







微小图像数据集
CIFAR-10由60000张微小的(32像素*32像素)RGB图像组成,用一个整数对应10个级别中的1个:飞机(0)、汽车(1)、鸟(2)、猫(3)、鹿(4)、狗(5)、青蛙(6)、马(7)、船(8)、卡车(9)。
下载CIFAR-10
'''
导入TorchVision模块并使用datasets模块下载CIFAR-10数据
'''
from torchvision import datasets
data_path='/data1/QinRui/CIFAR-10'
cifar10=datasets.CIFAR10(data_path,train=True,download=True)# 实例化一个数据集用于训练数据,如果数据集不存在,则TorchVision将下载该数据集
cifar10_val=datasets.CIFAR10(data_path,train=False,download=True)#使用train=False,获取一个数据集用于验证数据,并在需要时再次下载该数据集

Dataset类
Dataset是一个需要实现2种函数的对象:__ len__()和__getitem__(),前者返回数据中的项数,后者返回由样本和与之对应的标签(整数索引)组成的项。
class_names = ['airplane','automobile','bird','cat','deer',
'dog','frog','horse','ship','truck']
'''
当Python对象配备了__len__()函数时,我们可以将其作为参数传递给Python的内置函数len()
'''
print(len(cifar10))# 50000
'''
由于数据集配备了__getitem__()函数,我们可以使用标准索引对元组和列表进行索引
以访问单个数据项。这里,我们得到一个带有期望输出的PIL图像,即输出值为整数1,对应图像数据集中的”汽车“
'''
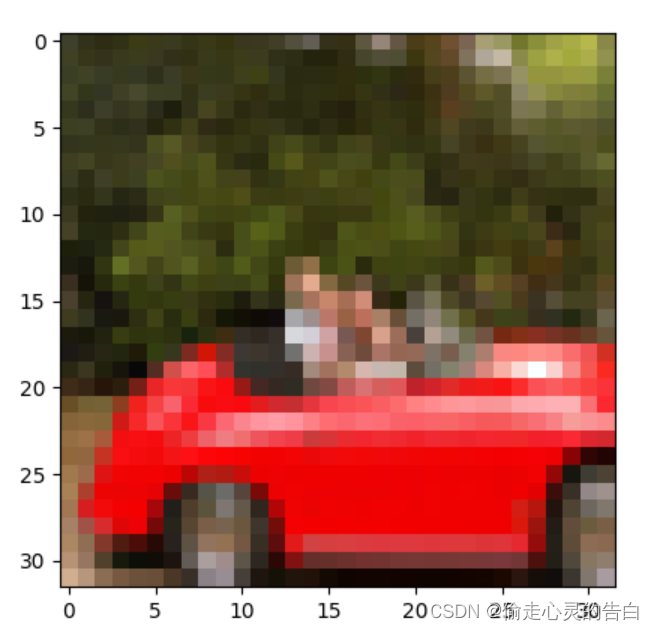
img,label=cifar10[99]
print(img,label,class_names[label])
plt.imshow(img)
plt.show()
来自CIFAR-10数据集的第99幅图像:一辆红色的汽车
Dataset变换
我们需要一种方法来将PIL图像变换为PyTorch张量,然后才能使用它做别的事情,因此引入了torchvision.transforms模块。这个模块定义了一组可组合的、类似函数的对象,它可以作为参数传递到TorchVision模块的数据集,诸如datasets.CIFAR10(… ),在数据加载之后,在__getitem__()返回之前对数据进行变换。
我们来试试ToTensor变换,一旦ToTensor被实例化,就可以像调用函数一样调用它,以PIL图像作为参数,返回一个张量作为输出。
from torchvision import transforms
to_tensor=transforms.ToTensor()
img_t=to_tensor(img)
#print(img_t,'\n',img_t.shape)# 图像已变换为3*32*32的张量
'''
我们可以将变换直接作为参数传递给dataset.CIFAR10,
此时,访问数据集的元素将返回一个张量,而不是PIL图像
'''
tensor_cifar10=datasets.CIFAR10(data_path,train=True,download=False,transform=transforms.ToTensor())
img_t,_=tensor_cifar10[99]
print(type(img_t),img_t.shape,img_t.dtype)
数据归一化
变换非常方便,因为我们可以使用transforms.Compose()将它们连接起来,然后在数据加载器中直接透明地进行数据归一化和数据增强操作。
对每个通道进行归一化,使其具有相同的分布,可以保证在相同的学习率下,通过梯度下降实现通道信息的混合和更新。
'''
现在让我们计算CIFAR-10训练集的平均值和标准差。
让我们将数据集返回的所有张量沿着一个额外的维度进行堆叠
'''
imgs=torch.stack([img_t for img_t, _ in tensor_cifar10],dim=3)
print(imgs.shape)
'''
计算出每个信道的平均值
'''
imgs.view(3,-1).mean(dim=1)
# 保留3个通道,并将剩余的所有维度合并为一个维度,从而计算出适当的尺寸大小。
# 这里3*32*32的图像被转换成一个3*1024的向量,然后对每个通道的1024个元素取平均值
'''
计算标准差
'''
imgs.view(3,-1).std(dim=1)
'''
连接到ToTensor变换
'''
transformed_cifar10=datasets.CIFAR10(
data_path,train=True,download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4915,0.4823,0.4468),
