







本篇博文以一篇综述为例,讲述什么叫联邦学习!!
《Federated Machine Learning:Concept and Applications》:https://arxiv.org/pdf/1902.04885v1.pdf
该篇综述是杨强教授在2019年发表在ACM Transactions on Intelligent Systems and Technology (TIST)上的一篇综述论文,比较全面和系统的介绍了联邦学习的基本概念、分类和一些安全隐私问题等。
目录
摘要
背景:如今人工智能仍然存在两个重大挑战:
- 数据以孤岛的形式存在;
- 数据隐私和安全问题。
引出:本文提出了可能的解决方案:一个更全面的安全联邦学习框架。该框架包括Horizontal(水平or横向)联邦学习、Vertical(垂直or纵向)联邦学习,以及联邦Transfer(迁移)学习。本文提供了联邦学习框架的定义、架构和应用程序,以及建立了基于联邦机制的组织之间建立数据网络,作为一种可以在不损害用户隐私的情况下共享知识(知识指参数、梯度等 )的有效解决方案。
1.引言
大数据能驱动人工智能快速实现我们生活的各个方面,但现实世界的情况有些令人失望。除了少数行业,大多数领域只有有限的数据或劣质数据,使得人工智能技术的实现比我们想象中更困难。通过跨组织传输数据,是否能将数据融合到一个公共站点中?事实上,在许多情况下,打破数据源之间的障碍是非常困难的,甚至是不可能的。在大多数行业中,数据以古岛的 形式存在。由于行业竞争、隐私安全和复杂的管理程序,即使同一个公司不同部门之间的数据整合也面临巨大压力。将分散在全国各地和机构的数据整合起来几乎是不可能的。
同时,大公司对数据安全和用户隐私妥协的意识日益增强,对数据隐私和安全的重视已经成为世界范围内的重大问题。公共数据泄露消息如,最近facebook的数据泄露引起了广泛的抗议 [70] 。作为回应,世界各国都在加强保护数据安全和隐私的法律。
- 中国在17年颁布了《网络安全法》和《民法通则》要求互联网企业不得泄露或篡改其收集的个人信息,在与第三方进行数据交易时,需确保协议的合同遵守法律数据保护义务。
- 2018年,欧盟实施了通用数据保护条例(GDPR) [19] ,它要求保护用户的个人隐私和数据安全,并给予用户的“被遗忘权”,即用户可以删除或撤回个人数据。
具体来说,人工智能中的传统数据处理模型往往涉及简单的数据交易模型,一方收集数据并将数据传输给另一方,另一方负责清理和融合数据。最后,第三方将获取集成数据并构建模型供其他方使用。模型通常是作为服务出售的最终产品。这种传统程序面临上述新数据法规和法律的挑战。因此,我们面临的困境是,数据是孤岛形式,但在多种情况下,我们被禁止收集、融合使用数据到不同的地方进行AI处理。如何合法解决数据碎片化的隔离问题,是当今人工智能研究人员和从业者面临的一大挑战。
2.联邦学习概述(重点章节)
2016年,联邦学习的概念由谷歌提出,其主要思想是基于分布在多个设备上的数据集构建机器学习模型,同时防止数据泄露。此外,数据按用户ID或设备ID的数据空间中是水平区分的。为扩展联邦学习概念以覆盖组织之间的协作学习场景,我们将原“联邦学习”扩展到所有保护隐私的分散式协作机器学习技术的一般概念。在本节中,提供了一个更全面的联邦学习定义,它考虑了数据分区、安全性和应用程序,还描述了联邦学习系统的工作流程和系统架构。
