有足够多的 覆盖率 - 锚框的损失函数怎么定义?
锚框的预测是一个回归问题,损失函数根据偏移量来定义。后面目标检测算法会讲 - 可以根据特征点筛选像素再生成锚框吗?
可以的。yolo就是根据先验知识来选锚框,而不是真的每个像素都扫一遍。之所以本节用每个像素点来生成,一是有算法这么做,也可以用python实现。二是目标检测有很多其它优化,有很多工程点在里面没时间讲完,这里只是简单过一遍。
三、目标检测常见算法:区域卷积神经网络(R-CNN)系列
3.1 R-CNN
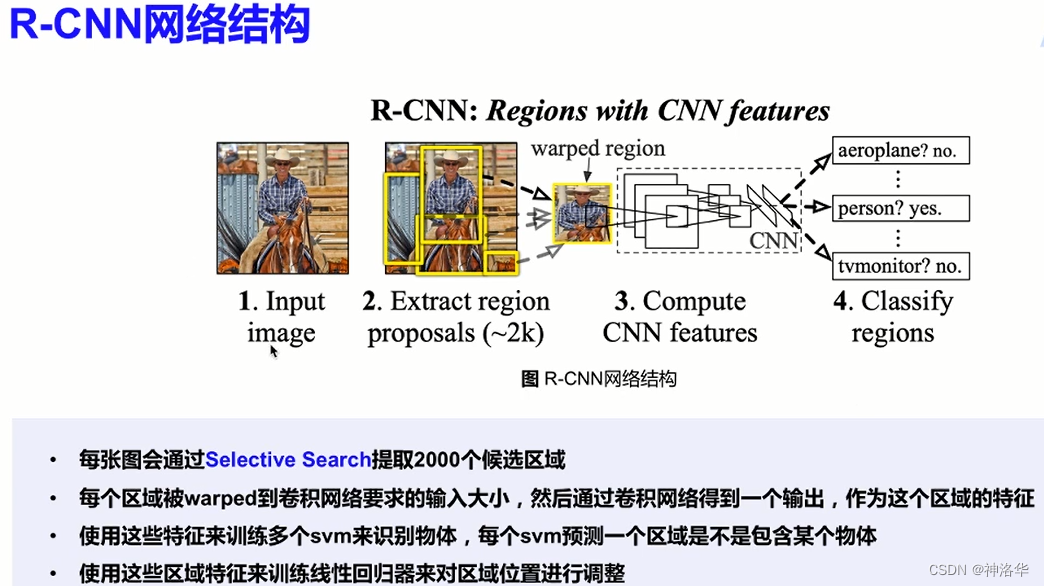
- 使用启发式搜索算法(selective search)选择锚框
- 使用预训练模型对每个锚框进行特征提取(每个锚框当做一张图片)
- 将每个锚框的提取特征及其标注的类别作为一个样本,训练多SVM对每个锚框进行分类,每个支持向量机用来判断样本是否属于某一个类别。(计算机视觉在神经网络之前主流分类器是SVM)
- 将每个锚框的提取特征及其标注的标注的边界框作为一个样本,训练线性回归模型来预测真实边界框
selective search:机器学习目标检测算法中的做法,根据传统图像特征,比如尺寸、纹理、颜色的相似度提取大概2000个候选框。
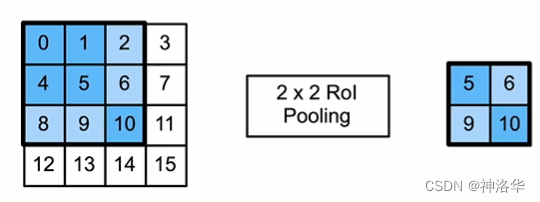
RoI 池化层
这里有一个问题:锚框的大小是不一样的,怎么保证这些锚框组成一个batch?通过兴趣区域池化层(region of interest pooling)实现。
RoI pooling核心思想:候选框共享特征图,并保持输出大小一致。 具体的:给定一个候选框,将其均匀地切割成 n x m 个块,每块对应到输入特征图上,然后输出每个块中的最大值。这样不管候选框多大,总是输出nm个值。
如下图,做一个2×2的RoI 池化。由于不能均匀切开,所以先做一个边界填充,再切成4块,取每块的最大值。
R-CNN三大不足:
- 候选区域太多,每个候选区域都需要通过CNN计算特征,计算量大
- Selective Search基于传统特征提取的区域质量不够好
- 特征提取、SVM分类器是分模块独立训练,没有联合起来系统性优化,训练耗时长
3.2 Fast R-CNN
R-CNN的主要性能瓶颈在于:对于每个锚框都用CNN提取特征,独自计算,其实很多锚框是有重叠的。Fast R-CNN改进在于:仅在整张图象上提取特征。
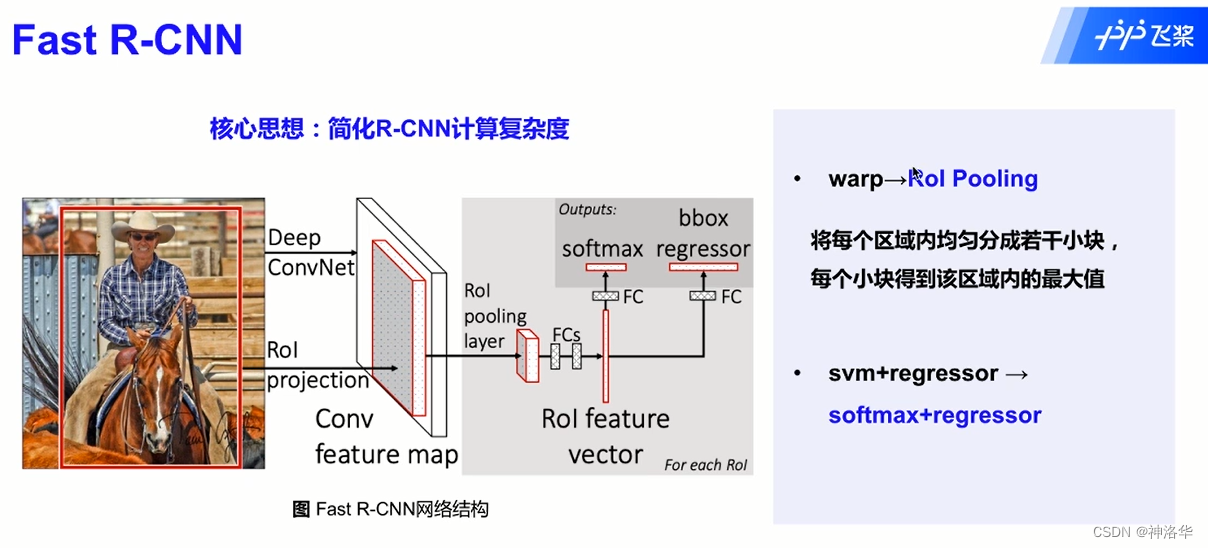
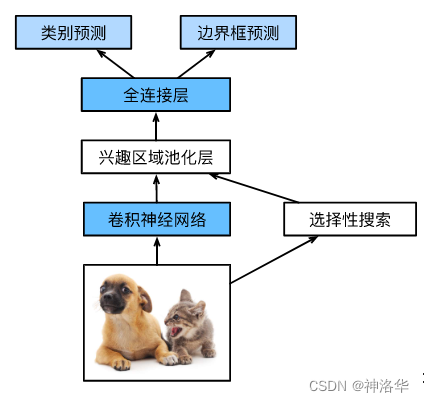
如上图,主要计算如下:
- 设输入为一张图像,将卷积神经网络的输出的形状记为 1 × c × h 1 × w 1 1 \times c \times h_1 \times w_1 1×c×h1×w1,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是某一个锚框
- 假设选择性搜索生成了
n
n
n个锚框,使用
兴趣区域汇聚层(RoI pooling):将卷积神经网络的输出和锚框作为输入,输出连结后的各个锚框抽取的特征,形状为 n × c × h 2 × w 2 n \times c \times h_2 \times w_2 n×c×h2×w2(RoI pooling后的特征图大小 h 2 × w 2 h_2 \times w_2 h2×w2) - 通过全连接层将输出形状变换为 n × d n \times d n×d,其中超参数 d d d取决于模型设计
- 预测 n n n个锚框的类别和边界框。全连接层的输出分别转换为形状为 n × q n \times q n×q( q q q是类别的数量)的输出和形状为 n × 4 n \times 4 n×4的输出,其中预测类别时使用softmax回归。
Fast R-CNN总结:
