







目录
4.DeepSeek-R1-Lite系列:推理模型预览版上线
1.Deepseek-v1:起步与编码强劲
| 类别 | 详情 |
|---|---|
| 发布时间 | 2024年1月,字节跳动在火山引擎FORCE 2024原动力大会上发布DeepSeek - Coder 1.0 ,而DeepSeek系列大模型是由字节跳动研发,DeepSeek - V1通常指代DeepSeek Coder V1,是该系列专注代码生成的模型。 |
| 核心定位 | 专注代码生成的初始版本,预训练于2TB编程语言数据 |
| 技术亮点 | 支持Python、Java等主流编程语言;上下文窗口高达128K标记 |
| 优势 | 1. 代码生成质量高,符合语法规范 2. 长上下文理解能力强,适合复杂代码场景 |
| 局限性 | 1. 缺乏多模态支持 2. 复杂逻辑推理能力较弱 |
| 适用场景 | 开发者代码补全、自动化测试脚本生成、技术文档撰写 |
2. DeepSeek-V2:性能提升与开源生态
| 类别 | 详情 |
|---|---|
| 发布时间 | 2024年上半年 |
| 核心定位 | 高性能开源版本,参数规模2360亿,训练成本仅为GPT-4 Turbo的1% |
| 技术亮点 | 1. 完全开源且免费商用 2. 支持分布式训练与微调优化 |
| 性能提升 | 1. 语言理解能力提升40% 2. 代码生成错误率较V1降低35% |
| 优势 | 1. 显著降低AI应用开发门槛 2. 社区生态活跃,支持第三方插件扩展 |
| 局限性 | 1. 推理速度较慢(响应延迟约2-3秒) 2. 多模态任务仍受限 |
| 适用场景 | 科研机构模型研究、中小企业AI应用开发、教育领域代码教学 |
3.DeepSeek-V2.5系列:数学与网络搜索突破
发布时间:2024年9月
下面是官方对于V2.5版本的更新日志:
DeepSeek 一直专注于模型的改进和优化。在 6 月份,我们对 DeepSeek-V2-Chat 进行了重大升级,用 Coder V2的 Base 模型替换原有的 Chat 的 Base 模型,显著提升了其代码生成和推理能力,并发布了DeepSeek-V2-Chat-0628 版本。紧接着,DeepSeek-Coder-V2 在原有 Base模型的基础上,通过对齐优化,大大提升通用能力后推出了 DeepSeek-Coder-V2 0724 版本。最终,我们成功将 Chat 和Coder 两个模型合并,推出了全新的DeepSeek-V2.5 版本。