2.1.联邦学习定义
定义N个数据拥有者{ F 1 , . . . , F N }他们希望通过合并各自的数据{ D 1 , . . . , D N } 来训练机器学习模型。传统的方法是将所有数据放在一起并使用D = D 1 ∪ D 2 . . . D N 训练模型 。联邦学习系统是数据拥有者协同训练模型
的一个学习过程,该过程中任何数据拥有者F i 都不会暴露其数据D i 给其他人。另外
的精度值表示为
,应该非常接近
的精度值
。形式上,δ是一个非负实数,如果满足
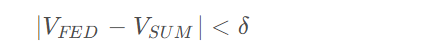
我们说联邦学习算法是δ \精度值损失。
2.2.联邦学习隐私
隐私=是联邦学习的基本属性之一,这需要安全模型和分析来提供有意义的隐私保证。在本节中,我们简要回顾和比较联邦学习的不同隐私技术,并确定防止间接泄露的方法和潜在挑战。
- 安全多方计算(SMC):安全模型涉及多方,并在定义良好的模型框架中提供证明,以确保完全零知识,即每一方除了输入和输出之外一无所知。零知识是非常可取的,但是这种期望的特性通常需要复杂的计算协议并且可能无法有效实现。在某些情况下,如果提供安全保证,部分知识披露可能被认为是可以接受的。可以在较低的安全要求下使用SMC构建安全模型以换取效率 [16] 。最近,研究 [46] 使用SMC框架来训练具有两个服务器和半城实假设的机器学习模型。参考文献 [33] 使用MPC协议进行模型训练和验证,而无需用户透露敏感数据。Sharemind [8] 是最先进的SMC框架之一。文献 [44] 提供了一个具有诚实多方的3-PC模型[5,21,45] ,并在半城实和恶意假设中考虑安全性。这些工作要求参与者的数据在非共谋服务器之间秘密共享。
- 差分隐私:另一种工作使用差分隐私 [18] 或k-匿名 [63] 技术来保护数据隐私 [1,12,42,61]。差分隐私、k-匿名和多样化 [3] 的方法涉及在数据中加入噪声,或使用泛化方法来掩盖某些敏感属性,直到第三方无法区分个体,从而使数据无法恢复到保护用户隐私。但是,这些方法的根源仍然要求将数据传输到其他地方,并这些工作通常涉及准确性和隐私之间的权衡。在 [23] 中,作者为联邦学习引入了一种差分隐私方法,以便通过在训练期间隐藏客户端的贡献来增强对客户端数据的保护。
- 同态加密:机器学习过程中还采用同态加密 [53] ,通过加密机制下的参数交换来保护用户数据隐私 [24,26,48] 。与差分隐私保护不同,数据和模型本身不会传输,也不会被对方的数据猜到。因此,在原始数据层面泄露的可能性很小。最近的工作采用同态加密来集中和训练云上的数据[75,76] 。在实践中,加法同态加密 [2] 广泛使用,并且需要进行多项式近似来评估机器学习算法中的非线性函数,从而导致准确性和隐私性之间的权衡[4,35]。
2.2.1.间接信息泄露
先前联邦学习的工作暴露了中间结果, 例如来自优化算法,如随机梯度下降(SGD) [41,58]的参数更新,但没有提供安全保证,当这些梯度与数据结构(如像素图)一起暴露时,实际上可能会泄漏重要的数据信息 [51] 。研究人员考虑了一种情况,即联邦学习系统的一个成员通过允许插入后门来学习他人数据,从而恶意攻击他人。在 [6] 中,作者证明了在联合全局模型中插入隐藏后门是可能的,并提出了一种新的“约束-规模”模型中毒方法来减少数据中毒。在 [43] 中,研究人员发现了协作机器学习系统中潜在的漏洞,即协作学习中各方使用的训练数据很容易受到推理攻击。他们表明,敌对的参与者可以推断出成员以及与训练数据子集相关的属性。他们还讨论了可能的防御措施。在 [62] 中,作者暴露了一个潜在的安全问题,与不同方之间的梯度交换有关,并提出了梯度下降方法的一个安全变体,并表明它可以容忍恒定分数的拜占庭工人。