- 使用CNN对整张图片提取特征,得到Featrue Map,再进行锚框的选择性搜索得到锚框
- 按照锚框在原始图片的位置比例,将其在Featrue Map找出来,再抽取锚框的特征
- RoI池化为每个锚框返回固定长度的特征
- svm分类器替换为softmax多分类器,实现分类分支和回归分支的联合训练
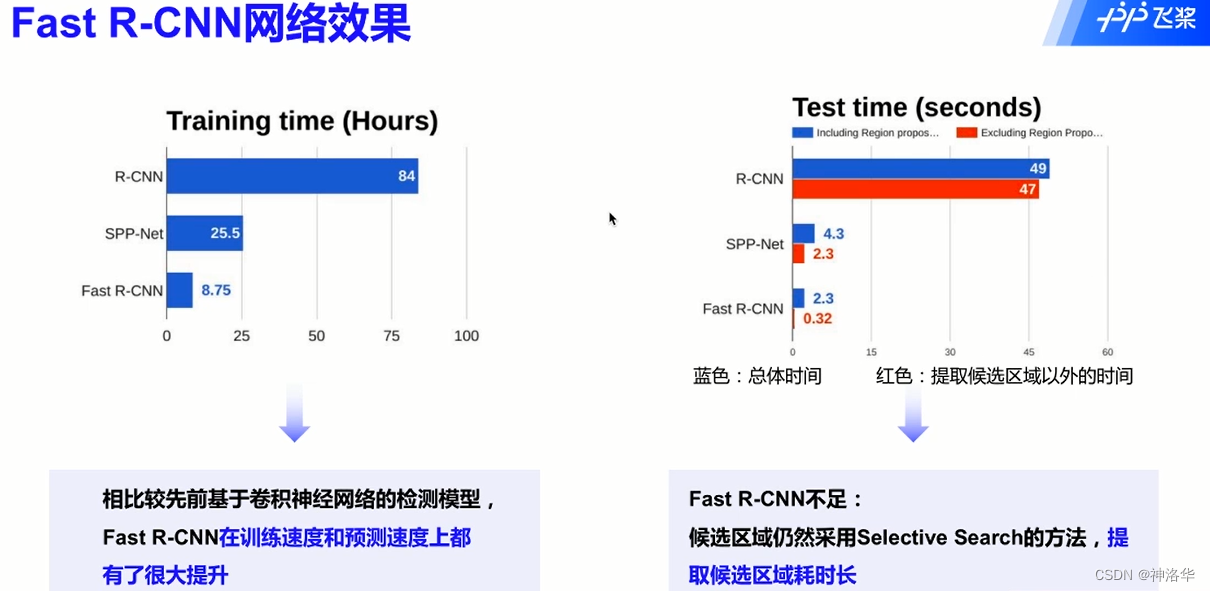
下图对比了几个模型的训练和预测的耗时,右下图蓝色部分表示整体的预测耗时,红色部分表示提取候选区域以外的时间。可见Fast R-CNN模型做预测时,大部分时间耗在提取候选区域上。
3. 3 Faster R-CNN
Fast R-CNN核心思想:使用RPN(区域提议网络region proposal network)代替启发式搜索Selective Search来生成提议区域(锚框),从而减少提议区域的生成数量,并保证目标检测的精度。

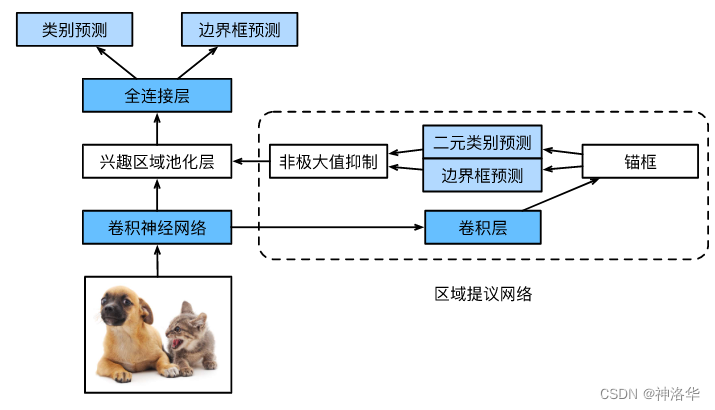
区域提议网络其实类似一个很粗糙的目标检测:
- RoI pooling需要CNN输出的Featrue Map和锚框
- CNN的输出进入一个卷积层,然后生成一堆锚框(启发式搜索或者别的方式)。根据提取的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用nms,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。
3.4 Mask R-CNN
如果在训练集中还标注了每个目标在图像上的像素级位置(比如无人机、自动驾驶领域),Mask R-CNN能够有效地利用这些详尽的标注信息进一步提升目标检测的精度。
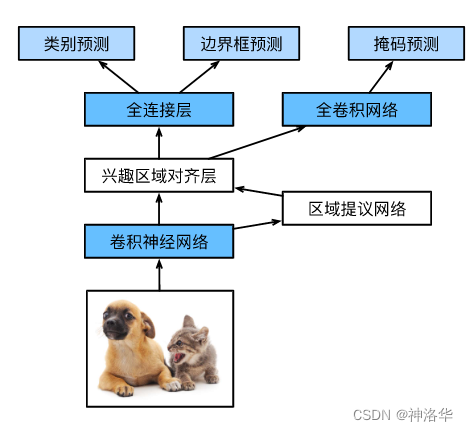
Mask R-CNN将兴趣区域汇聚层RoI pooling替换为了兴趣区域对齐层RoI align。RoI pooling在无法均分时有填充,但对于像素级标号来说,这种填充会造成像素级偏移。这样在边界处标号预测不准。RoI align简单来说不会填充,而使用双线性插值(bilinear interpolation)来保留特征图上的空间信息。
3.5 小结
- R-CNN是最早、最有名的的基于锚框和CNN的检测算法。R-CNN对图像选取若干提议区域(锚框),使用卷积神经网络对每个锚框执行前向传播以抽取其特征,然后再用这些特征来预测锚框的类别和边界框。
- Fast R-CNN对R-CNN的一个主要改进:只对整个图像做卷积神经网络的前向传播。它还引入了兴趣区域汇聚层,从而为具有不同形状的兴趣区域抽取相同形状的特征。
- Faster R-CNN将Fast R-CNN中使用的选择性搜索替换为参与训练的区域提议网络,这样后者可以在减少提议区域数量的情况下仍保证目标检测的精度。
- Mask R-CNN在Faster R-CNN的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。
- 在打比赛或者刷paper这种对精度要求特别高的时候可以使用Faster R-CNN、Mask R-CNN,工业界更关心速度。
四、目标检测算法:SDD(单发多框检测)
4.1 SSD简介
R-CNN是有两个网络,一个区域提议网络rpn抽取锚框特征,一个主网络用于训练。SSD(Single Shot MultiBox Detector)只用一个网络来训练模型。
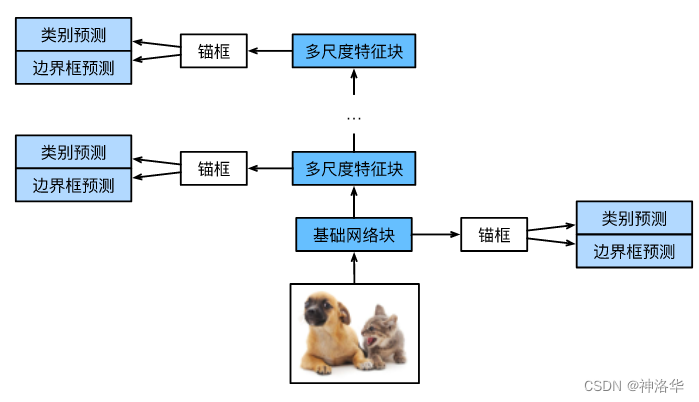
- 使用一个基础网络从原始图像中抽取特征,然后多个卷积层将高宽减半
- 在每段都生成锚框,然后对这些锚框进行类别预测和边界框预测
