










利用arima函数 对平稳序列拟合自回归模型AR,移动平均模型MA,自回归移动平均模型ARMA。按照如下步骤:
- 模型识别(定阶)
- 参数估计
- 模型检验
- 模型优化
- 预测
例 选择合适的模型拟合1950-2008我国邮路及农村投递线路每年新增里程序列
- 模型识别
首先,读取数据,绘制时序图,并做纯随机性检验
a<-read.table("E:/R/data/file8.csv",sep=",",header = T)
x<-ts(a$kilometer,start = 1950)
plot(x)
for(i in 1:2) print(Box.test(x,type = "Ljung-Box",lag=6*i))
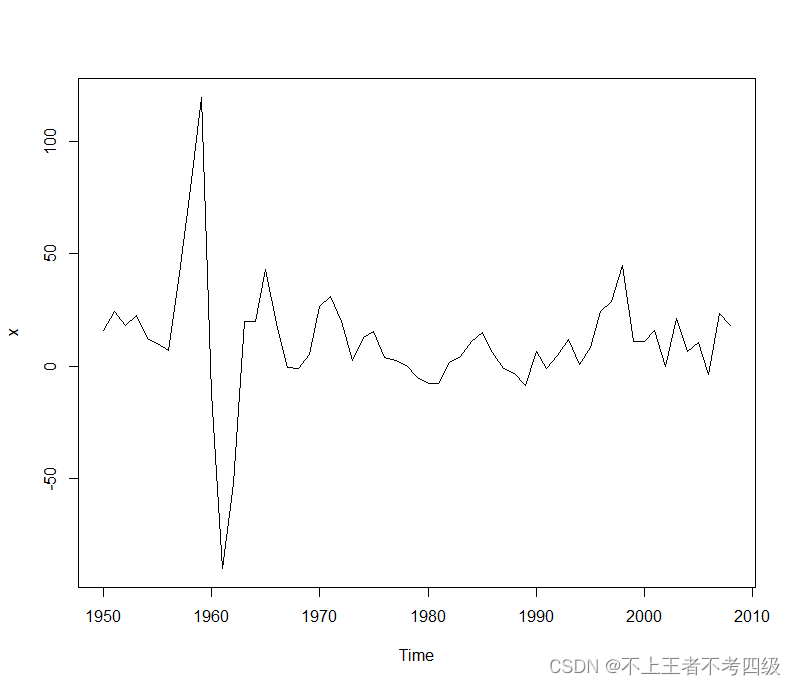

从时序图可以看出,序列平稳,纯随机性检验的结果显示序列不是纯随机序列。
然后绘制自相关图和偏自相关图,输入:
acf(x)
pacf(x)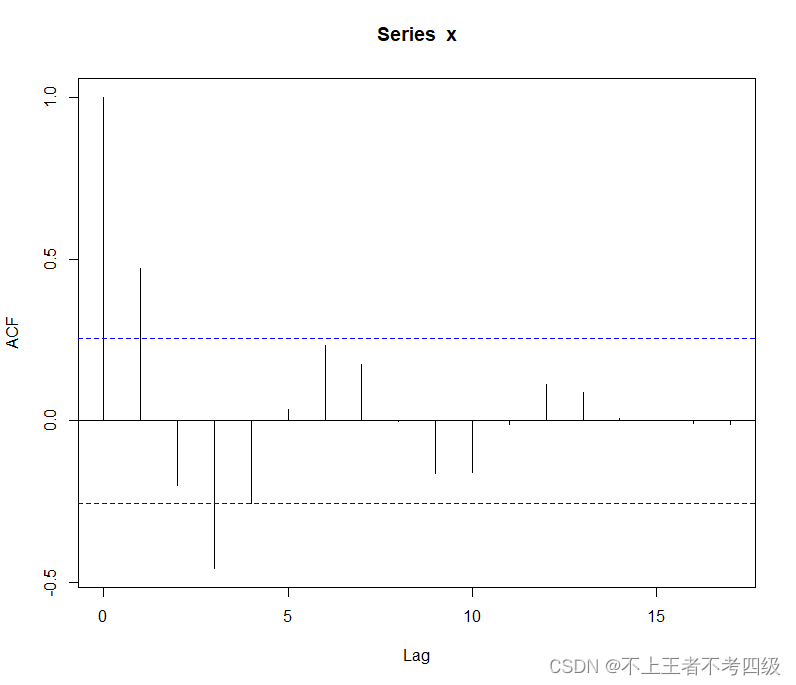
自相关图显示:除了延迟1~3阶的自相关系数在两倍标准差以外,其他各阶自相关系数都在两倍标准差之内,且自相关系数衰减的过程呈现类似正旋波动的形态,这是自相关系数拖尾的一种典型。
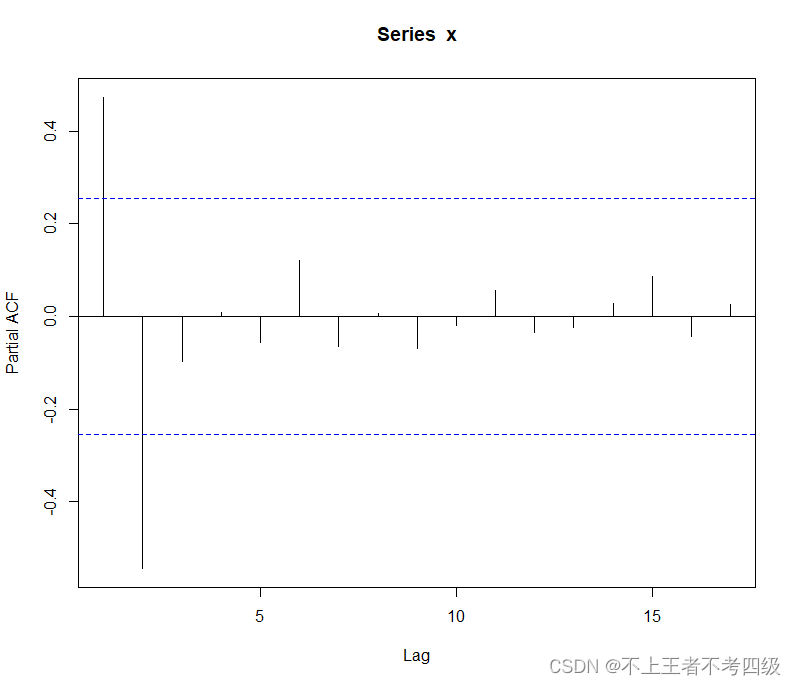
偏自相关图显示:除了延迟1~2阶的偏自相关系数在两倍标准差之外,其他各阶偏自相关系数都在两倍标准差之内,且偏自相关系数衰减的过程非常迅速,因此偏自相关系数2阶结尾。
根据以上特点,可以初步确定模型为AR(2)
2.参数估计
调用arima函数完成参数估计,命令格式为:
arima(x,order=,include.mean=,method=)
其中:x:要拟合的序列名
order:指定模型的阶数,order=c(p,d,q)
include.mean:是否包含常数项