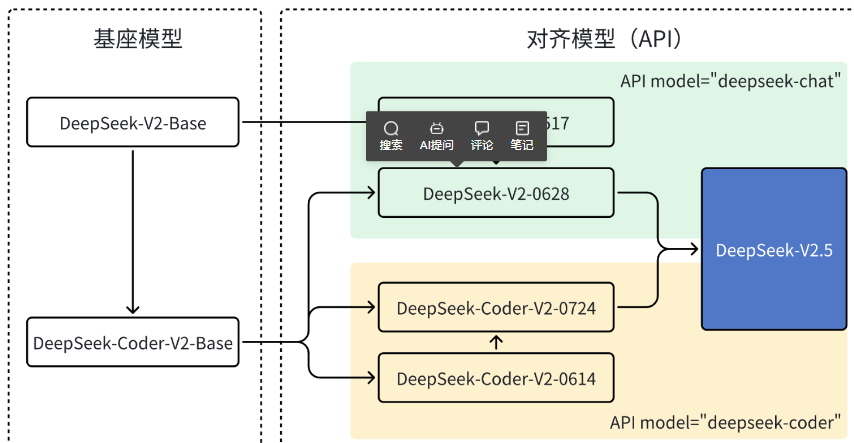
- Chat模型:专门为对话系统(聊天机器人)设计和优化,用于生成自然语言对话,能够理解上下文并生成连贯且有意义的回复,常见应用如聊天机器人、智能助手等。
- Coder模型:是一种基于深度学习技术,经过大量代码数据训练,能够理解、生成和处理代码的人工智能模型。
并且从官方发布的数据来看,V2.5在通用能力(创作、问答等)等问题中表现对比V2模型来说,有了显著得提升。
特点:
DeepSeek-V2.5在前一个版本的基础上进行了一些关键性改进,尤其是在数学推理和写作领域,表现得更加优异。同时,该版本加入了联网搜索功能,能够实时分析海量网页信息,增强了模型的实时性和数据丰富度。
优势:
- 数学和写作能力提升:在复杂的数学问题和创作写作方面,DeepSeek-V2.5表现优异,能够辅助开发者处理更高难度的任务。
- 联网搜索功能:通过联网,模型可以抓取最新的网页信息,对当前互联网资源进行分析和理解,提升模型的实时性和信息广度。
4.DeepSeek-R1-Lite系列:推理模型预览版上线
| 特点/表现 | 描述 |
|---|---|
| 模型名称 | DeepSeek-R1-Lite |
| 训练方法 | 强化学习 |
| 推理能力 | 包含大量反思和验证,思维链长度可达数万字 |
| 主要应用领域 | 数学、编程、复杂逻辑推理 |
| 性能亮点 | 在美国数学竞赛(AMC)AIME测试中表现优异 |
| 在全球顶级编程竞赛(Codeforces)中超越GPT-4等模型 | |
| 发布意义 | 标志着DeepSeek在AI领域的重大突破,为用户提供新的选择 |
5. DeepSeek-V3系列:大规模模型与推理速度提升
发布时间:
2024年12月26日
作为深度求索公司自主研发的首款混合专家(MoE)模型,其拥有6710亿参数,激活370亿,在14.8万亿token上完成了预训练。
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
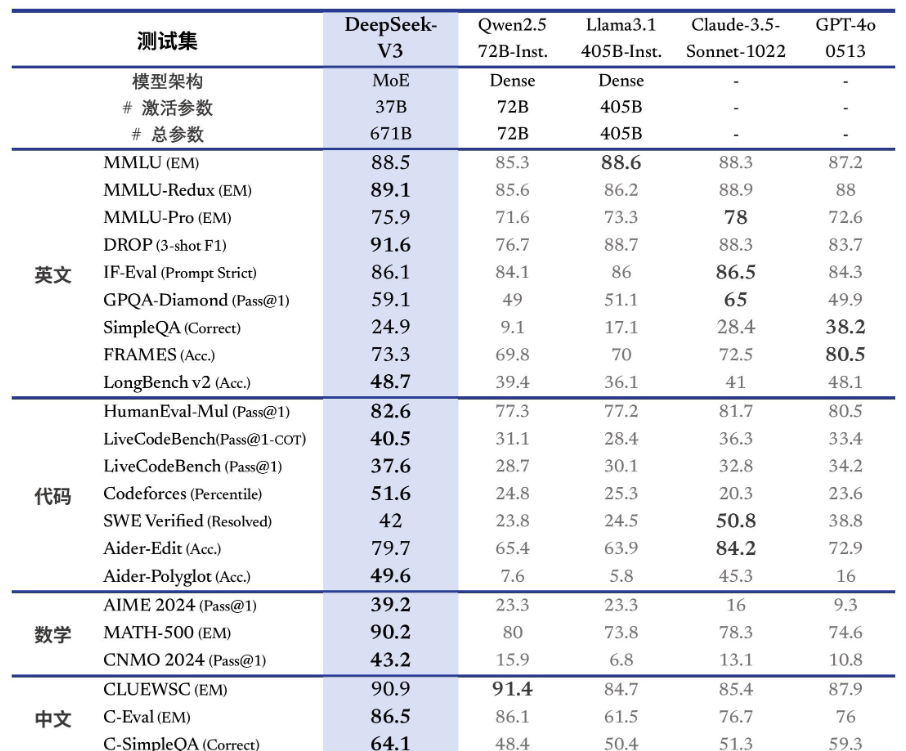
模型架构与参数
- DeepSeek - V3:采用MoE架构,激活参数37B,总参数671B。
- Qwen2.5 - 72B - Inst:Dense架构,激活参数72B,总参数72B。
- Llama3.1 - 405B - Inst:Dense架构,激活参数405B,总参数405B。