- 锚框生成方式:对于每个像素,生成n+m-1个锚框(缩放比scale取值 s 1 , … , s n s_1,\ldots, s_n s1,…,sn,宽高比aspect ratio取值 r 1 , … , r m r_1,\ldots, r_m r1,…,rm)。对于整个输入图像,我们将共生成 w h ( n + m − 1 ) wh(n+m-1) wh(n+m−1)个锚框。
- 底部预测小物体,顶部特征图压缩越来越狠,感受野越来越大,所以是预测大的物体。
SSD预测速度比Faster R-CNN系列快,但是精度会差一些。主要是SSD出来之后没有再更新升级了,很多这几年出现的新的优化或者trick没有加进去。
4.2 多尺度目标检测
在《动手深度学习13——计算机视觉(数据增广、微调、锚框目标检测)》4.1.1中,我们介绍了以输入图像的每个像素为中心,生成了多个锚框的算法。实际上,这种算法生成的锚框数量过多、计算量太大。一个减少锚框的想法是:
- 在输入图像中均匀采样一小部分像素,并以它们为中心生成锚框
- 卷积后的Featrue Map比较大的时候,可以考虑使用较小的scale。即当使用较小的锚框检测较小的物体时,我们可以采样更多的区域
- Featrue Map比较小的时候,可以考虑使用较大的scale。即对于较大的物体,我们可以采样较少的区域
为了演示如何在多个尺度下生成锚框,让我们先读取一张图像。 它的高度和宽度分别为561和728像素:
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
h, w
(561, 728)
定义函数display_anchors,用于在在特征图(fmap)上生成锚框(anchors),每个锚框以像素作中心。假设有
c
c
c张形状为
h
×
w
h \times w
h×w的特征图,那么共生成
h
w
hw
hw组锚框,每一组锚框有n+m-1个(见《动手深度学习13——计算机视觉(数据增广、微调、锚框目标检测)》4.1.1)。
def display_anchors(fmap_w, fmap_h, s):
"""
根据特征图的高宽以及缩放比scale,生成锚框,并打印出来。ratios固定为[1, 2, 0.5]
"""
d2l.set_figsize()
# 构造一个特征图,batch_size=1,channnel=10.这两个维度上的值不影响输出
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes,
anchors[0] * bbox_scale)
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])#s=0.15,锚框是特征图面积的0.15*0.15=0.225倍大小
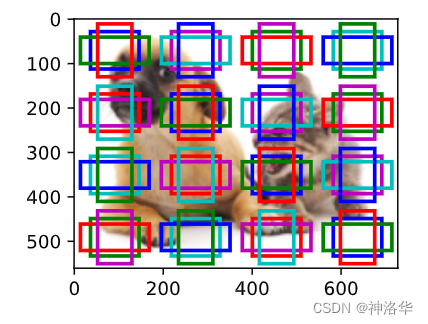
上图即是给定10个(通道数量)
4
×
4
4 \times 4
4×4的特征图,我们生成了16组锚框,每组包含3个中心相同的锚框。在当前尺度下,目标检测模型需要预测输入图像上 ℎ𝑤 组锚框类别和偏移量。然后,我们将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标:
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])
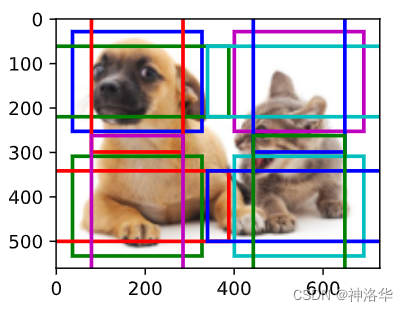
进一步将特征图的高度和宽度减小一半,然后将锚框的尺度增加到0.8。此时,锚框的中心即是图像的中心:
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
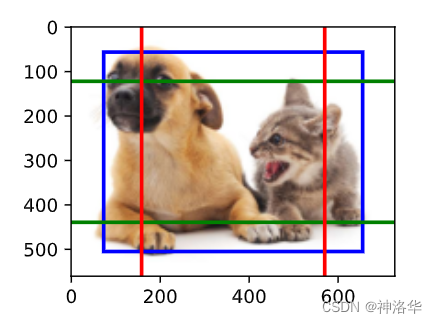
可以看出,Featrue Map比较小的时候,可以考虑使用较大的scale,生成较大的锚框来检测大的物体。而如果在较大的Featrue Map上也使用较大的scale,也可以生成大的锚框,但是这样锚框之间重叠会非常大,例如:
display_anchors(fmap_w=4, fmap_h=4, s=[0.8])
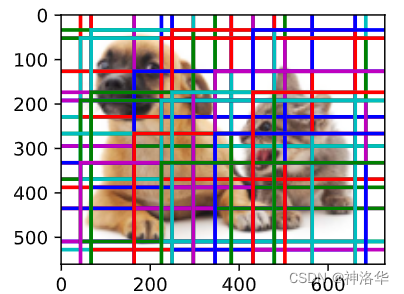
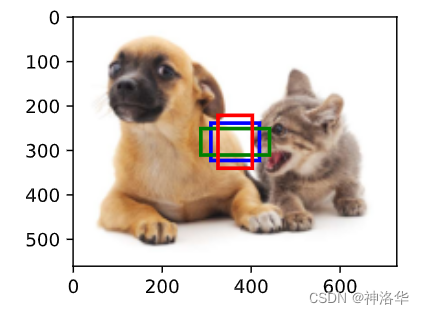
display_anchors(fmap_w=1, fmap_h=1, s=[0.15])
生成了多尺度的锚框,我们就可以用它们来检测不同尺度下各种大小的目标。这种算法在SSD中实现。
4.3 SSD算法实现
参考《13.7. 单发多框检测(SSD)》
本节代码不是为了给大家实际用的,只是给大家一个直观感受。因为代码都是python实现,会非常慢。如果是改成C++会快很多。真实的目标检测场景,代码一般多用C++去写,还有大量优化等等。
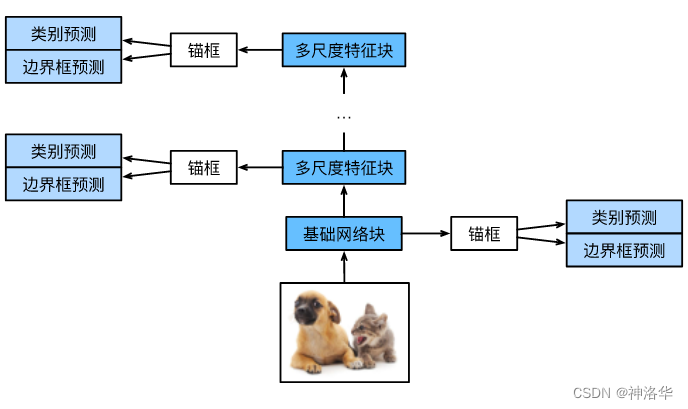
根据上一节内容,我们可以利用深层神经网络在多个层次上对图像进行分层表示,得到不同大小的特征图。然后应用多尺度锚框,从而实现多尺度目标检测。所以SSD模型主要由基础网络组成(VGG或者预训练的Resnet),其后是几个多尺度特征块。
4.3.1 预测层
类别预测层
类别预测层使用一个保持输入高和宽的卷积层,使输出和输入在特征图宽和高上的空间坐标一一对应( kernel_size=3, padding=1)。
在某个尺度下,设特征图的高和宽分别为
h
h
h和
w
w
w,每个像素生成
a
a
a(num_anchors)个锚框,总共 就是
h
w
a
hwa
hwa个锚框要预测类别。假设类别的数量为
q
q
q(num_classes),则锚框有 KaTeX parse error: Unexpected character: '?' at position 1: ?̲?+1 个类别(包含背景类0) 。
如果使用全连接层作为输出,很容易导致模型参数过多。所以这里使用《7.3 ⽹络中的⽹络(NiN)》卷积层的通道来输出类别预测的方法。即对于每个输入像素,输出通道数是a(q+1)。这些通道数就是每个像素生成的锚框的类别预测值。(所有像素生成的锚框都做预测)
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
#(输入通道数,每组锚框的数量,类别数)
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
边界框预测
边界框预测层的设计与类别预测层的设计类似。 唯一不同的是,这里需要为每个锚框预测4个偏移量,而不是𝑞+1个类别。
def bbox_predictor(num_inputs, num_anchors):#num_inputs输入通道数
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
4.3.2 连结多尺度的预测
不同尺度下预测输出的形状可能会有所不同, 为了将这两个预测输出链接起来以提高计算效率,我们将把这些张量转换为更一致的格式,方便后面进行loss计算等,而不用对每个不同的尺度做loss。下面举例说明:
def forward(x, block):
return block(x)
#Y1特征图的batch_size=2,channel=8,wh=20。
#Y1类别预测层输入channel=8,每像素生成锚框数=5,类别10
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10))
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10))
Y1.shape, Y2.shape
(torch.Size([2, 55, 20, 20]), torch.Size([2, 33, 10, 10]))