- include.mean=T,需要拟合常数项(默认)
- include.mean=F,不需要拟合常数项
method:指定参数估计得方法
- method="CSS",条件最小二乘
- method="ML"极大似然估计
- method="CSS-ML"两种方法混合
本例采用极大似然估计法,输入:
a<-read.table("E:/R/data/file8.csv",sep=",",header = T)
x<-ts(a$kilometer,start=1950)
x.fit<-arima(x,order = c(2,0,0),method = "ML")
x.fit
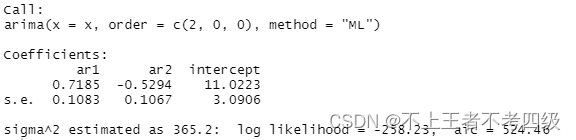
得出模型为:
![]()
或者等价写作:
![]()
3 .模型检验
包括对模型的显著性检验和对参数的显著性检验
- 对模型的显著性检验,即使检验参差序列是否为纯随机序列,用Box.test函数即可完成,输入:
for(i in 1:2) print(Box.test(x.fit$residual,lag=6*i))
从输出结果显示,p值较大,不能拒绝原假设,即参差序列为白噪声序列,因此,本模型为显著的
2.参数的显著性检验,即检验本模型中常数项μ和系数φ1,φ2是否显著,R不提供t检验的结果,但可根据参数估计值和标准差,计算t统计量的值,再调用t分布的p值函数pt计算相应的p值。在本例中,检验常数项的显著性,可输入:
t0=11.0223/3.0906
pt(t0,df=56,lower.tail = F)
输出p值:0.0003748601
可见,常数项是显著的,同理可以检验系数也是显著的
4.模型优化
如果有两个或以上模型都是显著,则可以比较这些模型的信息量AIC,AICC,BIC,按最小信息量准则来选择最优模型信息量为524.46:
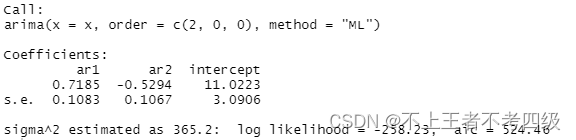 ,本例模型AIC