研究人员也开始将区块链视为促进联邦学习的平台。在 [34] 中,研究人员考虑了一种区块链联邦学习(BlockFL)架构,其中移动设备的本地学习模型更新通过利用区块链进行交换和验证。他们考虑了最佳区块生成、网络可扩展性和健壮性问题。
2.3.联邦学习分类
令矩阵D i 表示每个数据拥有者i ii持有的数据。矩阵的每行代表一个样本,每列代表一个特征。同时,一些数据集也可能包含标签数据,我们将特征空间表示为X ,标签空间表示为Y ,使用I 表示样本ID空间。例如,在金融领域标签可能是用户的信用;在营销领域的标签可能是用户的购买欲望;在教育领域,Y 能是学生的学位。特征X ,标签Y 和样本ID I构成了完整的训练数据集( I , X , Y ) 。数据方的特征和样本空间可能不完全相同,我们根据数据在特征和样本ID空间中在各方之间的分布情况,将联邦学习分为水平联邦学习、垂直联邦学习和联邦迁移学习。
- 1、水平(横向)联邦学习:即基于样本的联邦学习,旨在数据集共享相同特征空间但样本不同的场景。例如,两个区域的银行可能各自区域的用户群非常不同,且用户交集非常小。但是,他们的业务非常相似,因此特征空间是相同的。文献 [58] 提出了一种协作深度学习方案,参与者独立训练,并仅共享参数更新的子集。本文还介绍了一种在联邦学习框架下保护聚合用户更新隐私的安全聚合方案 [9] 。文献 [51] 使用加法同态加密进行模型参数聚合,以提供针对中央服务器的安全性。
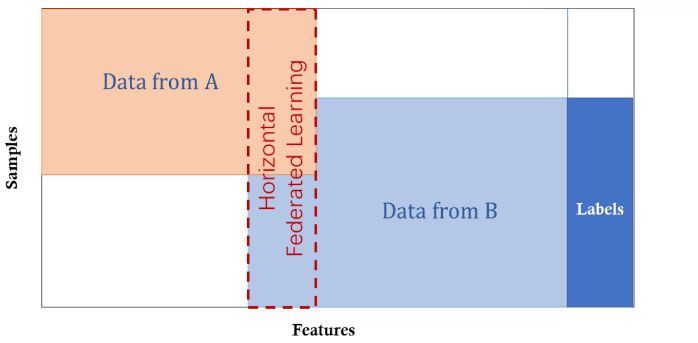
在 [60] 中,提出了一种多任务式的联邦学习系统,允许多个站点在共享知识和保证安全的同时完成各自的任务。他们提出的多任务学习模型还可以解决高通信成本、掉队和容错问题。在 [41] 中,作者提出建立一个安全的客户机-服务器结构,其中联邦学习系统根据用户划分数据,并允许在客户机设备上构建的模型在服务器站点上协作,以构建一个全局联邦模型,过程确保了数据不泄露。同样,在 [36] 中,作者提出了提高通信成本的方法,以促进基于分布在移动客户端数据的集中模型的训练。最近,一种被称为深度梯度压缩 [39] 的压缩方法被提出,以大大降低大规模分布式训练的通信带宽。即总结为:
![]()
安全定义:水平联邦学习系统通常假设参与者是诚实的,并对诚实且好奇的服务器是安全的 [9, 51] 。也就是说,只有服务器可以破坏(损害)数据参与者的隐私。这些工程都提供了安全证明。最近,另一种考虑恶意用户 [29] 的安全模型也被提出,带来了额外的隐私挑战。在训练结束时,通用模型和整个模型参数暴露给所有参与者。
- 2、垂直(纵向)联邦学习:针对垂直分割的数据提出了保护隐私的机器学习算法,包括合作统计分析 [15] 、关联规则挖掘 [65] 、安全线性回归 [22, 32, 55] 、分类 [16] 和梯度下降 [68] 。最近,文献 [27, 49] 提出了一种垂直联邦学习方案来训练一个隐私保护的logistic回归模型。研究了实体分辨率对学习性能的影响,并将泰勒近似应用于损失函数和梯度函数,以便可以采用同态加密进行隐私保护计算。