#Y1.shape表示对于20*20的每个像素,都做a(q+1)=55个锚框的类别预测
#Y2.shape表示对于10*10的每个像素,都做a(q+1)=33个锚框的类别预测
除了批量大小这一维度外,其他三个维度都具有不同的尺寸。通道维包含中心相同的锚框的预测结果,我们首先将通道维移到最后一维(这样每个像素预测值是连续的)。然后后三个维度拉平,形状变为(批量大小,高 × 宽 × 通道数),以便后面进行连结。
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
#channel维度丢到最后,这样每个像素预测值是连续的。start_dim=1表示后三维拉成向量
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
测试:
concat_preds([Y1, Y2]).shape
torch.Size([2, 25300])#55*20*20+33*10*10=25300
4.3.3 完整模型
1. 高宽减半block
为了在多个尺度下检测目标,我们在下面定义了高和宽减半块down_sample_blk。具体的,每个高和宽减半块由两个填充为 1 的 3×3 的卷积层、以及步幅为 2 的 2×2 最大汇聚层组成。
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):#两个卷积层
blk.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))#池化层
return nn.Sequential(*blk)
2. 基本网络块
基本网络块用于从输入图像中抽取特征,为了计算简洁,我们构造了一个小的基础网络,该网络串联3个高和宽减半块,并逐步将通道数翻倍。 给定输入图像的形状为 256×256:
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
#3个高宽减半块,通道数(3,16)、(16,32)、(32,64)
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape
torch.Size([2, 64, 32, 32])
3. 模型架构
完整的SSD由五个模块组成,每个块生成的特征图既用于生成锚框,又用于预测这些锚框的类别和偏移量。在这五个模块中,第一个是基本网络块,第二个到第四个是高和宽减半块,最后一个模块使用全局最大池将高度和宽度都降到1。
def get_blk(i):
if i == 0:
blk = base_net()#([batch, 64, 32, 32])
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1))#最后一个特征图压到1*1
else:
blk = down_sample_blk(128, 128)#数据集较小,所以后两个没有再倍增通道数
return blk
4.定义每个块的前向传播
与图像分类任务不同,此处的输出包括:CNN特征图Y;在当前尺度下根据Y生成的锚框;预测的这些锚框的类别和偏移量(基于Y)。(图片分类就只有输入X输出Y)
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)#特征图
#生成锚框时不知道特征图只有其大小也能提前生成,这样速度还快一点
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio)
#前向传播时不需要看锚框,而是整个特征图。只是算loss的时候尽量只看训练的锚框区域
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
5. 选取合适超参数