,本例模型AIC
5.模型预测
下载并调用forecast程序包,可用forecast函数进行预测,命令格式为:
forecast(object,h=,level=)
其中:object:拟合信息文件名
h:预测期数
level:置信区间置信水平,默认给出80%和95%的置信区间
在本例中,要预测未来5年的序列值,可输入:
library(forecast)
x.fore<-forecast(x.fit,h=5)
x.fore
plot(x.fore)
则可观察预测图
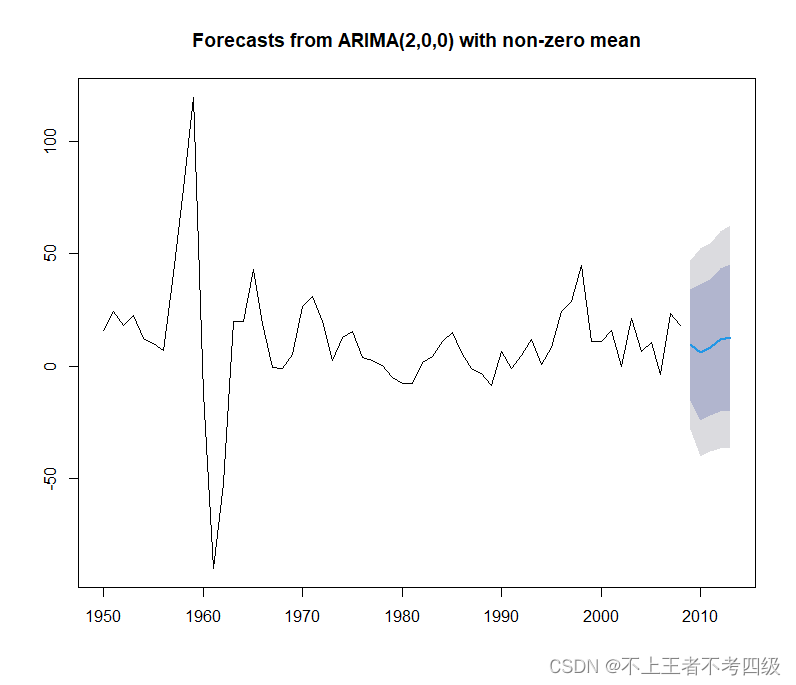
也可个性化输出预测图
L1<-x.fore$fitted-1.96*sqrt(x.fit$sigma2)
U1<-x.fore$fitted+1.96*sqrt(x.fit$sigma2)
L2<-ts(x.fore$lower[,2],start = 2009)
U2<-ts(x.fore$upper[,2],start = 2009)
c1<-min(x,L1,L2)
c2<-max(x,L2,U2)
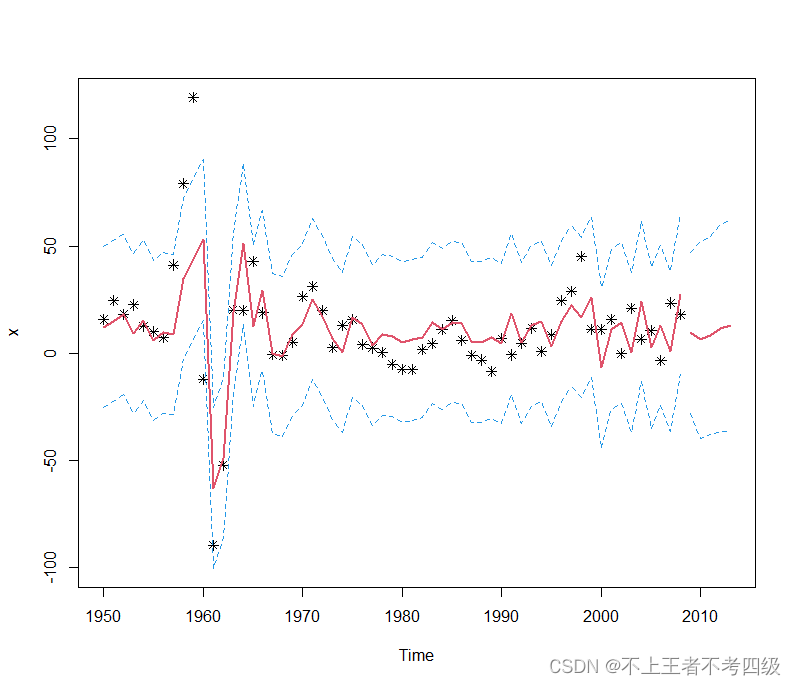
plot(x,type = "p",pch=8,xlim = c(1950,2013),ylim = c(c1,c2))
lines(x.fore$fitted,col=2,lwd=2)
lines(x.fore$mean,col=2,lwd=2)
lines(L1,col=4,lty=2)
lines(L2,col=4,lty=2)
lines(U1,col=4,lty=2)
lines(U2,col=4,lty=2)















 3514
3514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









