








本论文来自于The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21)
Abstract
Informer这篇文章讨论了长序列时间序列预测(LSTF)的问题和挑战,特别是在电力消耗规划等实际应用中。长序列时间序列预测要求模型具有高度的预测能力,能够准确、高效地捕捉输入和输出之间的长距离依赖关系。
虽然最近的研究显示,Transformer模型有潜力提高预测能力,但其存在几个严重问题,包括二次时间复杂度、高内存使用和编码器-解码器架构的内在限制,这使得它不能直接应用于LSTF。为了解决这些问题,作者设计了一个名为“Informer”的高效基于Transformer的模型,具有三个显著特点:
- ProbSparse 自注意力机制:这个机制实现了O(LlogL)的时间复杂度和内存使用,并且在序列依赖对齐上具有可比较的性能。
- 自注意力提炼:它通过减半层叠层输入来突显占主导地位的注意力,并有效处理极长的输入序列。
- 生成式解码器:尽管从概念上讲非常简单,但它可以通过一次向前操作而不是逐步方式预测长时间序列,从而极大地提高了长序列预测的推理速度。
在实验部分,通过在四个大规模数据集上的大量实验,证明了Informer显著优于现有方法,并为LSTF问题提供了新的解决方案。
Introduction
背景
这篇文章的介绍部分首先强调了时间序列预测在多个领域(例如传感器网络监控、能源和智能电网管理、经济金融和疾病传播分析)中的关键作用。在这些场景中,可以利用大量的时间序列数据来进行长期预测,这就是长序列时间序列预测(LSTF)。但目前存在的方法主要是设计用于短期问题设置,比如预测48个点或更少,这限制了研究LSTF的进展。
LSTF的主要挑战是提高预测能力来满足日益增长的长序列需求,这需要(a)卓越的长距离对齐能力和(b)在长序列输入和输出上的高效操作。虽然Transformer模型最近在捕捉长距离依赖性方面表现出了优越的性能,但它的自注意力机制违反了要求(b),因为它在L长度的输入/输出上具有L次方的计算和内存消耗。
原始Transformer的局限性
原始的Transformer模型在解决LSTF问题时存在三个主要限制:
- 自注意力的二次方计算 - 自注意力机制的基本操作,即规范点积,导致每层的时间复杂度和内存使用量为O(L²)。
- 在长输入上堆叠层的内存瓶颈 - J层编码器/解码器层的堆叠使总内存使用量达到O(J·L²),限制了模型在接收长序列输入时的可扩展性。
- 预测长输出时速度急剧下降 - 原始Transformer的动态解码使得逐步推理与基于RNN的模型一样慢。
虽然有一些先前的工作试图改善自注意力的效率,但它们主要关注第1个限制,而第2和3个限制在LSTF问题中仍然没有解决。
Informer模型特点
为了解决这些问题和提高预测能力,作者提出了Informer模型特点(同摘要一致):
- 利用ProbSparse自注意力机制有效替换传统的自注意力,实现了O(LlogL)的时间复杂度和内存使用量。