在 2.2 多尺度目标检测中,接近顶部的多尺度特征块,特征图较小,是用于检测较大目标的,因此需要生成更大的锚框(缩放比scale更大,也就是参数size)。
在下面,0.2和1.05之间的区间被均匀分成五个部分,以确定五个模块的在不同尺度下的较小值:0.2、0.37、0.54、0.71和0.88。之后,他们较大的值由
0.2
×
0.37
=
0.272
\sqrt{0.2 \times 0.37} = 0.272
0.2×0.37=0.272、
0.37
×
0.54
=
0.447
\sqrt{0.37 \times 0.54} = 0.447
0.37×0.54=0.447等给出。(每个尺度块size选两个参数,ratios三个取值,则每个像素生成4个锚框)
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619],
[0.71, 0.79],[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
6. 定义完整的模型TinySSD:
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]#5个块的输出通道数
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
# 五个尺度的特征图都做类别和边界框预测
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self,'blk_%d'%i)即访问self.blk_i
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)#多尺度连结
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)#2d变3d,方便做softmax预测类别
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
创建一个模型实例,执行前向计算
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
output anchors: torch.Size([1, 5444, 4])
output class preds: torch.Size([32, 5444, 2])#类别数=1,所以加上背景类是2
output bbox preds: torch.Size([32, 21776])#每个锚框做边界框预测有4个偏移量数值,所以一共是21766
第一个模块输出特征图的形状为 32 × 32 32 \times 32 32×32。第二到第四个模块为高和宽减半块,第五个模块为全局汇聚层。由于以特征图的每个单元为中心有 4 4 4个锚框生成,因此在所有五个尺度下,每个图像总共生成 ( 3 2 2 + 1 6 2 + 8 2 + 4 2 + 1 ) × 4 = 5444 (32^2 + 16^2 + 8^2 + 4^2 + 1)\times 4 = 5444 (322+162+82+42+1)×4=5444个锚框(w*h*a)。
4.3.4 SSD算法测试
1. 读取香蕉数据集
(见《动手深度学习13——计算机视觉(数据增广、微调、锚框目标检测)》中的3.2 目标检测数据集,或者《13.6. 目标检测数据集》)
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)
#读取图片和标注的边界框,这里每张图只标记一个香蕉,即一个边界框

2.定义模型,初始化其参数并定义优化算法
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
3. 定义损失函数和评价函数