垂直联邦学习适用于两个数据集共享相同样本ID空间,但特征空间不同的情况。例如,同城有一家银行,另一家电子商务公司,他们的用户集可能包含该地区的大多数居民,因此他们的用户空间交集很大。但是, 由于银行记录了用户的收支行为和信用评级,而电子商务保留了用户的浏览和购买历史,所以他们的特征空间有很大不同。
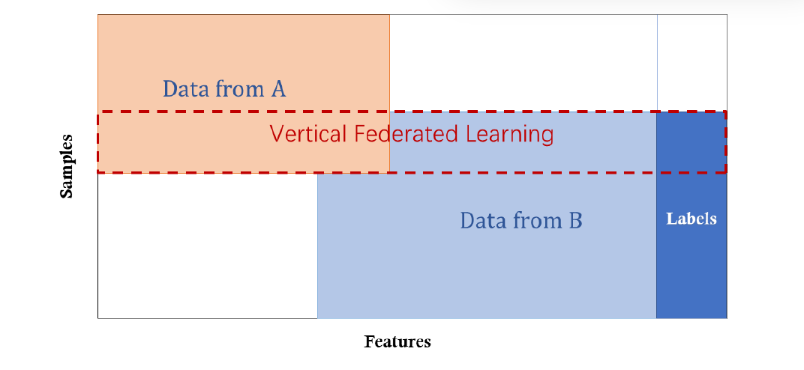
垂直联邦学习是将这些不同的特征聚合在一起,并以保护隐私的方式计算训练损失和梯度,共同利用双方的数据建立模型的过程。因此,在这个体系中,我们有:
![]()
安全定义:垂直联邦学习系统通常假设参与方诚实且好奇。例如,在两方不串通的情况下,最多其中一方收到对手的损害。安全定义是,攻击者只能从它损坏的客户端学习数据,而不能从其他客户端学习超出输入和输出揭示的数据。我们在学习结束时,每一方只持有与自己特征相关的模型参数,因此在推理时,两方也需要协作生成输出。
- 3、联邦迁移学习 :适用于两个数据集不仅样本不同,而且特征空间也不同的情况。考虑两家机构,一家中国的银行,另一家美国的电子商务公司。由于地域限制,两个机构的用户有很小的交集。另一方面,由于业务不同,双方的特征空间只有小部分重叠。在这种情况下,可以用联邦迁移学习 [50] 技术为联邦学习的整个样本和特征空间提供解决方案。特别地,使用有限的公共样本集学习两个特征空间之间的共同表示,然后将其用于获得只有单边特征的样本的预测。因此,它处理的问题超出了现有联邦学习算法的范围
安全定义:一个联邦迁移学习系统通常涉及双方。
2.4.联邦学习的框架
一般水平和垂直联邦学习系统的架构在设计上有很大区别。
2.4.1.水平联邦学习
如图,在该系统中,k个具有相同数据结构的参与者通过参数或云服务器协作学习机器学习模型。假设参与者是诚实的,而服务器是诚实但好奇的,因此不允许任何参与者向服务器泄露信息。有以下四个步骤:
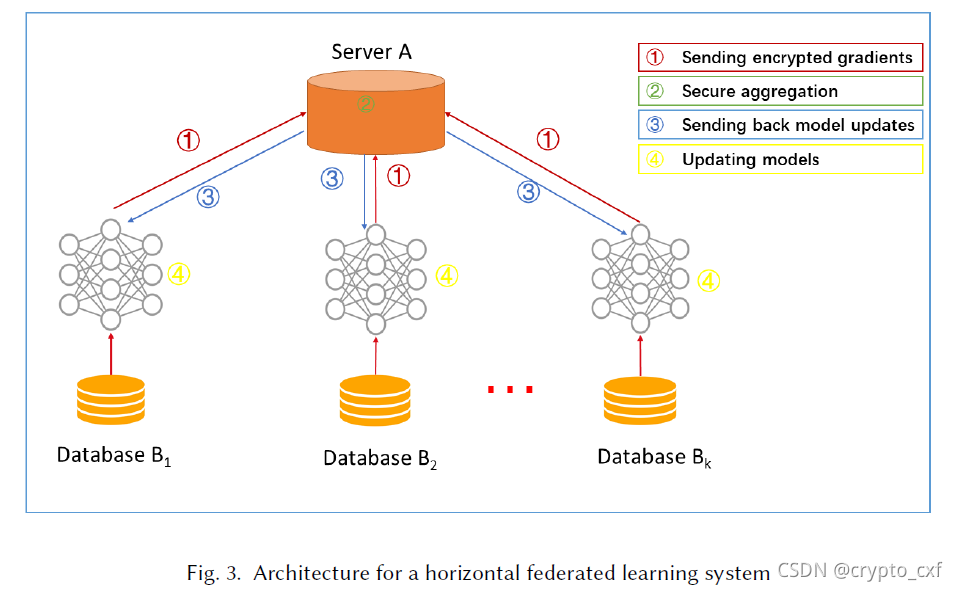
- Step 1:参与者本地计算训练梯度,使用加密、差分隐私或秘密共享技术对梯度选择进行掩码,并将掩码结果发送给服务器;
- Step 2:服务器在不了解任何参与者信息的情况下执行安全聚合;
- Step 3:服务器将聚合的结果反馈给参与者;
- Step 4:参与者用解密的梯度更新他们各自的模型。
通过以上不断的迭代,直到损失函数收敛,完成整个训练过程。
安全分析:使用SMC [9] 或同态加密 [51] 进行梯度聚合的情况下,证明了上述体系结构可以防止半城实服务器的数据泄露。但是它可能会受到恶意参与者在协作学习过程中训练生成对抗网络(GAN)的另一种安全模型的攻击 [29] 。
2.4.2.垂直联邦学习
假设公司A和B想联合训练一个机器学习模型,他们的业务系统都有自己的数据。此外,公司B也有模型需要预测的标签数据。出于数据隐私和安全的考虑,A和B不能直接交换数据。为了确保训练过程中数据的保密性,引入了第三方合作者C。在这里假设C是诚实的,但A和B是诚实但好奇的。
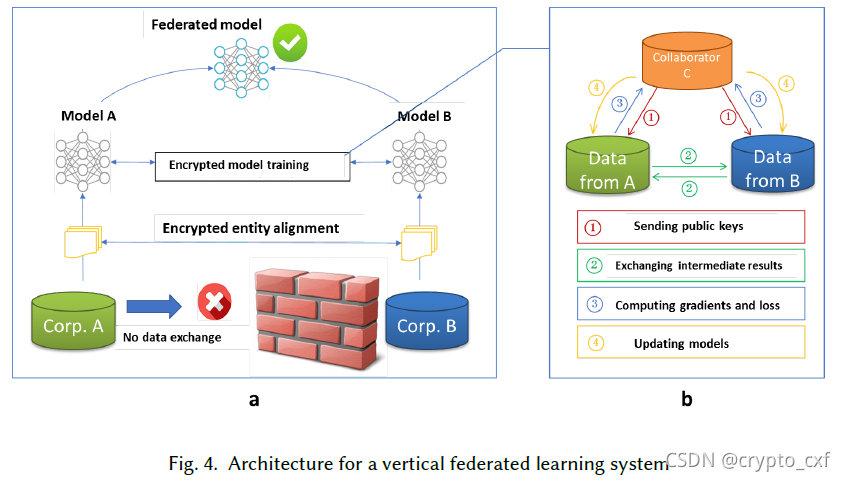
Part 1. 加密实体对齐。由于他们的用户组不同,系统使用基于加密的用户ID对齐技术 [38,56] 来确认双方的普通用户,而不需要A和B暴露各自的数据。在实体对齐期间,系统不会公开彼此没有重叠的用户。
