






VMD变分模态分解
VMD变分模态分解是一种在2014年由Konstantin等人提出的创新方法,它具备同时分解和提取模态的能力。与传统的分解方法不同,VMD将信号处理过程划分为非递归、基于变分理论的模态分解模式,这种处理方式显著增强了其面对复杂数据时的稳定性和适应性。
引入序列信号 ,然后对该序列进行不同频率的分解,每一个分量称为一个本征模函数(IMF)分量。
其理论如下所示:


具体步骤如下:

LSTM模型
全称为Long Short-Term Memory,LSTM模型对原油期货价格进行预测,在循环神经网络RNN基础上增加了遗忘门,和输出门、输入门这三个门就构成了“cell”这一重要的门户,其主要结构如下图所示。
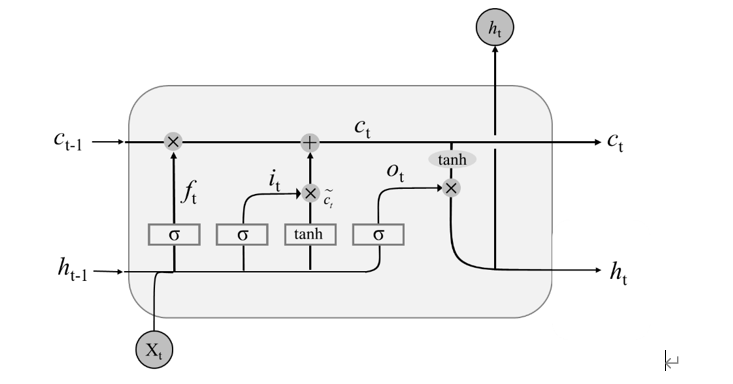
VMD-LSTM模型
先使用VMD变分模态分解模型对原油期货序列进行分解,然后用LSTM模型分别对每一个IMF序列拟合,最后将预测结果求和,建模流程如图所示:
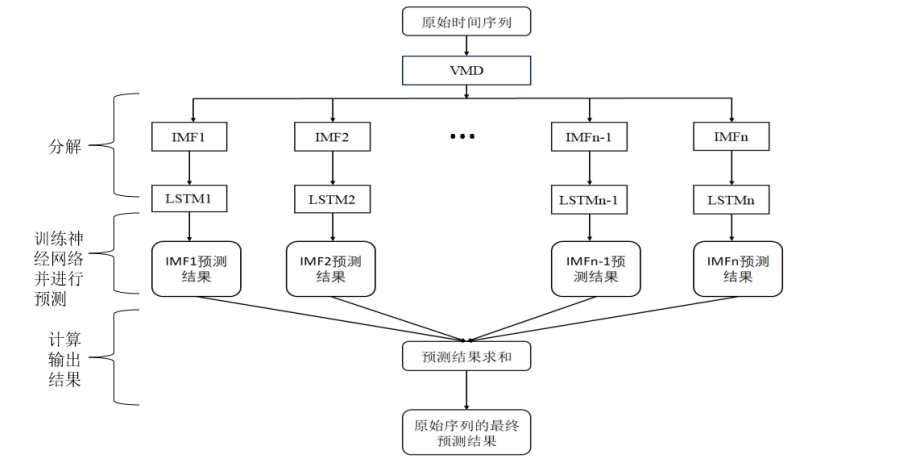
实例分析
选取了WTI原油期货价格数据,对其进行VMD-LSTM建模分析。
WTI原油不同K值对应模态下的中心频率如下所示:
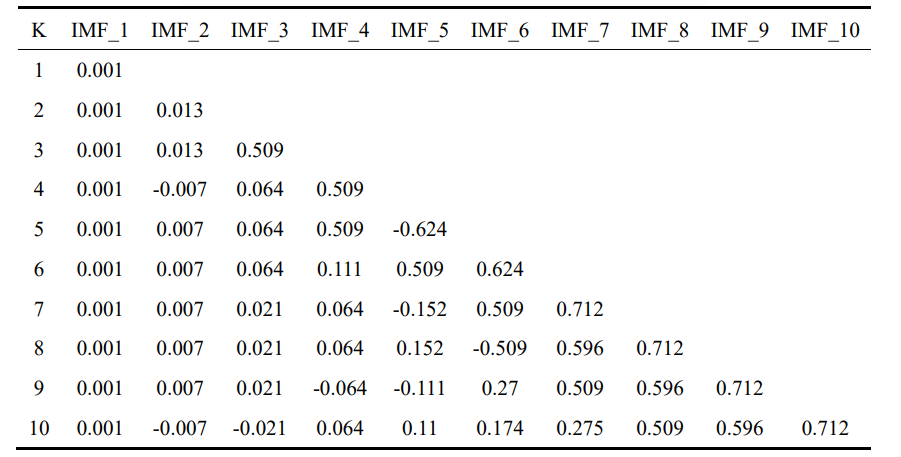
最大中心频率为0.712,于是把K定为7.
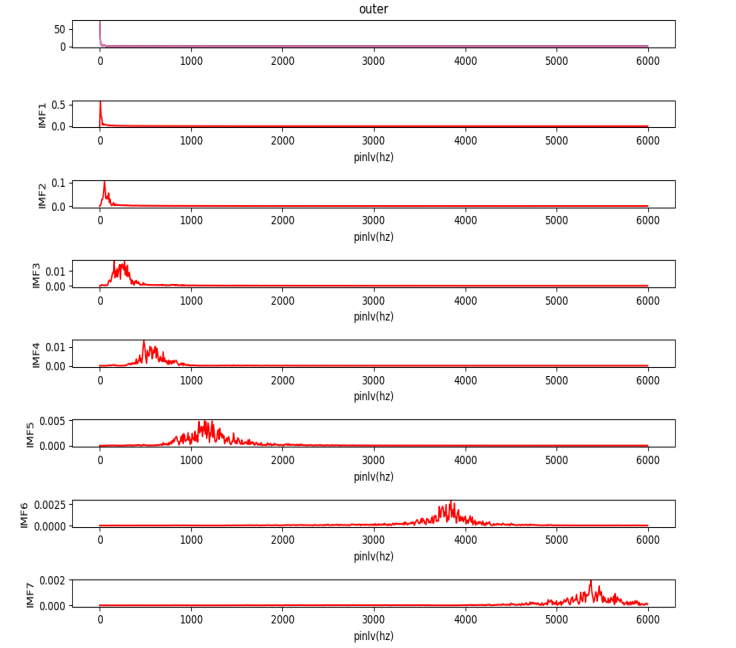
VMD分解结果图如下所示:
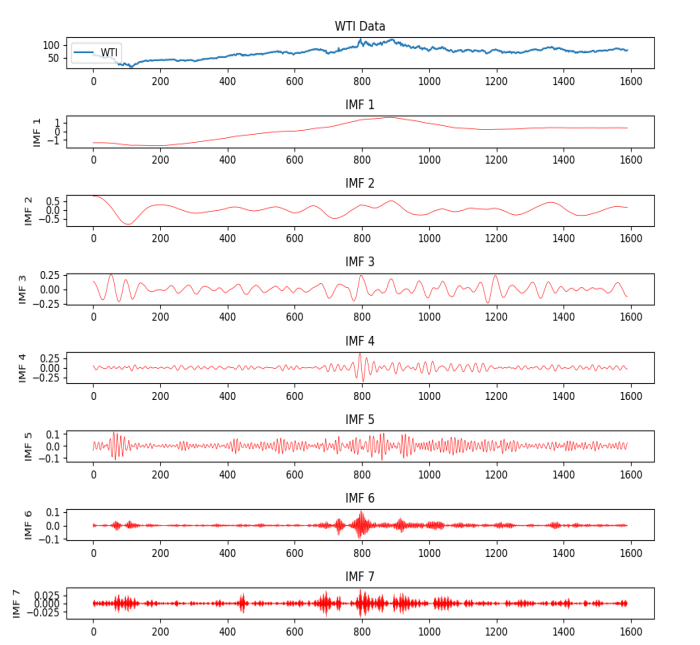
频谱图
LSTM运行结果:
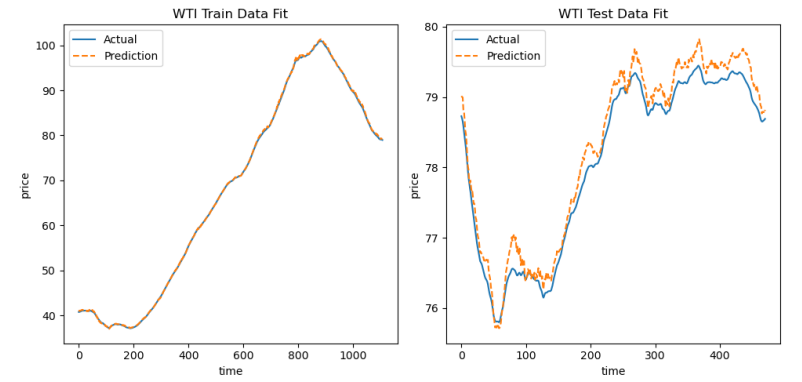
上图为分解后的序列,用LSTM模型在训练集和测试集上的拟合图,可见拟合效果较好。
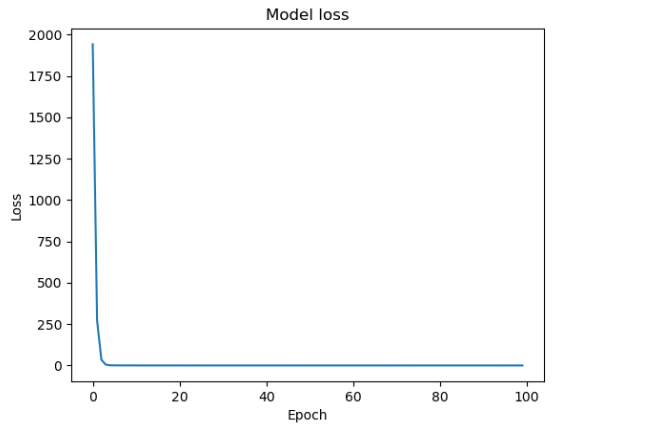
损失函数图如下所示:
评价指标:

完整代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
from vmdpy import VMD
# 定义VMD函数
def vmd_decomposition(data):
alpha = 2000
tau = 0.
K = 7
DC = 0
init = 1
tol = 1e-6
imfs, u_hat, omega = VMD(data, alpha, tau, K, DC, init, tol)
return imfs
data= pd.read_csv(r'D:\daily\data\插值后输出.csv')
data.set_index('date', inplace=True)
prices= data['WTI price'].values
# VMD分解
imfs = vmd_decomposition(prices)
features = np.column_stack([imf for imf in imfs])
# 划分训练集和测试集
train_size = int(len(features) * 0.7)
test_size = len(features) - train_size
train, test = features[0:train_size, :], features[train_size:len(features), :]
# 构造LSTM输入和输出数据
def create_dataset(dataset, look_back=5):
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), :]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 5
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 7))
testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 7))
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.layers import Input
timesteps = 5
features = 7
input_layer = Input(shape=(timesteps, features))
# 创建一个 Sequential 模型
model = Sequential([
input_layer,
LSTM(64),
Dense(1, activation='linear')
])
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history=model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
import matplotlib.pyplot as plt
# 绘制损失函数图
plt.plot(history.history['loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
# 绘制训练数据的拟合图
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(range(len(trainY)), trainY,label='Actual')
plt.plot(range(len(trainPredict)), trainPredict, linestyle='--', label='Prediction')
plt.title('WTI Train Data Fit')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(len(testY)), testY,label='Actual')
plt.plot(range(len(testPredict)), testPredict,linestyle='--',label='Prediction')
plt.title('WTI Test Data Fit')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.tight_layout()
plt.show()
#评价指标
from math import sqrt
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
mse=mean_squared_error(testY,testPredict)
print('均方误差mes:',mse)
rmse = sqrt(mse)
print("均方根误差 rmse:", rmse)
MAPE = mean_absolute_percentage_error(testY,testPredict)
print("平均绝对百分比误差 MAPE:", MAPE)
















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