- 提出了自注意力提炼操作,以优先考虑J堆叠层中占主导地位的注意分数,并大幅减少总空间复杂度至O((2-ε)LlogL),有助于接收长序列输入。
- 提出了生成式解码器,仅需一步向前操作就能获取长序列输出,同时避免了推理阶段累积错误的传播。
Preliminary
LSTF问题的定义
- 问题定义:在一个滚动预测的设定中,使用一个固定大小的窗口,我们有时间t的输入Xt={xt1,…,xtLx}, 其中每个 xti∈Rdx。输出是预测相应的序列 Yt={yt1,…,ytLy},其中每个 yti∈Rdy。
- 特点:
- 鼓励更长的输出长度 Ly,超过了之前的研究。
- 特征维度不限于单变量情况(dy≥1)。
编码器-解码器架构
- 功能:
- 编码器:将输入表示Xt 编码成隐藏状态表示Ht。
- 解码器:从 Ht 解码输出表示 Yt。
- 动态解码:
- 描述了解码过程中的一步步过程,其中解码器计算来自第 k 步的新隐藏状态 ht(k+1) 和其他必要输出,然后预测第 k+1 序列 yt(k+1)。
输入表示
- 均匀输入表示:给出一个均匀的输入表示,以增强时间序列输入的全局位置上下文和本地时间上下文。
- 细节:为了避免琐碎的描述,作者将细节放在附录B中。
Methodology
时间序列预测的现有方法:
两大类别:经典时间序列模型和深度学习技术,后者主要使用RNN及其变体来开发编码器-解码器预测范式。
nformer的总体结构图如下:
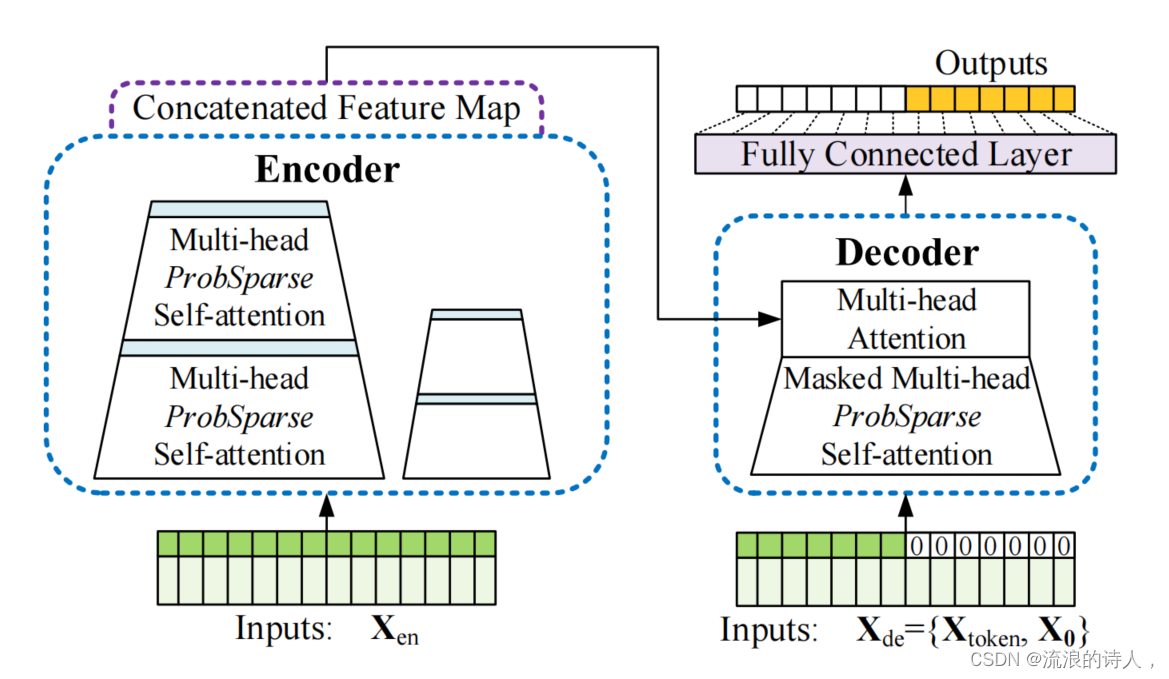
左:编码器接收大量的长序列输入(绿色序列)。我们用所提出的概率稀疏自注意来代替规范的自注意。蓝色梯形是提取主导注意力的自注意提取操作,大大减小了网络的规模。该层的堆叠副本增加了鲁棒性。
右图:解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意组成,并立即以生成方式预测输出元素(橙色系列)。
有效自注意力机制(Efficient Self-attention Mechanism)
基本定义:基于元组输入(即查询、键和值)的自注意力机制,通过执行缩放点积来定义。
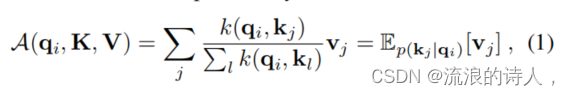
公式和运算:详细介绍了如何通过计算概率p(kj|qi)来结合值并获得输出。它需要二次时间的点积计算和O(LQ LK)的内存使用,这是增强预测能力时的主要缺点。
现有的解决方法和其局限性:
概率分布的稀疏性:早期的尝试揭示了自注意力概率分布具有潜在的稀疏性,并设计了选择性计数策略,而不会显著影响性能。
现有的改进方案:Sparse Transformer, LogSparse Transformer和Longformer 是针对自注意力机制的一些改进方案,但它们受到了理论分析的限制,并采用了相同的策略来处理每个多头自注意力,限制了它们的进一步改进。
对标准自注意力学习到的注意力模式进行定性评估,发现“稀疏”自注意力得分呈现长尾分布,即少数点积对贡献了主要的注意力,而其他则产生了微不足道的注意力。如何区分主要注意力和微不足道的注意力?