Part 2. 加密模型训练。确定公共实体后,可以使用公共实体的数据来训练机器学习模型。
Step 1:协作者C创建加密对,向A和B发送公钥;
Step 2:A和B加密并交换梯度和损耗计算的中间结果;
Step 3:A和B分别计算加密梯度和添加额外掩码,B还计算加密损失,A和B向C发送加密的值;
Step 4:C解密并将解密后的梯度和损耗发送回A和B;A和B获取梯度,更新相应的模型参数。


垂直联邦学习的训练步骤:线性回归
| Step | Party A | Party B | Party C |
|---|---|---|---|
| Step 1 | 初始化ΘA | 初始化ΘB | 创建加密密钥对,向A和B发送公钥 |
| Step 2 | 计算[[uik]], [[L]],并发送给B | 计算[[uik]], [[dBi]], [[L]],发送[[dBi]]给A,发送[[L]]给C | |
| Step 3 | 初始化RA,计算[[∇θA]] + [[RA]]并发送给C | 初始化RB,计算[[∇θB]] + [[RB]]并发送给C | C解密L,发送∇θA + RA给A,发送∇θB + RB给B |
| Step 4 | 更新ΘA | 更新ΘB | |
| 获得了什么? | ΘA | ΘB |
垂直联邦学习的评估步骤:线性回归
| 步骤 | Party A 操作 | Party B 操作 | Party C 操作 |
|---|---|---|---|
| Step 0 | 接收用户ID | 接收用户ID | 发送用户ID给Party A和Party B |
| Step 1 | 计算并发送 | 计算并发送 | 接收 |
如上面两个表,在实体对齐和模型训练过程中,A和B的数据保存在本地,训练中的数据交互不会导致数据隐私泄露。为了防止C从A或B哪里学习到信息,A和B可以通过添加加密的随机掩码对C进一步隐藏他们的梯度。因此,双方在联邦学习的帮助下合作实现了通用的训练模型。因为在训练过程中,每方接收到的损失和梯度与他们在没有隐私约束的情况下,用在一个地方收集的数据共同构建模型时所接收到的损失和梯度完全相同,即该模型是无损的。每次迭代中,A和B之间发送的信息以重叠样本的数量为尺度。因此,采用分布式并行计算技术可以进一步提高算法的效率。
安全分析:在训练阶段没有透露任何信息给C,因为C学习的都是掩码梯度,并且掩码矩阵的随机性和保密性得到保证 [16] 。在上面协议中,A方每一步都学习它的梯度,但这不足以让A从B学习任何信息,因为标量乘积协议的安全性是基于无法解决n多于n个未知数的方程 [16, 65] 。这里假设样本数N A远大于n A ,其中n A 是特征数。同样,B方无法从A哪里获取任何信息,因此证明了协议的安全性。注意,这里假设双方都是半城实的。若一方是恶意的,通过伪造输入来欺骗系统。
2.4.3 联邦迁移学习
假设上面垂直联邦学习示例中,A方和B方只有非常小的重叠样本集,我们感兴趣学习A方所有数据集的标签。上一节中描述的架构到目前为止仅有效对于重叠数据集。为了将其覆盖范围扩展到整个样本空间,引入迁移学习。具体而言,迁移学习通常涉及到学习一方A和一方B的特征之间的共同表示,并通过利用源域一方的标签来最大限度地减少预测目标域一方标签的错误。因此,A方和B方的梯度计算与垂直联邦学习场景中的梯度计算不同。在推理时,仍然需要双方计算预测结果。