目标检测有两种类型的损失:锚框类别的损失和对于边界框偏移量的损失。前者使用交叉熵损失函数计算,后者使用L1损失函数。之所以不用L2损失,是因为很多锚框离边界框很远,平方之后数值会特别大。我们只关心几个比较好的锚框,那些离得远的锚框根本不care,所以也不需要MSE那样讲误差大的进行平方加权。
掩码变量bbox_masks令负类锚框和填充锚框不参与损失的计算。 最后,我们将锚框类别和偏移量的损失相加,以获得模型的最终损失函数。
cls_loss = nn.CrossEntropyLoss(reduction='none')
bbox_loss = nn.L1Loss(reduction='none')#L1损失函数。
#cls_preds, cls_labels表示锚框预测类别和真实边界框类别
#bbox_preds, bbox_labels是锚框偏移量和
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
#cls_preds.reshape是指每个锚框是一个样本,所以把batch_size*锚框个数
cls = cls_loss(cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)
#背景框bbox_masks=0不计算损失,其它类bbox_masks=1
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox#这里可以加权
由于偏移量使用了 L 1 L_1 L1范数损失,我们使用平均绝对误差来评价边界框的预测结果。这些预测结果是从生成的锚框及其预测偏移量中获得的。
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
4. 训练模型
d2l.multibox_target函数见上一篇文章《动手深度学习13——计算机视觉(数据增广、微调、锚框目标检测)》4.1.3
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
for epoch in range(num_epochs):
# 指标包括:训练精确度的和,训练精确度的和中的示例数,
# 绝对误差的和,绝对误差的和中的示例数
metric = d2l.Accumulator(4)
for features, target in train_iter:
timer.start()
X = features.as_in_ctx(device)
Y = target.as_in_ctx(device)
with autograd.record():
# 生成多尺度的锚框,为每个锚框预测类别和偏移量,这是预测值
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量.这是真实值
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors,
Y)
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.backward()
trainer.step(batch_size)
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.size,
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.size)
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter._dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
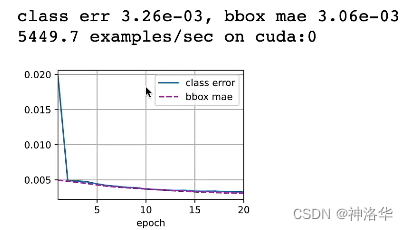