查询稀疏性度量(Query Sparsity Measurement )
- 背景:自注意力的输出是它与值v的组合。显著的点积对会推动相应查询的注意力概率分布远离均匀分布。
- 衡量“重要”查询的方式:通过Kullback-Leibler (KL) 散度来衡量分布p和q之间的“相似度”,用于区分“重要”的查询。
- 稀疏度量的公式:提出了一个计算查询的稀疏度量的公式,该公式包括对所有键的Log-Sum-Exp(LSE)和算术均值。
- 稀疏度量的解释:如果查询得到更大的M(qi, K)值,它的注意力概率更“多样”,并且更有可能包含长尾自注意力分布头部字段中的主导点积对
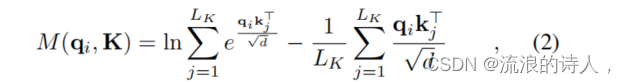
- 目的: 该公式定义了一个衡量查询向量qi的稀疏度的方法。
- 符号:
- M(qi,K): 第i个查询向量的稀疏度量
- LK: 键向量的数量
- 解释:
- 第一项是所有键向量上的Log-Sum-Exp(LSE);
- 第二项是对所有键向量点积的算术均值。
- 通过比较这两项,我们可以衡量特定查询向量的稀疏性,即它主要关注的键向量数量。
稀疏自注意力机制(ProbSparse Self-attention)
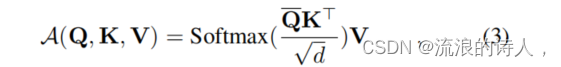
(此公式表示经过修改后的自注意力计算,其中Q是经过稀疏化处理的查询矩阵。)
- 基本概念:基于提出的度量,ProbSparse自注意力只允许每个键关注u个主导查询。
- 稀疏矩阵Q:Q是一个稀疏矩阵,只包含稀疏度量M(q, K)下的Top-u查询。
- 复杂度降低:通过控制一个常数采样因子c来设置u值,这使得ProbSparse自注意力只需要计算O(lnLQ)的点积,每个查询-键查找和层内存使用量保持在O(LK lnLQ)。
- 多头注意力的角度:这种注意力为每个头生成不同的稀疏查询-键对,以避免严重的信息损失。
查询稀疏性度量的近似和优化
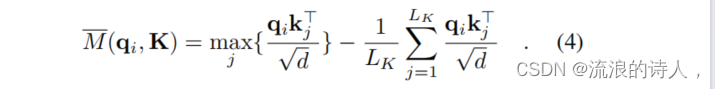
(此公式提供了一个经验近似来高效计算每个查询的稀疏度量,通过最大值和均值的差异来近似计算查询的稀疏度,减少了计算复杂度和提高了数值稳定性)
- 数值稳定性和效率问题:遍历所有查询以获得M(qi, K)度量需要计算每个点积对,除了LSE操作还有潜在的数值稳定性问题。由此,作者提出了一个经验近似来高效获取查询稀疏度量。
- 引理1和边界:提出了一个关于M(qi, K)的边界的引理。
- 最大-平均度量:基于引理1,提出了最大-平均度量的公式。
- 数值稳定性和计算复杂度:在长尾分布下,只需要随机抽样一些点积对来计算M(qi, K),并从中选择稀疏的Top-u作为Q。这种方式数值稳定且减少了计算复杂度。
ProbSparse自注意力计算过程(自我小结)
- 计算稀疏度量: 使用公式(4)来计算稀疏度量 M(qi, K),这涉及到计算每个查询 qi 与所有键的最大点积和平均点积。
- 选择Top-u查询: 基于计算出的稀疏度量,选择Top-u查询。u是一个参数,它决定了我们要选择多少个“顶部”查询。它是通过c·lnLQ来计算的,其中c是一个常数,LQ是查询的数量。
- 计算自注意力输出: 使用选定的Top-u查询和所有的键和值来计算自注意力输出。这是通过公式(3)来完成的,它涉及到计算一个稀疏的点积矩阵(只包含Top-u查询的点积),然后应用Softmax和乘以值矩阵来得到输出。
Encoder
Encoder结构如下图
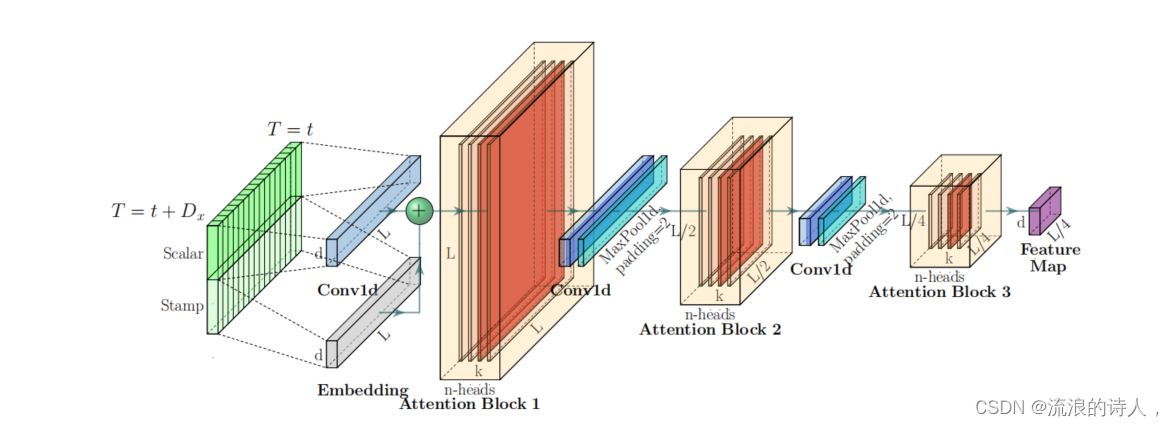
结构解释
- 水平堆栈:这表示单个的编码器副本。在Informer模型的架构中,可能有多个这样的副本或“堆栈”并行工作,每个都有不同的角色和责任。