3.相关工作
3.1 隐私保护机器学习
联邦学习可以看作是一种隐私保护的去中心化协作机器学习,因此它与多方隐私保护机器学习有着密切的关系。(后面作者介绍了许多相关的方案,详细内容见文章3.1节,内容比较多)
3.2 联邦学习vs分布式机器学习
水平联邦学习乍一看有点类似分布式机器学习。分布式机器学习覆盖了很多方面,包括训练数据的分布式存储、计算任务的分布式操作、模型结果的分布式分布等。对于水平联邦学习,工作节点表示数据所有者。它对本地数据有完全的自主权,可以决定何时以及如何加入联邦学习。在参数服务器中,中心节点始终处于控制状态,因此联邦学习面临着更加复杂的学习环境。其次,联邦学习强调模型训练过程中数据所有者的数据隐私保护。有效的数据隐私保护措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
3.3 联邦学习vs边缘计算
联邦学习可以看作是边缘计算的操作系统,因为它提供了协调和安全的学习协议。在 [69] 中,作者考虑了使用基于梯度下降方法训练的一般机器学习模型。从理论角度分析了分布式梯度下降算法的收敛界,并在此基础上提出了一种控制算法,该算法在给定资源预算的情况下,在局部更新和全局参数聚合之间进行最优权衡,使损失函数最小化。
3.4 联邦学习vs联邦数据库系统
联邦数据库系统 [57] 是集成多个数据库单元并将集成系统作为一个整体进行管理的系统。为了实现与多个独立数据库的互操作,提出了联邦数据库的概念。联邦数据库系统通常对数据库单元使用分布式存储,而实际上每个数据库单元中的数据是异构的。
因此,它在数据的类型和存储方面与联邦学习有很多相似之处。但是,联邦数据库系统在相互交互的过程中不涉及任何隐私保护机制,所有数据库单元对管理系统是完全可见的。此外,联邦数据库系统的重点是数据的插入、删除、搜索、合并等基本操作,而联邦学习的目的是在保护数据隐私的前提下,为每个数据所有者建立一个联合模型。
4.应用场景
作为一种创新的建模机制,可以在不损害数据隐私和安全的情况下,对来自多个方面的数据进行统一模型的训练,联邦学习在销售、金融和许多其他行业具有广阔的应用前景。
以智能零售为例。其目的是利用机器学习技术为客户提供个性化服务,主要包括产品推荐和销售服务。对于数据隐私和数据安全的保护,银行、社交网站和电子购物网站之间的数据壁垒很难突破。联邦学习为我们构建跨企业、跨数据、跨领域的大数据和人工智能生态圈提供了良好的技术支持。
可以使用联合学习框架进行多方数据库查询,而不暴露数据。具体来说,我们可以利用联邦学习的加密机制,对双方的用户列表进行加密,然后将加密列表在联邦中进行交集。最终结果的解密将给出多方借款者的列表,而不会将其他“优秀”用户暴露给另一方。
智能医疗是另一个将从联合学习技术的崛起中受益匪浅的领域。疾病症状、基因序列、医疗报告等医疗数据非常敏感和私密,但医疗数据难以收集,存在于孤立的医疗中心和医院。联合学习与迁移学习相结合是实现这一目标的主要途径。迁移学习可以用来填补缺失的标签,从而扩大可用数据的规模,进一步提高训练模型的性能。因此,联邦迁移学习将在智能医疗的发展中发挥关键作用,并可能将人类医疗提升到一个全新的水平。
5.代码实现