| 特性类别 | 描述 |
|---|---|
| 优势 | |
| - 强大的推理能力 | 凭借6710亿参数,在知识推理和数学任务方面展现出卓越表现 |
| - 高生成速度 | 每秒生成60个字符(TPS),满足高速响应需求 |
| - 本地部署支持 | 通过FP8权重的开源,支持本地部署,降低云服务依赖,提升数据隐私性 |
| 缺点 | |
| - 高训练资源需求 | 需要大量GPU资源进行训练,导致部署和训练成本较高 |
| - 多模态能力不强 | 在多模态任务(如图像理解)方面未专门优化,存在短板 |
6.DeepSeek-R1系列:强化学习与科研应用
发布时间: 2025年1月20日
作为一经发布就备受瞩目的DeepSeek-R1来说,真正的是经历了很多磨难才诞生走到现在,而DeepSeek-R1发布以来就秉持这开源的原则,遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
- 模型轻量化:蒸馏技术可以将大型的DeepSeek - R1模型的知识迁移到小型模型上。开发者能够训练出更轻量级、运行效率更高的模型,比如在资源受限的设备(如移动设备、嵌入式设备等)上部署模型,以实现实时的推理和应用,而无需依赖强大的计算资源来运行大型的DeepSeek - R1原模型。
- 个性化定制:用户可以根据自身特定的任务需求,比如特定领域的文本分类、特定类型的图像识别等,以DeepSeek - R1为基础,通过蒸馏训练出更适配该任务的模型,从而在性能和资源消耗之间取得更好的平衡,提升模型在特定场景下的表现。
- 促进技术创新:这种方式为研究人员和开发者提供了一个强大的工具和起点,鼓励更多人基于DeepSeek - R1进行探索和创新,加速人工智能技术在各个领域的应用和发展,推动整个行业的技术进步。
并且DeepSeek-R1 上线 API,对用户开放思维链输出,通过设置 model=‘deepseek-reasoner’ 即可调用,这无疑极大的方便了很多对于大模型感兴趣的个体用户。
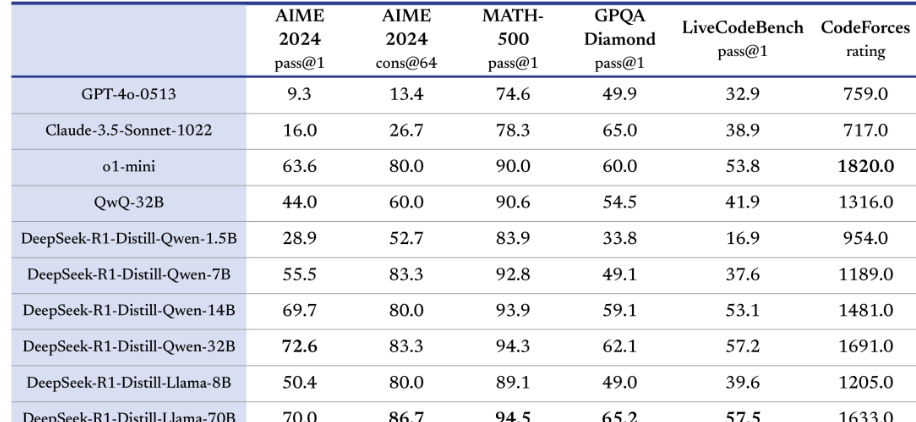
deepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。


















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