- 主堆栈:当前展示的是主堆栈,它接收整个输入序列。然后第二个堆栈只接收输入的一半切片,并且后续的堆栈会重复这个处理过程(每次都取前一个堆栈输入的一半)。
- 红色层(Dot-product矩阵):这些层表示点积矩阵,通过在每一层上应用自注意力提炼(self-attention distilling),这些矩阵会级联减少。这种减少可能是通过减少特征映射的维度或减少计算的复杂性来实现的,目的是优化性能和内存使用。
- 连接所有堆栈的特征映射:在所有的处理和计算完成后,所有堆栈的特征映射将被连接起来作为编码器的输出。这意味着从所有堆栈中收集信息和特征映射,并将它们整合成一个单一的输出,这将用于模型的下一阶段。
自注意力提炼(Self-attention Distilling)
因为ProbSparse自注意力机制的应用,编码器的特征映射(feature map)具有多余的值(V)的组合。作者提出一个“提炼”操作来特权占主导地位的特征,并在下一层创建一个集中的自注意力特征映射。这个操作大幅度减少了输入的时间维度。
提炼操作从第j层前进到第(j+1)层,其公式如下:
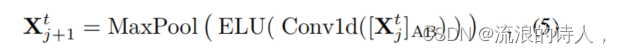
这里,[⋅]AB 是注意力块(Attention Block),它包含了多头(Multi-head)ProbSparse自注意力和一些基本操作。在这个块内,执行了一个1-D卷积滤波器(kernel width = 3)在时间维度上,其激活函数是ELU。
- Conv1d(·): 这是一个一维卷积操作,使用3个kernel width来处理时间维度。
- ELU(·): 指的是指数线性单元(Exponential Linear Unit),是一种激活函数,可以加快训练速度并提高网络的性能。
- MaxPool: 这是最大池化层,用stride 2来进行下采样,减少每一层的维度到一半。
(通过这种方式,每一层的内存使用量降低到O((2-ε)L log L),ε是一个很小的数字)
Decoder
解码器结构
解码器是基于Vaswani等人在2017年提出的标准结构,由两个相同的多头注意力层组成。该结构的目标是生成长序列输出。
示例: 假设你有一个模型,它需要预测未来一周的天气。输入数据包括每天的气温,湿度等。这个模型的解码器部分就会用于生成这种类型的长序列预测。
- 生成式推理(Generative Inference)
在这个部分,作者提到使用“生成式推理”来提高长序列预测的速度。它使用了一个“起始令牌”(start token)和一个目标序列的占位符来生成输入向量。
示例: 继续上述天气预测的例子,你可以选择目标周前5天的数据作为“起始令牌”,与目标周的时间戳一起作为输入向量。
- Loss 函数
这里选择了均方误差(MSE)作为损失函数,以量化预测与目标序列之间的差异。
示例: 在天气预测模型中,损失函数将帮助你量化模型预测的温度与实际温度之间的差异。
Conclusion
在这篇文章的结论部分,作者总结了他们的研究成果和Informer模型的贡献。他们详细描述了他们如何通过设计ProbSparse自注意力机制和提取操作来解决原始Transformer中的二次时间复杂度和内存使用问题。他们还强调了他们精心设计的生成式解码器如何减少了传统编码-解码架构的限制,增强了长序列时间序列预测(LSTF)问题中的预测能力。通过在实际数据上进行实验,他们验证了Informer模型的有效性。

















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