以下是一个简化的联邦学习示例,使用Python和PyTorch框架模拟联邦学习的训练过程。为了简化,我们假设有两个参与方(Client 1 和 Client 2),它们各自拥有不同的数据集,并希望共同训练一个线性回归模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class LinearModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearModel, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
return self.fc(x)
# 初始化模型参数
input_dim = 10
output_dim = 1
model_client1 = LinearModel(input_dim, output_dim)
model_client2 = LinearModel(input_dim, output_dim)
# 假设的本地数据集和标签(实际中应使用真实数据)
x_client1 = torch.randn(100, input_dim)
y_client1 = torch.randn(100, output_dim)
x_client2 = torch.randn(100, input_dim)
y_client2 = torch.randn(100, output_dim)
# 本地训练(简化示例,实际中可能更复杂)
optimizer_client1 = optim.SGD(model_client1.parameters(), lr=0.01)
optimizer_client2 = optim.SGD(model_client2.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 本地训练迭代(仅示例)
for epoch in range(10):
optimizer_client1.zero_grad()
pred_client1 = model_client1(x_client1)
loss_client1 = criterion(pred_client1, y_client1)
loss_client1.backward()
optimizer_client1.step()
optimizer_client2.zero_grad()
pred_client2 = model_client2(x_client2)
loss_client2 = criterion(pred_client2, y_client2)
loss_client2.backward()
optimizer_client2.step()
# 假设的模型参数聚合(实际中可能更复杂,如使用加权平均等)
# 这里简单地将两个模型的参数相加后平均
w_avg = (model_client1.fc.weight + model_client2.fc.weight) / 2
b_avg = (model_client1.fc.bias + model_client2.fc.bias) / 2
# 更新模型参数(实际应用中可能需要更复杂的同步机制)
model_client1.fc.weight = nn.Parameter(w_avg)


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