(0.2470,0.2435,0.2616))
]))
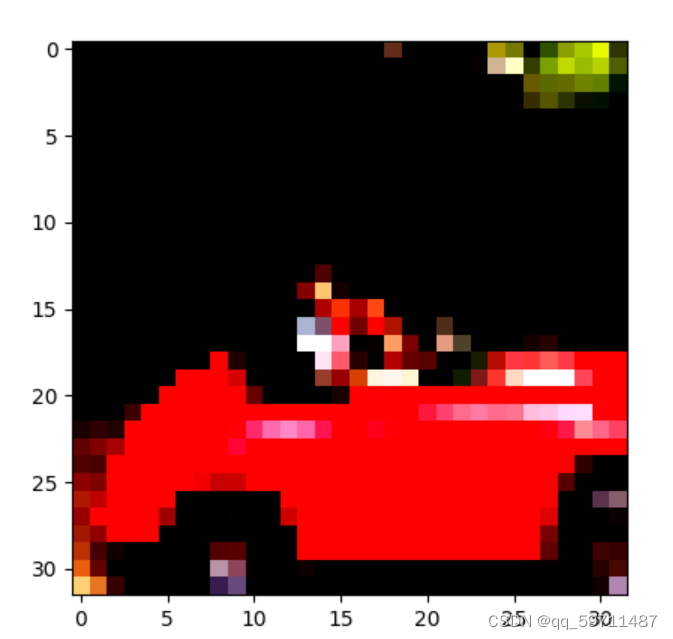
img_t,_=transformed_cifar10[99]
plt.imshow(img_t.permute(1,2,0))
plt.show()
重新归一化后得到的红色汽车。因为归一化对RGB超出0.0~1.0的数据进行了转化,并且调整了通道的总体大小,所有的数据仍然存在,只是Matplotlib将其渲染为黑色。
区分鸟和飞机
我们将从CIFAR-10数据集中选出所有的鸟和飞机,并建立一个神经网络来区分鸟和飞机。
构建数据集
'''
获取正确形状的数据
'''
label_map = {0: 0, 2: 1}
class_names = ['airplane', 'bird']
cifar2 = [(img, label_map[label])
for img, label in cifar10
if label in [0, 2]]
cifar2_val = [(img, label_map[label])
for img, label in cifar10_val
if label in [0, 2]]
一个全连接模型
我们知道神经网络它包括一个特征输入张量和一个特征输出张量。图像只是一组在空间结构中排列的数字,我们现在还不知道如何处理空间结构部分,但理论上如果我们把图像像素拉成一个长的一维向量,就可以把这些数字当作输入特征。
每个样本有多少特征?32323,也就是说,每个样本有3072个特征。我们的新模型将是一个线性模型(nn.Linear),它有3072个输入特征和一些隐藏的特征,接着是一个激活函数,然后另一个线性模型使网络的输出特征逐渐减少到适当的数量(本例来说,输出特征数量为2)。
'''
一个全连接模型
'''
import torch.nn as nn
n_out=2
model=nn.Sequential(
nn.Linear(3072,#输入特征
512,#隐藏层
),
nn.Tanh(),
nn.Linear(512,#影藏层
n_out,#输出类
)
)
我们任意选择了512个隐藏特征。一个神经网络至少需要一个隐藏层(激活层,也就是2个模块),否则它将只是一个线性模型。隐藏的特征表示经由权重矩阵编码的输入之间的(学习的)关系。
分类器的输出
我们认识到输出是分类的:要么是鸟,要么是飞机。当我们必须表示一个分类变量时,我们应该用该变量的独热编码表示,如对于飞机使用[1,0],对于鸟使用[0,1],顺序任意。
理想情况下,网络将为飞机输出torch.tensor([1.0,0.0]),为鸟输出torch.tensor([0.0,1.0])。实际上,由于我们的分类器并不是很完美的,我们可以期望网络输出介于二者之间的结果。在这种情况下,关键的实现是我们可以将输出解释为概率:第1项是“飞机的概率”,第2项是“鸟”的概率。
用概率表示输出
Softmax是一个函数。它获取一个值向量并生成另一个相同维度的向量,其中的值满足以下约束条件:
- 输出的每个元素必须在[0.0,1.0]的范围内
- 输出元素的总和必须为1.0
Softmax是一个单调函数,因为输入中的较小值对应输出中的较小值。
nn模块将Softmax作为一个可用的模块。其要求我们指定用来编码概率的维度。
本例中,我们在2行中有2个输入向量,所以我们初始化nn.Softmax()沿第一维度进行操作。
现在我们可以在模型的末尾添加一个nn.Softmax(),这样我们的网络就可以产生概率了。
import torch.nn as nn
n_out=2
model=nn.Sequential(
nn.Linear(3072,#输入特征
512,#隐藏层
),
nn.Tanh(),
nn.Linear(512,#影藏层
n_out,#输出类
),
nn.Softmax(dim=1)
)
'''
训练前的尝试
'''
img,_=cifar2[0]
img_batch=img.view(-1).unsqueeze(0)# 把3*32*32的图像变成一个一维张量,然后在第0个位置增加一个维度
out=model(img_batch)
_,index=torch.max(out,dim=1)# torch.max()返回该维度上的最大元素以及该值出现的索引
分类的损失
损失是赋予概率意义的东西。
我们需要最大化的是与正确的类out[class_index]相关的概率,其中out是softmax的输出,class_index是一个向量,对于每个样本,“飞机”为0,“鸟”为1。这个值,即与正确的类别相关的概率,被称为我们的模型给定参数的似然。
换句话说,我们想要一个损失函数,当概率很低的时候,损失非常高;低到其他选择都有比它更高的概率。相反,当概率高于其他选择时,损失应该很低,而且我们并不是真的专注于将概率提高到1。
综上,我们的分类损失可以按如下步骤计算。
- 运行正向传播,并从最后的线性层获得输出值
- 计算它们的Softmax,并获得概率
- 取与目标类别对应的预测概率(参数的似然值)
- 计算它的对数,在它前面加上一个负号,再添加到损失中