这里的逻辑是每个多尺度锚框经过net预测其类别和对真实边界框的偏移量,这是预测值。然后通过真实边界框,使用d2l.multibox_target函数标注锚框的真实类别和偏移量,这是真实值。二者的差距就是训练损失。
5. 模型预测
在预测阶段,我们希望能把图像里面所有我们感兴趣的目标检测出来。在下面,我们读取并调整测试图像的大小,然后将其转成卷积层需要的四维格式。
X = torchvision.io.read_image('../img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
使用下面的multibox_detection函数,我们可以根据锚框及其预测偏移量得到预测边界框。然后,通过非极大值抑制来移除相似的预测边界框。(还是见上一篇文章4.2.3)
def predict(X):
net.eval()
anchors, cls_preds, bbox_preds = net(X.to(device))
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
筛选所有置信度不低于0.9的边界框,做为最终输出
def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output.cpu(), threshold=0.9)
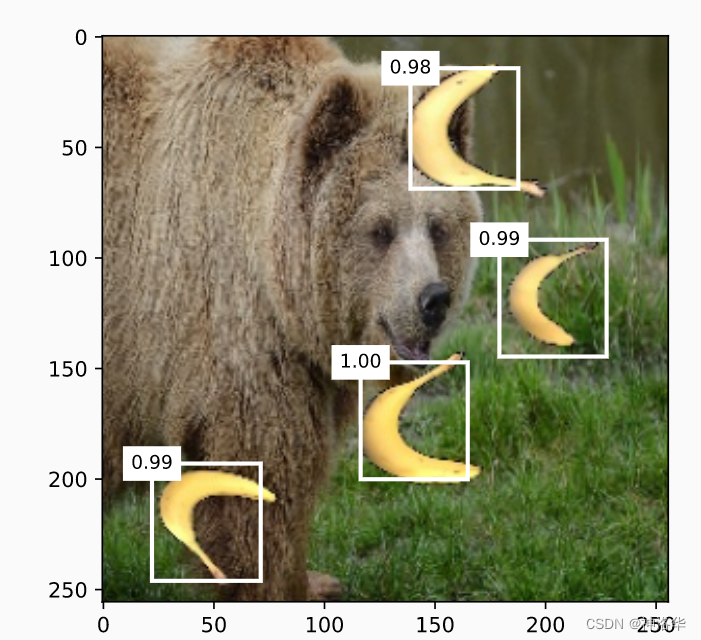
4.3.5 小结和讨论
- 对多尺度下锚框类别的预测和偏移量的预测,使用的是3×3卷积、padding=1的2d卷积神经网络来做的。这样卷积后特征图大小不变,这样就对每个像素都做预测。预测的值都在channel里面。channel数为(n+m-1)*(q+1)或者(n+m-1)*4。
- 网络输出不再是特征图,而是锚框、锚框预测的类别和偏移量。不同尺度下的预测结果做连结。
- 锚框的信息是在通过计算loss的进入神经网络。具体的,前向传播时锚框的类别预测,可以看整个图片的区域。算loss时告诉模型锚框对应通道位置预测应该是某个类,使得神经网络把注意力转到锚框位置。(网络可以看所有区域,但是算loss时目标区域很可能在这一块,尽量看这个地方)
- 预测时,channels是存每个像素的预测值。即使用类似《7.3 ⽹络中的⽹络(NiN)》卷积层的通道来输出类别预测的方法,而非用全连接来做预测。
- 输出类别个数是fmap_w*fmap_h*num_anchors*(num_classes+1)即wh*a(q+1)。这里没有num_inputs(输入通道数)是因为卷积时,输入通道已经变了。
讨论:
- 图片像素太高,比如1000×1000时锚框生成过多,SSD不适用。可以考虑Faster R-CNN里面的区域提议网络rpm降低锚框数。或者用YOLO这种,不管图片多大,锚框数都不会很多。
- 如果要识别电线杆这种细长物体,可以先把数据集真实的边界框拿出来做一下统计,统计出真实边界框的size和高宽比ratio。以此设计锚框的这两个超参数。
- for _ in range(2):这里下划线啥意思?
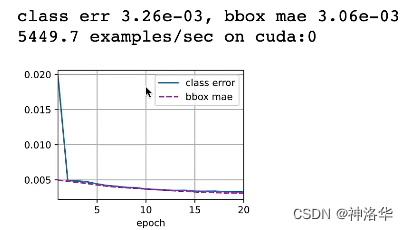
_表示这个变量我不要了 - 锚框预测的类别CrossEntropyLoss和偏移量的L1Loss是一个值域吗?直接相加会不会造成有一个loss起不到什么作用?
一个模型有两种loss相加时一般要进行加权(先打印出来看看值域)。而本章测试时两种loss差不多,所以直接相加(见下图)
五、YOLO (未完待续)
SSD中大量锚框重叠,浪费了很多计算。YOLO 将输入图像均匀地切割成 S x S 锚框,每个锚框预测B个边界框(一个锚框可能在多个边缘框里面或者相关)。




















 7329
7329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