PyTorch有一个nn.NLLLoss类,但是与你期望的不同,它没有取概率而是取对数概率张量作为输入。然后在给定一批数据的情况下计算模型的NLL,输入约定背后的原因是当概率接近0时,取概率的对数是很棘手的事情。解决方法是使用nn.LogSoftmax()而不是使用nn.Softmax(),以确保计算在数值上稳定。
loss=nn.NLLLoss()#实例化
'''
损失将批次的nn.LogSoftmax()的输出作为第1个参数,将类别索引的张量作为第2个参数。
用鸟来测试
'''
img,label=cifar2[0]
out=model(img.view(-1).unsqueeze(0))
loss(out,torch.tensor([label]))
训练分类器
'''
编写训练
'''
import torch.optim as optim
model=nn.Sequential(
nn.Linear(3072,512,),
nn.Tanh(),
nn.Linear(512,2,),
nn.LogSoftmax(dim=1))
learning_rate=1e-2
optimizer=optim.SGD(model.parameters(),lr=learning_rate)
loss_fn=nn.NLLLoss()
n_epochs=100
for epoch in range(n_epochs):
for img,label in cifar2:
out=model(img.view(-1).unsqueeze(0))
loss=loss_fn(out,torch.tensor([label]))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch:%d,Loss:%f"% (epoch,float(loss)))
在训练代码中,我们选择大小为1的小批量,即每次从数据集中选择一项。torch.utils.data模块有一个DataLoader类,该类有助于打乱数据和组织数据。数据加载器的工作是从数据集中采样小批量,这使我们能够灵活地选择不同的采样策略。一种非常常见的策略是在每个迭代周期洗牌后进行均匀采样。
DataLoader()构造函数至少接收一个数据集对象作为输入,以及batch_size和一个shuffle布尔值,该布尔值指示数据是否需要在每个迭代周期开始时被重新打乱。
DataLoader可以被迭代,因此我们可以直接在新训练代码的内部循环中使用它。
import torch.optim as optim
train_loader=torch.utils.data.DataLoader(cifar2,batch_size=64,shuffle=True)
model=nn.Sequential(
nn.Linear(3072,512,),
nn.Tanh(),
nn.Linear(512,2,),
nn.LogSoftmax(dim=1))
learning_rate=1e-2
optimizer=optim.SGD(model.parameters(),lr=learning_rate)
loss_fn=nn.NLLLoss()
n_epochs=100
for epoch in range(n_epochs):
for imgs,label in train_loader:
batch_size=imgs.shape[0]
out=model(imgs.view(batch_size,-1))
loss=loss_fn(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch:%d,Loss:%f"% (epoch,float(loss)))
在每个内部迭代中,imgs是一个6433232的张量,也就是64个3232的RGB图像的小批量,而labels是一个包含标签索引的、大小为64的张量。
由于我们的目标是正确地为图像分配类别,并且最好是在独立数据集上这样做,我们可以根据总分类的正确数量来计算验证集上模型的准确性。
'''
计算准确性
'''
val_loader=torch.utils.data.DataLoader(cifar2_val,batch_size=64,shuffle=False)
correct=0
total=0
with torch.no_grad():
for imgs,labels in val_loader:
batch_size=imgs.shape[0]
outputs=model(imgs.view(batch_size,-1))
_,predicted=torch.max(outputs,dim=1)
total+=labels.shape[0]
correct+=int((predicted==labels).sum())
print("Accuracy:%f",correct/total)
总结
我们构建的模型有一个严重的缺陷:我们一直将二维图像当作一维来处理。此外,我们没有一个自然的方法来整合全连接层的平移不变性。解决当前面临的问题的方法是改变我们的模型——使用卷积层。















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









